 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Meta-learning of Figure-Ground Segmentation via Imitating Visual Effects
Paper and Code


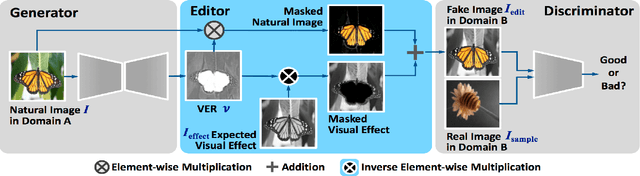
This paper presents a "learning to learn" approach to figure-ground image segmentation. By exploring webly-abundant images of specific visual effects, our method can effectively learn the visual-effect internal representations in an unsupervised manner and uses this knowledge to differentiate the figure from the ground in an image. Specifically, we formulate the meta-learning process as a compositional image editing task that learns to imitate a certain visual effect and derive the corresponding internal representation. Such a generative process can help instantiate the underlying figure-ground notion and enables the system to accomplish the intended image segmentation. Whereas existing generative methods are mostly tailored to image synthesis or style transfer, our approach offers a flexible learning mechanism to model a general concept of figure-ground segmentation from unorganized images that have no explicit pixel-level annotations. We validate our approach via extensive experiments on six datasets to demonstrate that the proposed model can be end-to-end trained without ground-truth pixel labeling yet outperforms the existing methods of unsupervised segmentation tasks.