 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MaxUp: A Simple Way to Improve Generalization of Neural Network Training
Feb 20, 2020
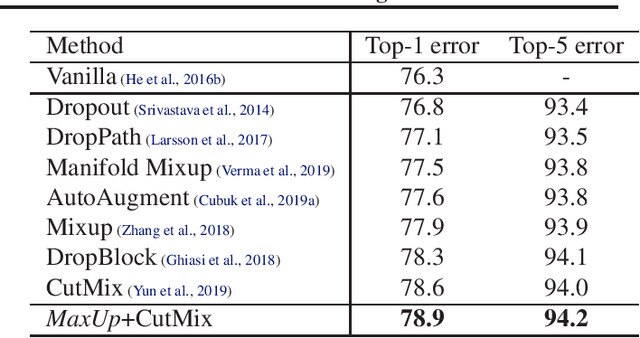
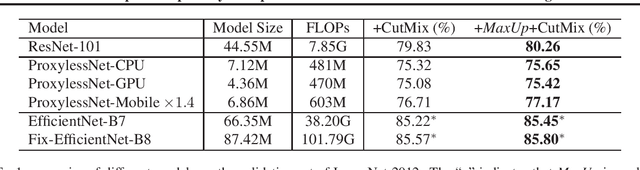
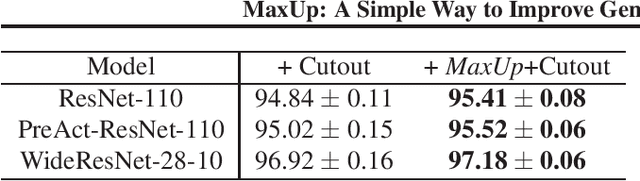

We propose \emph{MaxUp}, an embarrassingly simple, highly effective technique for improving the generalization performance of machine learning models, especially deep neural networks. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, we implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. For example, in the case of Gaussian perturbation, \emph{MaxUp} is asymptotically equivalent to using the gradient norm of the loss as a penalty to encourage smoothness. We test \emph{MaxUp} on a range of tasks, including image classification, language modeling, and adversarial certification, on which \emph{MaxUp} consistently outperforms the existing best baseline methods, without introducing substantial computational overhead. In particular, we improve ImageNet classification from the state-of-the-art top-1 accuracy $85.5\%$ without extra data to $85.8\%$. Code will be released soon.
Super-Resolution of PROBA-V Images Using Convolutional Neural Networks
Jul 03, 2019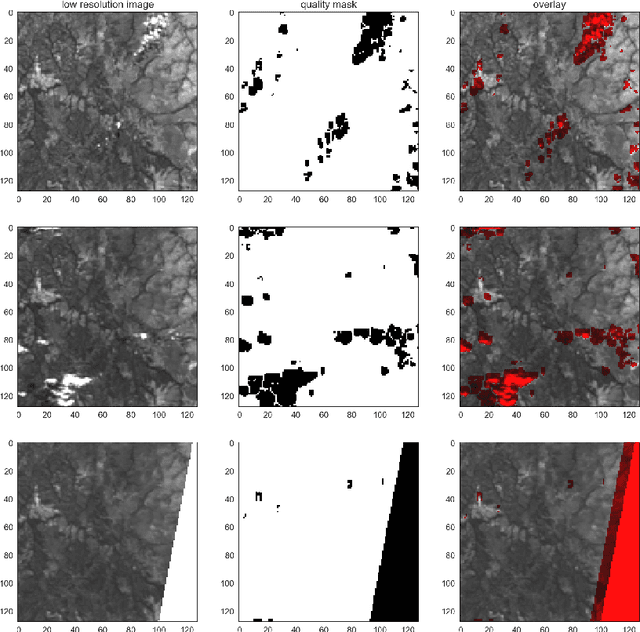
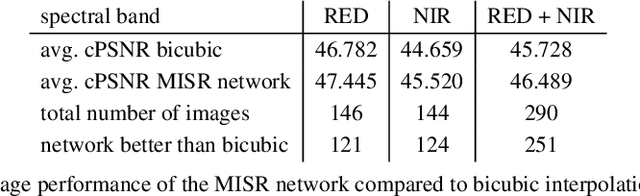
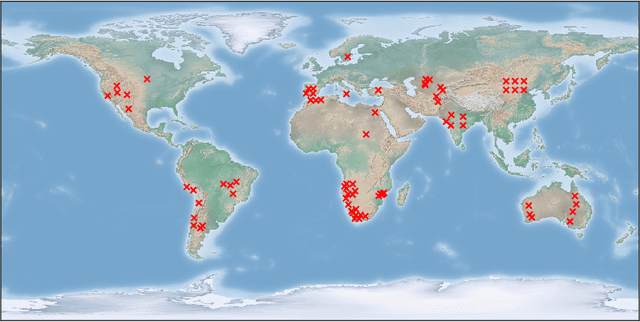
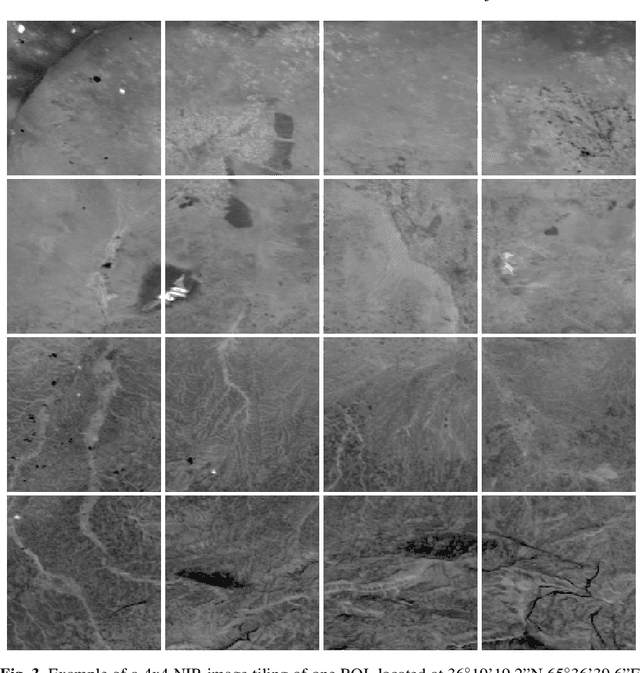
ESA's PROBA-V Earth observation satellite enables us to monitor our planet at a large scale, studying the interaction between vegetation and climate and provides guidance for important decisions on our common global future. However, the interval at which high resolution images are recorded spans over several days, in contrast to the availability of lower resolution images which is often daily. We collect an extensive dataset of both, high and low resolution images taken by PROBA-V instruments during monthly periods to investigate Multi Image Super-resolution, a technique to merge several low resolution images to one image of higher quality. We propose a convolutional neural network that is able to cope with changes in illumination, cloud coverage and landscape features which are challenges introduced by the fact that the different images are taken over successive satellite passages over the same region. Given a bicubic upscaling of low resolution images taken under optimal conditions, we find the Peak Signal to Noise Ratio of the reconstructed image of the network to be higher for a large majority of different scenes. This shows that applied machine learning has the potential to enhance large amounts of previously collected earth observation data during multiple satellite passes.
Patch-based Non-Local Bayesian Networks for Blind Confocal Microscopy Denoising
Mar 25, 2020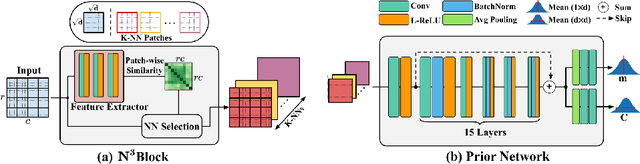
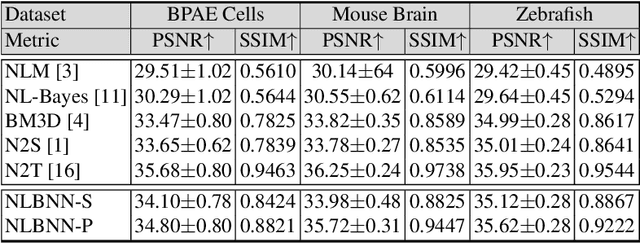
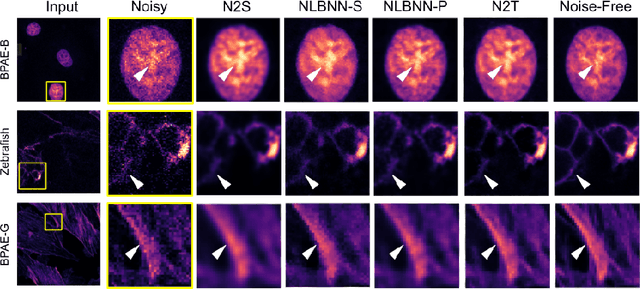
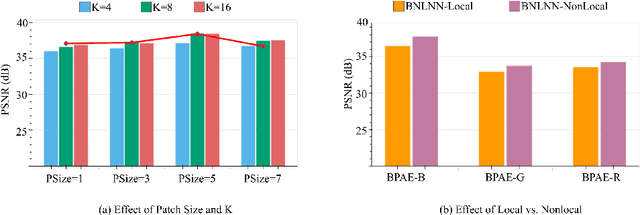
Confocal microscopy is essential for histopathologic cell visualization and quantification. Despite its significant role in biology, fluorescence confocal microscopy suffers from the presence of inherent noise during image acquisition. Non-local patch-wise Bayesian mean filtering (NLB) was until recently the state-of-the-art denoising approach. However, classic denoising methods have been outperformed by neural networks in recent years. In this work, we propose to exploit the strengths of NLB in the framework of Bayesian deep learning. We do so by designing a convolutional neural network and training it to learn parameters of a Gaussian model approximating the prior on noise-free patches given their nearest, similar yet non-local, neighbors. We then apply Bayesian reasoning to leverage the prior and information from the noisy patch in the process of approximating the noise-free patch. Specifically, we use the closed-form analytic \textit{maximum a posteriori} (MAP) estimate in the NLB algorithm to obtain the noise-free patch that maximizes the posterior distribution. The performance of our proposed method is evaluated on confocal microscopy images with real noise Poisson-Gaussian noise. Our experiments reveal the superiority of our approach against state-of-the-art unsupervised denoising techniques.
The Effects of Image Pre- and Post-Processing, Wavelet Decomposition, and Local Binary Patterns on U-Nets for Skin Lesion Segmentation
Apr 30, 2018

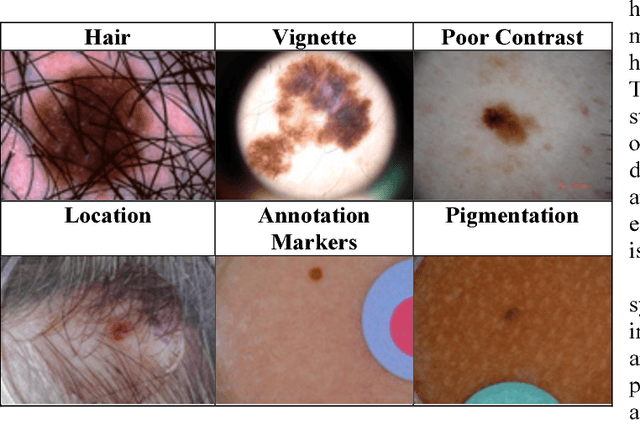

Skin cancer is a widespread, global, and potentially deadly disease, which over the last three decades has afflicted more lives in the USA than all other forms of cancer combined. There have been a lot of promising recent works utilizing deep network architectures, such as FCNs, U-Nets, and ResNets, for developing automated skin lesion segmentation. This paper investigates various pre- and post-processing techniques for improving the performance of U-Nets as measured by the Jaccard Index. The dataset provided as part of the "2017 ISBI Challenges on Skin Lesion Analysis Towards Melanoma Detection" was used for this evaluation and the performance of the finalist competitors was the standard for comparison. The pre-processing techniques employed in the proposed system included contrast enhancement, artifact removal, and vignette correction. More advanced image transformations, such as local binary patterns and wavelet decomposition, were also employed to augment the raw grayscale images used as network input features. While the performance of the proposed system fell short of the winners of the challenge, it was determined that using wavelet decomposition as an early transformation step improved the overall performance of the system over pre- and post-processing steps alone.
How to Close Sim-Real Gap? Transfer with Segmentation!
May 14, 2020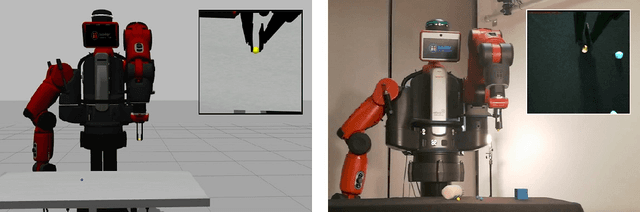
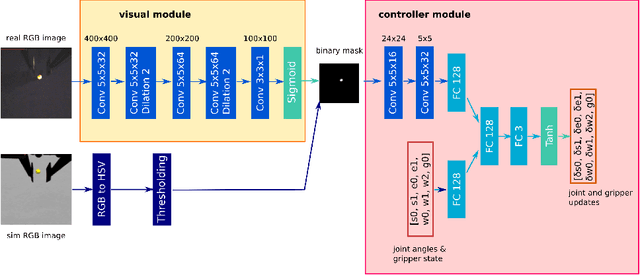
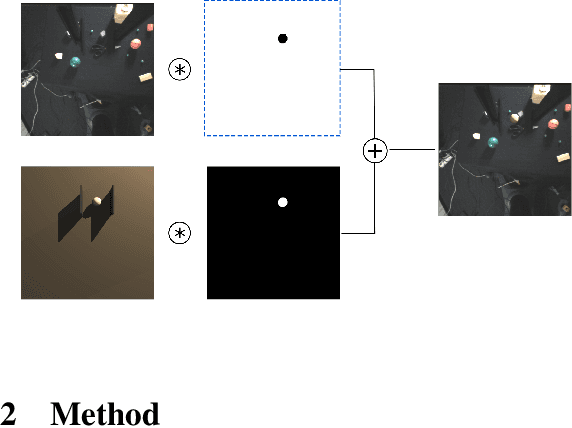
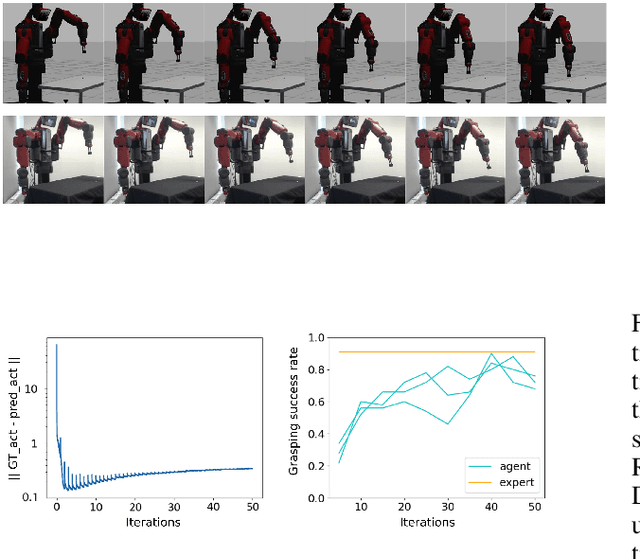
One fundamental difficulty in robotic learning is the sim-real gap problem. In this work, we propose to use segmentation as the interface between perception and control, as a domain-invariant state representation. We identify two sources of sim-real gap, one is dynamics sim-real gap, the other is visual sim-real gap. To close dynamics sim-real gap, we propose to use closed-loop control. For complex task with segmentation mask input, we further propose to learn a closed-loop model-free control policy with deep neural network using imitation learning. To close visual sim-real gap, we propose to learn a perception model in real environment using simulated target plus real background image, without using any real world supervision. We demonstrate this methodology in eye-in-hand grasping task. We train a closed-loop control policy model that taking the segmentation as input using simulation. We show that this control policy is able to transfer from simulation to real environment. The closed-loop control policy is not only robust with respect to discrepancies between the dynamic model of the simulated and real robot, but also is able to generalize to unseen scenarios where the target is moving and even learns to recover from failures. We train the perception segmentation model using training data generated by composing real background images with simulated images of the target. Combining the control policy learned from simulation with the perception model, we achieve an impressive $\bf{88\%}$ success rate in grasping a tiny sphere with a real robot.
A Bayes-Optimal View on Adversarial Examples
Feb 20, 2020
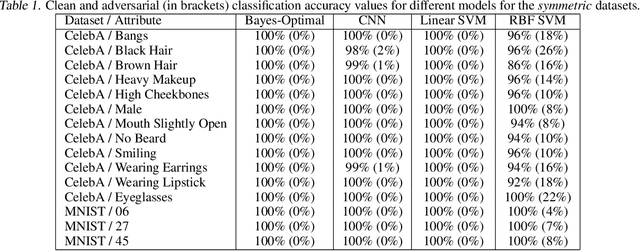

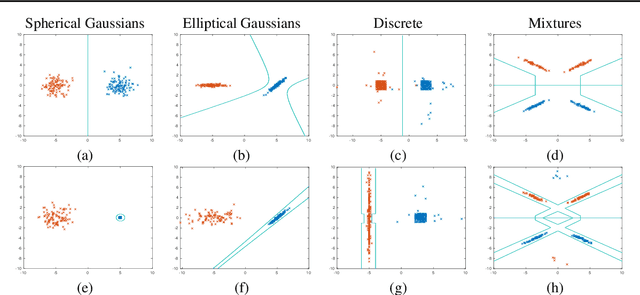
The ability to fool modern CNN classifiers with tiny perturbations of the input has lead to the development of a large number of candidate defenses and often conflicting explanations. In this paper, we argue for examining adversarial examples from the perspective of Bayes-Optimal classification. We construct realistic image datasets for which the Bayes-Optimal classifier can be efficiently computed and derive analytic conditions on the distributions so that the optimal classifier is either robust or vulnerable. By training different classifiers on these datasets (for which the "gold standard" optimal classifiers are known), we can disentangle the possible sources of vulnerability and avoid the accuracy-robustness tradeoff that may occur in commonly used datasets. Our results show that even when the optimal classifier is robust, standard CNN training consistently learns a vulnerable classifier. At the same time, for exactly the same training data, RBF SVMs consistently learn a robust classifier. The same trend is observed in experiments with real images.
Hyperspectral Classification Based on 3D Asymmetric Inception Network with Data Fusion Transfer Learning
Feb 11, 2020
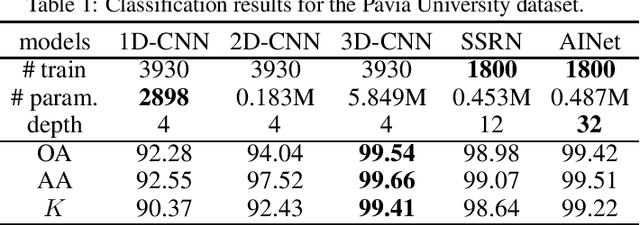
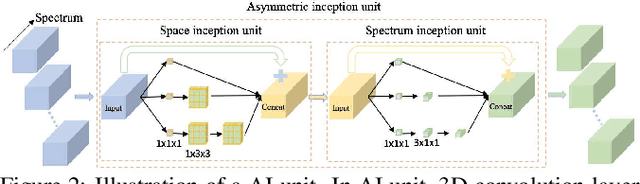
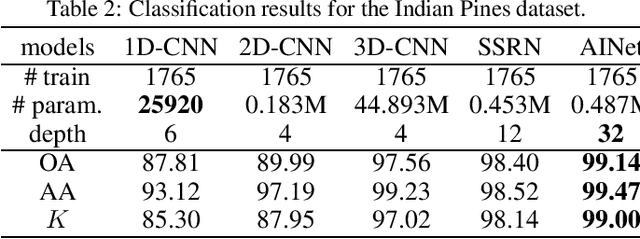
Hyperspectral image(HSI) classification has been improved with convolutional neural network(CNN) in very recent years. Being different from the RGB datasets, different HSI datasets are generally captured by various remote sensors and have different spectral configurations. Moreover, each HSI dataset only contains very limited training samples and thus it is prone to overfitting when using deep CNNs. In this paper, we first deliver a 3D asymmetric inception network, AINet, to overcome the overfitting problem. With the emphasis on spectral signatures over spatial contexts of HSI data, AINet can convey and classify the features effectively. In addition, the proposed data fusion transfer learning strategy is beneficial in boosting the classification performance. Extensive experiments show that the proposed approach beat all of the state-of-art methods on several HSI benchmarks, including Pavia University, Indian Pines and Kennedy Space Center(KSC). Code can be found at: https://github.com/UniLauX/AINet.
A Convolutional Neural Network into graph space
Feb 20, 2020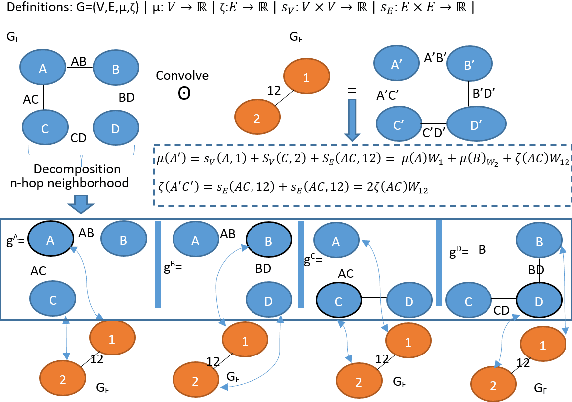

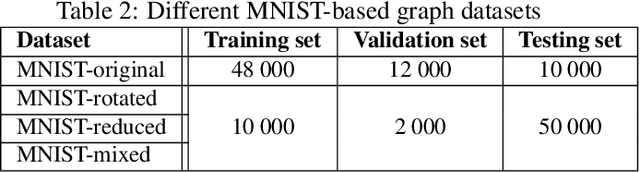
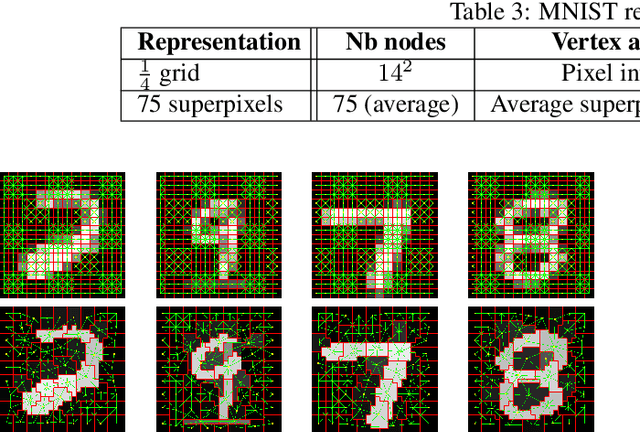
Convolutional neural networks (CNNs), in a few decades, have outperformed the existing state of the art methods in classification context. However, in the way they were formalised, CNNs are bound to operate on euclidean spaces. Indeed, convolution is a signal operation that are defined on euclidean spaces. This has restricted deep learning main use to euclidean-defined data such as sound or image. And yet, numerous computer application fields (among which network analysis, computational social science, chemo-informatics or computer graphics) induce non-euclideanly defined data such as graphs, networks or manifolds. In this paper we propose a new convolution neural network architecture, defined directly into graph space. Convolution and pooling operators are defined in graph domain. We show its usability in a back-propagation context. Experimental results show that our model performance is at state of the art level on simple tasks. It shows robustness with respect to graph domain changes and improvement with respect to other euclidean and non-euclidean convolutional architectures.
Deep Heterogeneous Hashing for Face Video Retrieval
Nov 04, 2019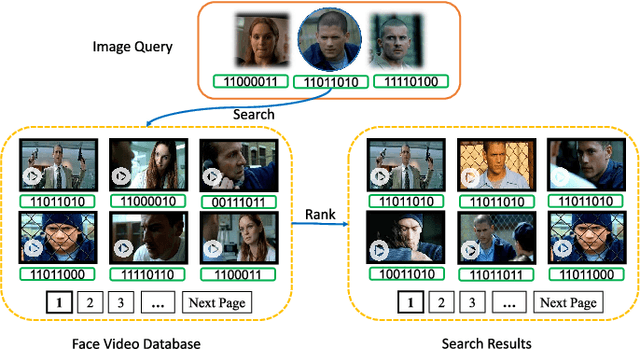
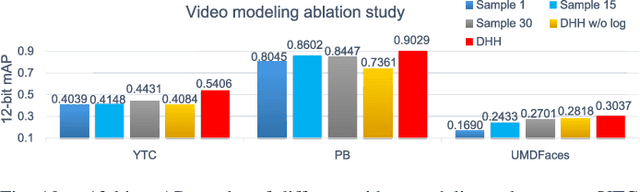
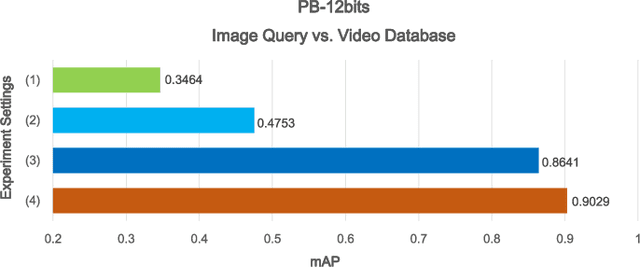
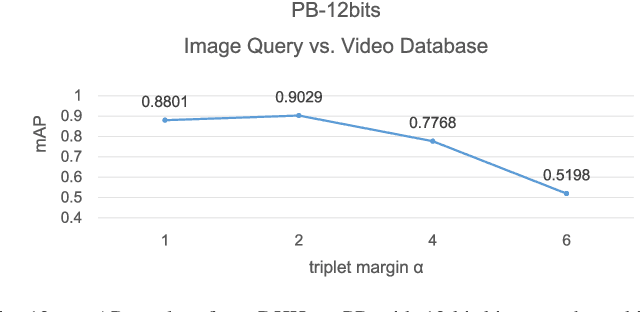
Retrieving videos of a particular person with face image as a query via hashing technique has many important applications. While face images are typically represented as vectors in Euclidean space, characterizing face videos with some robust set modeling techniques (e.g. covariance matrices as exploited in this study, which reside on Riemannian manifold), has recently shown appealing advantages. This hence results in a thorny heterogeneous spaces matching problem. Moreover, hashing with handcrafted features as done in many existing works is clearly inadequate to achieve desirable performance for this task. To address such problems, we present an end-to-end Deep Heterogeneous Hashing (DHH) method that integrates three stages including image feature learning, video modeling, and heterogeneous hashing in a single framework, to learn unified binary codes for both face images and videos. To tackle the key challenge of hashing on the manifold, a well-studied Riemannian kernel mapping is employed to project data (i.e. covariance matrices) into Euclidean space and thus enables to embed the two heterogeneous representations into a common Hamming space, where both intra-space discriminability and inter-space compatibility are considered. To perform network optimization, the gradient of the kernel mapping is innovatively derived via structured matrix backpropagation in a theoretically principled way. Experiments on three challenging datasets show that our method achieves quite competitive performance compared with existing hashing methods.
* 14 pages, 17 figures, 4 tables, accepted by IEEE Transactions on Image Processing (TIP) 2019
Vision-to-Language Tasks Based on Attributes and Attention Mechanism
May 29, 2019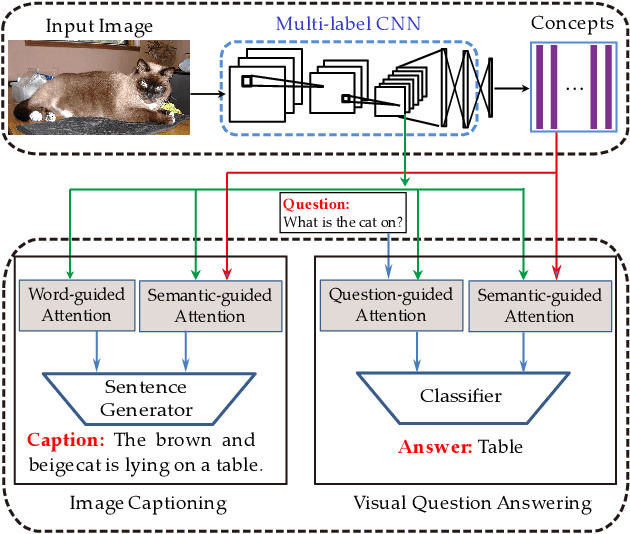
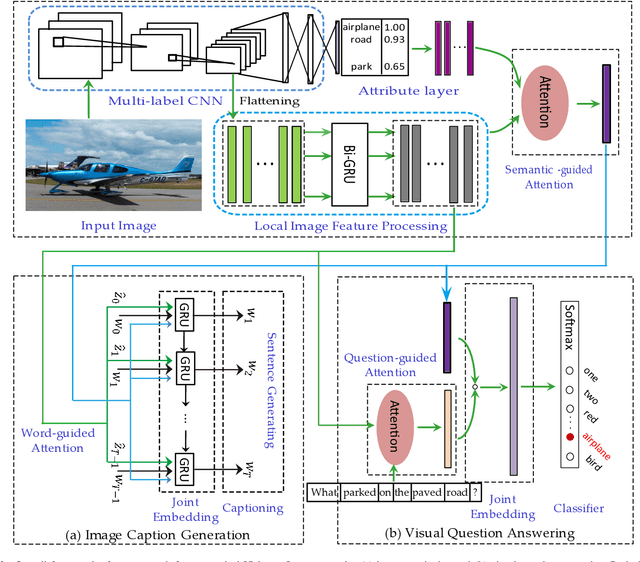
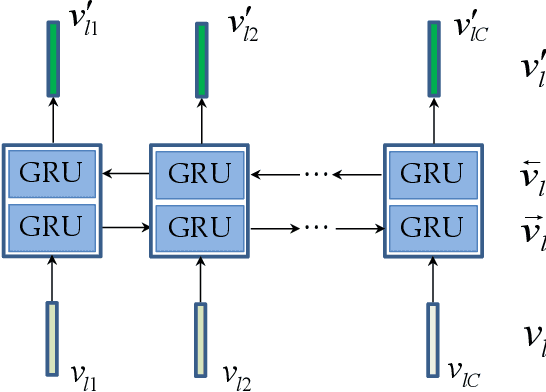
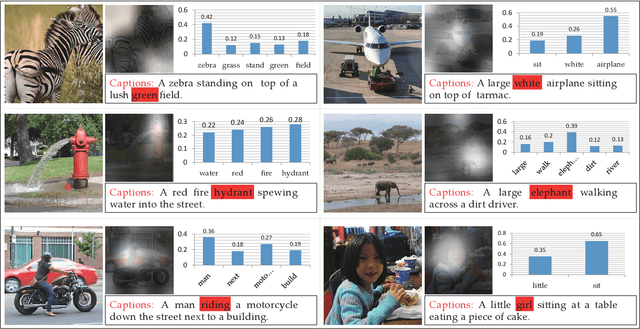
Vision-to-language tasks aim to integrate computer vision and natural language processing together, which has attracted the attention of many researchers. For typical approaches, they encode image into feature representations and decode it into natural language sentences. While they neglect high-level semantic concepts and subtle relationships between image regions and natural language elements. To make full use of these information, this paper attempt to exploit the text guided attention and semantic-guided attention (SA) to find the more correlated spatial information and reduce the semantic gap between vision and language. Our method includes two level attention networks. One is the text-guided attention network which is used to select the text-related regions. The other is SA network which is used to highlight the concept-related regions and the region-related concepts. At last, all these information are incorporated to generate captions or answers. Practically, image captioning and visual question answering experiments have been carried out, and the experimental results have shown the excellent performance of the proposed approach.