 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Spatially-Adaptive Normalization
Apr 06, 2020
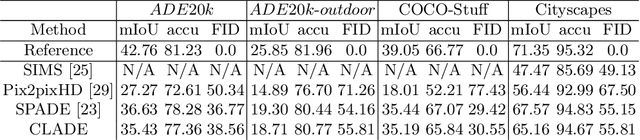
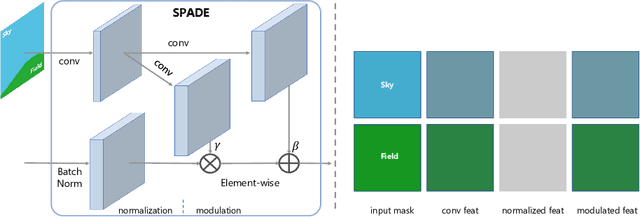


Spatially-adaptive normalization is remarkably successful recently in conditional semantic image synthesis, which modulates the normalized activation with spatially-varying transformations learned from semantic layouts, to preserve the semantic information from being washed away. Despite its impressive performance, a more thorough understanding of the true advantages inside the box is still highly demanded, to help reduce the significant computation and parameter overheads introduced by these new structures. In this paper, from a return-on-investment point of view, we present a deep analysis of the effectiveness of SPADE and observe that its advantages actually come mainly from its semantic-awareness rather than the spatial-adaptiveness. Inspired by this point, we propose class-adaptive normalization (CLADE), a lightweight variant that is not adaptive to spatial positions or layouts. Benefited from this design, CLADE greatly reduces the computation cost while still being able to preserve the semantic information during the generation. Extensive experiments on multiple challenging datasets demonstrate that while the resulting fidelity is on par with SPADE, its overhead is much cheaper than SPADE. Take the generator for ADE20k dataset as an example, the extra parameter and computation cost introduced by CLADE are only 4.57% and 0.07% while that of SPADE are 39.21% and 234.73% respectively.
Deep Morphological Simplification Network (MS-Net) for Guided Registration of Brain Magnetic Resonance Images
Feb 06, 2019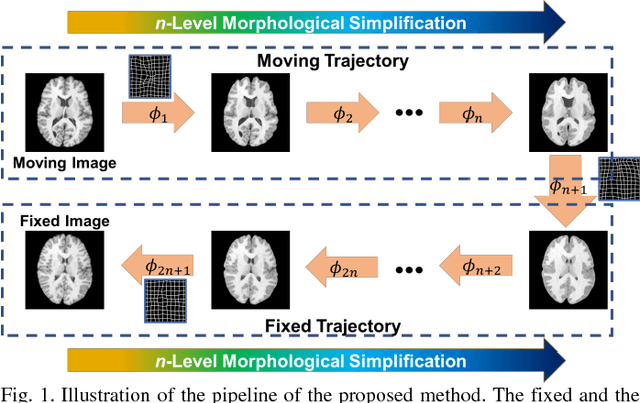
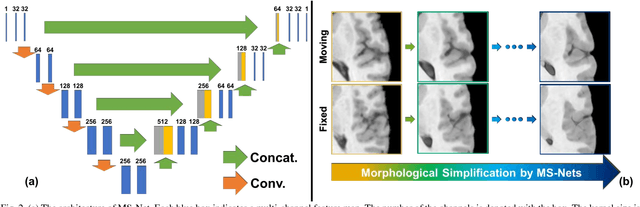
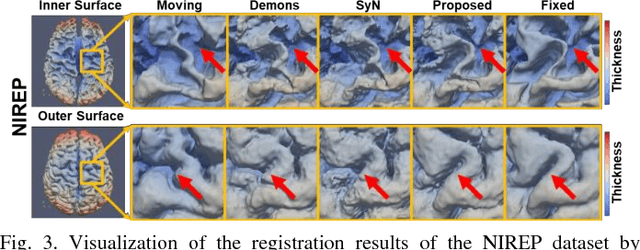
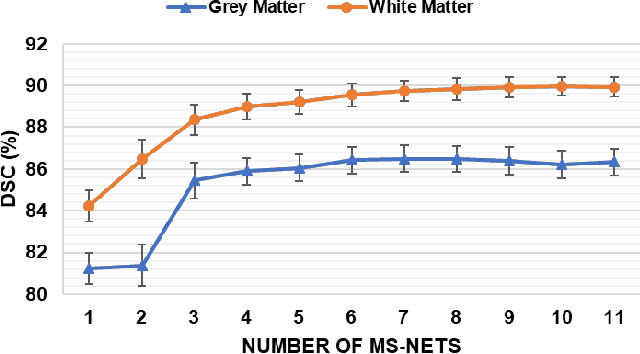
Objective: Deformable brain MR image registration is challenging due to large inter-subject anatomical variation. For example, the highly complex cortical folding pattern makes it hard to accurately align corresponding cortical structures of individual images. In this paper, we propose a novel deep learning way to simplify the difficult registration problem of brain MR images. Methods: We train a morphological simplification network (MS-Net), which can generate a "simple" image with less anatomical details based on the "complex" input. With MS-Net, the complexity of the fixed image or the moving image under registration can be reduced gradually, thus building an individual (simplification) trajectory represented by MS-Net outputs. Since the generated images at the ends of the two trajectories (of the fixed and moving images) are so simple and very similar in appearance, they are easy to register. Thus, the two trajectories can act as a bridge to link the fixed and the moving images, and guide their registration. Results: Our experiments show that the proposed method can achieve highly accurate registration performance on different datasets (i.e., NIREP, LPBA, IBSR, CUMC, and MGH). Moreover, the method can be also easily transferred across diverse image datasets and obtain superior accuracy on surface alignment. Conclusion and Significance: We propose MS-Net as a powerful and flexible tool to simplify brain MR images and their registration. To our knowledge, this is the first work to simplify brain MR image registration by deep learning, instead of estimating deformation field directly.
Re-learning of Child Model for Misclassified data by using KL Divergence in AffectNet: A Database for Facial Expression
Sep 30, 2019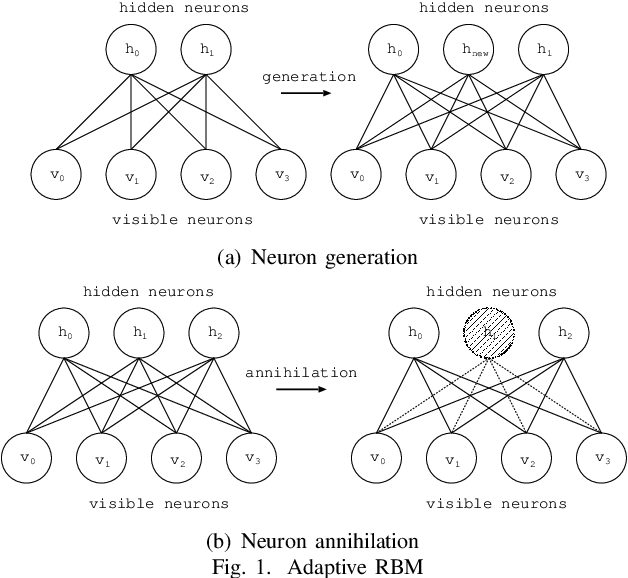
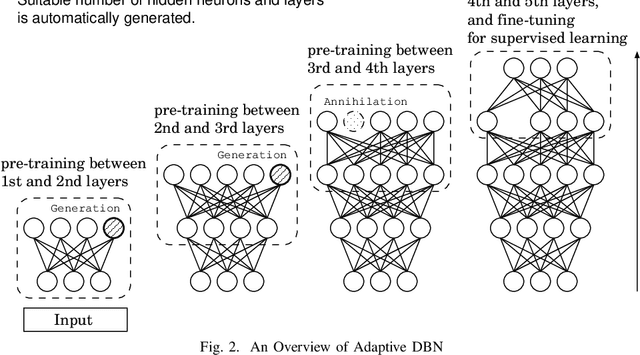

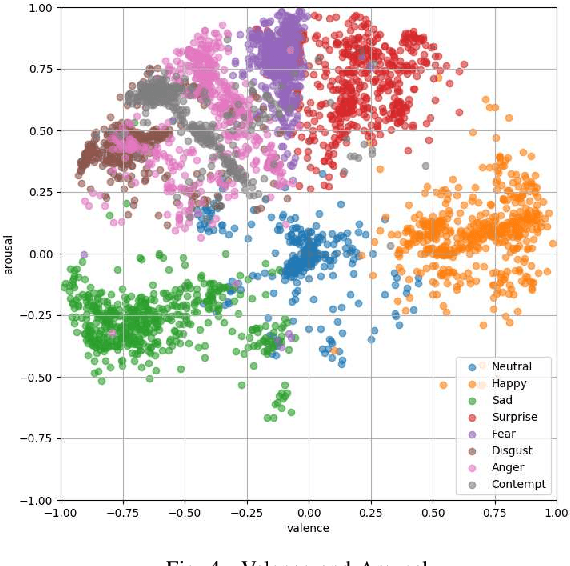
AffectNet contains more than 1,000,000 facial images which manually annotated for the presence of eight discrete facial expressions and the intensity of valence and arousal. Adaptive structural learning method of DBN (Adaptive DBN) is positioned as a top Deep learning model of classification capability for some large image benchmark databases. The Convolutional Neural Network and Adaptive DBN were trained for AffectNet and classification capability was compared. Adaptive DBN showed higher classification ratio. However, the model was not able to classify some test cases correctly because human emotions contain many ambiguous features or patterns leading wrong answer which includes the possibility of being a factor of adversarial examples, due to two or more annotators answer different subjective judgment for an image. In order to distinguish such cases, this paper investigated a re-learning model of Adaptive DBN with two or more child models, where the original trained model can be seen as a parent model and then new child models are generated for some misclassified cases. In addition, an appropriate child model was generated according to difference between two models by using KL divergence. The generated child models showed better performance to classify two emotion categories: `Disgust' and `Anger'.
Learning Similarity Metrics for Numerical Simulations
Feb 18, 2020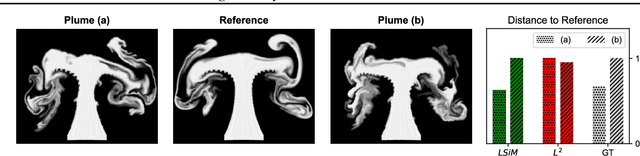
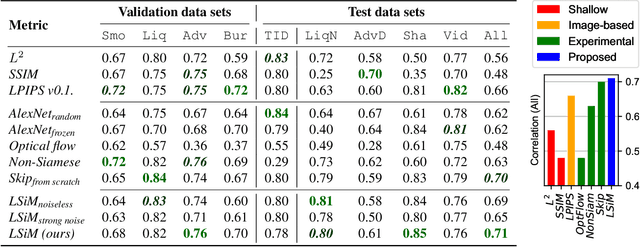
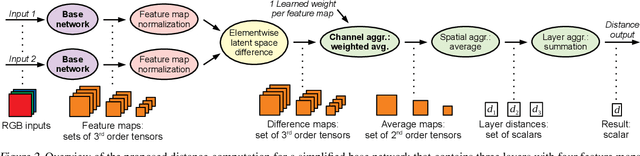
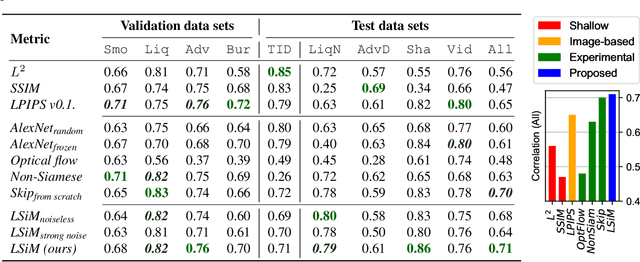
We propose a neural network-based approach that computes a stable and generalizing metric (LSiM), to compare field data from a variety of numerical simulation sources. Our method employs a Siamese network architecture that is motivated by the mathematical properties of a metric. We leverage a controllable data generation setup with partial differential equation (PDE) solvers to create increasingly different outputs from a reference simulation in a controlled environment. A central component of our learned metric is a specialized loss function that introduces knowledge about the correlation between single data samples into the training process. To demonstrate that the proposed approach outperforms existing simple metrics for vector spaces and other learned, image-based metrics, we evaluate the different methods on a large range of test data. Additionally, we analyze benefits for generalization and the impact of an adjustable training data difficulty. The robustness of LSiM is demonstrated via an evaluation on three real-world data sets.
Appearance Shock Grammar for Fast Medial Axis Extraction from Real Images
Apr 06, 2020

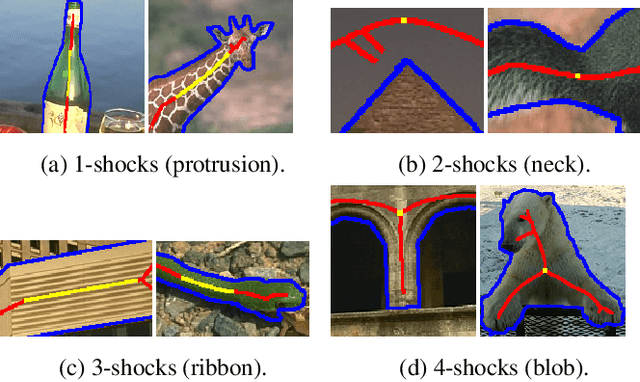
We combine ideas from shock graph theory with more recent appearance-based methods for medial axis extraction from complex natural scenes, improving upon the present best unsupervised method, in terms of efficiency and performance. We make the following specific contributions: i) we extend the shock graph representation to the domain of real images, by generalizing the shock type definitions using local, appearance-based criteria; ii) we then use the rules of a Shock Grammar to guide our search for medial points, drastically reducing run time when compared to other methods, which exhaustively consider all points in the input image;iii) we remove the need for typical post-processing steps including thinning, non-maximum suppression, and grouping, by adhering to the Shock Grammar rules while deriving the medial axis solution; iv) finally, we raise some fundamental concerns with the evaluation scheme used in previous work and propose a more appropriate alternative for assessing the performance of medial axis extraction from scenes. Our experiments on the BMAX500 and SK-LARGE datasets demonstrate the effectiveness of our approach. We outperform the present state-of-the-art, excelling particularly in the high-precision regime, while running an order of magnitude faster and requiring no post-processing.
Key Points Estimation and Point Instance Segmentation Approach for Lane Detection
Feb 18, 2020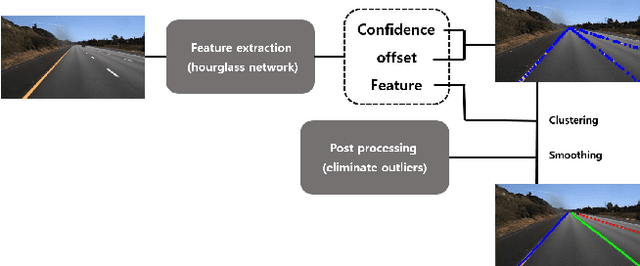
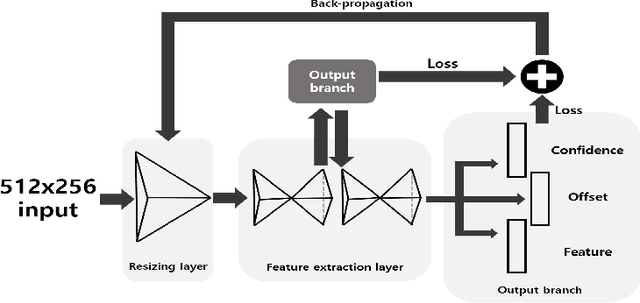
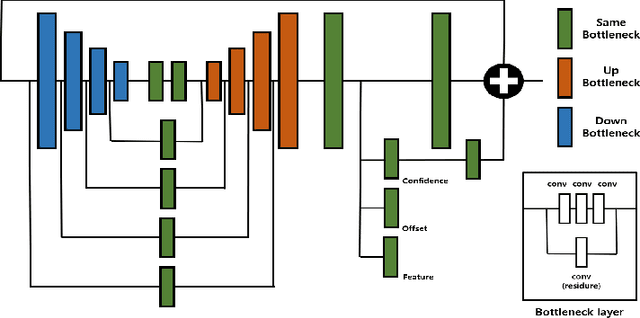

State-of-the-art lane detection methods achieve successful performance. Despite their advantages, these methods have critical deficiencies such as the limited number of detectable lanes and high false positive. In especial, high false positive can cause wrong and dangerous control. In this paper, we propose a novel lane detection method for the arbitrary number of lanes using the deep learning method, which has the lower number of false positives than other recent lane detection methods. The architecture of the proposed method has the shared feature extraction layers and several branches for detection and embedding to cluster lanes. The proposed method can generate exact points on the lanes, and we cast a clustering problem for the generated points as a point cloud instance segmentation problem. The proposed method is more compact because it generates fewer points than the original image pixel size. Our proposed post processing method eliminates outliers successfully and increases the performance notably. Whole proposed framework achieves competitive results on the tuSimple dataset.
Real-time interactive magnetic resonance (MR) temperature imaging in both aqueous and adipose tissues using cascaded deep neural networks for MR-guided focused ultrasound surgery (MRgFUS)
Aug 29, 2019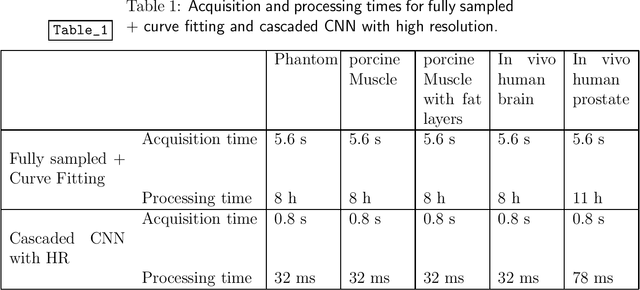
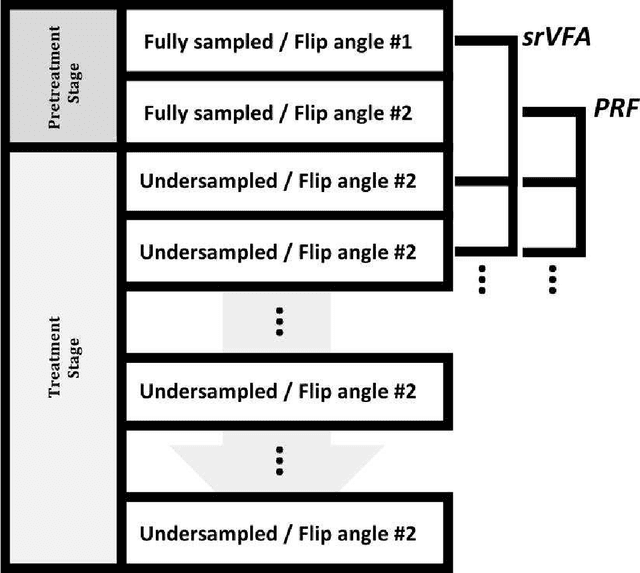
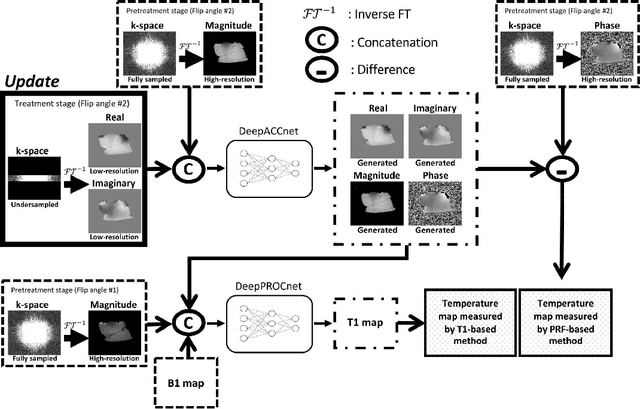
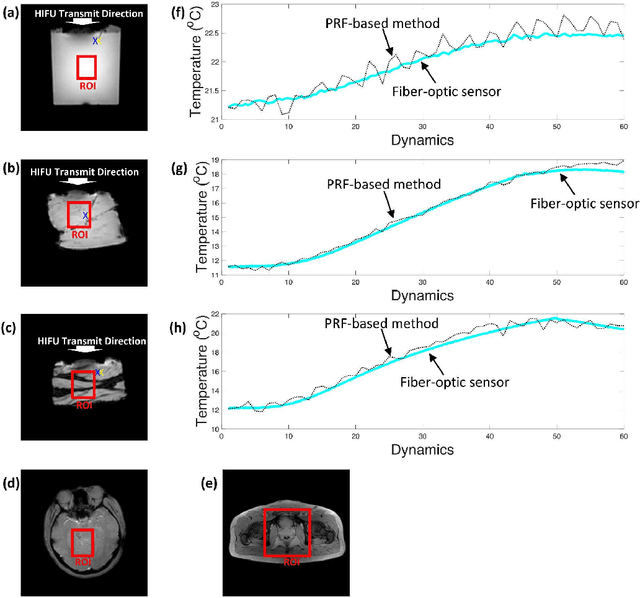
Purpose: To acquire the real-time interactive temperature map for aqueous and adipose tissue, the problems of long acquisition and processing time must be addressed. To overcome these major challenges, this paper proposes a cascaded convolutional neural network (CNN) framework and multi-echo gradient echo (meGRE) with a single reference variable flip angle (srVFA). Methods: To optimize the echo times for each method, MR images are acquired using a meGRE sequence; meGRE images with two flip angles (FAs) and meGRE images with a single FA are acquired during the pretreatment and treatment stages, respectively. These images are then processed and reconstructed by a cascaded CNN, which consists of two CNNs. The first CNN (called DeepACCnet) performs HR complex MR image reconstruction from the LR MR image acquired during the treatment stage, which is improved by the HR magnitude MR image acquired during the pretreatment stage. The second CNN (called DeepPROCnet) copes with T1 mapping. Results: Measurements of temperature and T1 changes obtained by meGRE combined with srVFA and cascaded CNNs were achieved in an agarose gel phantom, ex vivo porcine muscle, and ex vivo porcine muscle with fat layers (heating tests), and in vivo human prostate and brain (non-heating tests). In the heating test, the maximum differences between fiber-optic sensor and samples are less than 1 degree Celcius. In all cases, temperature mapping using the cascaded CNN achieved the best results in all cases. The acquisition and processing times for the proposed method are 0.8 s and 32 ms, respectively. Conclusions: Real-time interactive HR MR temperature mapping for simultaneously measuring aqueous and adipose tissue is feasible by combining a cascaded CNN with meGRE and srVFA.
Additive Angular Margin for Few Shot Learning to Classify Clinical Endoscopy Images
Mar 23, 2020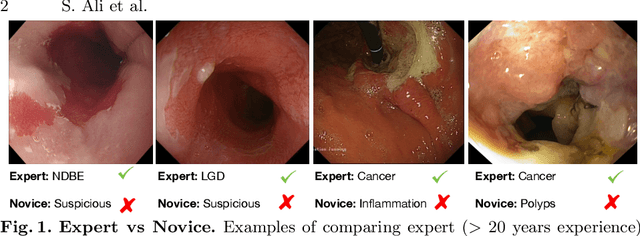
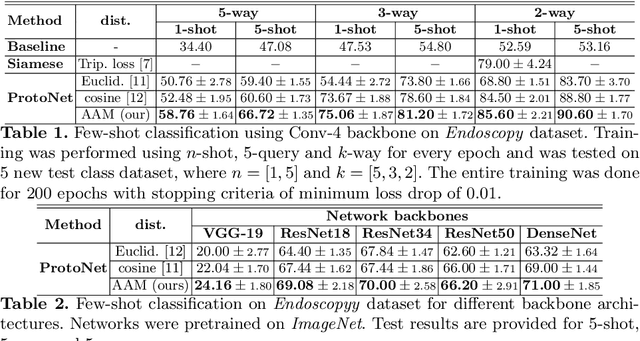
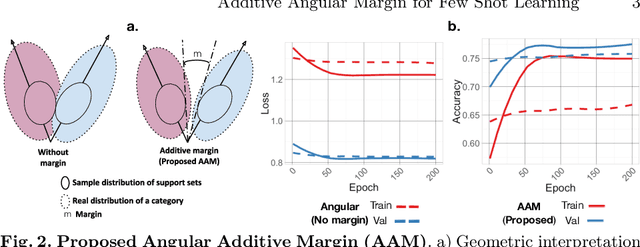
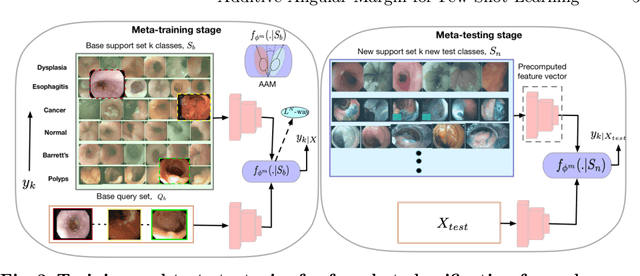
Endoscopy is a widely used imaging modality to diagnose and treat diseases in hollow organs as for example the gastrointestinal tract, the kidney and the liver. However, due to varied modalities and use of different imaging protocols at various clinical centers impose significant challenges when generalising deep learning models. Moreover, the assembly of large datasets from different clinical centers can introduce a huge label bias that renders any learnt model unusable. Also, when using new modality or presence of images with rare patterns, a bulk amount of similar image data and their corresponding labels are required for training these models. In this work, we propose to use a few-shot learning approach that requires less training data and can be used to predict label classes of test samples from an unseen dataset. We propose a novel additive angular margin metric in the framework of prototypical network in few-shot learning setting. We compare our approach to the several established methods on a large cohort of multi-center, multi-organ, and multi-modal endoscopy data. The proposed algorithm outperforms existing state-of-the-art methods.
State-of-the-Art in Retinal Optical Coherence Tomography Image Analysis
Nov 17, 2014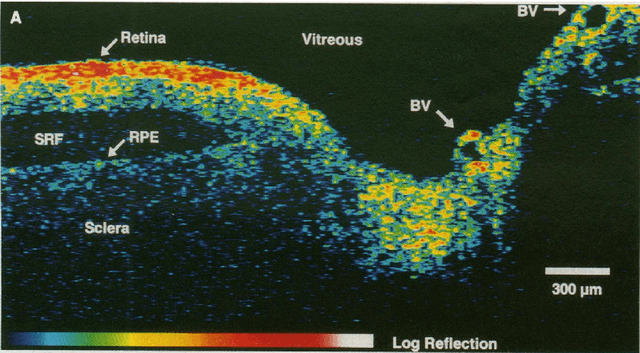
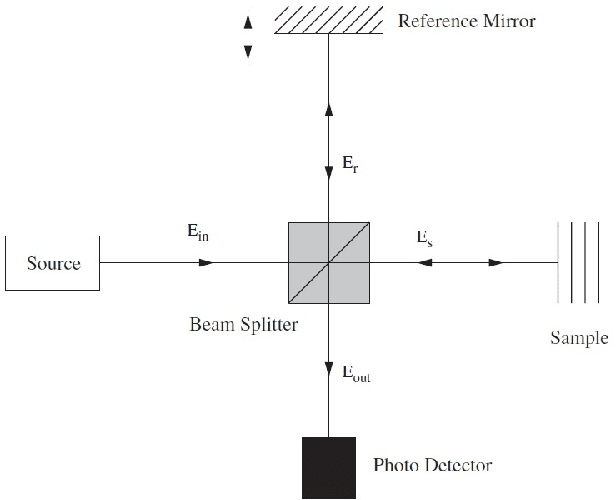

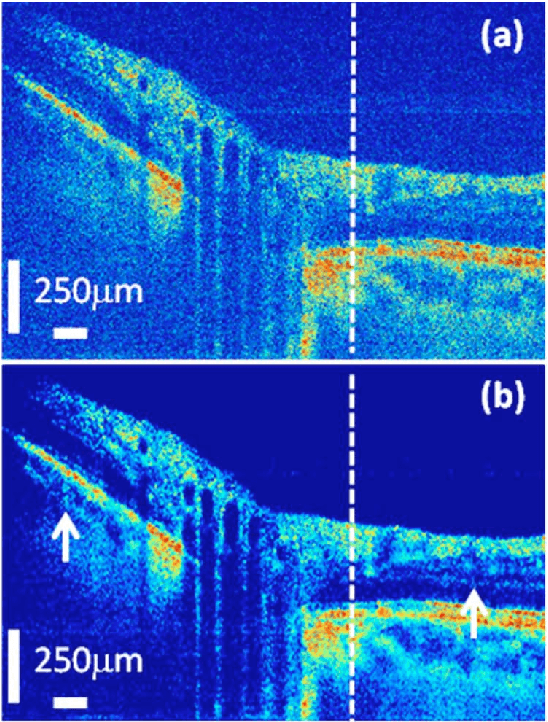
Optical Coherence Tomography (OCT) is one of the most emerging imaging modalities that has been used widely in the field of biomedical imaging. From its emergence in 1990's, plenty of hardware and software improvements have been made. Its applications range from ophthalmology to dermatology to coronary imaging etc. Here, the focus is on applications of OCT in ophthalmology and retinal imaging. OCT is able to non-invasively produce cross-sectional volume images of the tissues which are further used for analysis of the tissue structure and its properties. Due to the underlying physics, OCT images usually suffer from a granular pattern, called speckle noise, which restricts the process of interpretation, hence requiring specialized noise reduction techniques to remove the noise while preserving image details. Also, given the fact that OCT images are in the $\mu m$ -level, further analysis in needed to distinguish between the different structures in the imaged volume. Therefore the use of different segmentation techniques are of high importance. The movement of the tissue under imaging or the progression of disease in the tissue also imposes further implications both on the quality and the proper interpretation of the acquired images. Thus, use of image registration techniques can be very helpful. In this work, an overview of such image analysis techniques will be given.
Weakly Supervised Instance Segmentation by Deep Multi-Task Community Learning
Jan 30, 2020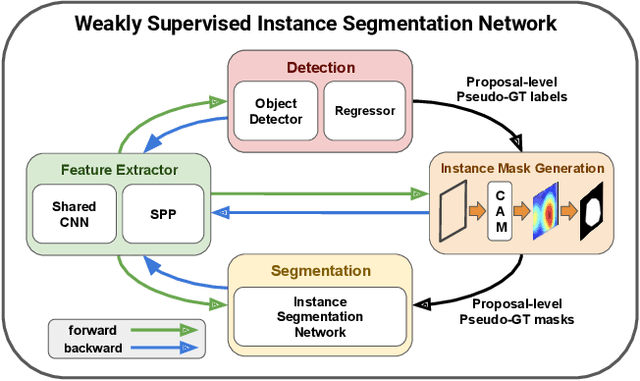
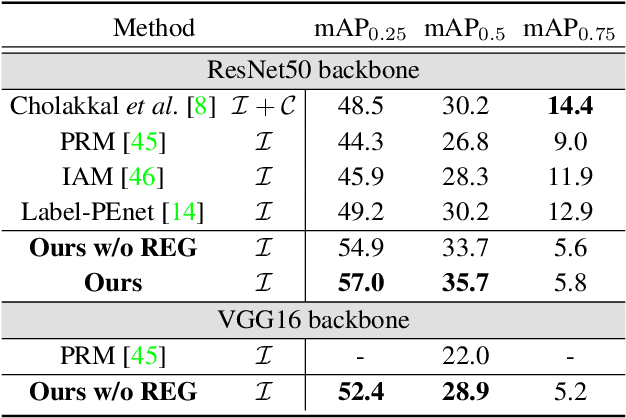
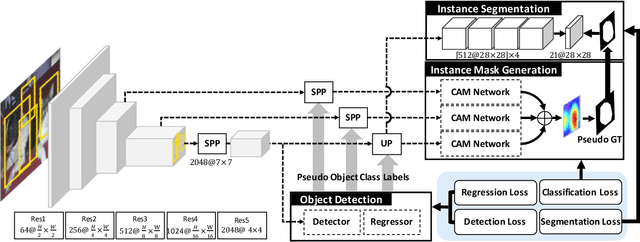
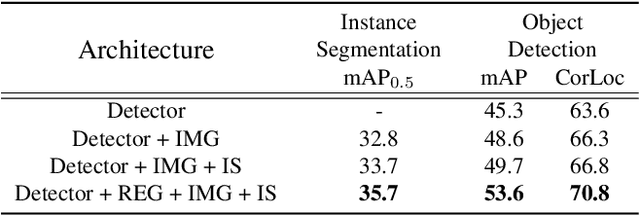
We present an object segmentation algorithm based on community learning for multiple tasks under the supervision of image-level class labels only, where individual instances of the same class are identified and segmented separately. This problem is formulated as a combination of weakly supervised object detection and semantic segmentation and is addressed by designing a unified deep neural network architecture, which has a positive feedback loop of object detection with bounding box regression, instance mask generation, instance segmentation, and feature extraction. Each component of the network makes active interactions with others to improve accuracy, and the end-to-end trainability of our model makes our results more reproducible. The proposed algorithm achieves competitive accuracy in the weakly supervised setting without any external components such as Fast R-CNN and Mask R-CNN on the standard benchmark dataset.