 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxUp: A Simple Way to Improve Generalization of Neural Network Training
Paper and Code
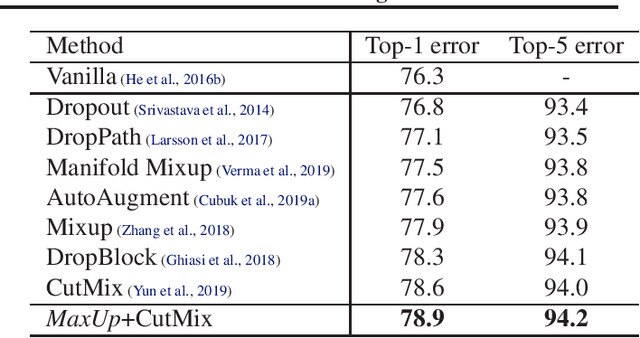
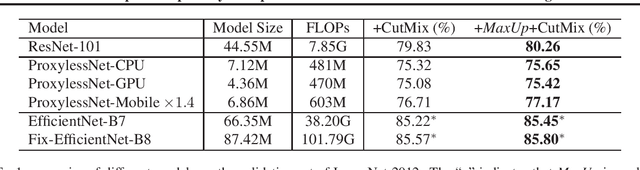
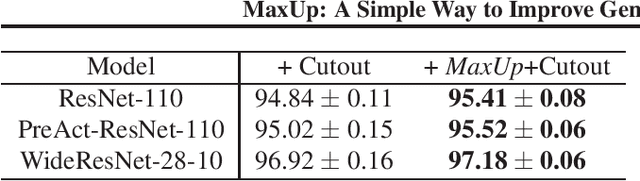

We propose \emph{MaxUp}, an embarrassingly simple, highly effective technique for improving the generalization performance of machine learning models, especially deep neural networks. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, we implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. For example, in the case of Gaussian perturbation, \emph{MaxUp} is asymptotically equivalent to using the gradient norm of the loss as a penalty to encourage smoothness. We test \emph{MaxUp} on a range of tasks, including image classification, language modeling, and adversarial certification, on which \emph{MaxUp} consistently outperforms the existing best baseline methods, without introducing substantial computational overhead. In particular, we improve ImageNet classification from the state-of-the-art top-1 accuracy $85.5\%$ without extra data to $85.8\%$. Code will be released soon.