 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recaptured Raw Screen Image and Video Demoiréing via Channel and Spatial Modulations
Oct 31, 2023
Capturing screen contents by smartphone cameras has become a common way for information sharing. However, these images and videos are often degraded by moir\'e patterns, which are caused by frequency aliasing between the camera filter array and digital display grids. We observe that the moir\'e patterns in raw domain is simpler than those in sRGB domain, and the moir\'e patterns in raw color channels have different properties. Therefore, we propose an image and video demoir\'eing network tailored for raw inputs. We introduce a color-separated feature branch, and it is fused with the traditional feature-mixed branch via channel and spatial modulations. Specifically, the channel modulation utilizes modulated color-separated features to enhance the color-mixed features. The spatial modulation utilizes the feature with large receptive field to modulate the feature with small receptive field. In addition, we build the first well-aligned raw video demoir\'eing (RawVDemoir\'e) dataset and propose an efficient temporal alignment method by inserting alternating patterns. Experiments demonstrate that our method achieves state-of-the-art performance for both image and video demori\'eing. We have released the code and dataset in https://github.com/tju-chengyijia/VD_raw.
Towards an accurate and generalizable multiple sclerosis lesion segmentation model using self-ensembled lesion fusion
Dec 03, 2023Automatic multiple sclerosis (MS) lesion segmentation using multi-contrast magnetic resonance (MR) images provides improved efficiency and reproducibility compared to manual delineation. Current state-of-the-art automatic MS lesion segmentation methods utilize modified U-Net-like architectures. However, in the literature, dedicated architecture modifications were always required to maximize their performance. In addition, the best-performing methods have not proven to be generalizable to diverse test datasets with contrast variations and image artifacts. In this work, we developed an accurate and generalizable MS lesion segmentation model using the well-known U-Net architecture without further modification. A novel test-time self-ensembled lesion fusion strategy is proposed that not only achieved the best performance using the ISBI 2015 MS segmentation challenge data but also demonstrated robustness across various self-ensemble parameter choices. Moreover, equipped with instance normalization rather than batch normalization widely used in literature, the model trained on the ISBI challenge data generalized well on clinical test datasets from different scanners.
Generative Rendering: Controllable 4D-Guided Video Generation with 2D Diffusion Models
Dec 03, 2023Traditional 3D content creation tools empower users to bring their imagination to life by giving them direct control over a scene's geometry, appearance, motion, and camera path. Creating computer-generated videos, however, is a tedious manual process, which can be automated by emerging text-to-video diffusion models. Despite great promise, video diffusion models are difficult to control, hindering a user to apply their own creativity rather than amplifying it. To address this challenge, we present a novel approach that combines the controllability of dynamic 3D meshes with the expressivity and editability of emerging diffusion models. For this purpose, our approach takes an animated, low-fidelity rendered mesh as input and injects the ground truth correspondence information obtained from the dynamic mesh into various stages of a pre-trained text-to-image generation model to output high-quality and temporally consistent frames. We demonstrate our approach on various examples where motion can be obtained by animating rigged assets or changing the camera path.
Perceptual Assessment and Optimization of High Dynamic Range Image Rendering
Oct 23, 2023High dynamic range (HDR) imaging has gained increasing popularity for its ability to faithfully reproduce the luminance levels in natural scenes. Accordingly, HDR image quality assessment (IQA) is crucial but has been superficially treated. The majority of existing IQA models are developed for and calibrated against low dynamic range (LDR) images, which have been shown to be poorly correlated with human perception of HDR image quality. In this work, we propose a family of HDR IQA models by transferring the recent advances in LDR IQA. The key step in our approach is to specify a simple inverse display model that decomposes an HDR image to a set of LDR images with different exposures, which will be assessed by existing LDR quality models. The local quality scores of each exposure are then aggregated with the help of a simple well-exposedness measure into a global quality score for each exposure, which will be further weighted across exposures to obtain the overall quality score. When assessing LDR images, the proposed HDR quality models reduce gracefully to the original LDR ones with the same performance. Experiments on four human-rated HDR image datasets demonstrate that our HDR quality models are consistently better than existing IQA methods, including the HDR-VDP family. Moreover, we demonstrate their strengths in perceptual optimization of HDR novel view synthesis.
Learning Real-World Image De-Weathering with Imperfect Supervision
Oct 23, 2023Real-world image de-weathering aims at removing various undesirable weather-related artifacts. Owing to the impossibility of capturing image pairs concurrently, existing real-world de-weathering datasets often exhibit inconsistent illumination, position, and textures between the ground-truth images and the input degraded images, resulting in imperfect supervision. Such non-ideal supervision negatively affects the training process of learning-based de-weathering methods. In this work, we attempt to address the problem with a unified solution for various inconsistencies. Specifically, inspired by information bottleneck theory, we first develop a Consistent Label Constructor (CLC) to generate a pseudo-label as consistent as possible with the input degraded image while removing most weather-related degradations. In particular, multiple adjacent frames of the current input are also fed into CLC to enhance the pseudo-label. Then we combine the original imperfect labels and pseudo-labels to jointly supervise the de-weathering model by the proposed Information Allocation Strategy (IAS). During testing, only the de-weathering model is used for inference. Experiments on two real-world de-weathering datasets show that our method helps existing de-weathering models achieve better performance. Codes are available at https://github.com/1180300419/imperfect-deweathering.
G-CASCADE: Efficient Cascaded Graph Convolutional Decoding for 2D Medical Image Segmentation
Oct 24, 2023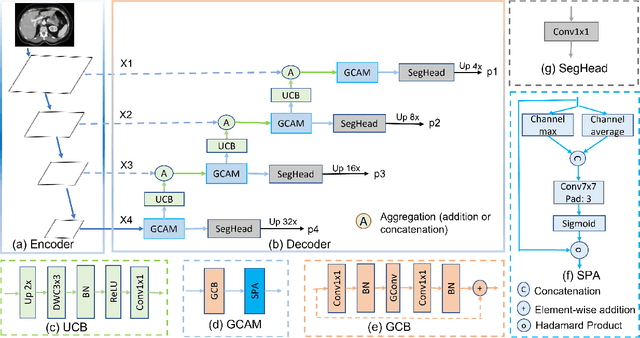
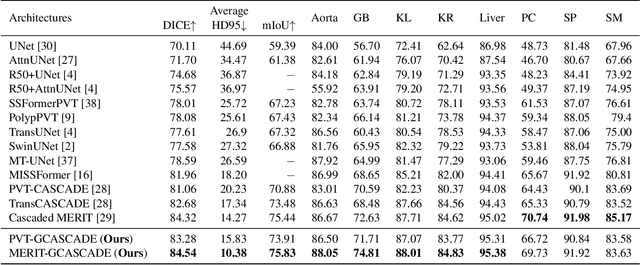
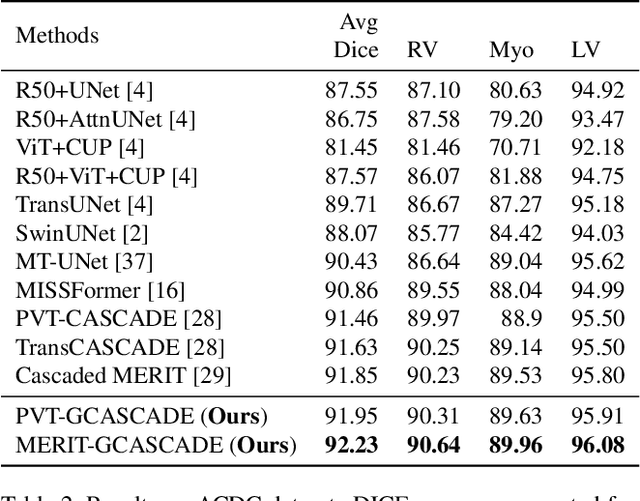
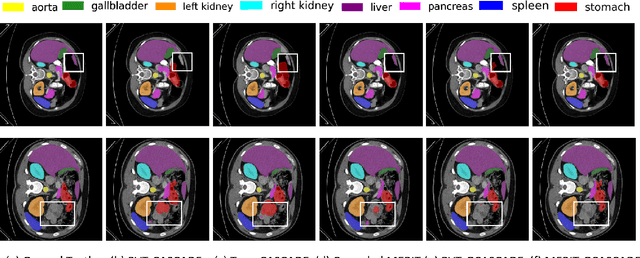
In recent years, medical image segmentation has become an important application in the field of computer-aided diagnosis. In this paper, we are the first to propose a new graph convolution-based decoder namely, Cascaded Graph Convolutional Attention Decoder (G-CASCADE), for 2D medical image segmentation. G-CASCADE progressively refines multi-stage feature maps generated by hierarchical transformer encoders with an efficient graph convolution block. The encoder utilizes the self-attention mechanism to capture long-range dependencies, while the decoder refines the feature maps preserving long-range information due to the global receptive fields of the graph convolution block. Rigorous evaluations of our decoder with multiple transformer encoders on five medical image segmentation tasks (i.e., Abdomen organs, Cardiac organs, Polyp lesions, Skin lesions, and Retinal vessels) show that our model outperforms other state-of-the-art (SOTA) methods. We also demonstrate that our decoder achieves better DICE scores than the SOTA CASCADE decoder with 80.8% fewer parameters and 82.3% fewer FLOPs. Our decoder can easily be used with other hierarchical encoders for general-purpose semantic and medical image segmentation tasks.
BiomedJourney: Counterfactual Biomedical Image Generation by Instruction-Learning from Multimodal Patient Journeys
Oct 18, 2023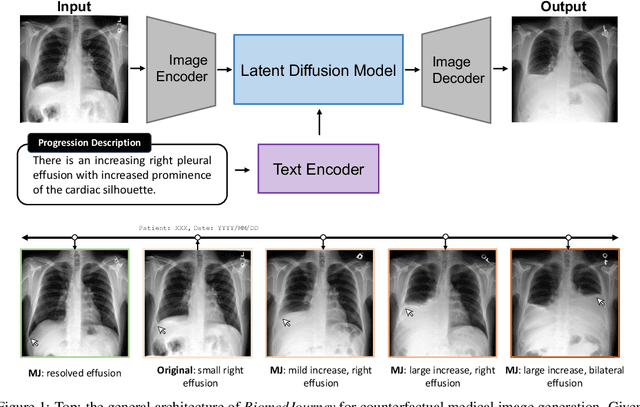
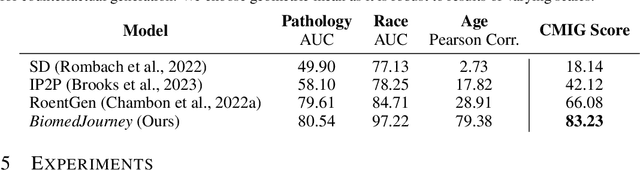
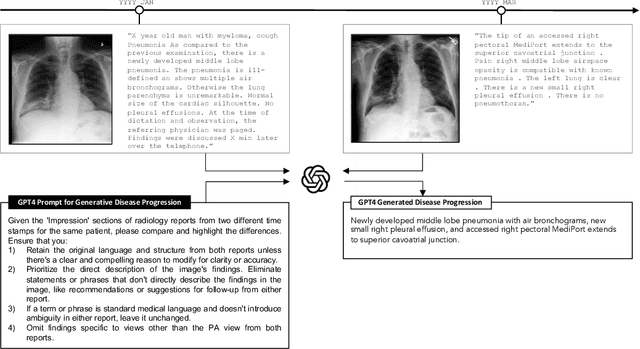
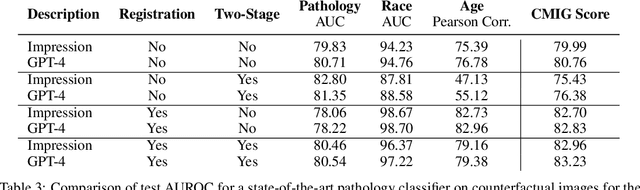
Rapid progress has been made in instruction-learning for image editing with natural-language instruction, as exemplified by InstructPix2Pix. In biomedicine, such methods can be applied to counterfactual image generation, which helps differentiate causal structure from spurious correlation and facilitate robust image interpretation for disease progression modeling. However, generic image-editing models are ill-suited for the biomedical domain, and counterfactual biomedical image generation is largely underexplored. In this paper, we present BiomedJourney, a novel method for counterfactual biomedical image generation by instruction-learning from multimodal patient journeys. Given a patient with two biomedical images taken at different time points, we use GPT-4 to process the corresponding imaging reports and generate a natural language description of disease progression. The resulting triples (prior image, progression description, new image) are then used to train a latent diffusion model for counterfactual biomedical image generation. Given the relative scarcity of image time series data, we introduce a two-stage curriculum that first pretrains the denoising network using the much more abundant single image-report pairs (with dummy prior image), and then continues training using the counterfactual triples. Experiments using the standard MIMIC-CXR dataset demonstrate the promise of our method. In a comprehensive battery of tests on counterfactual medical image generation, BiomedJourney substantially outperforms prior state-of-the-art methods in instruction image editing and medical image generation such as InstructPix2Pix and RoentGen. To facilitate future study in counterfactual medical generation, we plan to release our instruction-learning code and pretrained models.
DyRA: Dynamic Resolution Adjustment for Scale-robust Object Detection
Nov 28, 2023In object detection, achieving constant accuracy is challenging due to the variability of object sizes. One possible solution to this problem is to optimize the input resolution, known as a multi-resolution strategy. Previous approaches for optimizing resolution are often based on pre-defined resolutions or a dynamic neural network, but there is a lack of study for run-time resolution optimization for existing architecture. In this paper, we propose an adaptive resolution scaling network called DyRA, which comprises convolutions and transformer encoder blocks, for existing detectors. Our DyRA returns a scale factor from an input image, which enables instance-specific scaling. This network is jointly trained with detectors with specially designed loss functions, namely ParetoScaleLoss and BalanceLoss. The ParetoScaleLoss produces an adaptive scale factor from the image, while the BalanceLoss optimizes the scale factor according to localization power for the dataset. The loss function is designed to minimize accuracy drop about the contrasting objective of small and large objects. Our experiments on COCO, RetinaNet, Faster-RCNN, FCOS, and Mask-RCNN achieved 1.3%, 1.1%, 1.3%, and 0.8% accuracy improvement than a multi-resolution baseline with solely resolution adjustment. The code is available at https://github.com/DaEunFullGrace/DyRA.git.
Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
Nov 28, 2023Multimodal large language models have made significant advancements in recent years, yet they still suffer from a common issue known as the "hallucination problem" where the models generate textual descriptions that contain inaccurate or non-existent content from the image. To address this issue, this paper introduces a novel strategy: Hallucination-Aware Direct Preference Optimization (HA-DPO). Our approach treats the hallucination problem as a unique preference selection issue, where the model is trained to favor the non-hallucinating response when presented with two responses of the same image (one accurate and one hallucinating). This paper also presents an efficient process for constructing hallucination sample pairs to ensure high-quality, style-consistent pairs for stable HA-DPO training. We applied this strategy to two mainstream multimodal models, and the results showed a significant reduction in the hallucination problem and an enhancement in the models' generalization capabilities. With HA-DPO, the MiniGPT-4 model demonstrates significant advancements: POPE accuracy increases from 51.13% to 85.66% (34.5% absolute improvement), and the MME score escalates from 968.58 to 1365.76 (41% relative improvement). The code, models, and datasets will be made publicly available.
H-Packer: Holographic Rotationally Equivariant Convolutional Neural Network for Protein Side-Chain Packing
Nov 28, 2023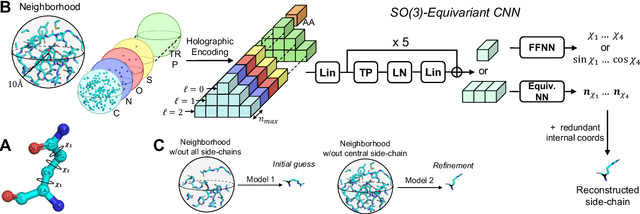
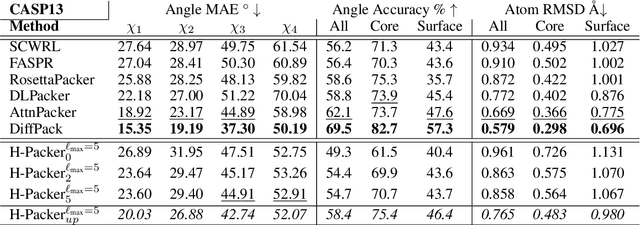
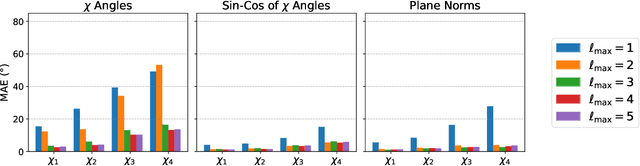
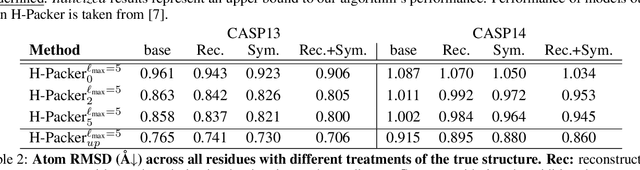
Accurately modeling protein 3D structure is essential for the design of functional proteins. An important sub-task of structure modeling is protein side-chain packing: predicting the conformation of side-chains (rotamers) given the protein's backbone structure and amino-acid sequence. Conventional approaches for this task rely on expensive sampling procedures over hand-crafted energy functions and rotamer libraries. Recently, several deep learning methods have been developed to tackle the problem in a data-driven way, albeit with vastly different formulations (from image-to-image translation to directly predicting atomic coordinates). Here, we frame the problem as a joint regression over the side-chains' true degrees of freedom: the dihedral $\chi$ angles. We carefully study possible objective functions for this task, while accounting for the underlying symmetries of the task. We propose Holographic Packer (H-Packer), a novel two-stage algorithm for side-chain packing built on top of two light-weight rotationally equivariant neural networks. We evaluate our method on CASP13 and CASP14 targets. H-Packer is computationally efficient and shows favorable performance against conventional physics-based algorithms and is competitive against alternative deep learning solutions.