 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
InstructPix2NeRF: Instructed 3D Portrait Editing from a Single Image
Nov 06, 2023
With the success of Neural Radiance Field (NeRF) in 3D-aware portrait editing, a variety of works have achieved promising results regarding both quality and 3D consistency. However, these methods heavily rely on per-prompt optimization when handling natural language as editing instructions. Due to the lack of labeled human face 3D datasets and effective architectures, the area of human-instructed 3D-aware editing for open-world portraits in an end-to-end manner remains under-explored. To solve this problem, we propose an end-to-end diffusion-based framework termed InstructPix2NeRF, which enables instructed 3D-aware portrait editing from a single open-world image with human instructions. At its core lies a conditional latent 3D diffusion process that lifts 2D editing to 3D space by learning the correlation between the paired images' difference and the instructions via triplet data. With the help of our proposed token position randomization strategy, we could even achieve multi-semantic editing through one single pass with the portrait identity well-preserved. Besides, we further propose an identity consistency module that directly modulates the extracted identity signals into our diffusion process, which increases the multi-view 3D identity consistency. Extensive experiments verify the effectiveness of our method and show its superiority against strong baselines quantitatively and qualitatively.
Semi-supervised multimodal coreference resolution in image narrations
Oct 20, 2023In this paper, we study multimodal coreference resolution, specifically where a longer descriptive text, i.e., a narration is paired with an image. This poses significant challenges due to fine-grained image-text alignment, inherent ambiguity present in narrative language, and unavailability of large annotated training sets. To tackle these challenges, we present a data efficient semi-supervised approach that utilizes image-narration pairs to resolve coreferences and narrative grounding in a multimodal context. Our approach incorporates losses for both labeled and unlabeled data within a cross-modal framework. Our evaluation shows that the proposed approach outperforms strong baselines both quantitatively and qualitatively, for the tasks of coreference resolution and narrative grounding.
Osteoporosis Prediction from Hand and Wrist X-rays using Image Segmentation and Self-Supervised Learning
Nov 12, 2023Osteoporosis is a widespread and chronic metabolic bone disease that often remains undiagnosed and untreated due to limited access to bone mineral density (BMD) tests like Dual-energy X-ray absorptiometry (DXA). In response to this challenge, current advancements are pivoting towards detecting osteoporosis by examining alternative indicators from peripheral bone areas, with the goal of increasing screening rates without added expenses or time. In this paper, we present a method to predict osteoporosis using hand and wrist X-ray images, which are both widely accessible and affordable, though their link to DXA-based data is not thoroughly explored. Initially, our method segments the ulnar, radius, and metacarpal bones using a foundational model for image segmentation. Then, we use a self-supervised learning approach to extract meaningful representations without the need for explicit labels, and move on to classify osteoporosis in a supervised manner. Our method is evaluated on a dataset with 192 individuals, cross-referencing their verified osteoporosis conditions against the standard DXA test. With a notable classification score (AUC=0.83), our model represents a pioneering effort in leveraging vision-based techniques for osteoporosis identification from the peripheral skeleton sites.
FreqFed: A Frequency Analysis-Based Approach for Mitigating Poisoning Attacks in Federated Learning
Dec 07, 2023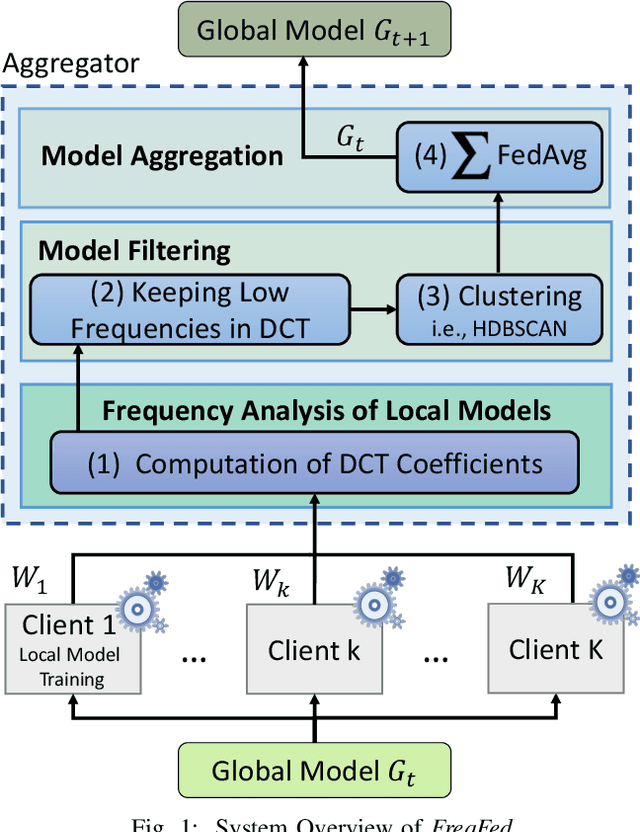
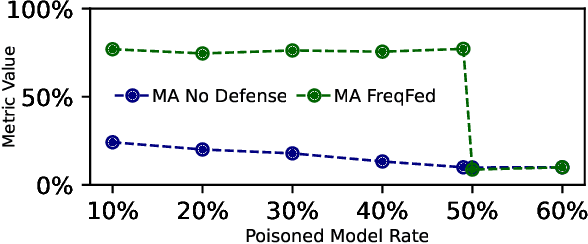

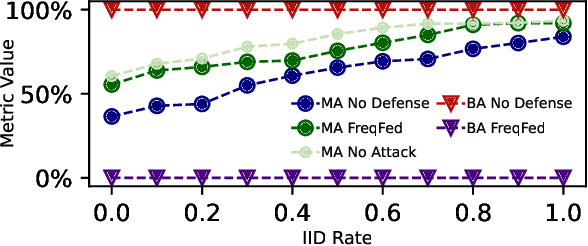
Federated learning (FL) is a collaborative learning paradigm allowing multiple clients to jointly train a model without sharing their training data. However, FL is susceptible to poisoning attacks, in which the adversary injects manipulated model updates into the federated model aggregation process to corrupt or destroy predictions (untargeted poisoning) or implant hidden functionalities (targeted poisoning or backdoors). Existing defenses against poisoning attacks in FL have several limitations, such as relying on specific assumptions about attack types and strategies or data distributions or not sufficiently robust against advanced injection techniques and strategies and simultaneously maintaining the utility of the aggregated model. To address the deficiencies of existing defenses, we take a generic and completely different approach to detect poisoning (targeted and untargeted) attacks. We present FreqFed, a novel aggregation mechanism that transforms the model updates (i.e., weights) into the frequency domain, where we can identify the core frequency components that inherit sufficient information about weights. This allows us to effectively filter out malicious updates during local training on the clients, regardless of attack types, strategies, and clients' data distributions. We extensively evaluate the efficiency and effectiveness of FreqFed in different application domains, including image classification, word prediction, IoT intrusion detection, and speech recognition. We demonstrate that FreqFed can mitigate poisoning attacks effectively with a negligible impact on the utility of the aggregated model.
DeepCache: Accelerating Diffusion Models for Free
Dec 07, 2023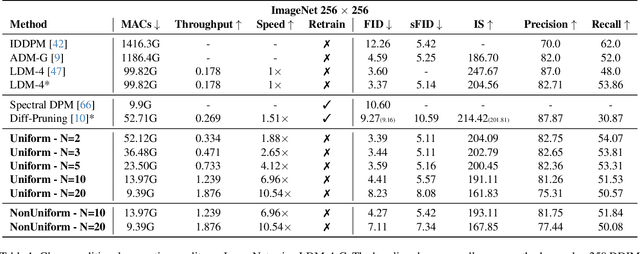
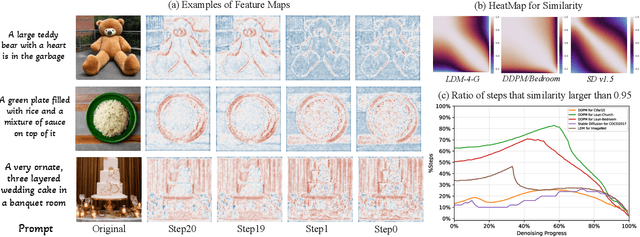
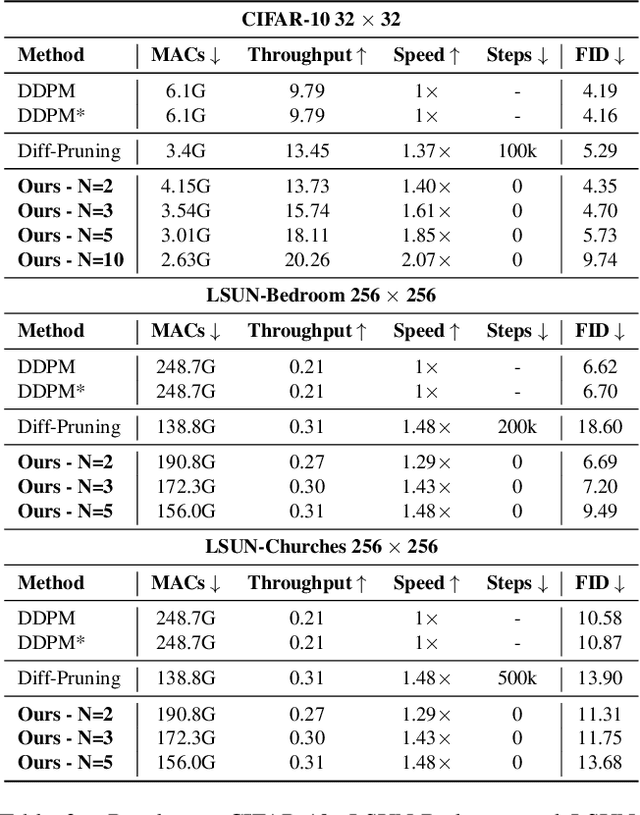
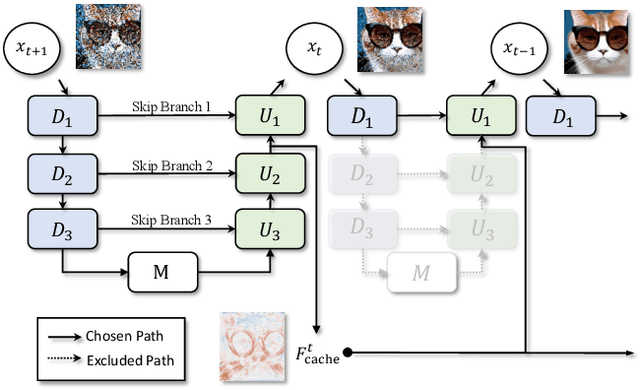
Diffusion models have recently gained unprecedented attention in the field of image synthesis due to their remarkable generative capabilities. Notwithstanding their prowess, these models often incur substantial computational costs, primarily attributed to the sequential denoising process and cumbersome model size. Traditional methods for compressing diffusion models typically involve extensive retraining, presenting cost and feasibility challenges. In this paper, we introduce DeepCache, a novel training-free paradigm that accelerates diffusion models from the perspective of model architecture. DeepCache capitalizes on the inherent temporal redundancy observed in the sequential denoising steps of diffusion models, which caches and retrieves features across adjacent denoising stages, thereby curtailing redundant computations. Utilizing the property of the U-Net, we reuse the high-level features while updating the low-level features in a very cheap way. This innovative strategy, in turn, enables a speedup factor of 2.3$\times$ for Stable Diffusion v1.5 with only a 0.05 decline in CLIP Score, and 4.1$\times$ for LDM-4-G with a slight decrease of 0.22 in FID on ImageNet. Our experiments also demonstrate DeepCache's superiority over existing pruning and distillation methods that necessitate retraining and its compatibility with current sampling techniques. Furthermore, we find that under the same throughput, DeepCache effectively achieves comparable or even marginally improved results with DDIM or PLMS. The code is available at https://github.com/horseee/DeepCache
gcDLSeg: Integrating Graph-cut into Deep Learning for Binary Semantic Segmentation
Dec 07, 2023Binary semantic segmentation in computer vision is a fundamental problem. As a model-based segmentation method, the graph-cut approach was one of the most successful binary segmentation methods thanks to its global optimality guarantee of the solutions and its practical polynomial-time complexity. Recently, many deep learning (DL) based methods have been developed for this task and yielded remarkable performance, resulting in a paradigm shift in this field. To combine the strengths of both approaches, we propose in this study to integrate the graph-cut approach into a deep learning network for end-to-end learning. Unfortunately, backward propagation through the graph-cut module in the DL network is challenging due to the combinatorial nature of the graph-cut algorithm. To tackle this challenge, we propose a novel residual graph-cut loss and a quasi-residual connection, enabling the backward propagation of the gradients of the residual graph-cut loss for effective feature learning guided by the graph-cut segmentation model. In the inference phase, globally optimal segmentation is achieved with respect to the graph-cut energy defined on the optimized image features learned from DL networks. Experiments on the public AZH chronic wound data set and the pancreas cancer data set from the medical segmentation decathlon (MSD) demonstrated promising segmentation accuracy, and improved robustness against adversarial attacks.
Joint-Individual Fusion Structure with Fusion Attention Module for Multi-Modal Skin Cancer Classification
Dec 07, 2023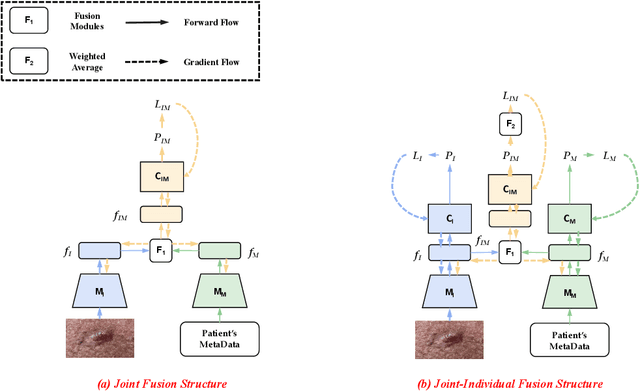
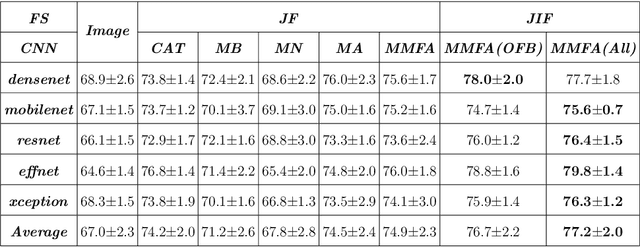
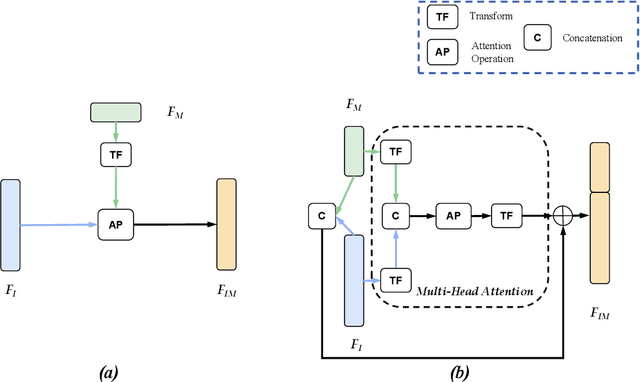
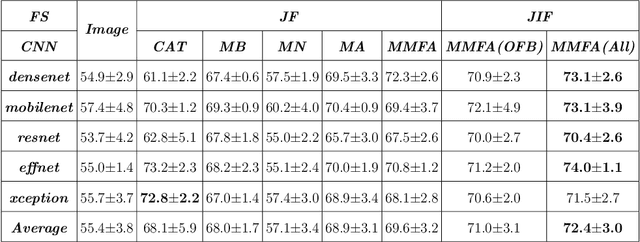
Most convolutional neural network (CNN) based methods for skin cancer classification obtain their results using only dermatological images. Although good classification results have been shown, more accurate results can be achieved by considering the patient's metadata, which is valuable clinical information for dermatologists. Current methods only use the simple joint fusion structure (FS) and fusion modules (FMs) for the multi-modal classification methods, there still is room to increase the accuracy by exploring more advanced FS and FM. Therefore, in this paper, we design a new fusion method that combines dermatological images (dermoscopy images or clinical images) and patient metadata for skin cancer classification from the perspectives of FS and FM. First, we propose a joint-individual fusion (JIF) structure that learns the shared features of multi-modality data and preserves specific features simultaneously. Second, we introduce a fusion attention (FA) module that enhances the most relevant image and metadata features based on both the self and mutual attention mechanism to support the decision-making pipeline. We compare the proposed JIF-MMFA method with other state-of-the-art fusion methods on three different public datasets. The results show that our JIF-MMFA method improves the classification results for all tested CNN backbones and performs better than the other fusion methods on the three public datasets, demonstrating our method's effectiveness and robustness
UniIR: Training and Benchmarking Universal Multimodal Information Retrievers
Nov 28, 2023Existing information retrieval (IR) models often assume a homogeneous format, limiting their applicability to diverse user needs, such as searching for images with text descriptions, searching for a news article with a headline image, or finding a similar photo with a query image. To approach such different information-seeking demands, we introduce UniIR, a unified instruction-guided multimodal retriever capable of handling eight distinct retrieval tasks across modalities. UniIR, a single retrieval system jointly trained on ten diverse multimodal-IR datasets, interprets user instructions to execute various retrieval tasks, demonstrating robust performance across existing datasets and zero-shot generalization to new tasks. Our experiments highlight that multi-task training and instruction tuning are keys to UniIR's generalization ability. Additionally, we construct the M-BEIR, a multimodal retrieval benchmark with comprehensive results, to standardize the evaluation of universal multimodal information retrieval.
PUMA: Fully Decentralized Uncertainty-aware Multiagent Trajectory Planner with Real-time Image Segmentation-based Frame Alignment
Nov 07, 2023Fully decentralized, multiagent trajectory planners enable complex tasks like search and rescue or package delivery by ensuring safe navigation in unknown environments. However, deconflicting trajectories with other agents and ensuring collision-free paths in a fully decentralized setting is complicated by dynamic elements and localization uncertainty. To this end, this paper presents (1) an uncertainty-aware multiagent trajectory planner and (2) an image segmentation-based frame alignment pipeline. The uncertainty-aware planner propagates uncertainty associated with the future motion of detected obstacles, and by incorporating this propagated uncertainty into optimization constraints, the planner effectively navigates around obstacles. Unlike conventional methods that emphasize explicit obstacle tracking, our approach integrates implicit tracking. Sharing trajectories between agents can cause potential collisions due to frame misalignment. Addressing this, we introduce a novel frame alignment pipeline that rectifies inter-agent frame misalignment. This method leverages a zero-shot image segmentation model for detecting objects in the environment and a data association framework based on geometric consistency for map alignment. Our approach accurately aligns frames with only 0.18 m and 2.7 deg of mean frame alignment error in our most challenging simulation scenario. In addition, we conducted hardware experiments and successfully achieved 0.29 m and 2.59 deg of frame alignment error. Together with the alignment framework, our planner ensures safe navigation in unknown environments and collision avoidance in decentralized settings.
GeoViT: A Versatile Vision Transformer Architecture for Geospatial Image Analysis
Nov 24, 2023Greenhouse gases are pivotal drivers of climate change, necessitating precise quantification and source identification to foster mitigation strategies. We introduce GeoViT, a compact vision transformer model adept in processing satellite imagery for multimodal segmentation, classification, and regression tasks targeting CO2 and NO2 emissions. Leveraging GeoViT, we attain superior accuracy in estimating power generation rates, fuel type, plume coverage for CO2, and high-resolution NO2 concentration mapping, surpassing previous state-of-the-art models while significantly reducing model size. GeoViT demonstrates the efficacy of vision transformer architectures in harnessing satellite-derived data for enhanced GHG emission insights, proving instrumental in advancing climate change monitoring and emission regulation efforts globally.