 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Process Reward Models
May 11, 2026Process Reward Models (PRMs) are a powerful mechanism for steering large language model reasoning by providing fine-grained, step-level supervision. However, this effectiveness comes at a significant cost: PRMs require expert annotations for every reasoning step, making them costly and difficult to scale. Here, we propose a method for training unsupervised PRMs (uPRM) that requires no human supervision, neither at the level of step-by-step annotations nor through ground-truth verification of final answers. The key idea behind our approach is to define a scoring function, derived from LLM next-token probabilities, that jointly assesses candidate positions of first erroneous steps across a batch of reasoning trajectories. We demonstrate the effectiveness of uPRM across diverse scenarios: (i) uPRM achieves up to 15% absolute accuracy improvements over the LLM-as-a-Judge in identifying first erroneous steps on the ProcessBench dataset; (ii) as a verifier for test-time scaling, uPRM performs comparably to supervised PRMs and outperforms the majority voting baseline by up to 6.9%, and (iii) when used as a reward signal in reinforcement learning, uPRM enables more robust policy optimization throughout training compared to a supervised PRM trained using ground-truth labels. Overall, our results open a path toward scalable reward modeling for complex reasoning tasks.
Large (Vision) Language Models are Unsupervised In-Context Learners
Apr 03, 2025Recent advances in large language and vision-language models have enabled zero-shot inference, allowing models to solve new tasks without task-specific training. Various adaptation techniques such as prompt engineering, In-Context Learning (ICL), and supervised fine-tuning can further enhance the model's performance on a downstream task, but they require substantial manual effort to construct effective prompts or labeled examples. In this work, we introduce a joint inference framework for fully unsupervised adaptation, eliminating the need for manual prompt engineering and labeled examples. Unlike zero-shot inference, which makes independent predictions, the joint inference makes predictions simultaneously for all inputs in a given task. Since direct joint inference involves computationally expensive optimization, we develop efficient approximation techniques, leading to two unsupervised adaptation methods: unsupervised fine-tuning and unsupervised ICL. We demonstrate the effectiveness of our methods across diverse tasks and models, including language-only Llama-3.1 on natural language processing tasks, reasoning-oriented Qwen2.5-Math on grade school math problems, vision-language OpenFlamingo on vision tasks, and the API-only access GPT-4o model on massive multi-discipline tasks. Our experiments demonstrate substantial improvements over the standard zero-shot approach, including 39% absolute improvement on the challenging GSM8K math reasoning dataset. Remarkably, despite being fully unsupervised, our framework often performs on par with supervised approaches that rely on ground truth labels.
Fine-grained Classes and How to Find Them
Jun 16, 2024



In many practical applications, coarse-grained labels are readily available compared to fine-grained labels that reflect subtle differences between classes. However, existing methods cannot leverage coarse labels to infer fine-grained labels in an unsupervised manner. To bridge this gap, we propose FALCON, a method that discovers fine-grained classes from coarsely labeled data without any supervision at the fine-grained level. FALCON simultaneously infers unknown fine-grained classes and underlying relationships between coarse and fine-grained classes. Moreover, FALCON is a modular method that can effectively learn from multiple datasets labeled with different strategies. We evaluate FALCON on eight image classification tasks and a single-cell classification task. FALCON outperforms baselines by a large margin, achieving 22% improvement over the best baseline on the tieredImageNet dataset with over 600 fine-grained classes.
Let Go of Your Labels with Unsupervised Transfer
Jun 11, 2024



Foundation vision-language models have enabled remarkable zero-shot transferability of the pre-trained representations to a wide range of downstream tasks. However, to solve a new task, zero-shot transfer still necessitates human guidance to define visual categories that appear in the data. Here, we show that fully unsupervised transfer emerges when searching for the labeling of a dataset that induces maximal margin classifiers in representation spaces of different foundation models. We present TURTLE, a fully unsupervised method that effectively employs this guiding principle to uncover the underlying labeling of a downstream dataset without any supervision and task-specific representation learning. We evaluate TURTLE on a diverse benchmark suite of 26 datasets and show that it achieves new state-of-the-art unsupervised performance. Furthermore, TURTLE, although being fully unsupervised, outperforms zero-shot transfer baselines on a wide range of datasets. In particular, TURTLE matches the average performance of CLIP zero-shot on 26 datasets by employing the same representation space, spanning a wide range of architectures and model sizes. By guiding the search for the underlying labeling using the representation spaces of two foundation models, TURTLE surpasses zero-shot transfer and unsupervised prompt tuning baselines, demonstrating the surprising power and effectiveness of unsupervised transfer.
The Pursuit of Human Labeling: A New Perspective on Unsupervised Learning
Nov 06, 2023



We present HUME, a simple model-agnostic framework for inferring human labeling of a given dataset without any external supervision. The key insight behind our approach is that classes defined by many human labelings are linearly separable regardless of the representation space used to represent a dataset. HUME utilizes this insight to guide the search over all possible labelings of a dataset to discover an underlying human labeling. We show that the proposed optimization objective is strikingly well-correlated with the ground truth labeling of the dataset. In effect, we only train linear classifiers on top of pretrained representations that remain fixed during training, making our framework compatible with any large pretrained and self-supervised model. Despite its simplicity, HUME outperforms a supervised linear classifier on top of self-supervised representations on the STL-10 dataset by a large margin and achieves comparable performance on the CIFAR-10 dataset. Compared to the existing unsupervised baselines, HUME achieves state-of-the-art performance on four benchmark image classification datasets including the large-scale ImageNet-1000 dataset. Altogether, our work provides a fundamentally new view to tackle unsupervised learning by searching for consistent labelings between different representation spaces.
Leveraging Recursive Gumbel-Max Trick for Approximate Inference in Combinatorial Spaces
Oct 28, 2021
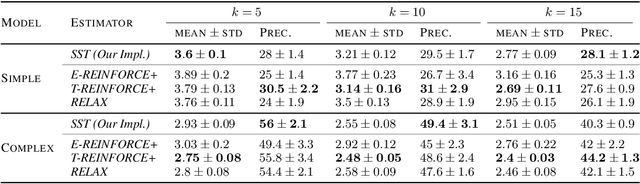
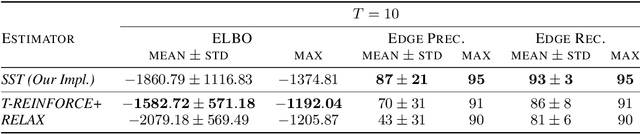
Structured latent variables allow incorporating meaningful prior knowledge into deep learning models. However, learning with such variables remains challenging because of their discrete nature. Nowadays, the standard learning approach is to define a latent variable as a perturbed algorithm output and to use a differentiable surrogate for training. In general, the surrogate puts additional constraints on the model and inevitably leads to biased gradients. To alleviate these shortcomings, we extend the Gumbel-Max trick to define distributions over structured domains. We avoid the differentiable surrogates by leveraging the score function estimators for optimization. In particular, we highlight a family of recursive algorithms with a common feature we call stochastic invariant. The feature allows us to construct reliable gradient estimates and control variates without additional constraints on the model. In our experiments, we consider various structured latent variable models and achieve results competitive with relaxation-based counterparts.
Low-variance Black-box Gradient Estimates for the Plackett-Luce Distribution
Nov 22, 2019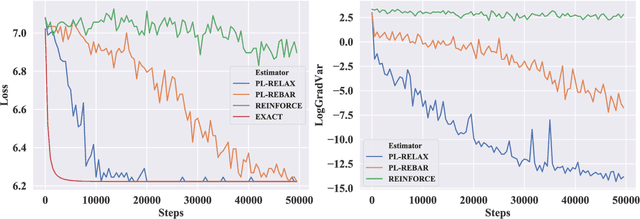
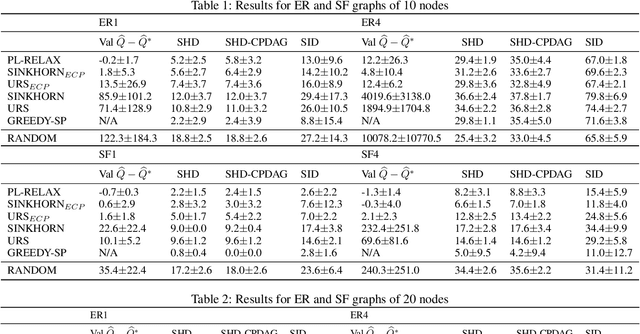
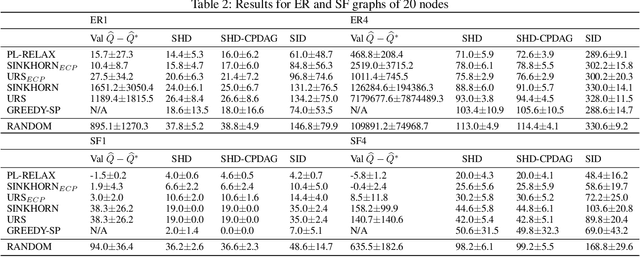
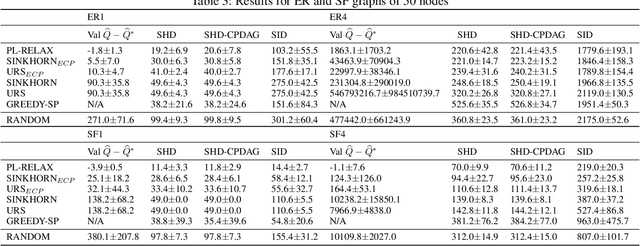
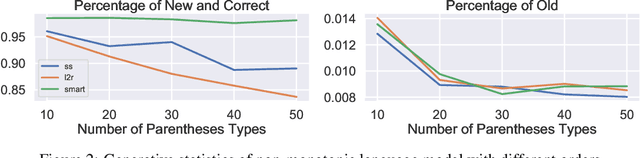
Learning models with discrete latent variables using stochastic gradient descent remains a challenge due to the high variance of gradient estimates. Modern variance reduction techniques mostly consider categorical distributions and have limited applicability when the number of possible outcomes becomes large. In this work, we consider models with latent permutations and propose control variates for the Plackett-Luce distribution. In particular, the control variates allow us to optimize black-box functions over permutations using stochastic gradient descent. To illustrate the approach, we consider a variety of causal structure learning tasks for continuous and discrete data. We show that our method outperforms competitive relaxation-based optimization methods and is also applicable to non-differentiable score functions.
Conditional Generators of Words Definitions
Jun 26, 2018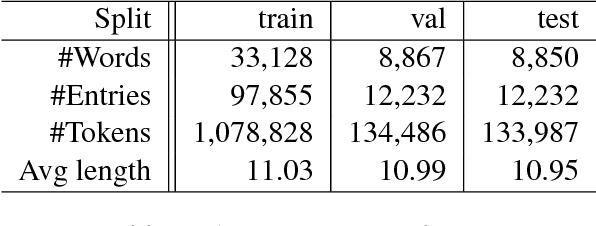
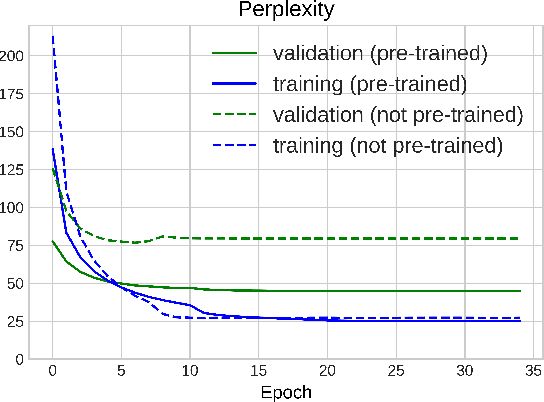
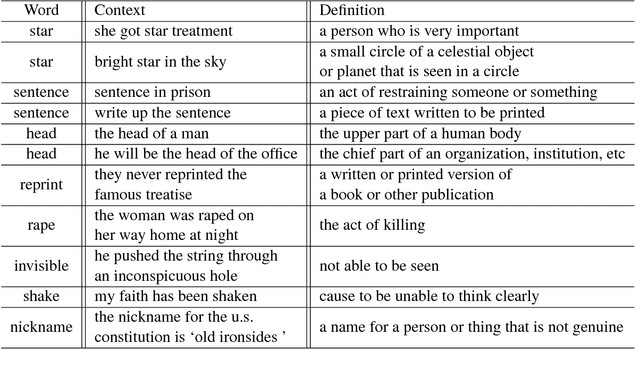
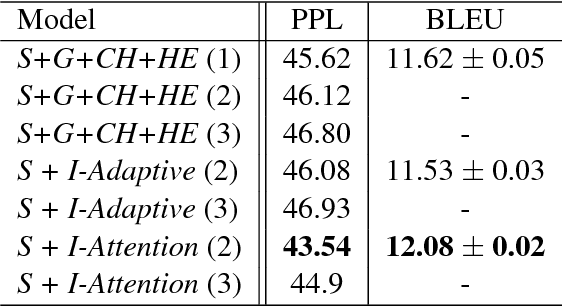
We explore recently introduced definition modeling technique that provided the tool for evaluation of different distributed vector representations of words through modeling dictionary definitions of words. In this work, we study the problem of word ambiguities in definition modeling and propose a possible solution by employing latent variable modeling and soft attention mechanisms. Our quantitative and qualitative evaluation and analysis of the model shows that taking into account words ambiguity and polysemy leads to performance improvement.