 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional Neural Networks for Automatic Detection of Intact Adenovirus from TEM Imaging with Debris, Broken and Artefacts Particles
Oct 30, 2023
Regular monitoring of the primary particles and purity profiles of a drug product during development and manufacturing processes is essential for manufacturers to avoid product variability and contamination. Transmission electron microscopy (TEM) imaging helps manufacturers predict how changes affect particle characteristics and purity for virus-based gene therapy vector products and intermediates. Since intact particles can characterize efficacious products, it is beneficial to automate the detection of intact adenovirus against a non-intact-viral background mixed with debris, broken, and artefact particles. In the presence of such particles, detecting intact adenoviruses becomes more challenging. To overcome the challenge, due to such a presence, we developed a software tool for semi-automatic annotation and segmentation of adenoviruses and a software tool for automatic segmentation and detection of intact adenoviruses in TEM imaging systems. The developed semi-automatic tool exploited conventional image analysis techniques while the automatic tool was built based on convolutional neural networks and image analysis techniques. Our quantitative and qualitative evaluations showed outstanding true positive detection rates compared to false positive and negative rates where adenoviruses were nicely detected without mistaking them for real debris, broken adenoviruses, and/or staining artefacts.
Copy-Paste Image Augmentation with Poisson Image Editing for Ultrasound Instance Segmentation Learning
Aug 28, 2023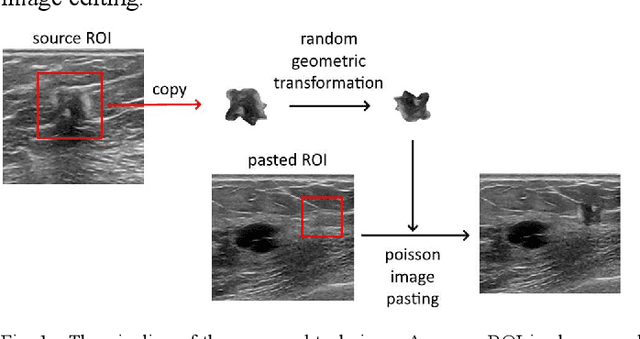
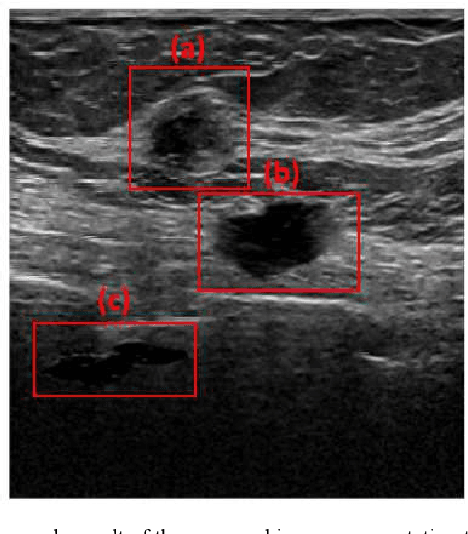
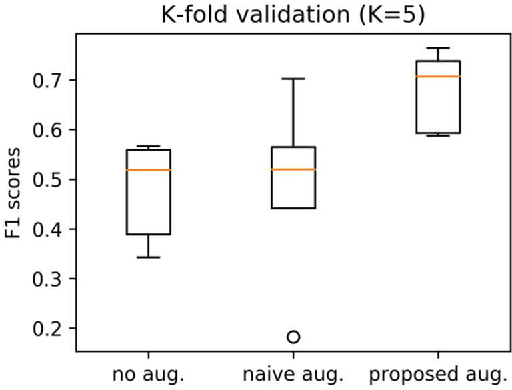
Deep learning has shown great success in high-level image analysis problems; yet its efficacy relies on the quality and diversity of the training data. In this work, we introduce a copypaste image augmentation for ultrasound images. The Poisson image editing technique is used to generate realistic and seamless boundary transitions around the pasted image. Results showed that the proposed image augmentation technique improves training performance in terms of higher objective metrics and more stable training results.
SILC: Improving Vision Language Pretraining with Self-Distillation
Oct 20, 2023Image-Text pretraining on web-scale image caption dataset has become the default recipe for open vocabulary classification and retrieval models thanks to the success of CLIP and its variants. Several works have also used CLIP features for dense prediction tasks and have shown the emergence of open-set abilities. However, the contrastive objective only focuses on image-text alignment and does not incentivise image feature learning for dense prediction tasks. In this work, we propose the simple addition of local-to-global correspondence learning by self-distillation as an additional objective for contrastive pre-training to propose SILC. We show that distilling local image features from an exponential moving average (EMA) teacher model significantly improves model performance on several computer vision tasks including classification, retrieval, and especially segmentation. We further show that SILC scales better with the same training duration compared to the baselines. Our model SILC sets a new state of the art for zero-shot classification, few shot classification, image and text retrieval, zero-shot segmentation, and open vocabulary segmentation.
MetaF2N: Blind Image Super-Resolution by Learning Efficient Model Adaptation from Faces
Sep 15, 2023
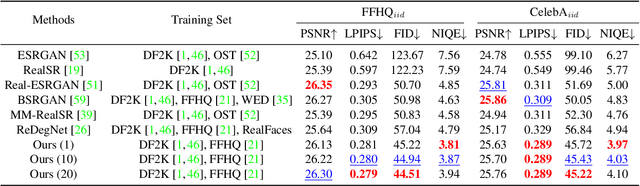
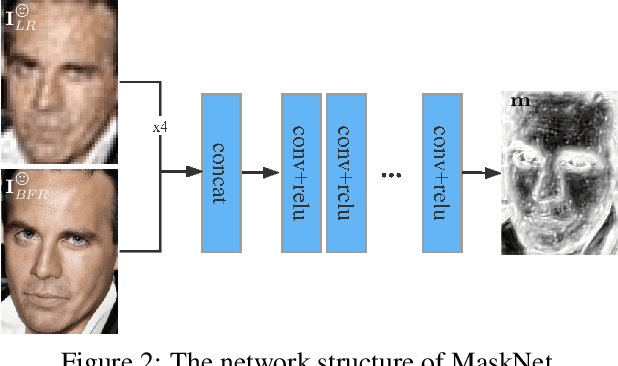
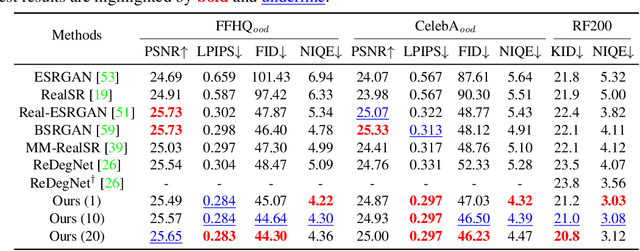
Due to their highly structured characteristics, faces are easier to recover than natural scenes for blind image super-resolution. Therefore, we can extract the degradation representation of an image from the low-quality and recovered face pairs. Using the degradation representation, realistic low-quality images can then be synthesized to fine-tune the super-resolution model for the real-world low-quality image. However, such a procedure is time-consuming and laborious, and the gaps between recovered faces and the ground-truths further increase the optimization uncertainty. To facilitate efficient model adaptation towards image-specific degradations, we propose a method dubbed MetaF2N, which leverages the contained Faces to fine-tune model parameters for adapting to the whole Natural image in a Meta-learning framework. The degradation extraction and low-quality image synthesis steps are thus circumvented in our MetaF2N, and it requires only one fine-tuning step to get decent performance. Considering the gaps between the recovered faces and ground-truths, we further deploy a MaskNet for adaptively predicting loss weights at different positions to reduce the impact of low-confidence areas. To evaluate our proposed MetaF2N, we have collected a real-world low-quality dataset with one or multiple faces in each image, and our MetaF2N achieves superior performance on both synthetic and real-world datasets. Source code, pre-trained models, and collected datasets are available at https://github.com/yinzhicun/MetaF2N.
The Pursuit of Human Labeling: A New Perspective on Unsupervised Learning
Nov 06, 2023We present HUME, a simple model-agnostic framework for inferring human labeling of a given dataset without any external supervision. The key insight behind our approach is that classes defined by many human labelings are linearly separable regardless of the representation space used to represent a dataset. HUME utilizes this insight to guide the search over all possible labelings of a dataset to discover an underlying human labeling. We show that the proposed optimization objective is strikingly well-correlated with the ground truth labeling of the dataset. In effect, we only train linear classifiers on top of pretrained representations that remain fixed during training, making our framework compatible with any large pretrained and self-supervised model. Despite its simplicity, HUME outperforms a supervised linear classifier on top of self-supervised representations on the STL-10 dataset by a large margin and achieves comparable performance on the CIFAR-10 dataset. Compared to the existing unsupervised baselines, HUME achieves state-of-the-art performance on four benchmark image classification datasets including the large-scale ImageNet-1000 dataset. Altogether, our work provides a fundamentally new view to tackle unsupervised learning by searching for consistent labelings between different representation spaces.
Advancing Post Hoc Case Based Explanation with Feature Highlighting
Nov 06, 2023Explainable AI (XAI) has been proposed as a valuable tool to assist in downstream tasks involving human and AI collaboration. Perhaps the most psychologically valid XAI techniques are case based approaches which display 'whole' exemplars to explain the predictions of black box AI systems. However, for such post hoc XAI methods dealing with images, there has been no attempt to improve their scope by using multiple clear feature 'parts' of the images to explain the predictions while linking back to relevant cases in the training data, thus allowing for more comprehensive explanations that are faithful to the underlying model. Here, we address this gap by proposing two general algorithms (latent and super pixel based) which can isolate multiple clear feature parts in a test image, and then connect them to the explanatory cases found in the training data, before testing their effectiveness in a carefully designed user study. Results demonstrate that the proposed approach appropriately calibrates a users feelings of 'correctness' for ambiguous classifications in real world data on the ImageNet dataset, an effect which does not happen when just showing the explanation without feature highlighting.
Masking Hyperspectral Imaging Data with Pretrained Models
Nov 06, 2023The presence of undesired background areas associated with potential noise and unknown spectral characteristics degrades the performance of hyperspectral data processing. Masking out unwanted regions is key to addressing this issue. Processing only regions of interest yields notable improvements in terms of computational costs, required memory, and overall performance. The proposed processing pipeline encompasses two fundamental parts: regions of interest mask generation, followed by the application of hyperspectral data processing techniques solely on the newly masked hyperspectral cube. The novelty of our work lies in the methodology adopted for the preliminary image segmentation. We employ the Segment Anything Model (SAM) to extract all objects within the dataset, and subsequently refine the segments with a zero-shot Grounding Dino object detector, followed by intersection and exclusion filtering steps, without the need for fine-tuning or retraining. To illustrate the efficacy of the masking procedure, the proposed method is deployed on three challenging applications scenarios that demand accurate masking; shredded plastics characterization, drill core scanning, and litter monitoring. The numerical evaluation of the proposed masking method on the three applications is provided along with the used hyperparameters. The scripts for the method will be available at https://github.com/hifexplo/Masking.
MaskDiffusion: Boosting Text-to-Image Consistency with Conditional Mask
Sep 08, 2023

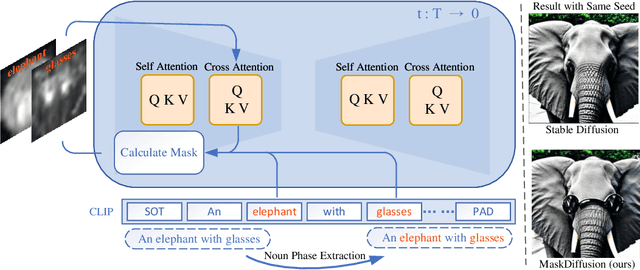

Recent advancements in diffusion models have showcased their impressive capacity to generate visually striking images. Nevertheless, ensuring a close match between the generated image and the given prompt remains a persistent challenge. In this work, we identify that a crucial factor leading to the text-image mismatch issue is the inadequate cross-modality relation learning between the prompt and the output image. To better align the prompt and image content, we advance the cross-attention with an adaptive mask, which is conditioned on the attention maps and the prompt embeddings, to dynamically adjust the contribution of each text token to the image features. This mechanism explicitly diminishes the ambiguity in semantic information embedding from the text encoder, leading to a boost of text-to-image consistency in the synthesized images. Our method, termed MaskDiffusion, is training-free and hot-pluggable for popular pre-trained diffusion models. When applied to the latent diffusion models, our MaskDiffusion can significantly improve the text-to-image consistency with negligible computation overhead compared to the original diffusion models.
Transport-of-Intensity Model for Single-Mask X-ray Differential Phase Contrast Imaging
Oct 29, 2023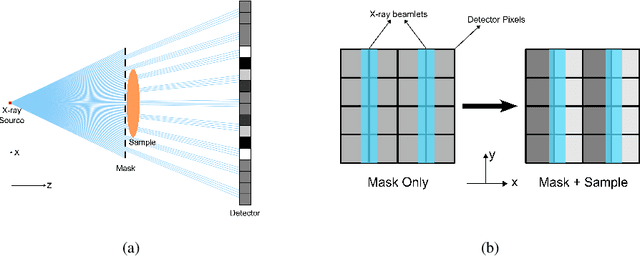
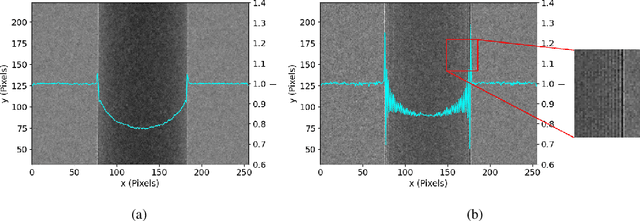
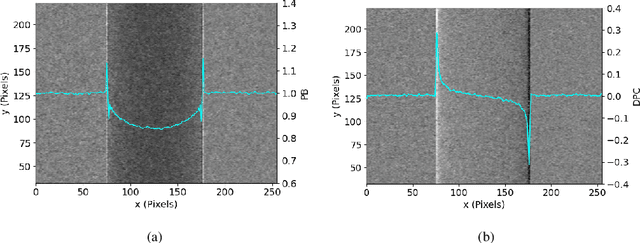

X-ray phase contrast imaging has emerged as a promising technique for enhancing contrast and visibility of light-element materials, including soft tissues and tumors. In this paper, we propose a novel model for a single-mask phase imaging system based on the transport-of-intensity equation. Our model offers an intuitive understanding of signal and contrast formation in single-mask phase imaging systems. We also demonstrate efficient retrieval of attenuation and differential phase contrast with just one intensity image without requiring spectral information or mask/detector movement. The model validity as well as the proposed retrieval method is demonstrated via both experimental results on a system developed in-house as well as with Monte Carlo simulations. Our proposed model overcomes the limitations of existing models by providing an intuitive visualization of the image formation process. It also allows optimizing differential phase imaging geometries for practical applications, further enhancing broader applicability. Furthermore, the general methodology described herein offers insight on deriving transport-of-intensity models for novel X-ray imaging systems with periodic structures in the beam path.
Incorporating Ensemble and Transfer Learning For An End-To-End Auto-Colorized Image Detection Model
Sep 25, 2023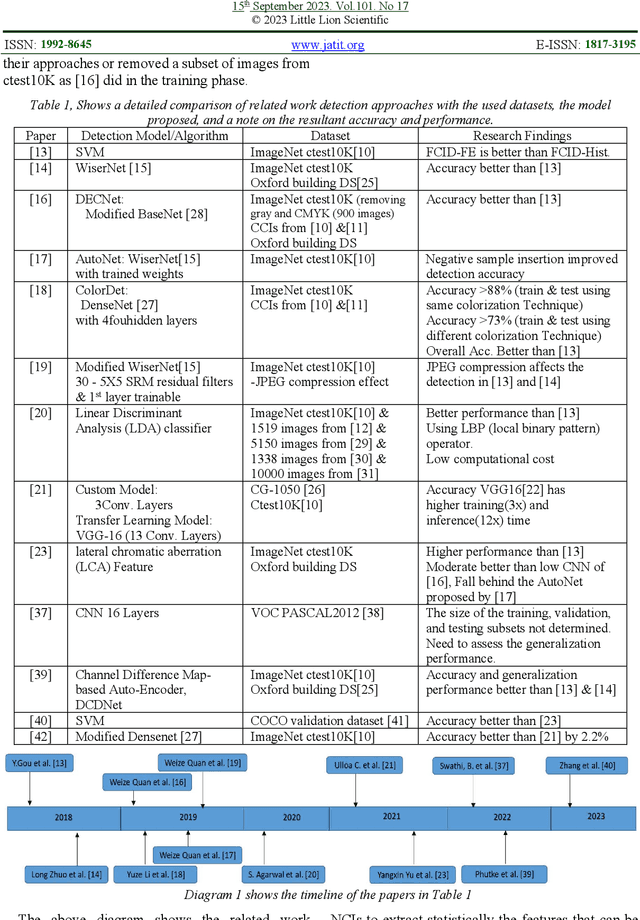
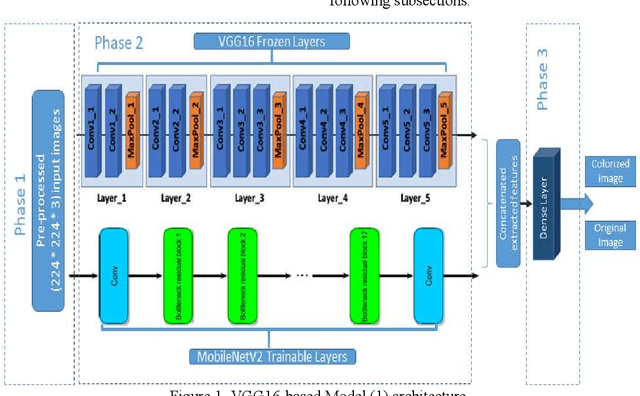
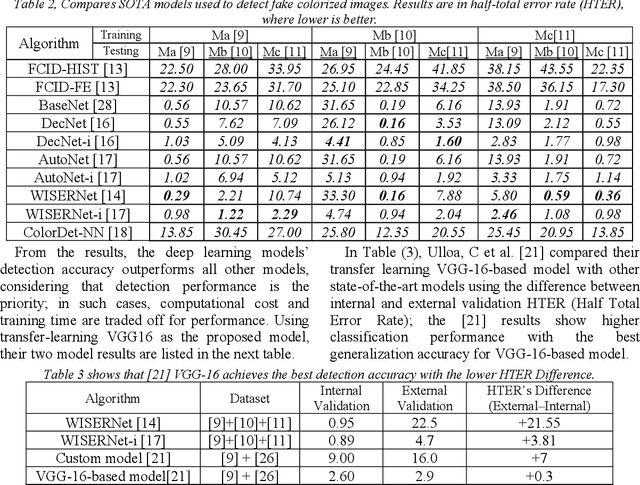
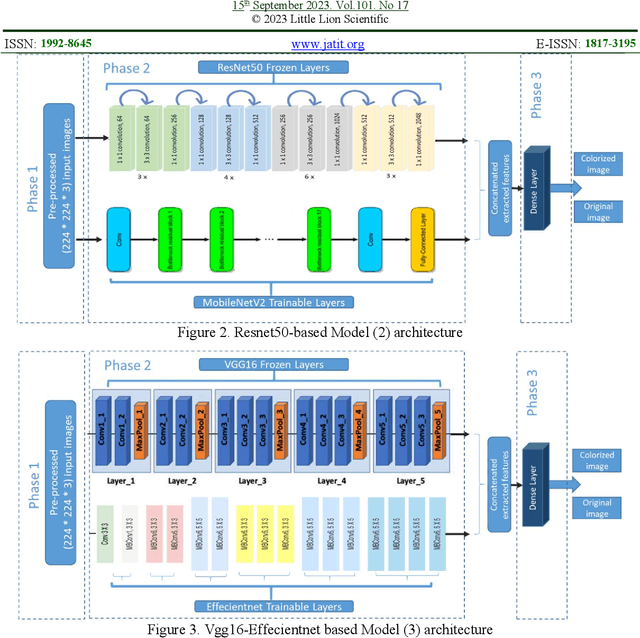
Image colorization is the process of colorizing grayscale images or recoloring an already-color image. This image manipulation can be used for grayscale satellite, medical and historical images making them more expressive. With the help of the increasing computation power of deep learning techniques, the colorization algorithms results are becoming more realistic in such a way that human eyes cannot differentiate between natural and colorized images. However, this poses a potential security concern, as forged or illegally manipulated images can be used illegally. There is a growing need for effective detection methods to distinguish between natural color and computer-colorized images. This paper presents a novel approach that combines the advantages of transfer and ensemble learning approaches to help reduce training time and resource requirements while proposing a model to classify natural color and computer-colorized images. The proposed model uses pre-trained branches VGG16 and Resnet50, along with Mobile Net v2 or Efficientnet feature vectors. The proposed model showed promising results, with accuracy ranging from 94.55% to 99.13% and very low Half Total Error Rate values. The proposed model outperformed existing state-of-the-art models regarding classification performance and generalization capabilities.