 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
Mar 17, 2020
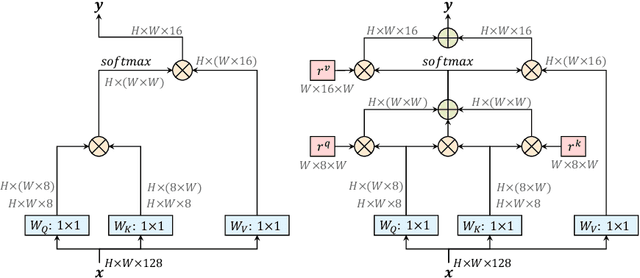
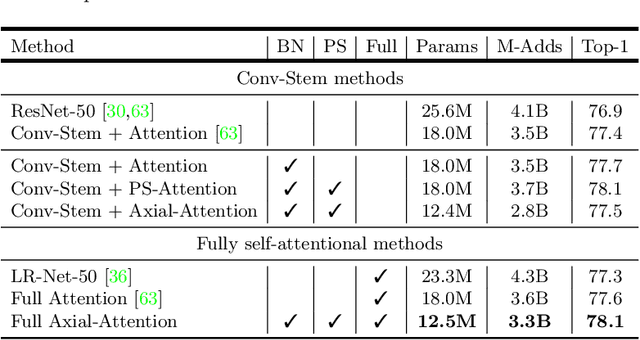
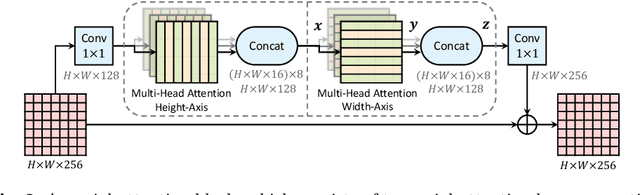
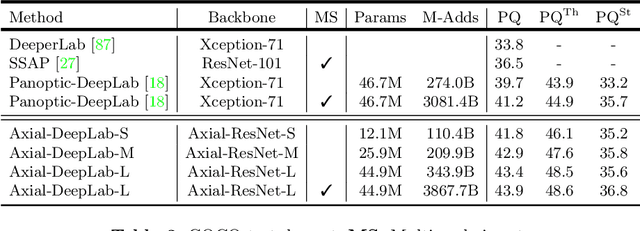
Convolution exploits locality for efficiency at a cost of missing long range context. Self-attention has been adopted to augment CNNs with non-local interactions. Recent works prove it possible to stack self-attention layers to obtain a fully attentional network by restricting the attention to a local region. In this paper, we attempt to remove this constraint by factorizing 2D self-attention into two 1D self-attentions. This reduces computation complexity and allows performing attention within a larger or even global region. In companion, we also propose a position-sensitive self-attention design. Combining both yields our position-sensitive axial-attention layer, a novel building block that one could stack to form axial-attention models for image classification and dense prediction. We demonstrate the effectiveness of our model on four large-scale datasets. In particular, our model outperforms all existing stand-alone self-attention models on ImageNet. Our Axial-DeepLab improves 2.8% PQ over bottom-up state-of-the-art on COCO test-dev. This previous state-of-the-art is attained by our small variant that is 3.8x parameter-efficient and 27x computation-efficient. Axial-DeepLab also achieves state-of-the-art results on Mapillary Vistas and Cityscapes.
Enabling Deep Spiking Neural Networks with Hybrid Conversion and Spike Timing Dependent Backpropagation
May 04, 2020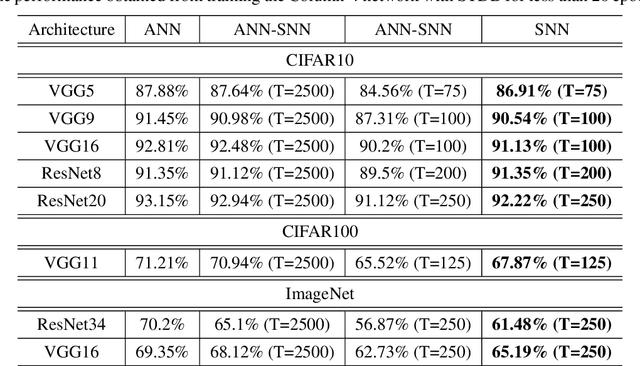
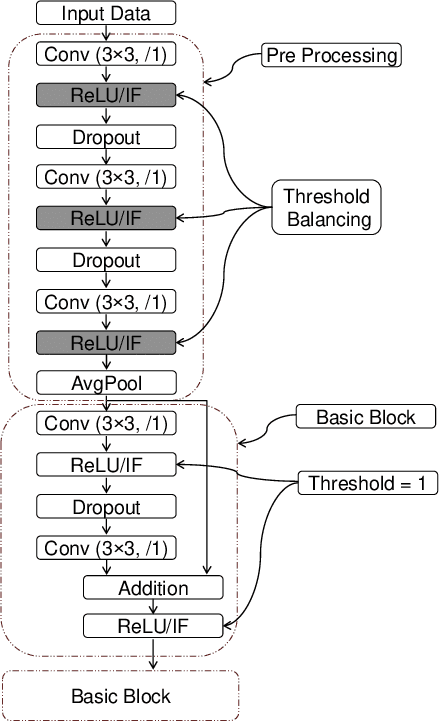
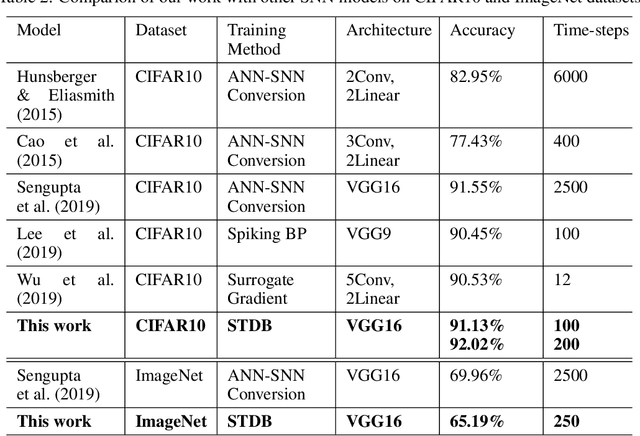
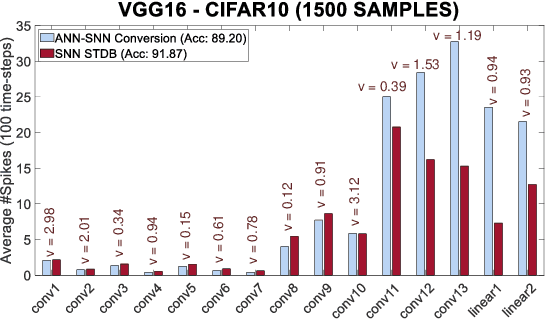
Spiking Neural Networks (SNNs) operate with asynchronous discrete events (or spikes) which can potentially lead to higher energy-efficiency in neuromorphic hardware implementations. Many works have shown that an SNN for inference can be formed by copying the weights from a trained Artificial Neural Network (ANN) and setting the firing threshold for each layer as the maximum input received in that layer. These type of converted SNNs require a large number of time steps to achieve competitive accuracy which diminishes the energy savings. The number of time steps can be reduced by training SNNs with spike-based backpropagation from scratch, but that is computationally expensive and slow. To address these challenges, we present a computationally-efficient training technique for deep SNNs. We propose a hybrid training methodology: 1) take a converted SNN and use its weights and thresholds as an initialization step for spike-based backpropagation, and 2) perform incremental spike-timing dependent backpropagation (STDB) on this carefully initialized network to obtain an SNN that converges within few epochs and requires fewer time steps for input processing. STDB is performed with a novel surrogate gradient function defined using neuron's spike time. The proposed training methodology converges in less than 20 epochs of spike-based backpropagation for most standard image classification datasets, thereby greatly reducing the training complexity compared to training SNNs from scratch. We perform experiments on CIFAR-10, CIFAR-100, and ImageNet datasets for both VGG and ResNet architectures. We achieve top-1 accuracy of 65.19% for ImageNet dataset on SNN with 250 time steps, which is 10X faster compared to converted SNNs with similar accuracy.
CMRNet: Camera to LiDAR-Map Registration
Jun 24, 2019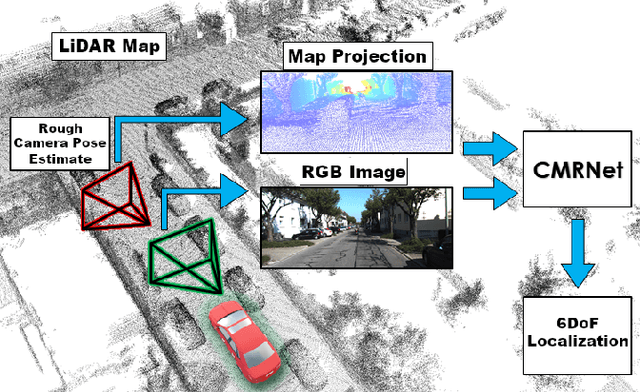


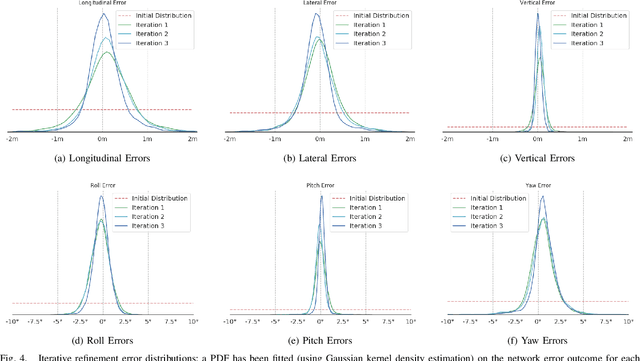
In this paper we present CMRNet, a realtime approach based on a Convolutional Neural Network to localize an RGB image of a scene in a map built from LiDAR data. Our network is not trained on the working area, i.e. CMRNet does not learn the map. Instead it learns to match an image to the map. We validate our approach on the KITTI dataset, processing each frame independently without any tracking procedure. CMRNet achieves 0.26m and 1.05deg median localization accuracy on the sequence 00 of the odometry dataset, starting from a rough pose estimate displaced up to 3.5m and 17deg. To the best of our knowledge this is the first CNN-based approach that learns to match images from a monocular camera to a given, preexisting 3D LiDAR-map.
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Feb 15, 2020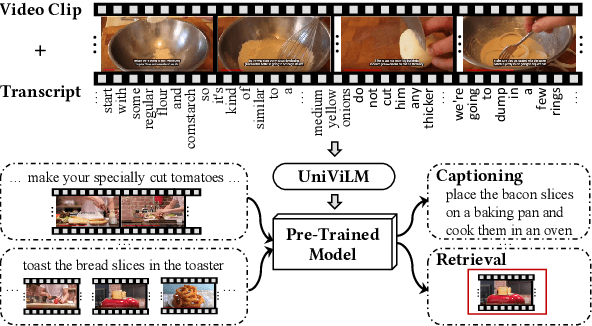
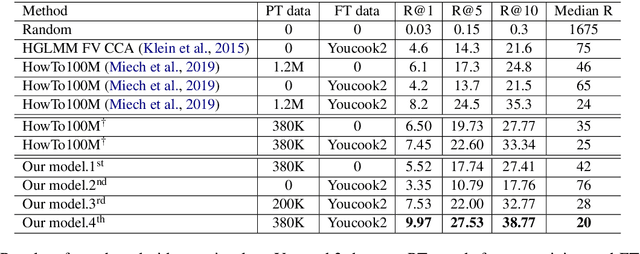
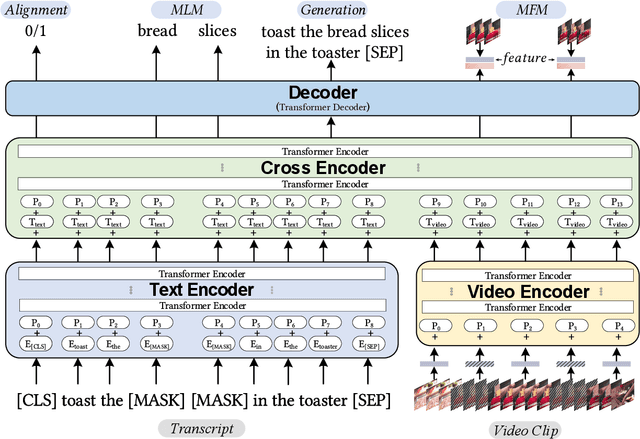
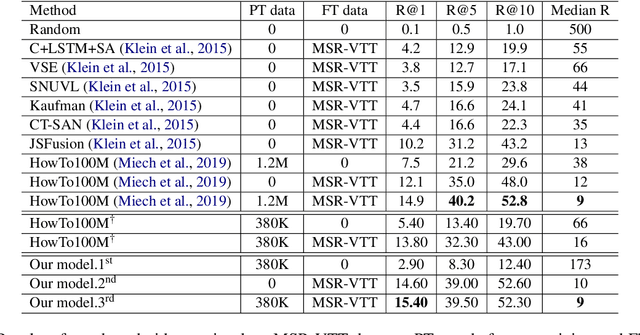
We propose UniViLM: a Unified Video and Language pre-training Model for multimodal understanding and generation. Motivated by the recent success of BERT based pre-training technique for NLP and image-language tasks, VideoBERT and CBT are proposed to exploit BERT model for video and language pre-training using narrated instructional videos. Different from their works which only pre-train understanding task, we propose a unified video-language pre-training model for both understanding and generation tasks. Our model comprises of 4 components including two single-modal encoders, a cross encoder and a decoder with the Transformer backbone. We first pre-train our model to learn the universal representation for both video and language on a large instructional video dataset. Then we fine-tune the model on two multimodal tasks including understanding task (text-based video retrieval) and generation task (multimodal video captioning). Our extensive experiments show that our method can improve the performance of both understanding and generation tasks and achieves the state-of-the art results.
When to Use Convolutional Neural Networks for Inverse Problems
Mar 30, 2020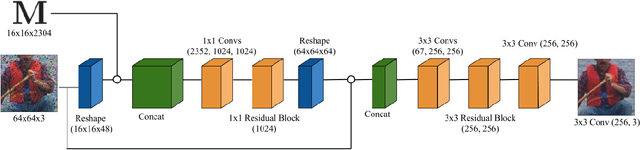

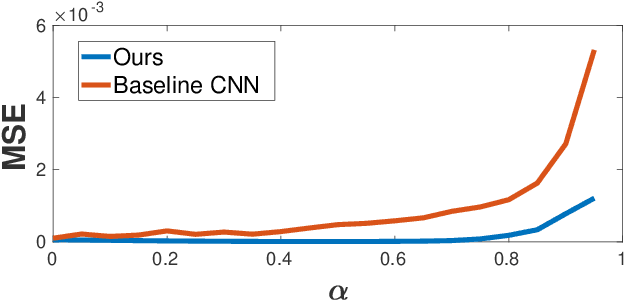
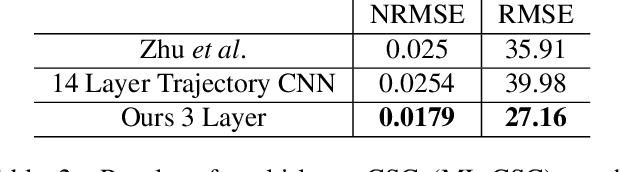
Reconstruction tasks in computer vision aim fundamentally to recover an undetermined signal from a set of noisy measurements. Examples include super-resolution, image denoising, and non-rigid structure from motion, all of which have seen recent advancements through deep learning. However, earlier work made extensive use of sparse signal reconstruction frameworks (e.g convolutional sparse coding). While this work was ultimately surpassed by deep learning, it rested on a much more developed theoretical framework. Recent work by Papyan et. al provides a bridge between the two approaches by showing how a convolutional neural network (CNN) can be viewed as an approximate solution to a convolutional sparse coding (CSC) problem. In this work we argue that for some types of inverse problems the CNN approximation breaks down leading to poor performance. We argue that for these types of problems the CSC approach should be used instead and validate this argument with empirical evidence. Specifically we identify JPEG artifact reduction and non-rigid trajectory reconstruction as challenging inverse problems for CNNs and demonstrate state of the art performance on them using a CSC method. Furthermore, we offer some practical improvements to this model and its application, and also show how insights from the CSC model can be used to make CNNs effective in tasks where their naive application fails.
Unsupervised Meta-learning of Figure-Ground Segmentation via Imitating Visual Effects
Dec 20, 2018

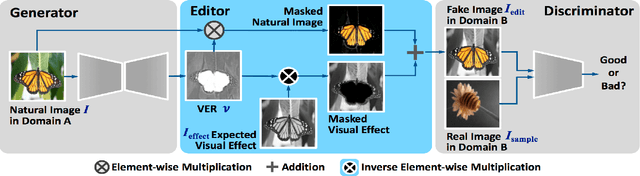
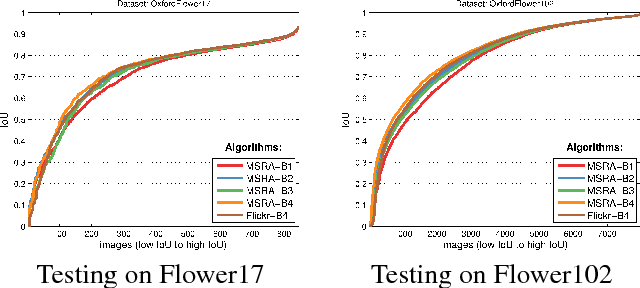
This paper presents a "learning to learn" approach to figure-ground image segmentation. By exploring webly-abundant images of specific visual effects, our method can effectively learn the visual-effect internal representations in an unsupervised manner and uses this knowledge to differentiate the figure from the ground in an image. Specifically, we formulate the meta-learning process as a compositional image editing task that learns to imitate a certain visual effect and derive the corresponding internal representation. Such a generative process can help instantiate the underlying figure-ground notion and enables the system to accomplish the intended image segmentation. Whereas existing generative methods are mostly tailored to image synthesis or style transfer, our approach offers a flexible learning mechanism to model a general concept of figure-ground segmentation from unorganized images that have no explicit pixel-level annotations. We validate our approach via extensive experiments on six datasets to demonstrate that the proposed model can be end-to-end trained without ground-truth pixel labeling yet outperforms the existing methods of unsupervised segmentation tasks.
Single Frame Image super Resolution using Learned Directionlets
Nov 10, 2010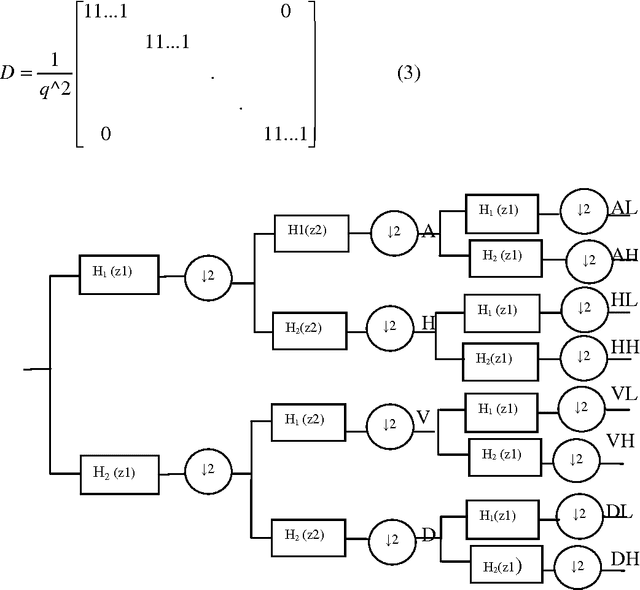
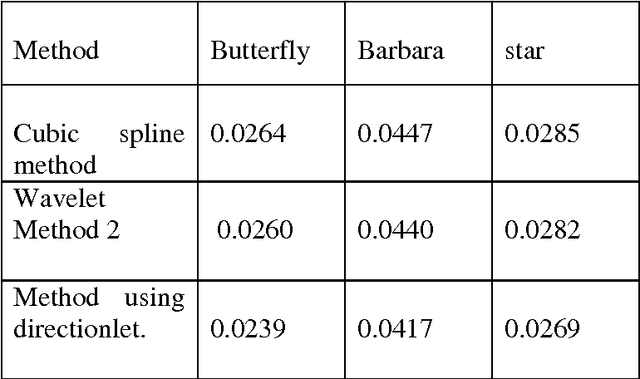
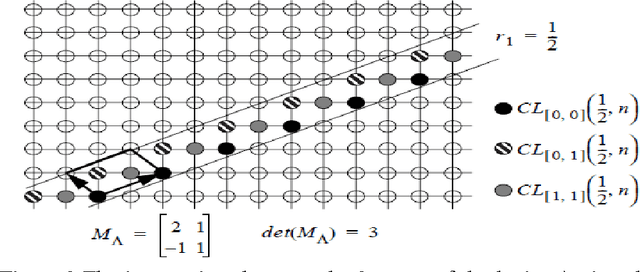
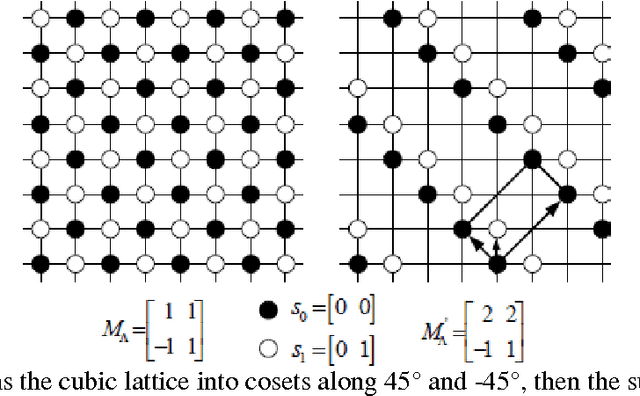
In this paper, a new directionally adaptive, learning based, single image super resolution method using multiple direction wavelet transform, called Directionlets is presented. This method uses directionlets to effectively capture directional features and to extract edge information along different directions of a set of available high resolution images .This information is used as the training set for super resolving a low resolution input image and the Directionlet coefficients at finer scales of its high-resolution image are learned locally from this training set and the inverse Directionlet transform recovers the super-resolved high resolution image. The simulation results showed that the proposed approach outperforms standard interpolation techniques like Cubic spline interpolation as well as standard Wavelet-based learning, both visually and in terms of the mean squared error (mse) values. This method gives good result with aliased images also.
* 14 pages,6 figures
Print Defect Mapping with Semantic Segmentation
Jan 27, 2020

Efficient automated print defect mapping is valuable to the printing industry since such defects directly influence customer-perceived printer quality and manually mapping them is cost-ineffective. Conventional methods consist of complicated and hand-crafted feature engineering techniques, usually targeting only one type of defect. In this paper, we propose the first end-to-end framework to map print defects at pixel level, adopting an approach based on semantic segmentation. Our framework uses Convolutional Neural Networks, specifically DeepLab-v3+, and achieves promising results in the identification of defects in printed images. We use synthetic training data by simulating two types of print defects and a print-scan effect with image processing and computer graphic techniques. Compared with conventional methods, our framework is versatile, allowing two inference strategies, one being near real-time and providing coarser results, and the other focusing on offline processing with more fine-grained detection. Our model is evaluated on a dataset of real printed images.
Automatic Estimation of Live Coffee Leaf Infection based on Image Processing Techniques
Feb 24, 2014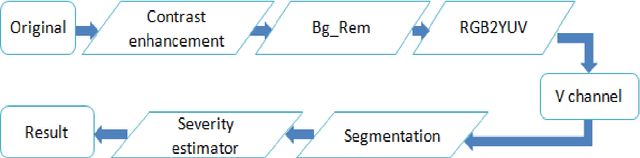
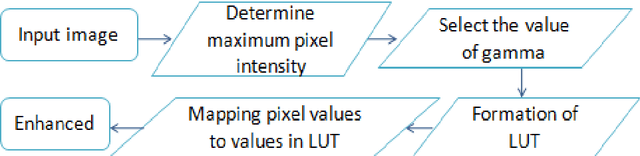
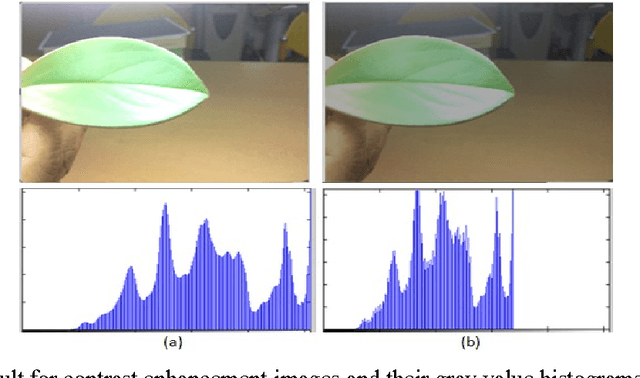
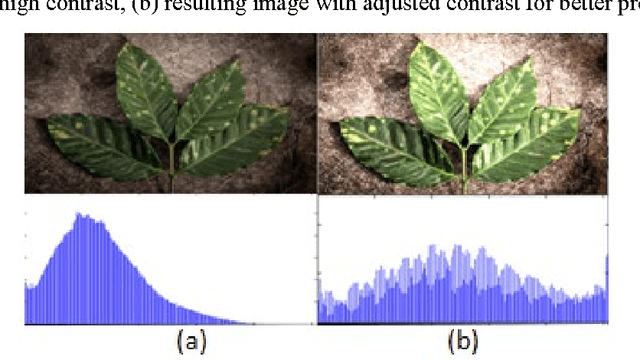
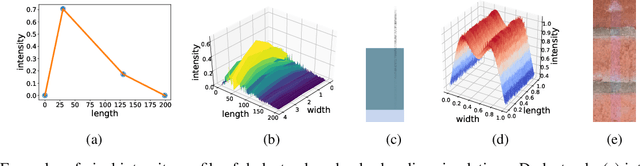
Image segmentation is the most challenging issue in computer vision applications. And most difficulties for crops management in agriculture are the lack of appropriate methods for detecting the leaf damage for pests treatment. In this paper we proposed an automatic method for leaf damage detection and severity estimation of coffee leaf by avoiding defoliation. After enhancing the contrast of the original image using LUT based gamma correction, the image is processed to remove the background, and the output leaf is clustered using Fuzzy c-means segmentation in V channel of YUV color space to maximize all leaf damage detection, and finally, the severity of leaf is estimated in terms of ratio for leaf pixel distribution between the normal and the detected leaf damage. The results in each proposed method was compared to the current researches and the accuracy is obvious either in the background removal or damage detection.
A Comparative Study of Filtering Approaches Applied to Color Archival Document Images
Aug 16, 2019
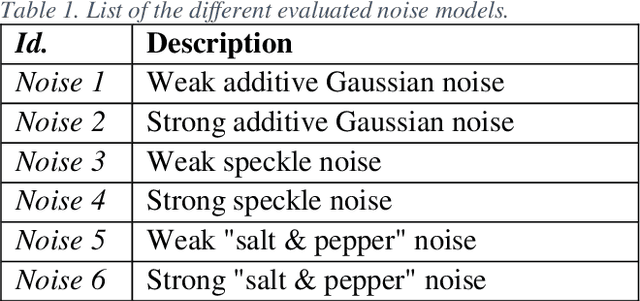

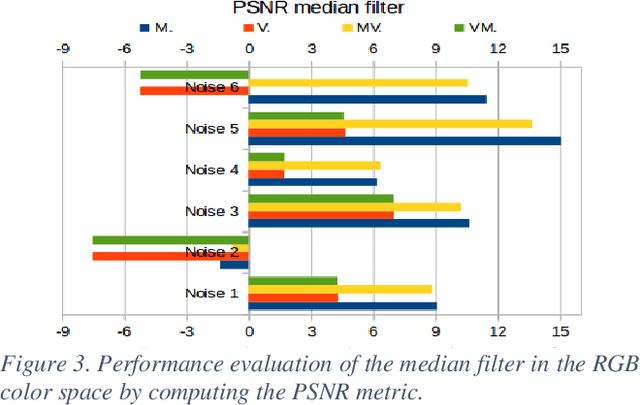
Current systems used by the Tunisian national archives for the automatic transcription of archival documents are hindered by many issues related to the performance of the optical character recognition (OCR) tools. Indeed, using a classical OCR system to transcribe and index ancient Arabic documents is not a straightforward task due to the idiosyncrasies of this category of documents, such as noise and degradation. Thus, applying an enhancement method or a denoising technique remains an essential prerequisite step to ease the archival document image analysis task. The state-of-the-art methods addressing the use of degraded document image enhancement and denoising are mainly based on applying filters. The most common filtering techniques applied to color images in the literature may be categorized into four approaches: scalar, marginal, vector and hybrid. To provide a set of comprehensive guidelines on the strengths and weaknesses of these filtering approaches, a thorough comparative study is proposed in this article. Numerical experiments are carried out in this study on color archival document images to show and quantify the performance of each assessed filtering approach.