 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bridging the Gap between Synthetic and Authentic Images for Multimodal Machine Translation
Oct 20, 2023
Multimodal machine translation (MMT) simultaneously takes the source sentence and a relevant image as input for translation. Since there is no paired image available for the input sentence in most cases, recent studies suggest utilizing powerful text-to-image generation models to provide image inputs. Nevertheless, synthetic images generated by these models often follow different distributions compared to authentic images. Consequently, using authentic images for training and synthetic images for inference can introduce a distribution shift, resulting in performance degradation during inference. To tackle this challenge, in this paper, we feed synthetic and authentic images to the MMT model, respectively. Then we minimize the gap between the synthetic and authentic images by drawing close the input image representations of the Transformer Encoder and the output distributions of the Transformer Decoder. Therefore, we mitigate the distribution disparity introduced by the synthetic images during inference, thereby freeing the authentic images from the inference process.Experimental results show that our approach achieves state-of-the-art performance on the Multi30K En-De and En-Fr datasets, while remaining independent of authentic images during inference.
Towards Complex-query Referring Image Segmentation: A Novel Benchmark
Sep 29, 2023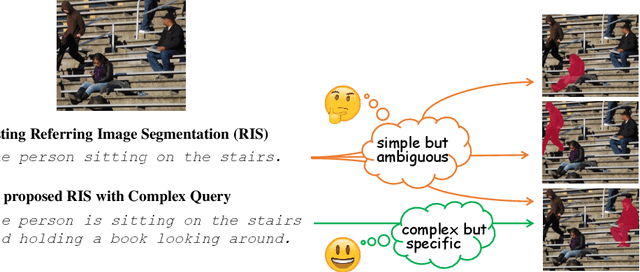
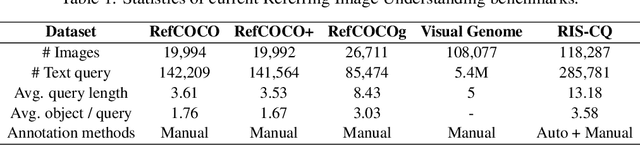

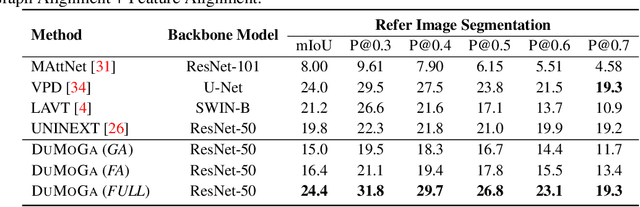
Referring Image Understanding (RIS) has been extensively studied over the past decade, leading to the development of advanced algorithms. However, there has been a lack of research investigating how existing algorithms should be benchmarked with complex language queries, which include more informative descriptions of surrounding objects and backgrounds (\eg \textit{"the black car."} vs. \textit{"the black car is parking on the road and beside the bus."}). Given the significant improvement in the semantic understanding capability of large pre-trained models, it is crucial to take a step further in RIS by incorporating complex language that resembles real-world applications. To close this gap, building upon the existing RefCOCO and Visual Genome datasets, we propose a new RIS benchmark with complex queries, namely \textbf{RIS-CQ}. The RIS-CQ dataset is of high quality and large scale, which challenges the existing RIS with enriched, specific and informative queries, and enables a more realistic scenario of RIS research. Besides, we present a nichetargeting method to better task the RIS-CQ, called dual-modality graph alignment model (\textbf{\textsc{DuMoGa}}), which outperforms a series of RIS methods.
Pre-training-free Image Manipulation Localization through Non-Mutually Exclusive Contrastive Learning
Sep 27, 2023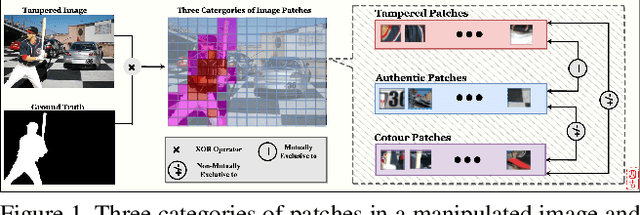
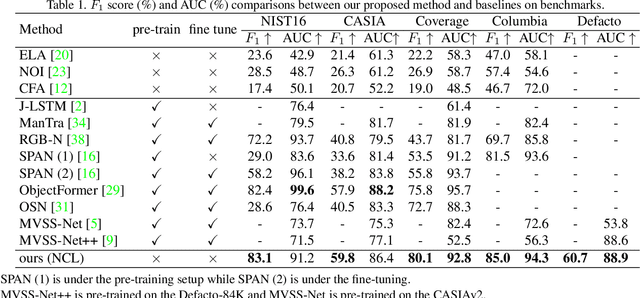
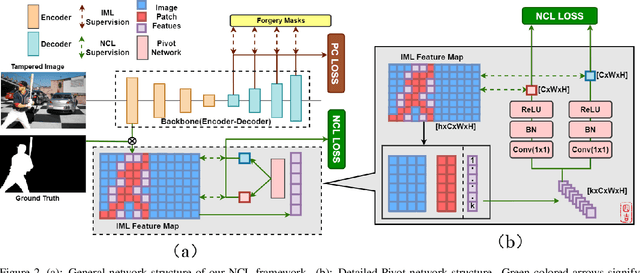
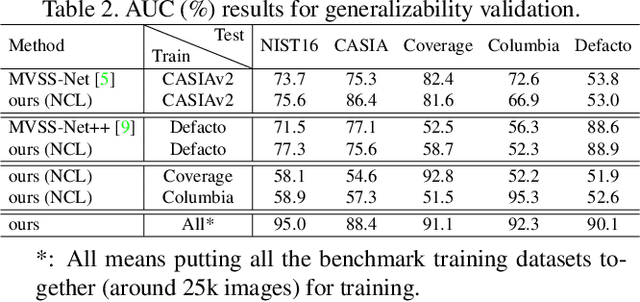
Deep Image Manipulation Localization (IML) models suffer from training data insufficiency and thus heavily rely on pre-training. We argue that contrastive learning is more suitable to tackle the data insufficiency problem for IML. Crafting mutually exclusive positives and negatives is the prerequisite for contrastive learning. However, when adopting contrastive learning in IML, we encounter three categories of image patches: tampered, authentic, and contour patches. Tampered and authentic patches are naturally mutually exclusive, but contour patches containing both tampered and authentic pixels are non-mutually exclusive to them. Simply abnegating these contour patches results in a drastic performance loss since contour patches are decisive to the learning outcomes. Hence, we propose the Non-mutually exclusive Contrastive Learning (NCL) framework to rescue conventional contrastive learning from the above dilemma. In NCL, to cope with the non-mutually exclusivity, we first establish a pivot structure with dual branches to constantly switch the role of contour patches between positives and negatives while training. Then, we devise a pivot-consistent loss to avoid spatial corruption caused by the role-switching process. In this manner, NCL both inherits the self-supervised merits to address the data insufficiency and retains a high manipulation localization accuracy. Extensive experiments verify that our NCL achieves state-of-the-art performance on all five benchmarks without any pre-training and is more robust on unseen real-life samples. The code is available at: https://github.com/Knightzjz/NCL-IML.
Unveiling the deep plumbing system of a volcano by a reflection matrix analysis of seismic noise
Nov 02, 2023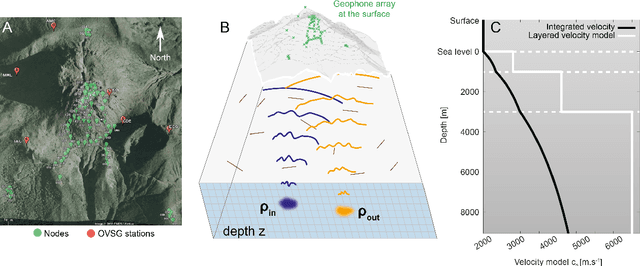
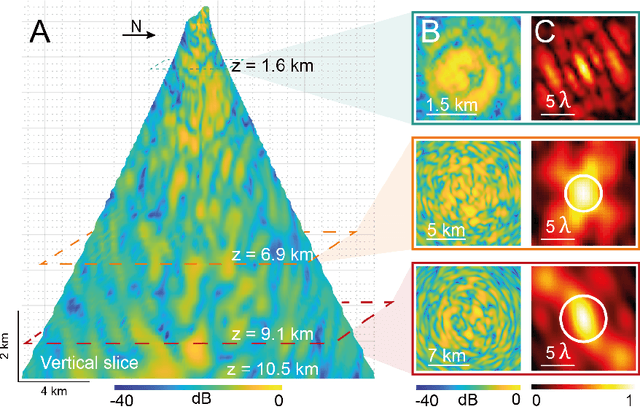
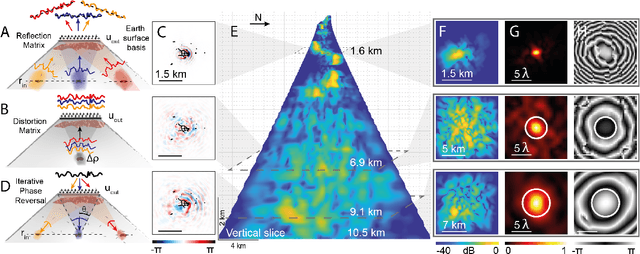
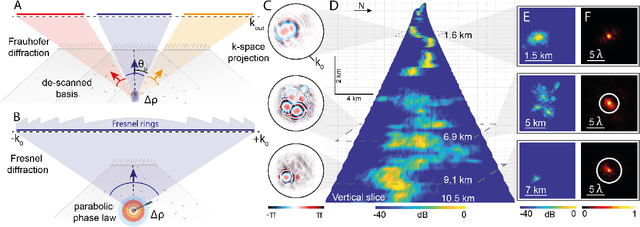
In geophysics, volcanoes are particularly difficult to image because of the multi-scale heterogeneities of fluids and rocks that compose them and their complex non-linear dynamics. By exploiting seismic noise recorded by a sparse array of geophones, we are able to reveal the magmatic and hydrothermal plumbing system of La Soufri\`ere volcano in Guadeloupe. Spatio-temporal cross-correlation of seismic noise actually provides the impulse responses between virtual geophones located inside the volcano. The resulting reflection matrix can be exploited to numerically perform an auto-focus of seismic waves on any reflector of the underground. An unprecedented view on the volcano's inner structure is obtained at a half-wavelength resolution. This innovative observable provides fundamental information for the conceptual modeling and high-resolution monitoring of volcanoes.
TAMPAR: Visual Tampering Detection for Parcel Logistics in Postal Supply Chains
Nov 06, 2023Due to the steadily rising amount of valuable goods in supply chains, tampering detection for parcels is becoming increasingly important. In this work, we focus on the use-case last-mile delivery, where only a single RGB image is taken and compared against a reference from an existing database to detect potential appearance changes that indicate tampering. We propose a tampering detection pipeline that utilizes keypoint detection to identify the eight corner points of a parcel. This permits applying a perspective transformation to create normalized fronto-parallel views for each visible parcel side surface. These viewpoint-invariant parcel side surface representations facilitate the identification of signs of tampering on parcels within the supply chain, since they reduce the problem to parcel side surface matching with pair-wise appearance change detection. Experiments with multiple classical and deep learning-based change detection approaches are performed on our newly collected TAMpering detection dataset for PARcels, called TAMPAR. We evaluate keypoint and change detection separately, as well as in a unified system for tampering detection. Our evaluation shows promising results for keypoint (Keypoint AP 75.76) and tampering detection (81% accuracy, F1-Score 0.83) on real images. Furthermore, a sensitivity analysis for tampering types, lens distortion and viewing angles is presented. Code and dataset are available at https://a-nau.github.io/tampar.
MA-SAM: Modality-agnostic SAM Adaptation for 3D Medical Image Segmentation
Sep 16, 2023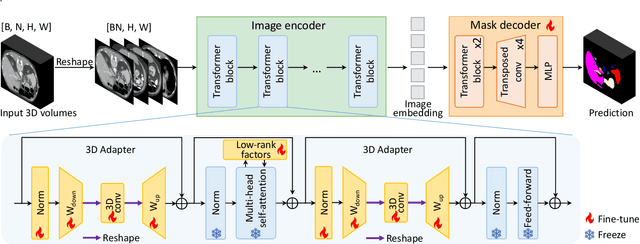
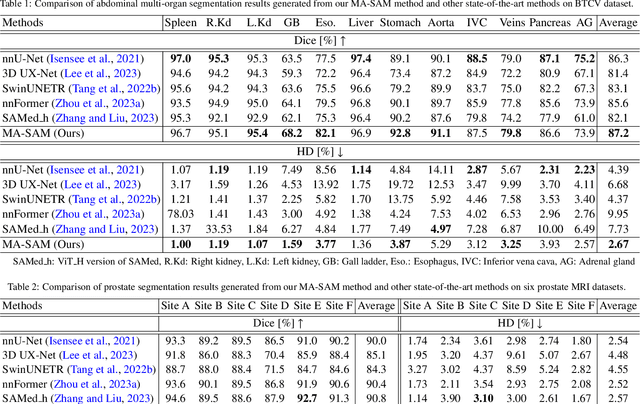
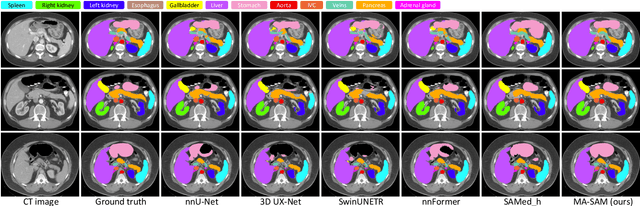
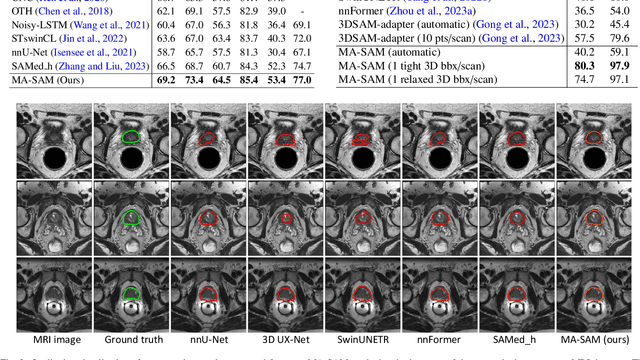
The Segment Anything Model (SAM), a foundation model for general image segmentation, has demonstrated impressive zero-shot performance across numerous natural image segmentation tasks. However, SAM's performance significantly declines when applied to medical images, primarily due to the substantial disparity between natural and medical image domains. To effectively adapt SAM to medical images, it is important to incorporate critical third-dimensional information, i.e., volumetric or temporal knowledge, during fine-tuning. Simultaneously, we aim to harness SAM's pre-trained weights within its original 2D backbone to the fullest extent. In this paper, we introduce a modality-agnostic SAM adaptation framework, named as MA-SAM, that is applicable to various volumetric and video medical data. Our method roots in the parameter-efficient fine-tuning strategy to update only a small portion of weight increments while preserving the majority of SAM's pre-trained weights. By injecting a series of 3D adapters into the transformer blocks of the image encoder, our method enables the pre-trained 2D backbone to extract third-dimensional information from input data. The effectiveness of our method has been comprehensively evaluated on four medical image segmentation tasks, by using 10 public datasets across CT, MRI, and surgical video data. Remarkably, without using any prompt, our method consistently outperforms various state-of-the-art 3D approaches, surpassing nnU-Net by 0.9%, 2.6%, and 9.9% in Dice for CT multi-organ segmentation, MRI prostate segmentation, and surgical scene segmentation respectively. Our model also demonstrates strong generalization, and excels in challenging tumor segmentation when prompts are used. Our code is available at: https://github.com/cchen-cc/MA-SAM.
Text-to-Image Models for Counterfactual Explanations: a Black-Box Approach
Sep 14, 2023This paper addresses the challenge of generating Counterfactual Explanations (CEs), involving the identification and modification of the fewest necessary features to alter a classifier's prediction for a given image. Our proposed method, Text-to-Image Models for Counterfactual Explanations (TIME), is a black-box counterfactual technique based on distillation. Unlike previous methods, this approach requires solely the image and its prediction, omitting the need for the classifier's structure, parameters, or gradients. Before generating the counterfactuals, TIME introduces two distinct biases into Stable Diffusion in the form of textual embeddings: the context bias, associated with the image's structure, and the class bias, linked to class-specific features learned by the target classifier. After learning these biases, we find the optimal latent code applying the classifier's predicted class token and regenerate the image using the target embedding as conditioning, producing the counterfactual explanation. Extensive empirical studies validate that TIME can generate explanations of comparable effectiveness even when operating within a black-box setting.
A Strictly Bounded Deep Network for Unpaired Cyclic Translation of Medical Images
Nov 04, 2023Medical image translation is an ill-posed problem. Unlike existing paired unbounded unidirectional translation networks, in this paper, we consider unpaired medical images and provide a strictly bounded network that yields a stable bidirectional translation. We propose a patch-level concatenated cyclic conditional generative adversarial network (pCCGAN) embedded with adaptive dictionary learning. It consists of two cyclically connected CGANs of 47 layers each; where both generators (each of 32 layers) are conditioned with concatenation of alternate unpaired patches from input and target modality images (not ground truth) of the same organ. The key idea is to exploit cross-neighborhood contextual feature information that bounds the translation space and boosts generalization. The generators are further equipped with adaptive dictionaries learned from the contextual patches to reduce possible degradation. Discriminators are 15-layer deep networks that employ minimax function to validate the translated imagery. A combined loss function is formulated with adversarial, non-adversarial, forward-backward cyclic, and identity losses that further minimize the variance of the proposed learning machine. Qualitative, quantitative, and ablation analysis show superior results on real CT and MRI.
PIPO-Net: A Penalty-based Independent Parameters Optimization Deep Unfolding Network
Nov 04, 2023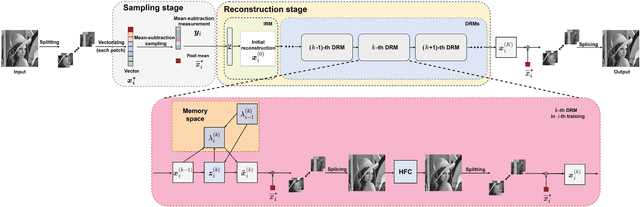
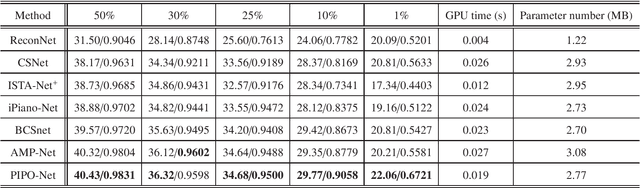
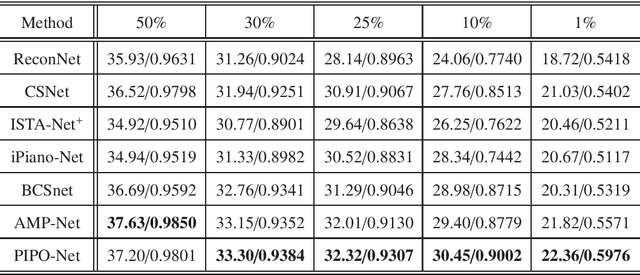

Compressive sensing (CS) has been widely applied in signal and image processing fields. Traditional CS reconstruction algorithms have a complete theoretical foundation but suffer from the high computational complexity, while fashionable deep network-based methods can achieve high-accuracy reconstruction of CS but are short of interpretability. These facts motivate us to develop a deep unfolding network named the penalty-based independent parameters optimization network (PIPO-Net) to combine the merits of the above mentioned two kinds of CS methods. Each module of PIPO-Net can be viewed separately as an optimization problem with respective penalty function. The main characteristic of PIPO-Net is that, in each round of training, the learnable parameters in one module are updated independently from those of other modules. This makes the network more flexible to find the optimal solutions of the corresponding problems. Moreover, the mean-subtraction sampling and the high-frequency complementary blocks are developed to improve the performance of PIPO-Net. Experiments on reconstructing CS images demonstrate the effectiveness of the proposed PIPO-Net.
MMTF-DES: A Fusion of Multimodal Transformer Models for Desire, Emotion, and Sentiment Analysis of Social Media Data
Oct 22, 2023Desire is a set of human aspirations and wishes that comprise verbal and cognitive aspects that drive human feelings and behaviors, distinguishing humans from other animals. Understanding human desire has the potential to be one of the most fascinating and challenging research domains. It is tightly coupled with sentiment analysis and emotion recognition tasks. It is beneficial for increasing human-computer interactions, recognizing human emotional intelligence, understanding interpersonal relationships, and making decisions. However, understanding human desire is challenging and under-explored because ways of eliciting desire might be different among humans. The task gets more difficult due to the diverse cultures, countries, and languages. Prior studies overlooked the use of image-text pairwise feature representation, which is crucial for the task of human desire understanding. In this research, we have proposed a unified multimodal transformer-based framework with image-text pair settings to identify human desire, sentiment, and emotion. The core of our proposed method lies in the encoder module, which is built using two state-of-the-art multimodal transformer models. These models allow us to extract diverse features. To effectively extract visual and contextualized embedding features from social media image and text pairs, we conducted joint fine-tuning of two pre-trained multimodal transformer models: Vision-and-Language Transformer (ViLT) and Vision-and-Augmented-Language Transformer (VAuLT). Subsequently, we use an early fusion strategy on these embedding features to obtain combined diverse feature representations of the image-text pair. This consolidation incorporates diverse information about this task, enabling us to robustly perceive the context and image pair from multiple perspectives.