 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disentangling Structure and Appearance in ViT Feature Space
Nov 20, 2023


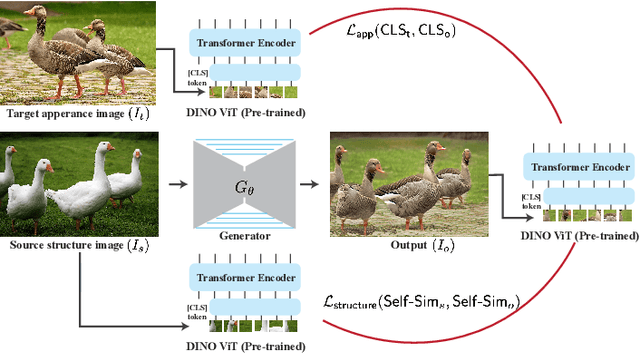
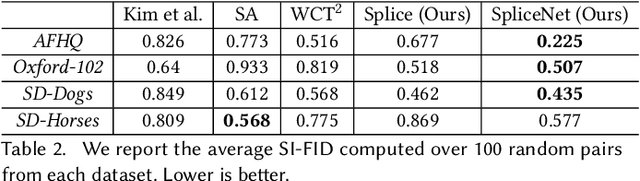
We present a method for semantically transferring the visual appearance of one natural image to another. Specifically, our goal is to generate an image in which objects in a source structure image are "painted" with the visual appearance of their semantically related objects in a target appearance image. To integrate semantic information into our framework, our key idea is to leverage a pre-trained and fixed Vision Transformer (ViT) model. Specifically, we derive novel disentangled representations of structure and appearance extracted from deep ViT features. We then establish an objective function that splices the desired structure and appearance representations, interweaving them together in the space of ViT features. Based on our objective function, we propose two frameworks of semantic appearance transfer -- "Splice", which works by training a generator on a single and arbitrary pair of structure-appearance images, and "SpliceNet", a feed-forward real-time appearance transfer model trained on a dataset of images from a specific domain. Our frameworks do not involve adversarial training, nor do they require any additional input information such as semantic segmentation or correspondences. We demonstrate high-resolution results on a variety of in-the-wild image pairs, under significant variations in the number of objects, pose, and appearance. Code and supplementary material are available in our project page: splice-vit.github.io.
EDiffSR: An Efficient Diffusion Probabilistic Model for Remote Sensing Image Super-Resolution
Oct 30, 2023Recently, convolutional networks have achieved remarkable development in remote sensing image Super-Resoltuion (SR) by minimizing the regression objectives, e.g., MSE loss. However, despite achieving impressive performance, these methods often suffer from poor visual quality with over-smooth issues. Generative adversarial networks have the potential to infer intricate details, but they are easy to collapse, resulting in undesirable artifacts. To mitigate these issues, in this paper, we first introduce Diffusion Probabilistic Model (DPM) for efficient remote sensing image SR, dubbed EDiffSR. EDiffSR is easy to train and maintains the merits of DPM in generating perceptual-pleasant images. Specifically, different from previous works using heavy UNet for noise prediction, we develop an Efficient Activation Network (EANet) to achieve favorable noise prediction performance by simplified channel attention and simple gate operation, which dramatically reduces the computational budget. Moreover, to introduce more valuable prior knowledge into the proposed EDiffSR, a practical Conditional Prior Enhancement Module (CPEM) is developed to help extract an enriched condition. Unlike most DPM-based SR models that directly generate conditions by amplifying LR images, the proposed CPEM helps to retain more informative cues for accurate SR. Extensive experiments on four remote sensing datasets demonstrate that EDiffSR can restore visual-pleasant images on simulated and real-world remote sensing images, both quantitatively and qualitatively. The code of EDiffSR will be available at https://github.com/XY-boy/EDiffSR
Attention Modules Improve Image-Level Anomaly Detection for Industrial Inspection: A DifferNet Case Study
Nov 07, 2023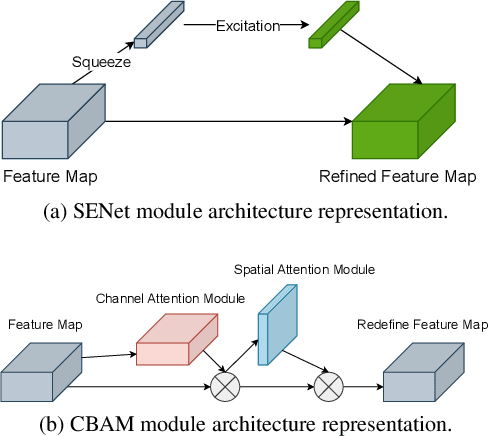
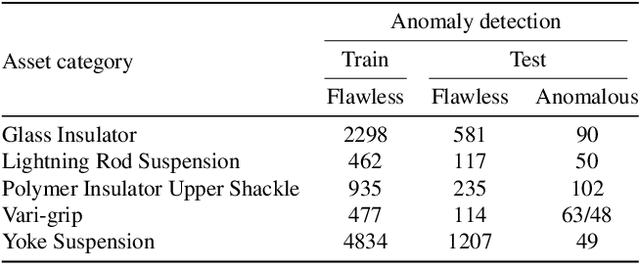
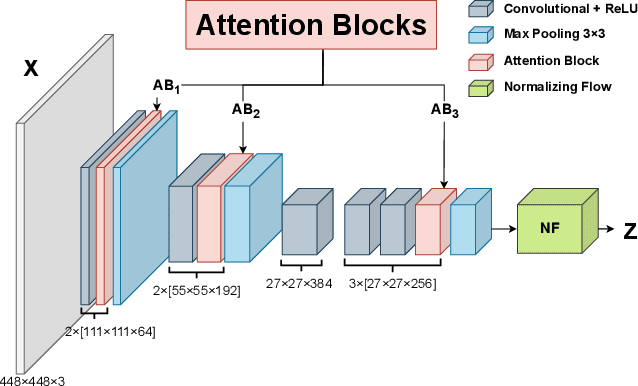
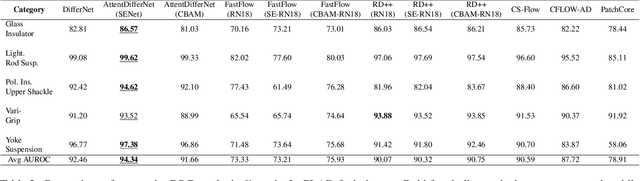
Within (semi-)automated visual industrial inspection, learning-based approaches for assessing visual defects, including deep neural networks, enable the processing of otherwise small defect patterns in pixel size on high-resolution imagery. The emergence of these often rarely occurring defect patterns explains the general need for labeled data corpora. To alleviate this issue and advance the current state of the art in unsupervised visual inspection, this work proposes a DifferNet-based solution enhanced with attention modules: AttentDifferNet. It improves image-level detection and classification capabilities on three visual anomaly detection datasets for industrial inspection: InsPLAD-fault, MVTec AD, and Semiconductor Wafer. In comparison to the state of the art, AttentDifferNet achieves improved results, which are, in turn, highlighted throughout our quali-quantitative study. Our quantitative evaluation shows an average improvement - compared to DifferNet - of 1.77 +/- 0.25 percentage points in overall AUROC considering all three datasets, reaching SOTA results in InsPLAD-fault, an industrial inspection in-the-wild dataset. As our variants to AttentDifferNet show great prospects in the context of currently investigated approaches, a baseline is formulated, emphasizing the importance of attention for industrial anomaly detection both in the wild and in controlled environments.
Mitigating Over-smoothing in Transformers via Regularized Nonlocal Functionals
Dec 01, 2023Transformers have achieved remarkable success in a wide range of natural language processing and computer vision applications. However, the representation capacity of a deep transformer model is degraded due to the over-smoothing issue in which the token representations become identical when the model's depth grows. In this work, we show that self-attention layers in transformers minimize a functional which promotes smoothness, thereby causing token uniformity. We then propose a novel regularizer that penalizes the norm of the difference between the smooth output tokens from self-attention and the input tokens to preserve the fidelity of the tokens. Minimizing the resulting regularized energy functional, we derive the Neural Transformer with a Regularized Nonlocal Functional (NeuTRENO), a novel class of transformer models that can mitigate the over-smoothing issue. We empirically demonstrate the advantages of NeuTRENO over the baseline transformers and state-of-the-art methods in reducing the over-smoothing of token representations on various practical tasks, including object classification, image segmentation, and language modeling.
Zero-Shot Video Question Answering with Procedural Programs
Dec 01, 2023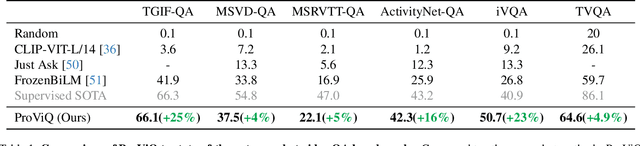
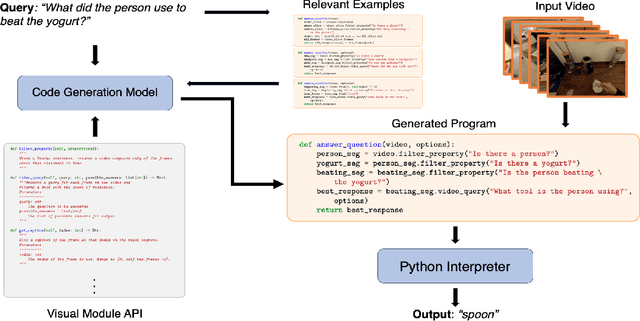
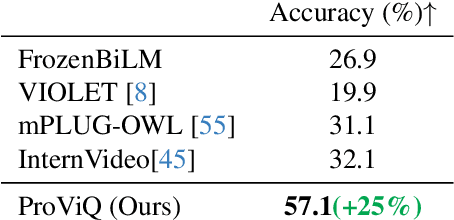
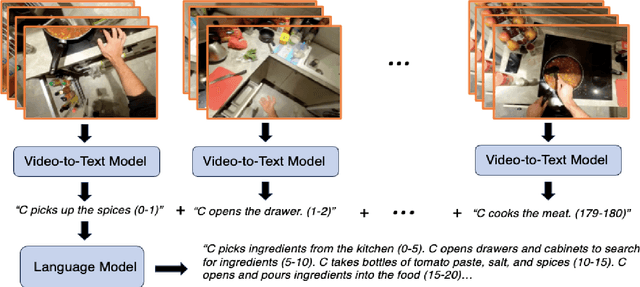
We propose to answer zero-shot questions about videos by generating short procedural programs that derive a final answer from solving a sequence of visual subtasks. We present Procedural Video Querying (ProViQ), which uses a large language model to generate such programs from an input question and an API of visual modules in the prompt, then executes them to obtain the output. Recent similar procedural approaches have proven successful for image question answering, but videos remain challenging: we provide ProViQ with modules intended for video understanding, allowing it to generalize to a wide variety of videos. This code generation framework additionally enables ProViQ to perform other video tasks in addition to question answering, such as multi-object tracking or basic video editing. ProViQ achieves state-of-the-art results on a diverse range of benchmarks, with improvements of up to 25% on short, long, open-ended, and multimodal video question-answering datasets. Our project page is at https://rccchoudhury.github.io/proviq2023.
Adversarial Score Distillation: When score distillation meets GAN
Dec 01, 2023Existing score distillation methods are sensitive to classifier-free guidance (CFG) scale: manifested as over-smoothness or instability at small CFG scales, while over-saturation at large ones. To explain and analyze these issues, we revisit the derivation of Score Distillation Sampling (SDS) and decipher existing score distillation with the Wasserstein Generative Adversarial Network (WGAN) paradigm. With the WGAN paradigm, we find that existing score distillation either employs a fixed sub-optimal discriminator or conducts incomplete discriminator optimization, resulting in the scale-sensitive issue. We propose the Adversarial Score Distillation (ASD), which maintains an optimizable discriminator and updates it using the complete optimization objective. Experiments show that the proposed ASD performs favorably in 2D distillation and text-to-3D tasks against existing methods. Furthermore, to explore the generalization ability of our WGAN paradigm, we extend ASD to the image editing task, which achieves competitive results. The project page and code are at https://github.com/2y7c3/ASD.
EvE: Exploiting Generative Priors for Radiance Field Enrichment
Dec 01, 2023Modeling large-scale scenes from unconstrained image collections in-the-wild has proven to be a major challenge in computer vision. Existing methods tackling in-the-wild neural rendering operate in a closed-world setting, where knowledge is limited to a scene's captured images within a training set. We propose EvE, which is, to the best of our knowledge, the first method leveraging generative priors to improve in-the-wild scene modeling. We employ pre-trained generative networks to enrich K-Planes representations with extrinsic knowledge. To this end, we define an alternating training procedure to conduct optimization guidance of K-Planes trained on the training set. We carry out extensive experiments and verify the merit of our method on synthetic data as well as real tourism photo collections. EvE enhances rendered scenes with richer details and outperforms the state of the art on the task of novel view synthesis in-the-wild. Our project page can be found at https://eve-nvs.github.io .
RIS-Based On-the-Air Semantic Communications -- a Diffractional Deep Neural Network Approach
Dec 01, 2023Semantic communication has gained significant attention recently due to its advantages in achieving higher transmission efficiency by focusing on semantic information instead of bit-level information. However, current AI-based semantic communication methods require digital hardware for implementation. With the rapid advancement on reconfigurable intelligence surfaces (RISs), a new approach called on-the-air diffractional deep neural networks (D$^2$NN) can be utilized to enable semantic communications on the wave domain. This paper proposes a new paradigm of RIS-based on-the-air semantic communications, where the computational process occurs inherently as wireless signals pass through RISs. We present the system model and discuss the data and control flows of this scheme, followed by a performance analysis using image transmission as an example. In comparison to traditional hardware-based approaches, RIS-based semantic communications offer appealing features, such as light-speed computation, low computational power requirements, and the ability to handle multiple tasks simultaneously.
CustomNet: Zero-shot Object Customization with Variable-Viewpoints in Text-to-Image Diffusion Models
Oct 30, 2023Incorporating a customized object into image generation presents an attractive feature in text-to-image generation. However, existing optimization-based and encoder-based methods are hindered by drawbacks such as time-consuming optimization, insufficient identity preservation, and a prevalent copy-pasting effect. To overcome these limitations, we introduce CustomNet, a novel object customization approach that explicitly incorporates 3D novel view synthesis capabilities into the object customization process. This integration facilitates the adjustment of spatial position relationships and viewpoints, yielding diverse outputs while effectively preserving object identity. Moreover, we introduce delicate designs to enable location control and flexible background control through textual descriptions or specific user-defined images, overcoming the limitations of existing 3D novel view synthesis methods. We further leverage a dataset construction pipeline that can better handle real-world objects and complex backgrounds. Equipped with these designs, our method facilitates zero-shot object customization without test-time optimization, offering simultaneous control over the viewpoints, location, and background. As a result, our CustomNet ensures enhanced identity preservation and generates diverse, harmonious outputs.
LICO: Explainable Models with Language-Image Consistency
Oct 15, 2023Interpreting the decisions of deep learning models has been actively studied since the explosion of deep neural networks. One of the most convincing interpretation approaches is salience-based visual interpretation, such as Grad-CAM, where the generation of attention maps depends merely on categorical labels. Although existing interpretation methods can provide explainable decision clues, they often yield partial correspondence between image and saliency maps due to the limited discriminative information from one-hot labels. This paper develops a Language-Image COnsistency model for explainable image classification, termed LICO, by correlating learnable linguistic prompts with corresponding visual features in a coarse-to-fine manner. Specifically, we first establish a coarse global manifold structure alignment by minimizing the distance between the distributions of image and language features. We then achieve fine-grained saliency maps by applying optimal transport (OT) theory to assign local feature maps with class-specific prompts. Extensive experimental results on eight benchmark datasets demonstrate that the proposed LICO achieves a significant improvement in generating more explainable attention maps in conjunction with existing interpretation methods such as Grad-CAM. Remarkably, LICO improves the classification performance of existing models without introducing any computational overhead during inference. Source code is made available at https://github.com/ymLeiFDU/LICO.