 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Defending Adversarial Attacks by Correcting logits
Jun 26, 2019
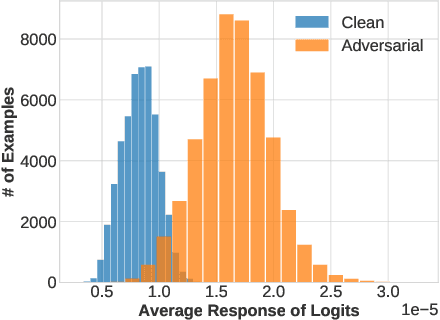

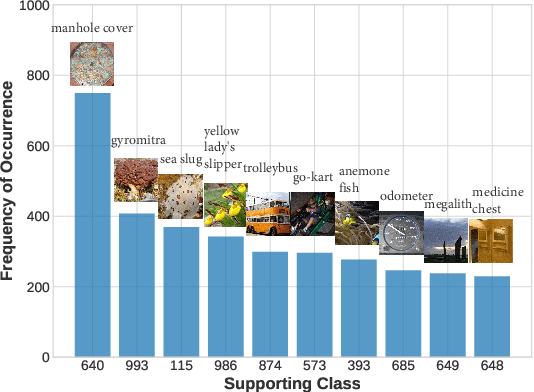
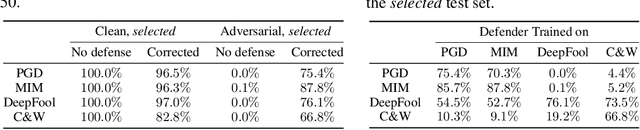
Generating and eliminating adversarial examples has been an intriguing topic in the field of deep learning. While previous research verified that adversarial attacks are often fragile and can be defended via image-level processing, it remains unclear how high-level features are perturbed by such attacks. We investigate this issue from a new perspective, which purely relies on logits, the class scores before softmax, to detect and defend adversarial attacks. Our defender is a two-layer network trained on a mixed set of clean and perturbed logits, with the goal being recovering the original prediction. Upon a wide range of adversarial attacks, our simple approach shows promising results with relatively high accuracy in defense, and the defender can transfer across attackers with similar properties. More importantly, our defender can work in the scenarios that image data are unavailable, and enjoys high interpretability especially at the semantic level.
Unprocessing Images for Learned Raw Denoising
Nov 27, 2018
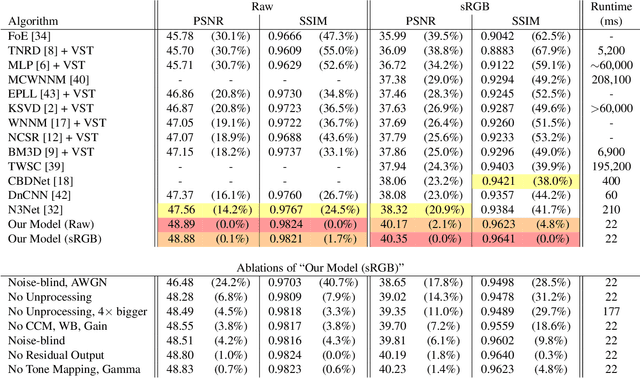
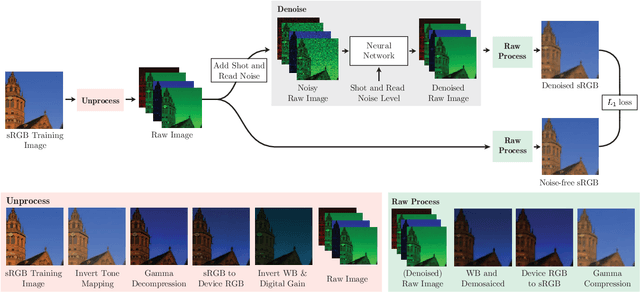
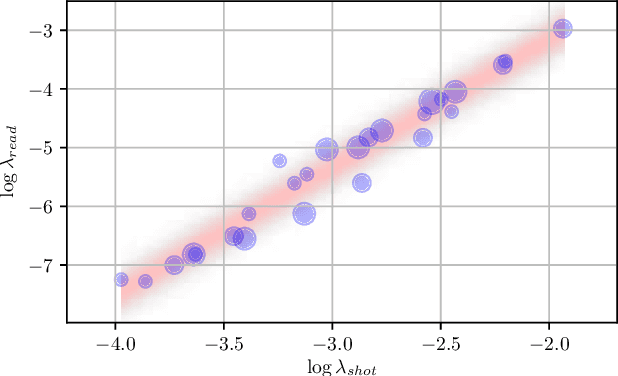
Machine learning techniques work best when the data used for training resembles the data used for evaluation. This holds true for learned single-image denoising algorithms, which are applied to real raw camera sensor readings but, due to practical constraints, are often trained on synthetic image data. Though it is understood that generalizing from synthetic to real data requires careful consideration of the noise properties of image sensors, the other aspects of a camera's image processing pipeline (gain, color correction, tone mapping, etc) are often overlooked, despite their significant effect on how raw measurements are transformed into finished images. To address this, we present a technique to "unprocess" images by inverting each step of an image processing pipeline, thereby allowing us to synthesize realistic raw sensor measurements from commonly available internet photos. We additionally model the relevant components of an image processing pipeline when evaluating our loss function, which allows training to be aware of all relevant photometric processing that will occur after denoising. By processing and unprocessing model outputs and training data in this way, we are able to train a simple convolutional neural network that has 14%-38% lower error rates and is 9x-18x faster than the previous state of the art on the Darmstadt Noise Dataset, and generalizes to sensors outside of that dataset as well.
Enhanced Convolutional Neural Tangent Kernels
Nov 03, 2019
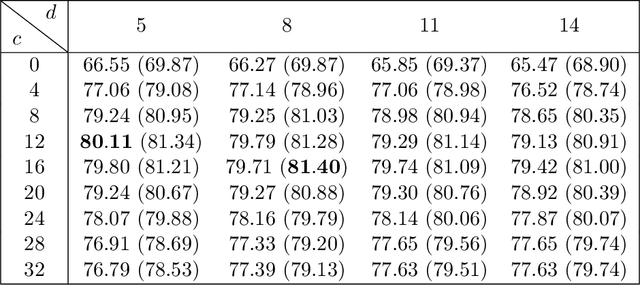
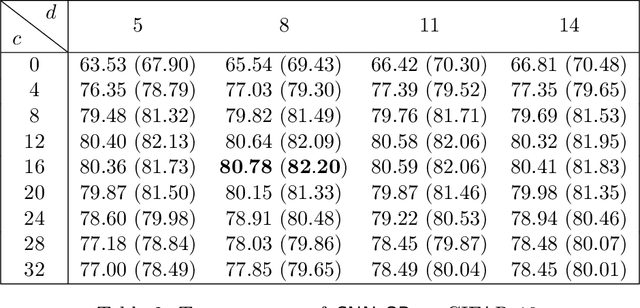
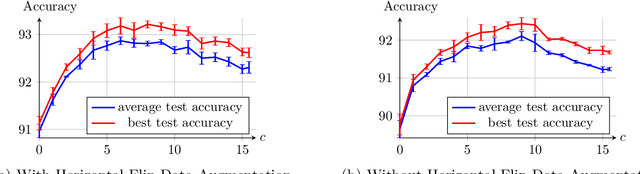
Recent research shows that for training with $\ell_2$ loss, convolutional neural networks (CNNs) whose width (number of channels in convolutional layers) goes to infinity correspond to regression with respect to the CNN Gaussian Process kernel (CNN-GP) if only the last layer is trained, and correspond to regression with respect to the Convolutional Neural Tangent Kernel (CNTK) if all layers are trained. An exact algorithm to compute CNTK (Arora et al., 2019) yielded the finding that classification accuracy of CNTK on CIFAR-10 is within 6-7% of that of that of the corresponding CNN architecture (best figure being around 78%) which is interesting performance for a fixed kernel. Here we show how to significantly enhance the performance of these kernels using two ideas. (1) Modifying the kernel using a new operation called Local Average Pooling (LAP) which preserves efficient computability of the kernel and inherits the spirit of standard data augmentation using pixel shifts. Earlier papers were unable to incorporate naive data augmentation because of the quadratic training cost of kernel regression. This idea is inspired by Global Average Pooling (GAP), which we show for CNN-GP and CNTK is equivalent to full translation data augmentation. (2) Representing the input image using a pre-processing technique proposed by Coates et al. (2011), which uses a single convolutional layer composed of random image patches. On CIFAR-10, the resulting kernel, CNN-GP with LAP and horizontal flip data augmentation, achieves 89% accuracy, matching the performance of AlexNet (Krizhevsky et al., 2012). Note that this is the best such result we know of for a classifier that is not a trained neural network. Similar improvements are obtained for Fashion-MNIST.
A Coarse-to-Fine Adaptive Network for Appearance-Based Gaze Estimation
Jan 01, 2020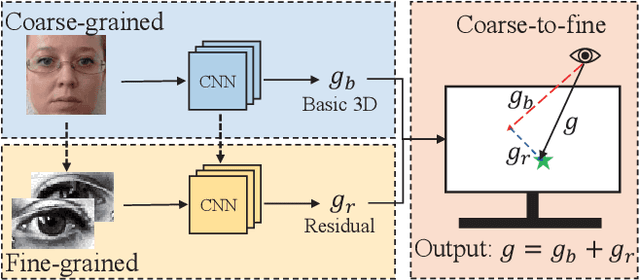
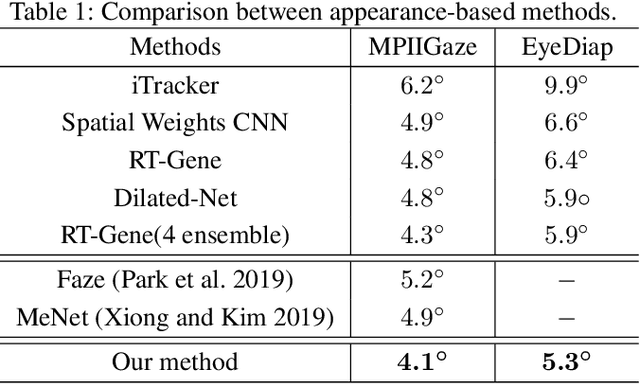
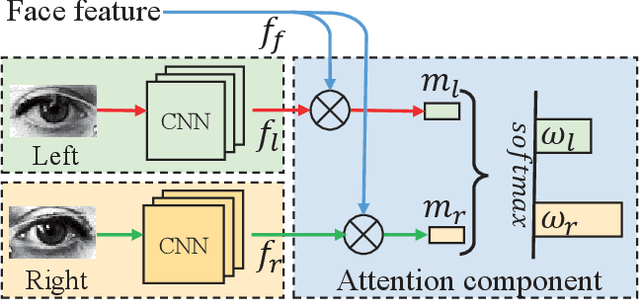
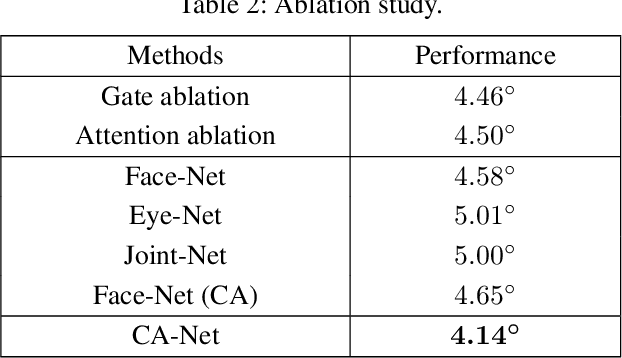
Human gaze is essential for various appealing applications. Aiming at more accurate gaze estimation, a series of recent works propose to utilize face and eye images simultaneously. Nevertheless, face and eye images only serve as independent or parallel feature sources in those works, the intrinsic correlation between their features is overlooked. In this paper we make the following contributions: 1) We propose a coarse-to-fine strategy which estimates a basic gaze direction from face image and refines it with corresponding residual predicted from eye images. 2) Guided by the proposed strategy, we design a framework which introduces a bi-gram model to bridge gaze residual and basic gaze direction, and an attention component to adaptively acquire suitable fine-grained feature. 3) Integrating the above innovations, we construct a coarse-to-fine adaptive network named CA-Net and achieve state-of-the-art performances on MPIIGaze and EyeDiap.
CubeSLAM: Monocular 3D Object SLAM
Apr 05, 2019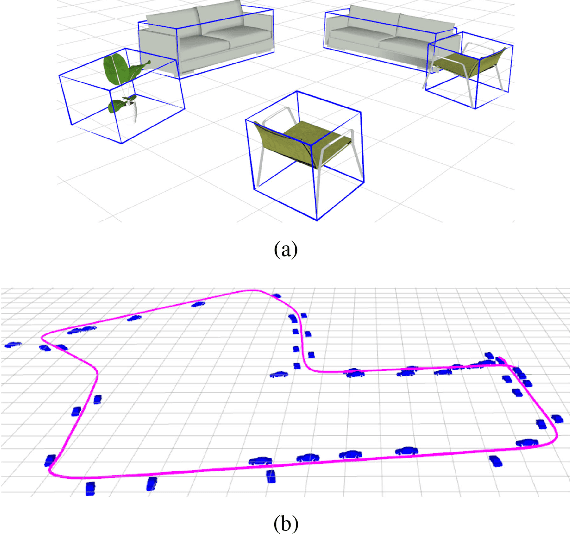
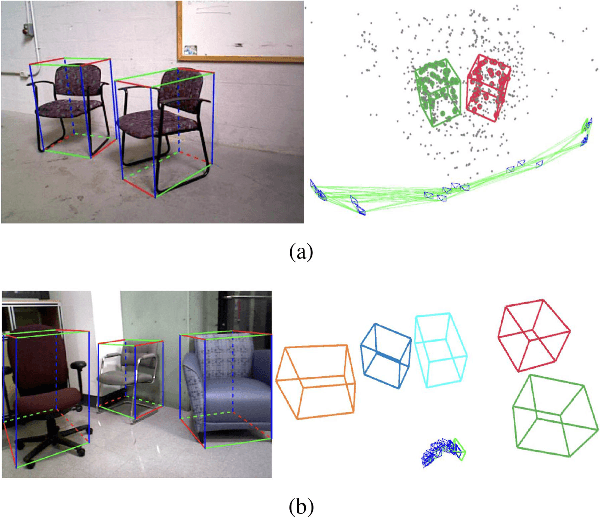
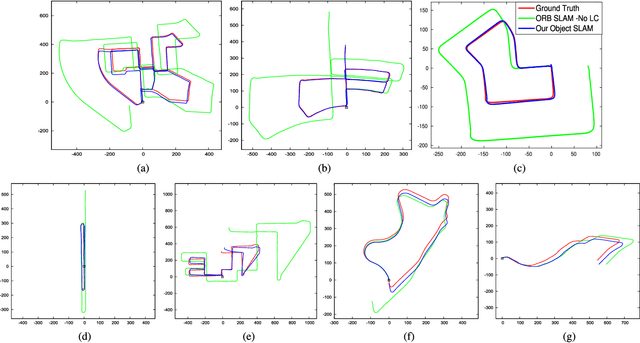
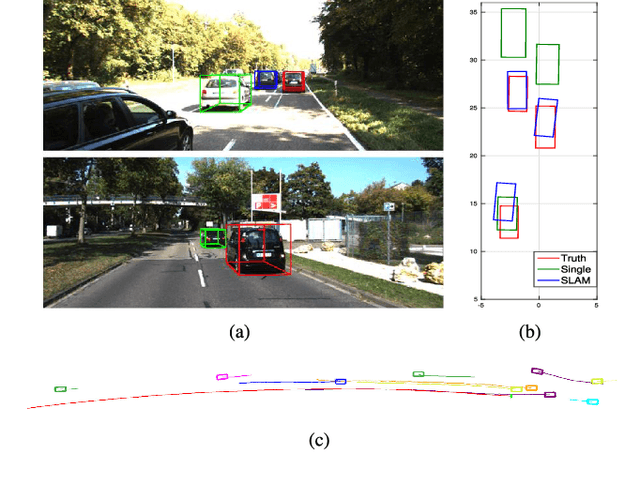
We present a method for single image 3D cuboid object detection and multi-view object SLAM in both static and dynamic environments, and demonstrate that the two parts can improve each other. Firstly for single image object detection, we generate high-quality cuboid proposals from 2D bounding boxes and vanishing points sampling. The proposals are further scored and selected based on the alignment with image edges. Secondly, multi-view bundle adjustment with new object measurements is proposed to jointly optimize poses of cameras, objects and points. Objects can provide long-range geometric and scale constraints to improve camera pose estimation and reduce monocular drift. Instead of treating dynamic regions as outliers, we utilize object representation and motion model constraints to improve the camera pose estimation. The 3D detection experiments on SUN RGBD and KITTI show better accuracy and robustness over existing approaches. On the public TUM, KITTI odometry and our own collected datasets, our SLAM method achieves the state-of-the-art monocular camera pose estimation and at the same time, improves the 3D object detection accuracy.
HiCoRe: Visual Hierarchical Context-Reasoning
Sep 02, 2019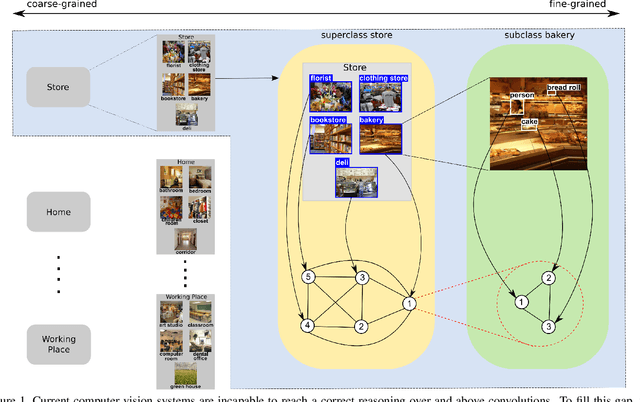
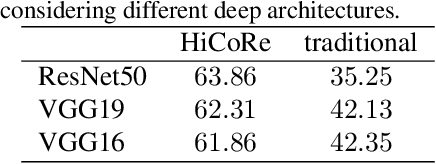
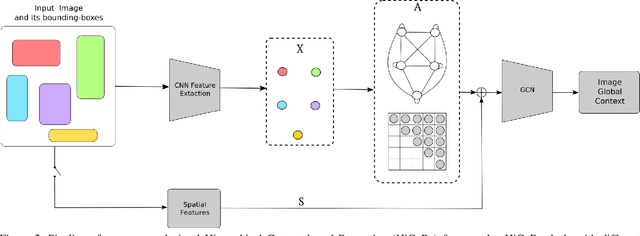
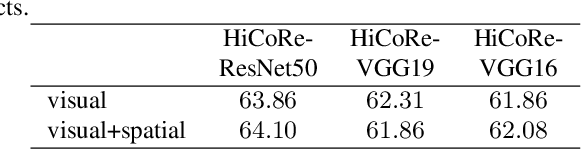
Reasoning about images/objects and their hierarchical interactions is a key concept for the next generation of computer vision approaches. Here we present a new framework to deal with it through a visual hierarchical context-based reasoning. Current reasoning methods use the fine-grained labels from images' objects and their interactions to predict labels to new objects. Our framework modifies this current information flow. It goes beyond and is independent of the fine-grained labels from the objects to define the image context. It takes into account the hierarchical interactions between different abstraction levels (i.e. taxonomy) of information in the images and their bounding-boxes. Besides these connections, it considers their intrinsic characteristics. To do so, we build and apply graphs to graph convolution networks with convolutional neural networks. We show a strong effectiveness over widely used convolutional neural networks, reaching a gain 3 times greater on well-known image datasets. We evaluate the capability and the behavior of our framework under different scenarios, considering distinct (superclass, subclass and hierarchical) granularity levels. We also explore attention mechanisms through graph attention networks and pre-processing methods considering dimensionality expansion and/or reduction of the features' representations. Further analyses are performed comparing supervised and semi-supervised approaches.
DESAT: an SSW tool for SDO/AIA image de-saturation
Mar 08, 2015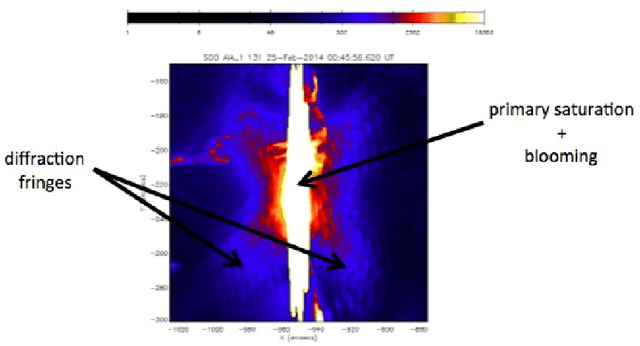
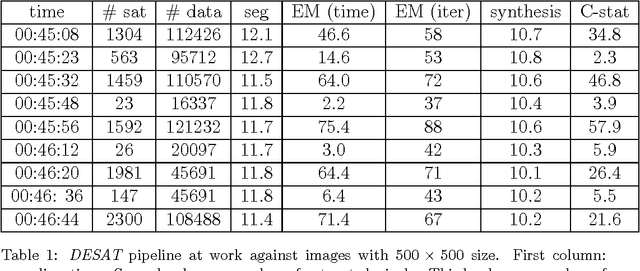
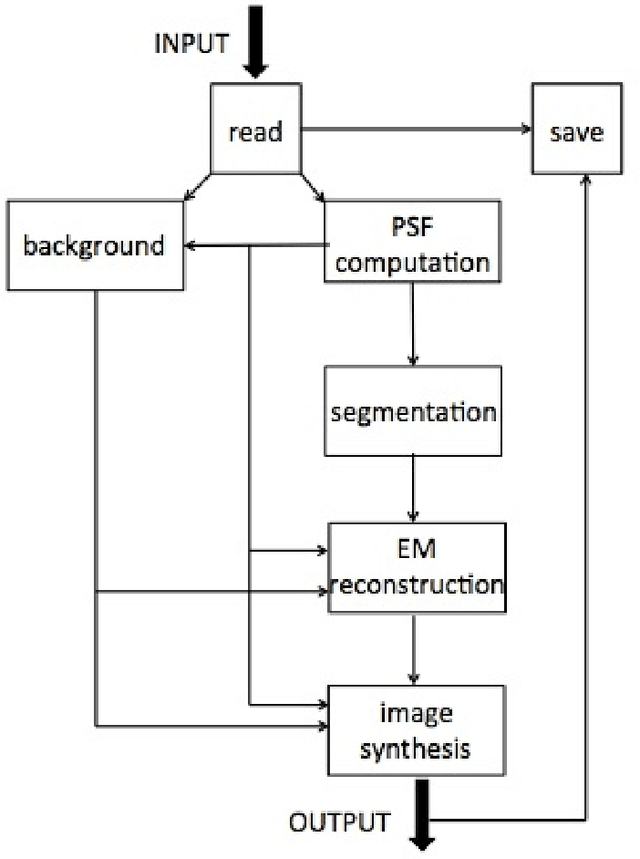
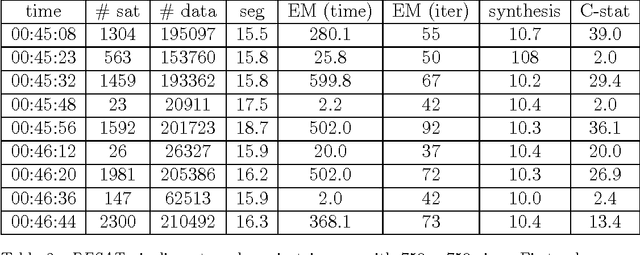
Saturation affects a significant rate of images recorded by the Atmospheric Imaging Assembly on the Solar Dynamics Observatory. This paper describes a computational method and a technological pipeline for the de-saturation of such images, based on several mathematical ingredients like Expectation Maximization, image correlation and interpolation. An analysis of the computational properties and demands of the pipeline, together with an assessment of its reliability are performed against a set of data recorded from the Feburary 25 2014 flaring event.
Deep Automodulators
Dec 21, 2019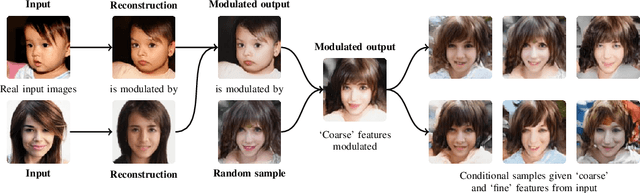
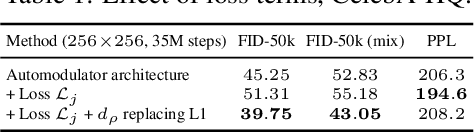
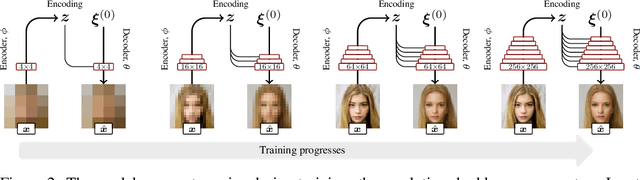

We introduce a novel autoencoder model that deviates from traditional autoencoders by using the full latent vector to independently modulate each layer in the decoder. We demonstrate how such an 'automodulator' allows for a principled approach to enforce latent space disentanglement, mixing of latent codes, and a straightforward way to utilise prior information that can be construed as a scale-specific invariance. Unlike the GAN models without encoders, autoencoder models can directly operate on new real input samples. This makes our model directly suitable for applications involving real-world inputs. As the architectural backbone, we extend recent generative autoencoder models that retain input identity and image sharpness at high resolutions better than VAEs. We show that our model achieves state-of-the-art latent space disentanglement and achieves high quality and diversity of output samples, as well as faithfulness of reconstructions.
Few Labeled Atlases are Necessary for Deep-Learning-Based Segmentation
Aug 15, 2019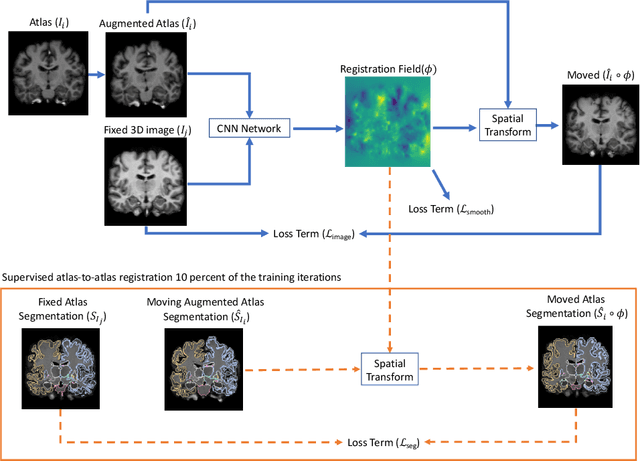
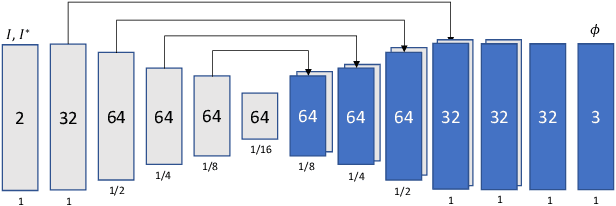
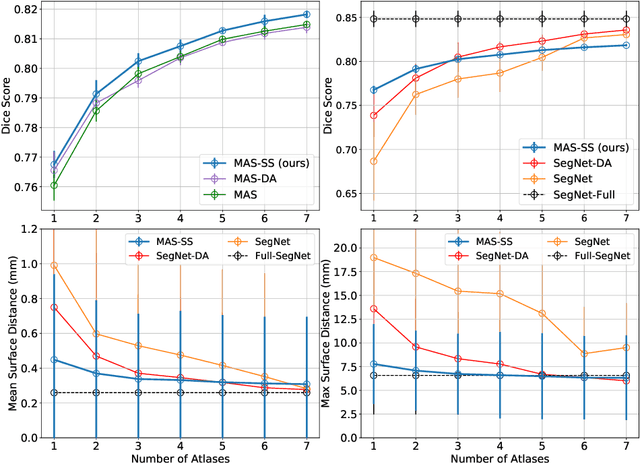
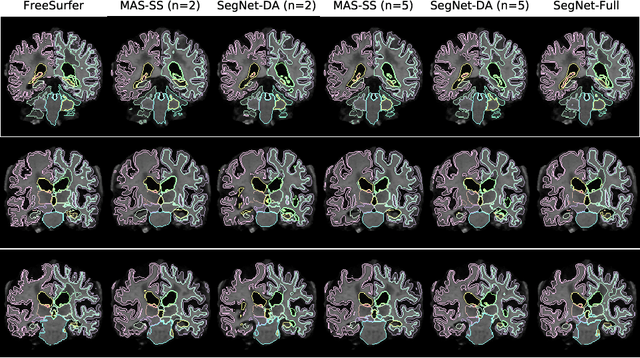
We tackle biomedical image segmentation in the scenario of only a few labeled brain MR images. This is an important and challenging task in medical applications, where manual annotations are time-consuming. Classical multi-atlas based anatomical segmentation methods use image registration to warp segments from labeled images onto a new scan. These approaches have traditionally required significant runtime, but recent learning-based registration methods promise substantial runtime improvement. In a different paradigm, supervised learning-based segmentation strategies have gained popularity. These methods have consistently used relatively large sets of labeled training data, and their behavior in the regime of a few labeled images has not been thoroughly evaluated. In this work, we provide two important results for anatomical segmentation in the scenario where few labeled images are available. First, we propose a straightforward implementation of efficient semi-supervised learning-based registration method, which we showcase in a multi-atlas segmentation framework. Second, through a thorough empirical study, we evaluate the performance of a supervised segmentation approach, where the training images are augmented via random deformations. Surprisingly, we find that in both paradigms, accurate segmentation is generally possible even in the context of few labeled images.
Text Based Approach For Indexing And Retrieval Of Image And Video: A Review
Apr 05, 2014


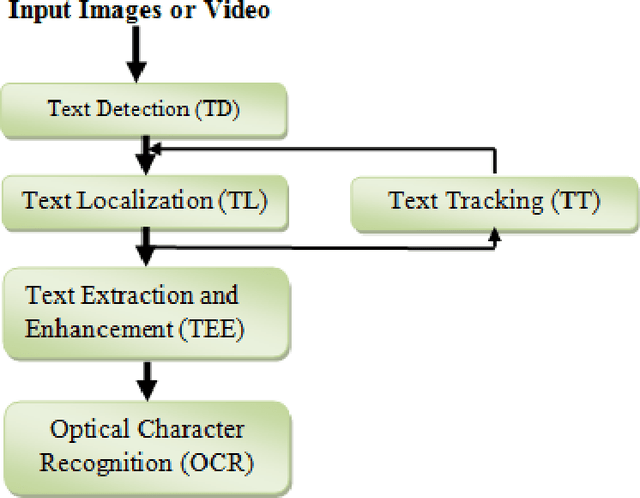
Text data present in multimedia contain useful information for automatic annotation, indexing. Extracted information used for recognition of the overlay or scene text from a given video or image. The Extracted text can be used for retrieving the videos and images. In this paper, firstly, we are discussed the different techniques for text extraction from images and videos. Secondly, we are reviewed the techniques for indexing and retrieval of image and videos by using extracted text.
* 12 pages