 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Weak-to-Strong Generalization Even in Random Feature Networks, Provably
Mar 04, 2025Weak-to-Strong Generalization (Burns et al., 2024) is the phenomenon whereby a strong student, say GPT-4, learns a task from a weak teacher, say GPT-2, and ends up significantly outperforming the teacher. We show that this phenomenon does not require a strong learner like GPT-4. We consider student and teacher that are random feature models, described by two-layer networks with a random and fixed bottom layer and a trained top layer. A "weak" teacher, with a small number of units (i.e. random features), is trained on the population, and a "strong" student, with a much larger number of units (i.e. random features), is trained only on labels generated by the weak teacher. We demonstrate, prove, and understand how the student can outperform the teacher, even though trained only on data labeled by the teacher. We also explain how such weak-to-strong generalization is enabled by early stopping. Importantly, we also show the quantitative limits of weak-to-strong generalization in this model.
Generalizing from SIMPLE to HARD Visual Reasoning: Can We Mitigate Modality Imbalance in VLMs?
Jan 05, 2025



While Vision Language Models (VLMs) are impressive in tasks such as visual question answering (VQA) and image captioning, their ability to apply multi-step reasoning to images has lagged, giving rise to perceptions of modality imbalance or brittleness. Towards systematic study of such issues, we introduce a synthetic framework for assessing the ability of VLMs to perform algorithmic visual reasoning (AVR), comprising three tasks: Table Readout, Grid Navigation, and Visual Analogy. Each has two levels of difficulty, SIMPLE and HARD, and even the SIMPLE versions are difficult for frontier VLMs. We seek strategies for training on the SIMPLE version of the tasks that improve performance on the corresponding HARD task, i.e., S2H generalization. This synthetic framework, where each task also has a text-only version, allows a quantification of the modality imbalance, and how it is impacted by training strategy. Ablations highlight the importance of explicit image-to-text conversion in promoting S2H generalization when using auto-regressive training. We also report results of mechanistic study of this phenomenon, including a measure of gradient alignment that seems to identify training strategies that promote better S2H generalization.
Phi-4 Technical Report
Dec 12, 2024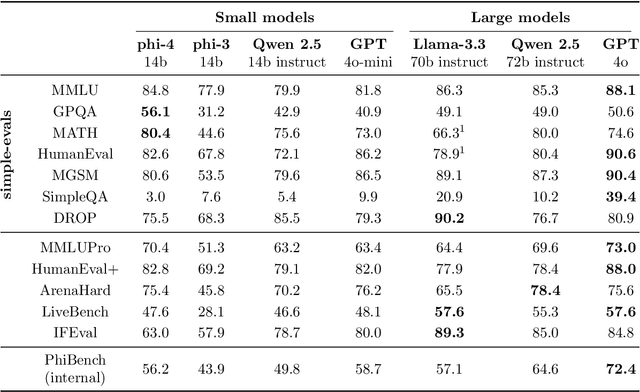
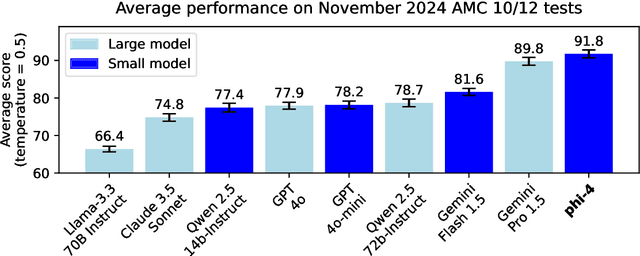

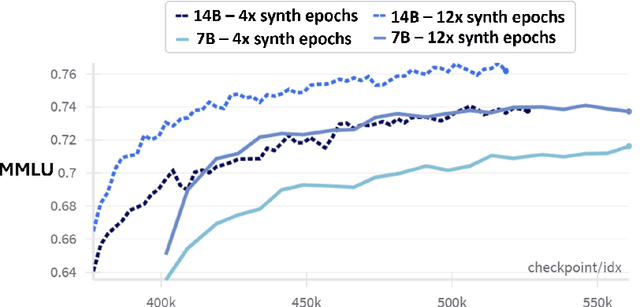
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
Can Models Learn Skill Composition from Examples?
Sep 29, 2024



As large language models (LLMs) become increasingly advanced, their ability to exhibit compositional generalization -- the capacity to combine learned skills in novel ways not encountered during training -- has garnered significant attention. This type of generalization, particularly in scenarios beyond training data, is also of great interest in the study of AI safety and alignment. A recent study introduced the SKILL-MIX evaluation, where models are tasked with composing a short paragraph demonstrating the use of a specified $k$-tuple of language skills. While small models struggled with composing even with $k=3$, larger models like GPT-4 performed reasonably well with $k=5$ and $6$. In this paper, we employ a setup akin to SKILL-MIX to evaluate the capacity of smaller models to learn compositional generalization from examples. Utilizing a diverse set of language skills -- including rhetorical, literary, reasoning, theory of mind, and common sense -- GPT-4 was used to generate text samples that exhibit random subsets of $k$ skills. Subsequent fine-tuning of 7B and 13B parameter models on these combined skill texts, for increasing values of $k$, revealed the following findings: (1) Training on combinations of $k=2$ and $3$ skills results in noticeable improvements in the ability to compose texts with $k=4$ and $5$ skills, despite models never having seen such examples during training. (2) When skill categories are split into training and held-out groups, models significantly improve at composing texts with held-out skills during testing despite having only seen training skills during fine-tuning, illustrating the efficacy of the training approach even with previously unseen skills. This study also suggests that incorporating skill-rich (potentially synthetic) text into training can substantially enhance the compositional capabilities of models.
ConceptMix: A Compositional Image Generation Benchmark with Controllable Difficulty
Aug 26, 2024Compositionality is a critical capability in Text-to-Image (T2I) models, as it reflects their ability to understand and combine multiple concepts from text descriptions. Existing evaluations of compositional capability rely heavily on human-designed text prompts or fixed templates, limiting their diversity and complexity, and yielding low discriminative power. We propose ConceptMix, a scalable, controllable, and customizable benchmark which automatically evaluates compositional generation ability of T2I models. This is done in two stages. First, ConceptMix generates the text prompts: concretely, using categories of visual concepts (e.g., objects, colors, shapes, spatial relationships), it randomly samples an object and k-tuples of visual concepts, then uses GPT4-o to generate text prompts for image generation based on these sampled concepts. Second, ConceptMix evaluates the images generated in response to these prompts: concretely, it checks how many of the k concepts actually appeared in the image by generating one question per visual concept and using a strong VLM to answer them. Through administering ConceptMix to a diverse set of T2I models (proprietary as well as open ones) using increasing values of k, we show that our ConceptMix has higher discrimination power than earlier benchmarks. Specifically, ConceptMix reveals that the performance of several models, especially open models, drops dramatically with increased k. Importantly, it also provides insight into the lack of prompt diversity in widely-used training datasets. Additionally, we conduct extensive human studies to validate the design of ConceptMix and compare our automatic grading with human judgement. We hope it will guide future T2I model development.
AI-Assisted Generation of Difficult Math Questions
Jul 30, 2024



Current LLM training positions mathematical reasoning as a core capability. With publicly available sources fully tapped, there is unmet demand for diverse and challenging math questions. Relying solely on human experts is both time-consuming and costly, while LLM-generated questions often lack the requisite diversity and difficulty. We present a design framework that combines the strengths of LLMs with a human-in-the-loop approach to generate a diverse array of challenging math questions. We leverage LLM metacognition skills [Didolkar et al., 2024] of a strong LLM to extract core "skills" from existing math datasets. These skills serve as the basis for generating novel and difficult questions by prompting the LLM with random pairs of core skills. The use of two different skills within each question makes finding such questions an "out of distribution" task for both LLMs and humans. Our pipeline employs LLMs to iteratively generate and refine questions and solutions through multiturn prompting. Human annotators then verify and further refine the questions, with their efficiency enhanced via further LLM interactions. Applying this pipeline on skills extracted from the MATH dataset [Hendrycks et al., 2021] resulted in MATH$^2$ - a dataset of higher-quality math questions, as evidenced by: (a) Lower performance of all models on MATH$^2$ than on MATH (b) Higher performance on MATH when using MATH$^2$ questions as in-context examples. Although focused on mathematics, our methodology seems applicable to other domains requiring structured reasoning, and potentially as a component of scalable oversight. Also of interest is a striking relationship observed between models' performance on the new dataset: the success rate on MATH$^2$ is the square on MATH, suggesting that successfully solving the question in MATH$^2$ requires a nontrivial combination of two distinct math skills.
Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates
Feb 28, 2024



Public LLMs such as the Llama 2-Chat have driven huge activity in LLM research. These models underwent alignment training and were considered safe. Recently Qi et al. (2023) reported that even benign fine-tuning (e.g., on seemingly safe datasets) can give rise to unsafe behaviors in the models. The current paper is about methods and best practices to mitigate such loss of alignment. Through extensive experiments on several chat models (Meta's Llama 2-Chat, Mistral AI's Mistral 7B Instruct v0.2, and OpenAI's GPT-3.5 Turbo), this paper uncovers that the prompt templates used during fine-tuning and inference play a crucial role in preserving safety alignment, and proposes the "Pure Tuning, Safe Testing" (PTST) principle -- fine-tune models without a safety prompt, but include it at test time. Fine-tuning experiments on GSM8K, ChatDoctor, and OpenOrca show that PTST significantly reduces the rise of unsafe behaviors, and even almost eliminates them in some cases.
Skill-Mix: a Flexible and Expandable Family of Evaluations for AI models
Oct 26, 2023



With LLMs shifting their role from statistical modeling of language to serving as general-purpose AI agents, how should LLM evaluations change? Arguably, a key ability of an AI agent is to flexibly combine, as needed, the basic skills it has learned. The capability to combine skills plays an important role in (human) pedagogy and also in a paper on emergence phenomena (Arora & Goyal, 2023). This work introduces Skill-Mix, a new evaluation to measure ability to combine skills. Using a list of $N$ skills the evaluator repeatedly picks random subsets of $k$ skills and asks the LLM to produce text combining that subset of skills. Since the number of subsets grows like $N^k$, for even modest $k$ this evaluation will, with high probability, require the LLM to produce text significantly different from any text in the training set. The paper develops a methodology for (a) designing and administering such an evaluation, and (b) automatic grading (plus spot-checking by humans) of the results using GPT-4 as well as the open LLaMA-2 70B model. Administering a version of to popular chatbots gave results that, while generally in line with prior expectations, contained surprises. Sizeable differences exist among model capabilities that are not captured by their ranking on popular LLM leaderboards ("cramming for the leaderboard"). Furthermore, simple probability calculations indicate that GPT-4's reasonable performance on $k=5$ is suggestive of going beyond "stochastic parrot" behavior (Bender et al., 2021), i.e., it combines skills in ways that it had not seen during training. We sketch how the methodology can lead to a Skill-Mix based eco-system of open evaluations for AI capabilities of future models.
Tensor Programs VI: Feature Learning in Infinite-Depth Neural Networks
Oct 12, 2023



By classifying infinite-width neural networks and identifying the *optimal* limit, Tensor Programs IV and V demonstrated a universal way, called $\mu$P, for *widthwise hyperparameter transfer*, i.e., predicting optimal hyperparameters of wide neural networks from narrow ones. Here we investigate the analogous classification for *depthwise parametrizations* of deep residual networks (resnets). We classify depthwise parametrizations of block multiplier and learning rate by their infinite-width-then-depth limits. In resnets where each block has only one layer, we identify a unique optimal parametrization, called Depth-$\mu$P that extends $\mu$P and show empirically it admits depthwise hyperparameter transfer. We identify *feature diversity* as a crucial factor in deep networks, and Depth-$\mu$P can be characterized as maximizing both feature learning and feature diversity. Exploiting this, we find that absolute value, among all homogeneous nonlinearities, maximizes feature diversity and indeed empirically leads to significantly better performance. However, if each block is deeper (such as modern transformers), then we find fundamental limitations in all possible infinite-depth limits of such parametrizations, which we illustrate both theoretically and empirically on simple networks as well as Megatron transformer trained on Common Crawl.