 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePush it to the Demonstrated Limit: Multimodal Visuotactile Imitation Learning with Force Matching
Nov 02, 2023



Optical tactile sensors have emerged as an effective means to acquire dense contact information during robotic manipulation. A recently-introduced `see-through-your-skin' (STS) variant of this type of sensor has both visual and tactile modes, enabled by leveraging a semi-transparent surface and controllable lighting. In this work, we investigate the benefits of pairing visuotactile sensing with imitation learning for contact-rich manipulation tasks. First, we use tactile force measurements and a novel algorithm during kinesthetic teaching to yield a force profile that better matches that of the human demonstrator. Second, we add visual/tactile STS mode switching as a control policy output, simplifying the application of the sensor. Finally, we study multiple observation configurations to compare and contrast the value of visual/tactile data (both with and without mode switching) with visual data from a wrist-mounted eye-in-hand camera. We perform an extensive series of experiments on a real robotic manipulator with door-opening and closing tasks, including over 3,000 real test episodes. Our results highlight the importance of tactile sensing for imitation learning, both for data collection to allow force matching, and for policy execution to allow accurate task feedback.
Efficient Dynamics Modeling in Interactive Environments with Koopman Theory
Jul 12, 2023



The accurate modeling of dynamics in interactive environments is critical for successful long-range prediction. Such a capability could advance Reinforcement Learning (RL) and Planning algorithms, but achieving it is challenging. Inaccuracies in model estimates can compound, resulting in increased errors over long horizons. We approach this problem from the lens of Koopman theory, where the nonlinear dynamics of the environment can be linearized in a high-dimensional latent space. This allows us to efficiently parallelize the sequential problem of long-range prediction using convolution, while accounting for the agent's action at every time step. Our approach also enables stability analysis and better control over gradients through time. Taken together, these advantages result in significant improvement over the existing approaches, both in the efficiency and the accuracy of modeling dynamics over extended horizons. We also report promising experimental results in dynamics modeling for the scenarios of both model-based planning and model-free RL.
MLGCN: An Ultra Efficient Graph Convolution Neural Model For 3D Point Cloud Analysis
Mar 31, 2023The analysis of 3D point clouds has diverse applications in robotics, vision and graphics. Processing them presents specific challenges since they are naturally sparse, can vary in spatial resolution and are typically unordered. Graph-based networks to abstract features have emerged as a promising alternative to convolutional neural networks for their analysis, but these can be computationally heavy as well as memory inefficient. To address these limitations we introduce a novel Multi-level Graph Convolution Neural (MLGCN) model, which uses Graph Neural Networks (GNN) blocks to extract features from 3D point clouds at specific locality levels. Our approach employs precomputed graph KNNs, where each KNN graph is shared between GCN blocks inside a GNN block, making it both efficient and effective compared to present models. We demonstrate the efficacy of our approach on point cloud based object classification and part segmentation tasks on benchmark datasets, showing that it produces comparable results to those of state-of-the-art models while requiring up to a thousand times fewer floating-point operations (FLOPs) and having significantly reduced storage requirements. Thus, our MLGCN model could be particular relevant to point cloud based 3D shape analysis in industrial applications when computing resources are scarce.
Medial Spectral Coordinates for 3D Shape Analysis
Nov 30, 2021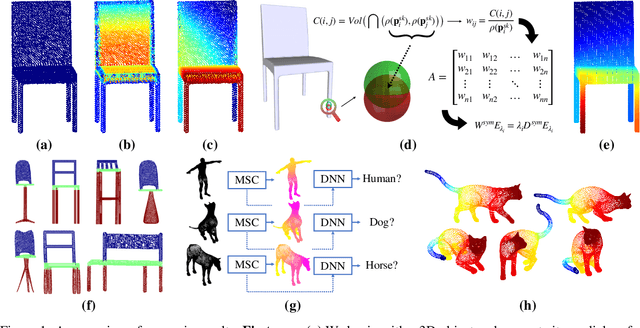
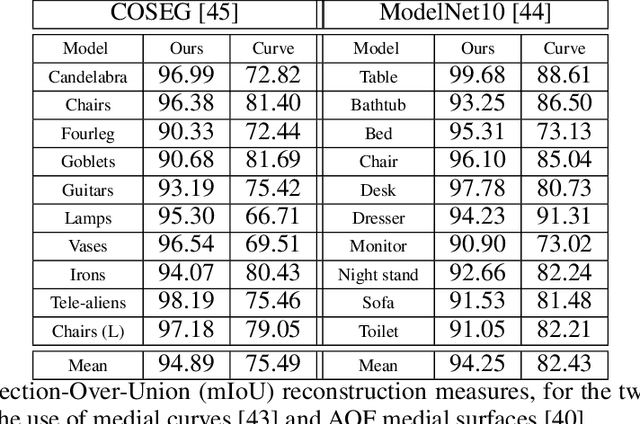
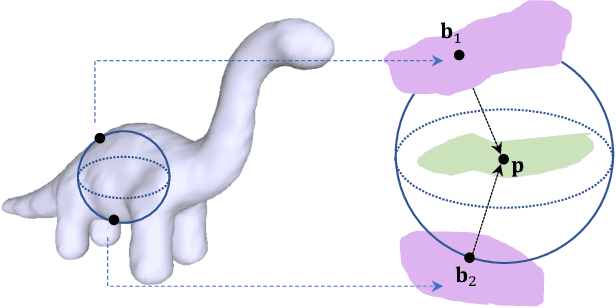
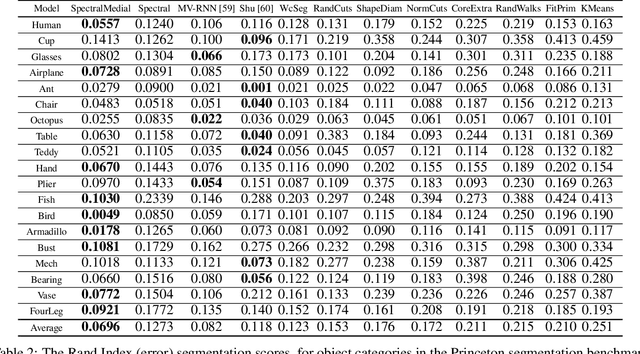
In recent years there has been a resurgence of interest in our community in the shape analysis of 3D objects represented by surface meshes, their voxelized interiors, or surface point clouds. In part, this interest has been stimulated by the increased availability of RGBD cameras, and by applications of computer vision to autonomous driving, medical imaging, and robotics. In these settings, spectral coordinates have shown promise for shape representation due to their ability to incorporate both local and global shape properties in a manner that is qualitatively invariant to isometric transformations. Yet, surprisingly, such coordinates have thus far typically considered only local surface positional or derivative information. In the present article, we propose to equip spectral coordinates with medial (object width) information, so as to enrich them. The key idea is to couple surface points that share a medial ball, via the weights of the adjacency matrix. We develop a spectral feature using this idea, and the algorithms to compute it. The incorporation of object width and medial coupling has direct benefits, as illustrated by our experiments on object classification, object part segmentation, and surface point correspondence.
Average Outward Flux Skeletons for Environment Mapping and Topology Matching
Nov 27, 2021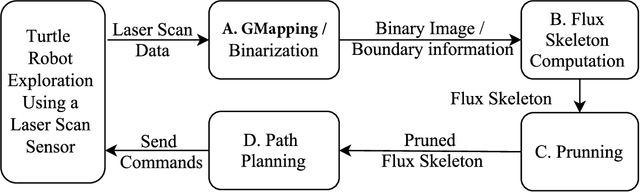
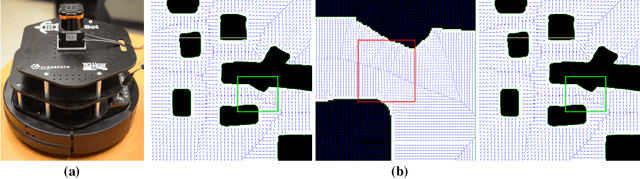
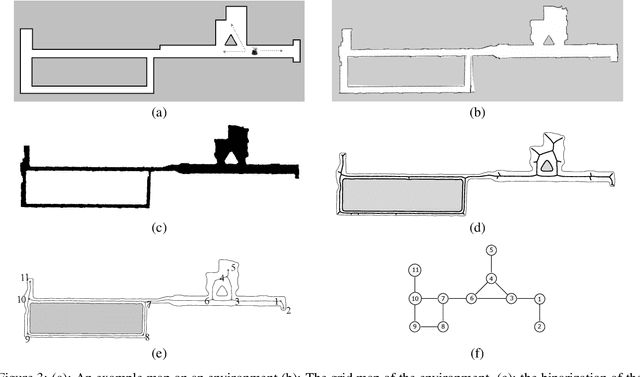
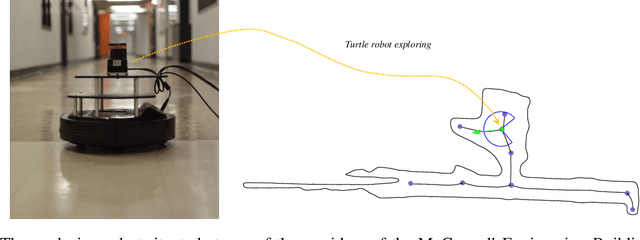
We consider how to directly extract a road map (also known as a topological representation) of an initially-unknown 2-dimensional environment via an online procedure that robustly computes a retraction of its boundaries. In this article, we first present the online construction of a topological map and the implementation of a control law for guiding the robot to the nearest unexplored area, first presented in [1]. The proposed method operates by allowing the robot to localize itself on a partially constructed map, calculate a path to unexplored parts of the environment (frontiers), compute a robust terminating condition when the robot has fully explored the environment, and achieve loop closure detection. The proposed algorithm results in smooth safe paths for the robot's navigation needs. The presented approach is any time algorithm that has the advantage that it allows for the active creation of topological maps from laser scan data, as it is being acquired. We also propose a navigation strategy based on a heuristic where the robot is directed towards nodes in the topological map that open to empty space. We then extend the work in [1] by presenting a topology matching algorithm that leverages the strengths of a particular spectral correspondence method [2], to match the mapped environments generated from our topology-making algorithm. Here, we concentrated on implementing a system that could be used to match the topologies of the mapped environment by using AOF Skeletons. In topology matching between two given maps and their AOF skeletons, we first find correspondences between points on the AOF skeletons of two different environments. We then align the (2D) points of the environments themselves. We also compute a distance measure between two given environments, based on their extracted AOF skeletons and their topology, as the sum of the matching errors between corresponding points.
Mini-batch graphs for robust image classification
Apr 22, 2021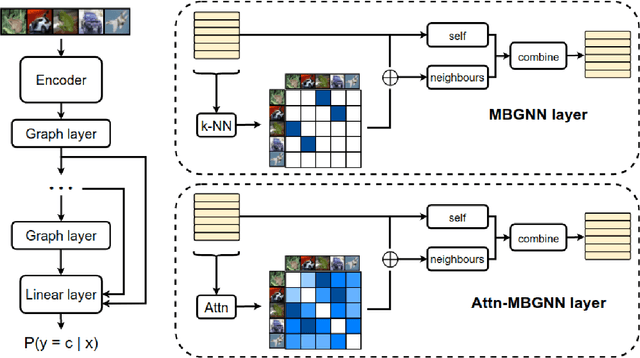
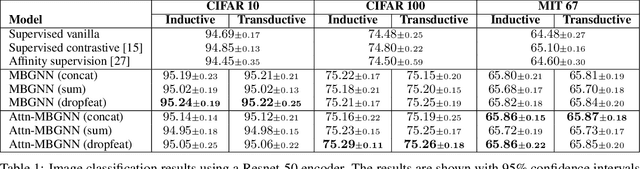
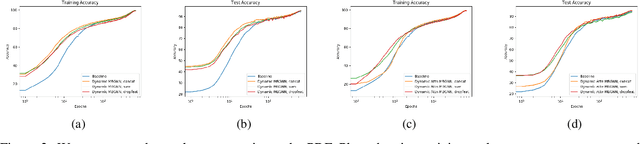

Current deep learning models for classification tasks in computer vision are trained using mini-batches. In the present article, we take advantage of the relationships between samples in a mini-batch, using graph neural networks to aggregate information from similar images. This helps mitigate the adverse effects of alterations to the input images on classification performance. Diverse experiments on image-based object and scene classification show that this approach not only improves a classifier's performance but also increases its robustness to image perturbations and adversarial attacks. Further, we also show that mini-batch graph neural networks can help to alleviate the problem of mode collapse in Generative Adversarial Networks.
Group Equivariant Deep Reinforcement Learning
Jul 01, 2020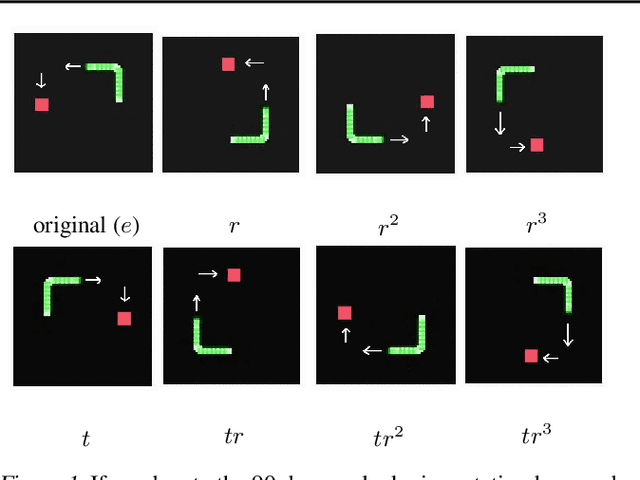
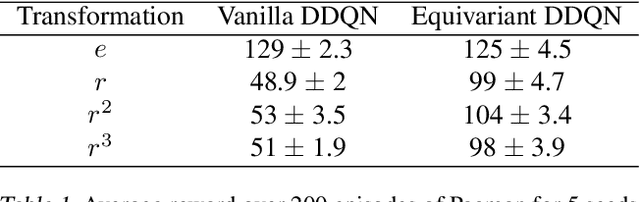
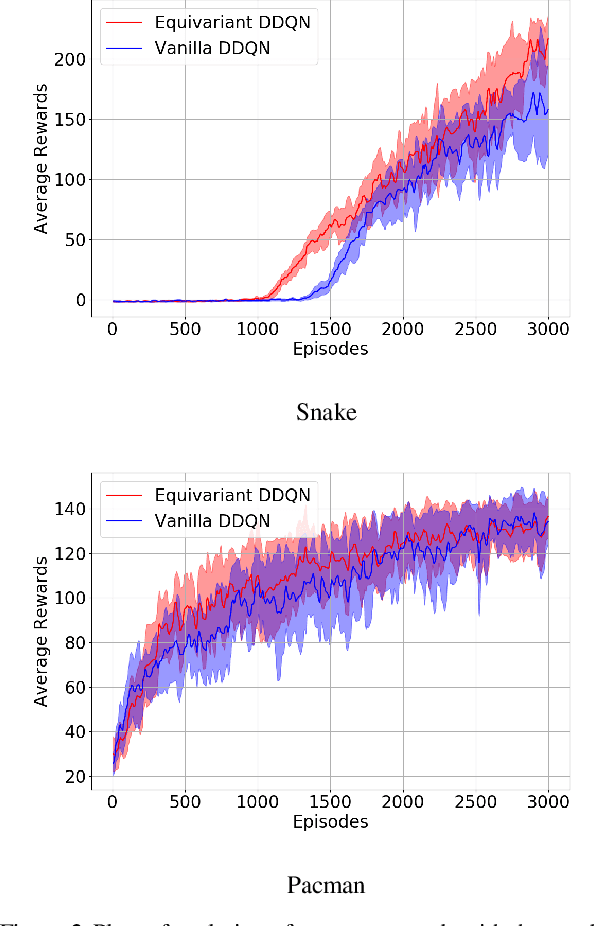
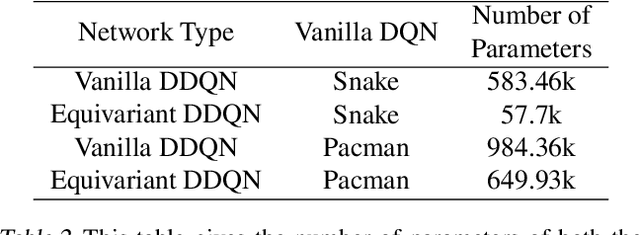
In Reinforcement Learning (RL), Convolutional Neural Networks(CNNs) have been successfully applied as function approximators in Deep Q-Learning algorithms, which seek to learn action-value functions and policies in various environments. However, to date, there has been little work on the learning of symmetry-transformation equivariant representations of the input environment state. In this paper, we propose the use of Equivariant CNNs to train RL agents and study their inductive bias for transformation equivariant Q-value approximation. We demonstrate that equivariant architectures can dramatically enhance the performance and sample efficiency of RL agents in a highly symmetric environment while requiring fewer parameters. Additionally, we show that they are robust to changes in the environment caused by affine transformations.
Appearance Shock Grammar for Fast Medial Axis Extraction from Real Images
Apr 06, 2020

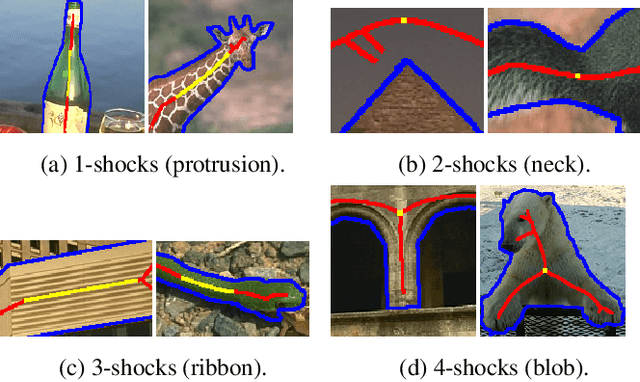
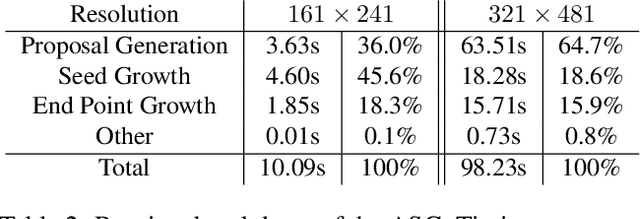
We combine ideas from shock graph theory with more recent appearance-based methods for medial axis extraction from complex natural scenes, improving upon the present best unsupervised method, in terms of efficiency and performance. We make the following specific contributions: i) we extend the shock graph representation to the domain of real images, by generalizing the shock type definitions using local, appearance-based criteria; ii) we then use the rules of a Shock Grammar to guide our search for medial points, drastically reducing run time when compared to other methods, which exhaustively consider all points in the input image;iii) we remove the need for typical post-processing steps including thinning, non-maximum suppression, and grouping, by adhering to the Shock Grammar rules while deriving the medial axis solution; iv) finally, we raise some fundamental concerns with the evaluation scheme used in previous work and propose a more appropriate alternative for assessing the performance of medial axis extraction from scenes. Our experiments on the BMAX500 and SK-LARGE datasets demonstrate the effectiveness of our approach. We outperform the present state-of-the-art, excelling particularly in the high-precision regime, while running an order of magnitude faster and requiring no post-processing.
Affinity Graph Supervision for Visual Recognition
Mar 19, 2020

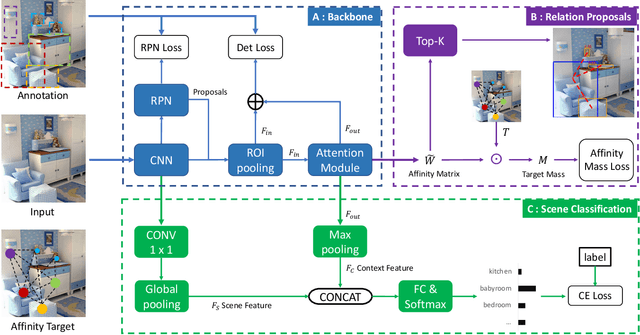

Affinity graphs are widely used in deep architectures, including graph convolutional neural networks and attention networks. Thus far, the literature has focused on abstracting features from such graphs, while the learning of the affinities themselves has been overlooked. Here we propose a principled method to directly supervise the learning of weights in affinity graphs, to exploit meaningful connections between entities in the data source. Applied to a visual attention network, our affinity supervision improves relationship recovery between objects, even without the use of manually annotated relationship labels. We further show that affinity learning between objects boosts scene categorization performance and that the supervision of affinity can also be applied to graphs built from mini-batches, for neural network training. In an image classification task we demonstrate consistent improvement over the baseline, with diverse network architectures and datasets.
Dominant Set Clustering and Pooling for Multi-View 3D Object Recognition
Jun 04, 2019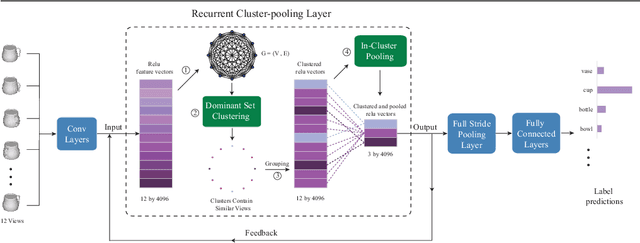
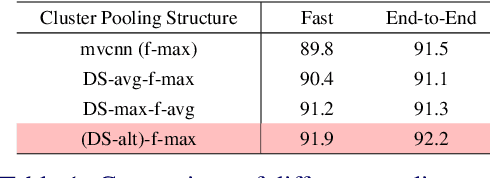
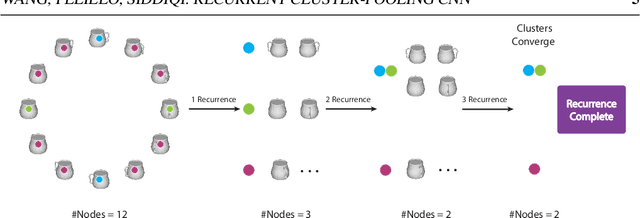
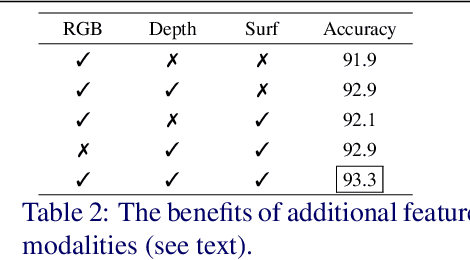
View based strategies for 3D object recognition have proven to be very successful. The state-of-the-art methods now achieve over 90% correct category level recognition performance on appearance images. We improve upon these methods by introducing a view clustering and pooling layer based on dominant sets. The key idea is to pool information from views which are similar and thus belong to the same cluster. The pooled feature vectors are then fed as inputs to the same layer, in a recurrent fashion. This recurrent clustering and pooling module, when inserted in an off-the-shelf pretrained CNN, boosts performance for multi-view 3D object recognition, achieving a new state of the art test set recognition accuracy of 93.8% on the ModelNet 40 database. We also explore a fast approximate learning strategy for our cluster-pooling CNN, which, while sacrificing end-to-end learning, greatly improves its training efficiency with only a slight reduction of recognition accuracy to 93.3%. Our implementation is available at https://github.com/fate3439/dscnn.