 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Spatially-Adaptive Normalization
Paper and Code
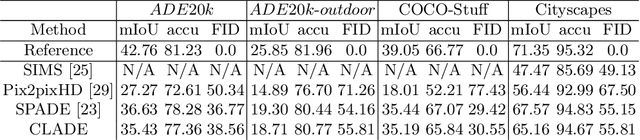
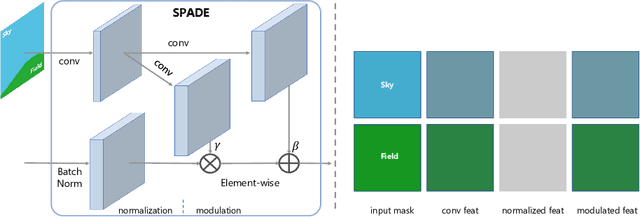


Spatially-adaptive normalization is remarkably successful recently in conditional semantic image synthesis, which modulates the normalized activation with spatially-varying transformations learned from semantic layouts, to preserve the semantic information from being washed away. Despite its impressive performance, a more thorough understanding of the true advantages inside the box is still highly demanded, to help reduce the significant computation and parameter overheads introduced by these new structures. In this paper, from a return-on-investment point of view, we present a deep analysis of the effectiveness of SPADE and observe that its advantages actually come mainly from its semantic-awareness rather than the spatial-adaptiveness. Inspired by this point, we propose class-adaptive normalization (CLADE), a lightweight variant that is not adaptive to spatial positions or layouts. Benefited from this design, CLADE greatly reduces the computation cost while still being able to preserve the semantic information during the generation. Extensive experiments on multiple challenging datasets demonstrate that while the resulting fidelity is on par with SPADE, its overhead is much cheaper than SPADE. Take the generator for ADE20k dataset as an example, the extra parameter and computation cost introduced by CLADE are only 4.57% and 0.07% while that of SPADE are 39.21% and 234.73% respectively.