 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using Stochastic Gradient Descent to Smooth Nonconvex Functions: Analysis of Implicit Graduated Optimization with Optimal Noise Scheduling
Nov 29, 2023
The graduated optimization approach is a heuristic method for finding globally optimal solutions for nonconvex functions and has been theoretically analyzed in several studies. This paper defines a new family of nonconvex functions for graduated optimization, discusses their sufficient conditions, and provides a convergence analysis of the graduated optimization algorithm for them. It shows that stochastic gradient descent (SGD) with mini-batch stochastic gradients has the effect of smoothing the function, the degree of which is determined by the learning rate and batch size. This finding provides theoretical insights on why large batch sizes fall into sharp local minima, why decaying learning rates and increasing batch sizes are superior to fixed learning rates and batch sizes, and what the optimal learning rate scheduling is. To the best of our knowledge, this is the first paper to provide a theoretical explanation for these aspects. Moreover, a new graduated optimization framework that uses a decaying learning rate and increasing batch size is analyzed and experimental results of image classification that support our theoretical findings are reported.
Manipulation Mask Generator: High-Quality Image Manipulation Mask Generation Method Based on Modified Total Variation Noise Reduction
Oct 23, 2023In artificial intelligence, any model that wants to achieve a good result is inseparable from a large number of high-quality data. It is especially true in the field of tamper detection. This paper proposes a modified total variation noise reduction method to acquire high-quality tampered images. We automatically crawl original and tampered images from the Baidu PS Bar. Baidu PS Bar is a website where net friends post countless tampered images. Subtracting the original image with the tampered image can highlight the tampered area. However, there is also substantial noise on the final print, so these images can't be directly used in the deep learning model. Our modified total variation noise reduction method is aimed at solving this problem. Because a lot of text is slender, it is easy to lose text information after the opening and closing operation. We use MSER (Maximally Stable Extremal Regions) and NMS (Non-maximum Suppression) technology to extract text information. And then use the modified total variation noise reduction technology to process the subtracted image. Finally, we can obtain an image with little noise by adding the image and text information. And the idea also largely retains the text information. Datasets generated in this way can be used in deep learning models, and they will help the model achieve better results.
MAIRA-1: A specialised large multimodal model for radiology report generation
Nov 22, 2023We present a radiology-specific multimodal model for the task for generating radiological reports from chest X-rays (CXRs). Our work builds on the idea that large language model(s) can be equipped with multimodal capabilities through alignment with pre-trained vision encoders. On natural images, this has been shown to allow multimodal models to gain image understanding and description capabilities. Our proposed model (MAIRA-1) leverages a CXR-specific image encoder in conjunction with a fine-tuned large language model based on Vicuna-7B, and text-based data augmentation, to produce reports with state-of-the-art quality. In particular, MAIRA-1 significantly improves on the radiologist-aligned RadCliQ metric and across all lexical metrics considered. Manual review of model outputs demonstrates promising fluency and accuracy of generated reports while uncovering failure modes not captured by existing evaluation practices. More information and resources can be found on the project website: https://aka.ms/maira.
Panda or not Panda? Understanding Adversarial Attacks with Interactive Visualization
Nov 22, 2023Adversarial machine learning (AML) studies attacks that can fool machine learning algorithms into generating incorrect outcomes as well as the defenses against worst-case attacks to strengthen model robustness. Specifically for image classification, it is challenging to understand adversarial attacks due to their use of subtle perturbations that are not human-interpretable, as well as the variability of attack impacts influenced by diverse methodologies, instance differences, and model architectures. Through a design study with AML learners and teachers, we introduce AdvEx, a multi-level interactive visualization system that comprehensively presents the properties and impacts of evasion attacks on different image classifiers for novice AML learners. We quantitatively and qualitatively assessed AdvEx in a two-part evaluation including user studies and expert interviews. Our results show that AdvEx is not only highly effective as a visualization tool for understanding AML mechanisms, but also provides an engaging and enjoyable learning experience, thus demonstrating its overall benefits for AML learners.
Guided Flows for Generative Modeling and Decision Making
Nov 22, 2023Classifier-free guidance is a key component for improving the performance of conditional generative models for many downstream tasks. It drastically improves the quality of samples produced, but has so far only been used for diffusion models. Flow Matching (FM), an alternative simulation-free approach, trains Continuous Normalizing Flows (CNFs) based on regressing vector fields. It remains an open question whether classifier-free guidance can be performed for Flow Matching models, and to what extent does it improve performance. In this paper, we explore the usage of Guided Flows for a variety of downstream applications involving conditional image generation, speech synthesis, and reinforcement learning. In particular, we are the first to apply flow models to the offline reinforcement learning setting. We also show that Guided Flows significantly improves the sample quality in image generation and zero-shot text-to-speech synthesis, and can make use of drastically low amounts of computation without affecting the agent's overall performance.
PixArt-$α$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Oct 16, 2023

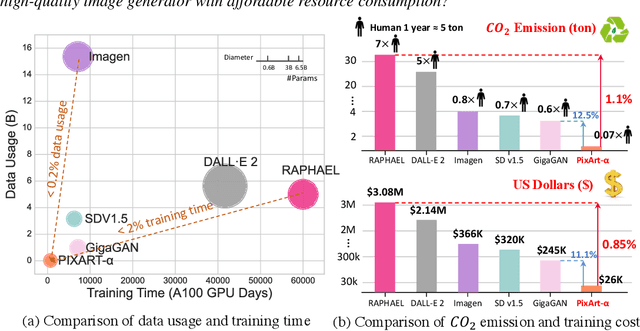
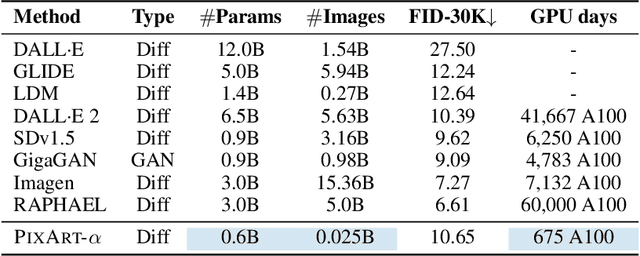
The most advanced text-to-image (T2I) models require significant training costs (e.g., millions of GPU hours), seriously hindering the fundamental innovation for the AIGC community while increasing CO2 emissions. This paper introduces PIXART-$\alpha$, a Transformer-based T2I diffusion model whose image generation quality is competitive with state-of-the-art image generators (e.g., Imagen, SDXL, and even Midjourney), reaching near-commercial application standards. Additionally, it supports high-resolution image synthesis up to 1024px resolution with low training cost, as shown in Figure 1 and 2. To achieve this goal, three core designs are proposed: (1) Training strategy decomposition: We devise three distinct training steps that separately optimize pixel dependency, text-image alignment, and image aesthetic quality; (2) Efficient T2I Transformer: We incorporate cross-attention modules into Diffusion Transformer (DiT) to inject text conditions and streamline the computation-intensive class-condition branch; (3) High-informative data: We emphasize the significance of concept density in text-image pairs and leverage a large Vision-Language model to auto-label dense pseudo-captions to assist text-image alignment learning. As a result, PIXART-$\alpha$'s training speed markedly surpasses existing large-scale T2I models, e.g., PIXART-$\alpha$ only takes 10.8% of Stable Diffusion v1.5's training time (675 vs. 6,250 A100 GPU days), saving nearly \$300,000 (\$26,000 vs. \$320,000) and reducing 90% CO2 emissions. Moreover, compared with a larger SOTA model, RAPHAEL, our training cost is merely 1%. Extensive experiments demonstrate that PIXART-$\alpha$ excels in image quality, artistry, and semantic control. We hope PIXART-$\alpha$ will provide new insights to the AIGC community and startups to accelerate building their own high-quality yet low-cost generative models from scratch.
MAM-E: Mammographic synthetic image generation with diffusion models
Nov 16, 2023Generative models are used as an alternative data augmentation technique to alleviate the data scarcity problem faced in the medical imaging field. Diffusion models have gathered special attention due to their innovative generation approach, the high quality of the generated images and their relatively less complex training process compared with Generative Adversarial Networks. Still, the implementation of such models in the medical domain remains at early stages. In this work, we propose exploring the use of diffusion models for the generation of high quality full-field digital mammograms using state-of-the-art conditional diffusion pipelines. Additionally, we propose using stable diffusion models for the inpainting of synthetic lesions on healthy mammograms. We introduce MAM-E, a pipeline of generative models for high quality mammography synthesis controlled by a text prompt and capable of generating synthetic lesions on specific regions of the breast. Finally, we provide quantitative and qualitative assessment of the generated images and easy-to-use graphical user interfaces for mammography synthesis.
From Denoising Training to Test-Time Adaptation: Enhancing Domain Generalization for Medical Image Segmentation
Nov 03, 2023In medical image segmentation, domain generalization poses a significant challenge due to domain shifts caused by variations in data acquisition devices and other factors. These shifts are particularly pronounced in the most common scenario, which involves only single-source domain data due to privacy concerns. To address this, we draw inspiration from the self-supervised learning paradigm that effectively discourages overfitting to the source domain. We propose the Denoising Y-Net (DeY-Net), a novel approach incorporating an auxiliary denoising decoder into the basic U-Net architecture. The auxiliary decoder aims to perform denoising training, augmenting the domain-invariant representation that facilitates domain generalization. Furthermore, this paradigm provides the potential to utilize unlabeled data. Building upon denoising training, we propose Denoising Test Time Adaptation (DeTTA) that further: (i) adapts the model to the target domain in a sample-wise manner, and (ii) adapts to the noise-corrupted input. Extensive experiments conducted on widely-adopted liver segmentation benchmarks demonstrate significant domain generalization improvements over our baseline and state-of-the-art results compared to other methods. Code is available at https://github.com/WenRuxue/DeTTA.
TeG-DG: Textually Guided Domain Generalization for Face Anti-Spoofing
Nov 30, 2023Enhancing the domain generalization performance of Face Anti-Spoofing (FAS) techniques has emerged as a research focus. Existing methods are dedicated to extracting domain-invariant features from various training domains. Despite the promising performance, the extracted features inevitably contain residual style feature bias (e.g., illumination, capture device), resulting in inferior generalization performance. In this paper, we propose an alternative and effective solution, the Textually Guided Domain Generalization (TeG-DG) framework, which can effectively leverage text information for cross-domain alignment. Our core insight is that text, as a more abstract and universal form of expression, can capture the commonalities and essential characteristics across various attacks, bridging the gap between different image domains. Contrary to existing vision-language models, the proposed framework is elaborately designed to enhance the domain generalization ability of the FAS task. Concretely, we first design a Hierarchical Attention Fusion (HAF) module to enable adaptive aggregation of visual features at different levels; Then, a Textual-Enhanced Visual Discriminator (TEVD) is proposed for not only better alignment between the two modalities but also to regularize the classifier with unbiased text features. TeG-DG significantly outperforms previous approaches, especially in situations with extremely limited source domain data (~14% and ~12% improvements on HTER and AUC respectively), showcasing impressive few-shot performance.
SPiC-E : Structural Priors in 3D Diffusion Models using Cross-Entity Attention
Nov 30, 2023We are witnessing rapid progress in automatically generating and manipulating 3D assets due to the availability of pretrained text-image diffusion models. However, time-consuming optimization procedures are required for synthesizing each sample, hindering their potential for democratizing 3D content creation. Conversely, 3D diffusion models now train on million-scale 3D datasets, yielding high-quality text-conditional 3D samples within seconds. In this work, we present SPiC-E - a neural network that adds structural guidance to 3D diffusion models, extending their usage beyond text-conditional generation. At its core, our framework introduces a cross-entity attention mechanism that allows for multiple entities (in particular, paired input and guidance 3D shapes) to interact via their internal representations within the denoising network. We utilize this mechanism for learning task-specific structural priors in 3D diffusion models from auxiliary guidance shapes. We show that our approach supports a variety of applications, including 3D stylization, semantic shape editing and text-conditional abstraction-to-3D, which transforms primitive-based abstractions into highly-expressive shapes. Extensive experiments demonstrate that SPiC-E achieves SOTA performance over these tasks while often being considerably faster than alternative methods. Importantly, this is accomplished without tailoring our approach for any specific task.