 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Paper and Code
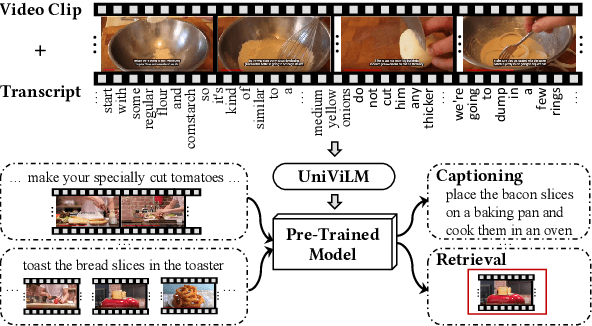
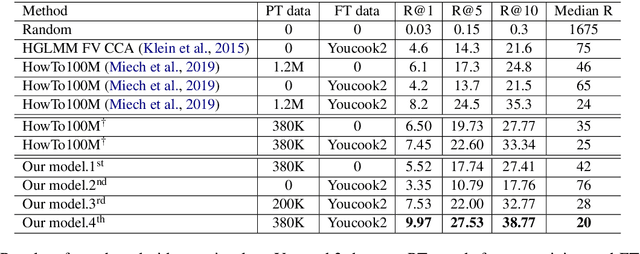
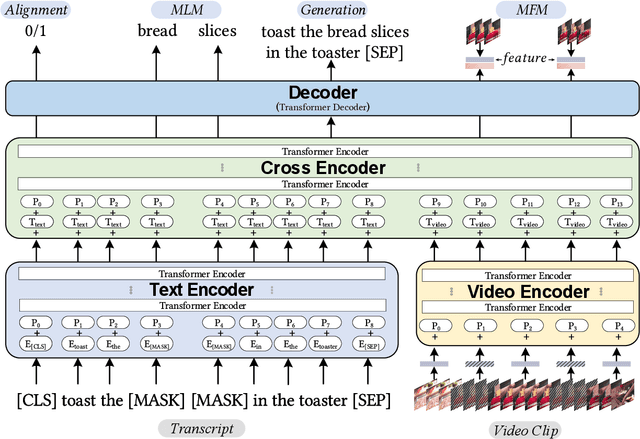
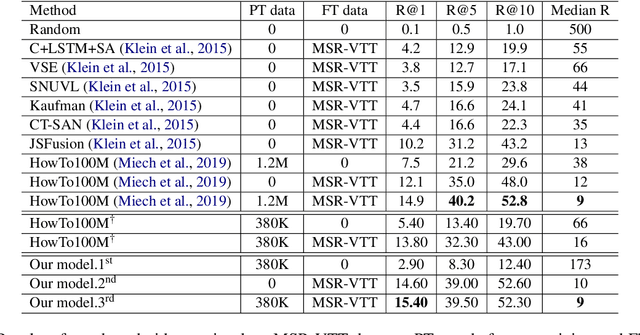
We propose UniViLM: a Unified Video and Language pre-training Model for multimodal understanding and generation. Motivated by the recent success of BERT based pre-training technique for NLP and image-language tasks, VideoBERT and CBT are proposed to exploit BERT model for video and language pre-training using narrated instructional videos. Different from their works which only pre-train understanding task, we propose a unified video-language pre-training model for both understanding and generation tasks. Our model comprises of 4 components including two single-modal encoders, a cross encoder and a decoder with the Transformer backbone. We first pre-train our model to learn the universal representation for both video and language on a large instructional video dataset. Then we fine-tune the model on two multimodal tasks including understanding task (text-based video retrieval) and generation task (multimodal video captioning). Our extensive experiments show that our method can improve the performance of both understanding and generation tasks and achieves the state-of-the art results.