 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Mar 19, 2020
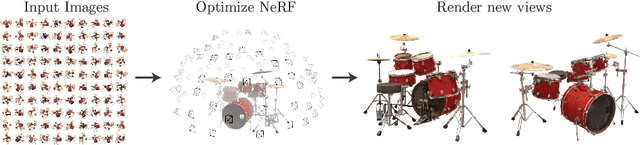
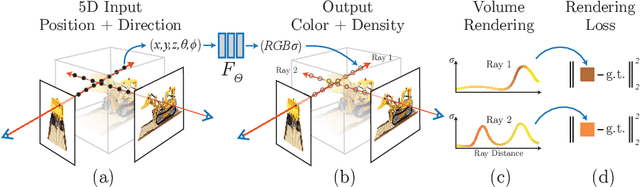

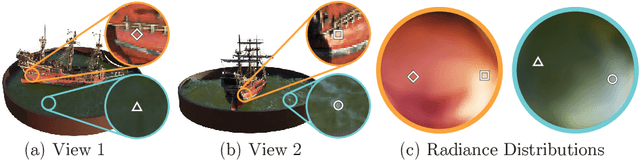
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-connected (non-convolutional) deep network, whose input is a single continuous 5D coordinate (spatial location $(x,y,z)$ and viewing direction $(\theta, \phi)$) and whose output is the volume density and view-dependent emitted radiance at that spatial location. We synthesize views by querying 5D coordinates along camera rays and use classic volume rendering techniques to project the output colors and densities into an image. Because volume rendering is naturally differentiable, the only input required to optimize our representation is a set of images with known camera poses. We describe how to effectively optimize neural radiance fields to render photorealistic novel views of scenes with complicated geometry and appearance, and demonstrate results that outperform prior work on neural rendering and view synthesis. View synthesis results are best viewed as videos, so we urge readers to view our supplementary video for convincing comparisons.
Depth Estimation by Learning Triangulation and Densification of Sparse Points for Multi-view Stereo
Mar 19, 2020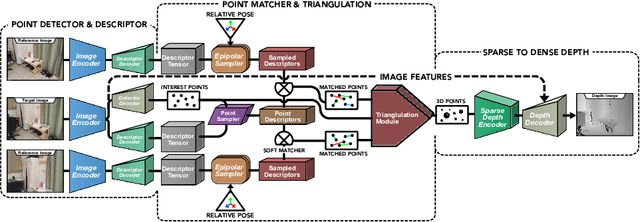
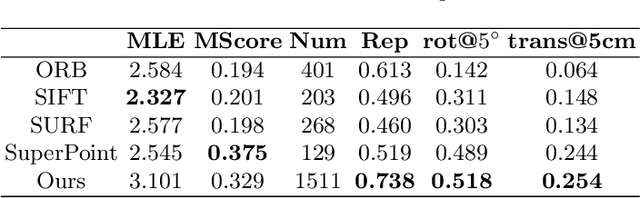
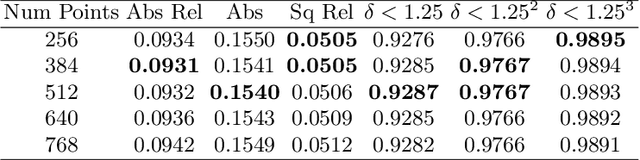

Multi-view stereo (MVS) is the golden mean between the accuracy of active depth sensing and the practicality of monocular depth estimation. Cost volume based approaches employing 3D convolutional neural networks (CNNs) have considerably improved the accuracy of MVS systems. However, this accuracy comes at a high computational cost which impedes practical adoption. Distinct from cost volume approaches, we propose an efficient depth estimation approach by first (a) detecting and evaluating descriptors for interest points, then (b) learning to match and triangulate a small set of interest points, and finally (c) densifying this sparse set of 3D points using CNNs. An end-to-end network efficiently performs all three steps within a deep learning framework and trained with intermediate 2D image and 3D geometric supervision, along with depth supervision. Crucially, our first step complements pose estimation using interest point detection and descriptor learning. We demonstrate that state-of-the-art results on depth estimation with lower compute for different scene lengths. Furthermore, our method generalizes to newer environments and the descriptors output by our network compare favorably to strong baselines.
Active Perception with A Monocular Camera for Multiscopic Vision
Jan 22, 2020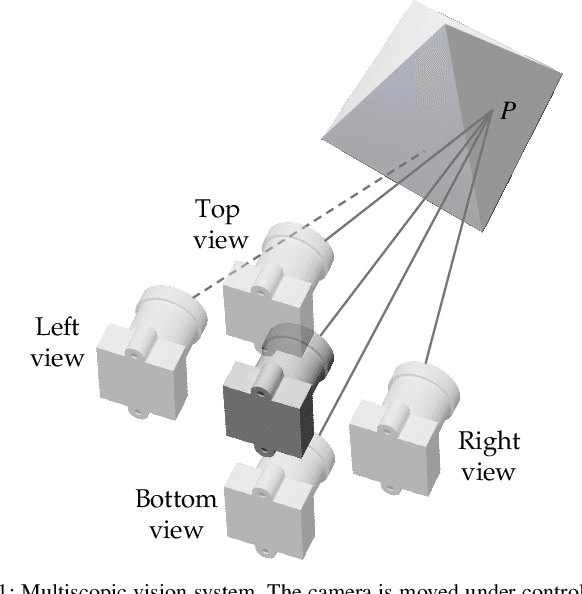
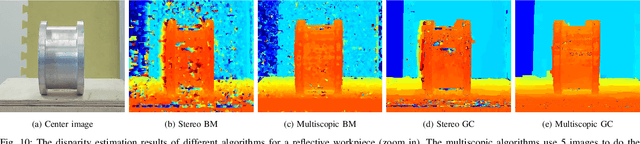

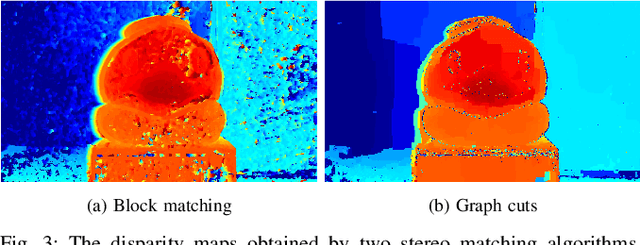
We design a multiscopic vision system that utilizes a low-cost monocular RGB camera to acquire accurate depth estimation for robotic applications. Unlike multi-view stereo with images captured at unconstrained camera poses, the proposed system actively controls a robot arm with a mounted camera to capture a sequence of images in horizontally or vertically aligned positions with the same parallax. In this system, we combine the cost volumes for stereo matching between the reference image and the surrounding images to form a fused cost volume that is robust to outliers. Experiments on the Middlebury dataset and real robot experiments show that our obtained disparity maps are more accurate than two-frame stereo matching: the average absolute error is reduced by 50.2% in our experiments.
Automatic Grading of Knee Osteoarthritis on the Kellgren-Lawrence Scale from Radiographs Using Convolutional Neural Networks
Apr 18, 2020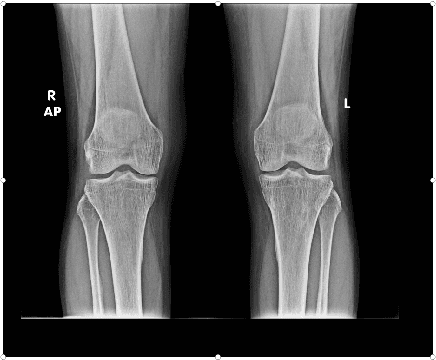

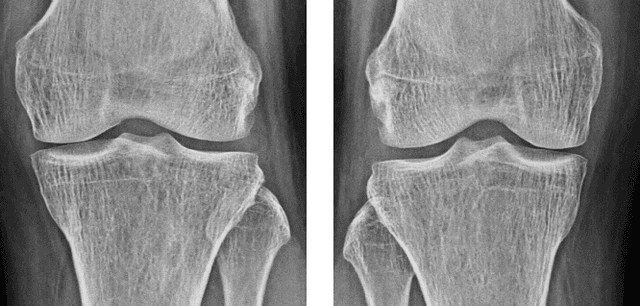
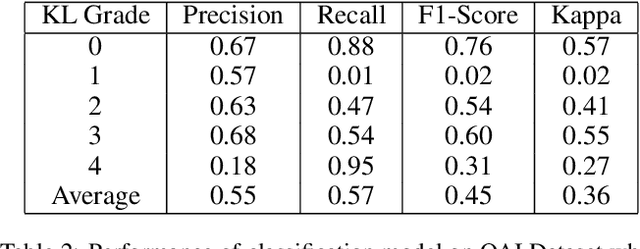
The severity of knee osteoarthritis is graded using the 5-point Kellgren-Lawrence (KL) scale where healthy knees are assigned grade 0, and the subsequent grades 1-4 represent increasing severity of the affliction. Although several methods have been proposed in recent years to develop models that can automatically predict the KL grade from a given radiograph, most models have been developed and evaluated on datasets not sourced from India. These models fail to perform well on the radiographs of Indian patients. In this paper, we propose a novel method using convolutional neural networks to automatically grade knee radiographs on the KL scale. Our method works in two connected stages: in the first stage, an object detection model segments individual knees from the rest of the image; in the second stage, a regression model automatically grades each knee separately on the KL scale. We train our model using the publicly available Osteoarthritis Initiative (OAI) dataset and demonstrate that fine-tuning the model before evaluating it on a dataset from a private hospital significantly improves the mean absolute error from 1.09 (95% CI: 1.03-1.15) to 0.28 (95% CI: 0.25-0.32). Additionally, we compare classification and regression models built for the same task and demonstrate that regression outperforms classification.
SPair-71k: A Large-scale Benchmark for Semantic Correspondence
Aug 28, 2019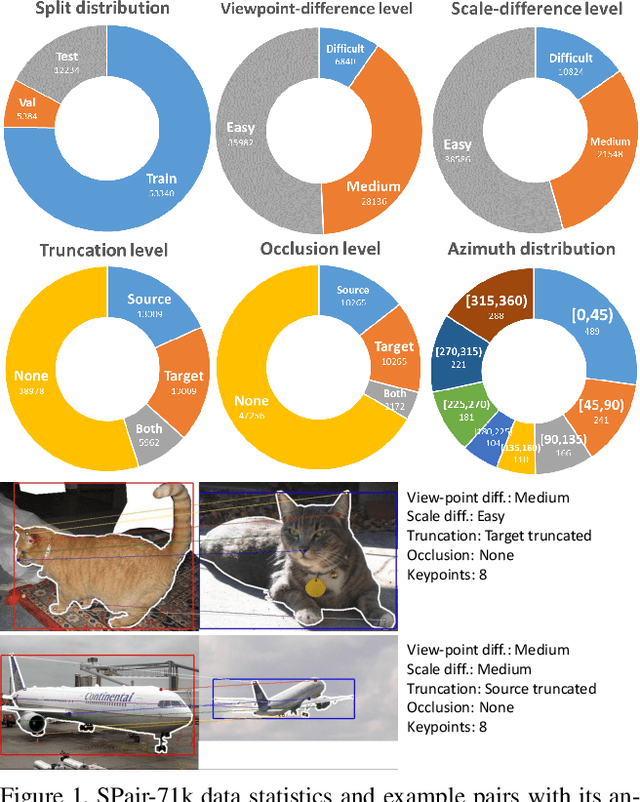
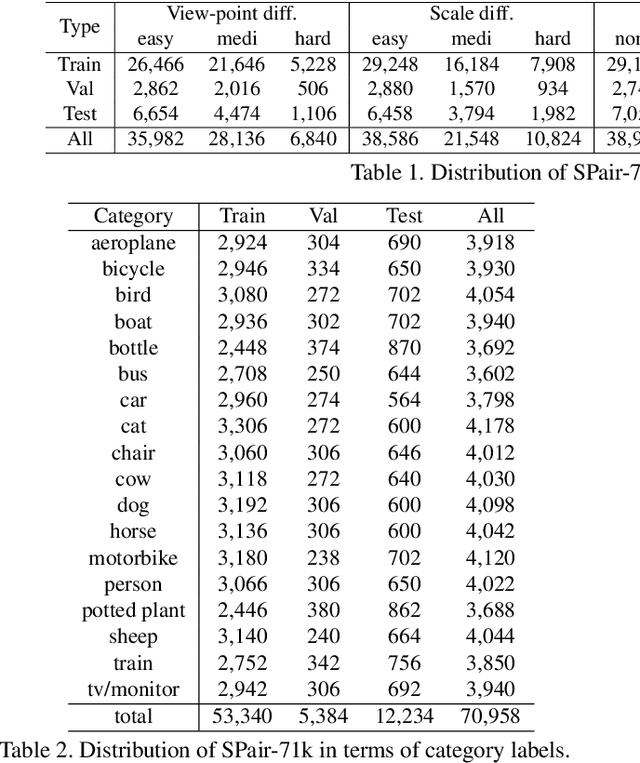
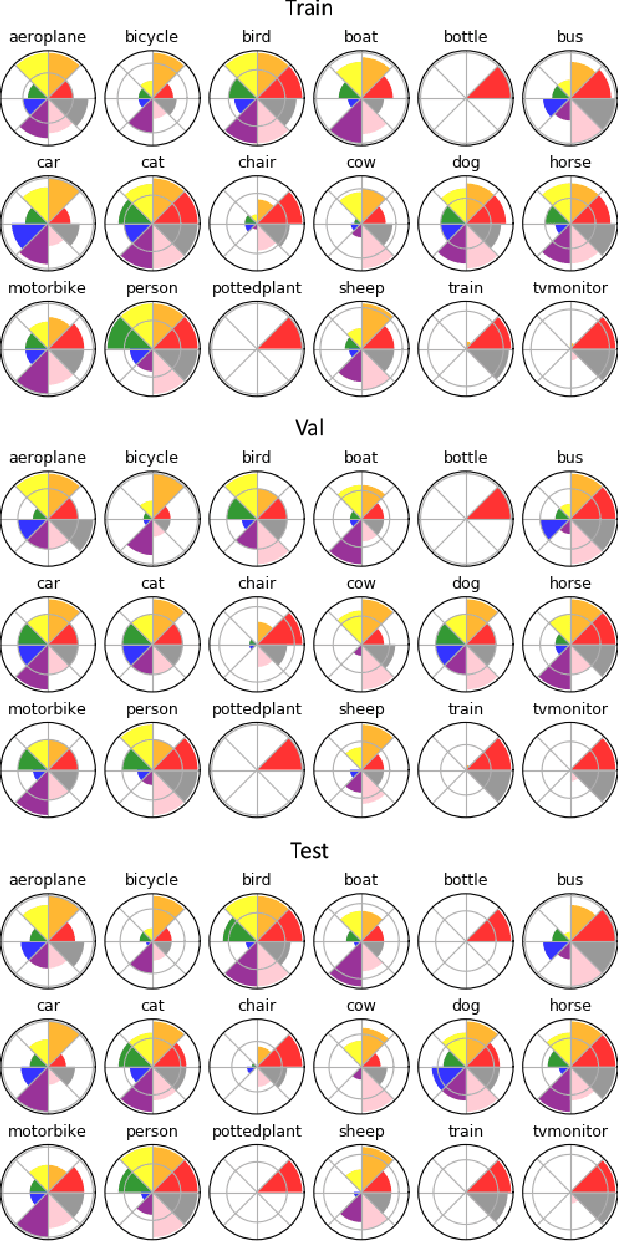
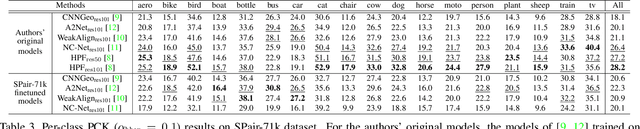
Establishing visual correspondences under large intra-class variations, which is often referred to as semantic correspondence or semantic matching, remains a challenging problem in computer vision. Despite its significance, however, most of the datasets for semantic correspondence are limited to a small amount of image pairs with similar viewpoints and scales. In this paper, we present a new large-scale benchmark dataset of semantically paired images, SPair-71k, which contains 70,958 image pairs with diverse variations in viewpoint and scale. Compared to previous datasets, it is significantly larger in number and contains more accurate and richer annotations. We believe this dataset will provide a reliable testbed to study the problem of semantic correspondence and will help to advance research in this area. We provide the results of recent methods on our new dataset as baselines for further research. Our benchmark is available online at http://cvlab.postech.ac.kr/research/SPair-71k/.
Building Information Modeling and Classification by Visual Learning At A City Scale
Oct 14, 2019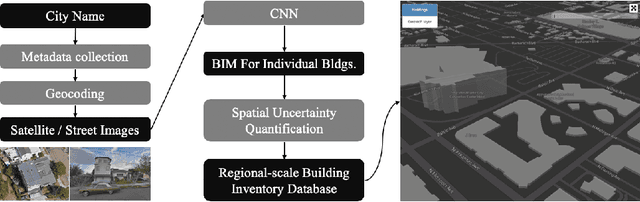
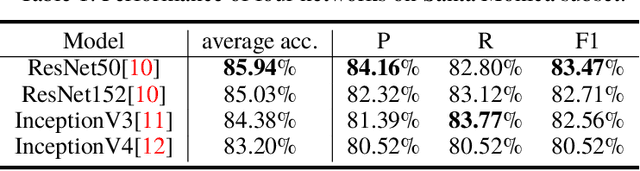

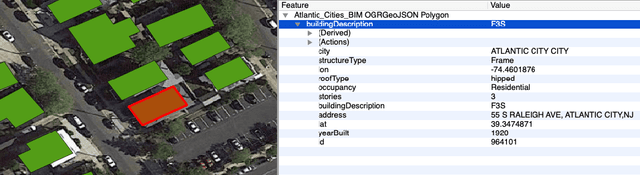
In this paper, we provide two case studies to demonstrate how artificial intelligence can empower civil engineering. In the first case, a machine learning-assisted framework, BRAILS, is proposed for city-scale building information modeling. Building information modeling (BIM) is an efficient way of describing buildings, which is essential to architecture, engineering, and construction. Our proposed framework employs deep learning technique to extract visual information of buildings from satellite/street view images. Further, a novel machine learning (ML)-based statistical tool, SURF, is proposed to discover the spatial patterns in building metadata. The second case focuses on the task of soft-story building classification. Soft-story buildings are a type of buildings prone to collapse during a moderate or severe earthquake. Hence, identifying and retrofitting such buildings is vital in the current earthquake preparedness efforts. For this task, we propose an automated deep learning-based procedure for identifying soft-story buildings from street view images at a regional scale. We also create a large-scale building image database and a semi-automated image labeling approach that effectively annotates new database entries. Through extensive computational experiments, we demonstrate the effectiveness of the proposed method.
Detecting GAN generated Fake Images using Co-occurrence Matrices
Mar 15, 2019
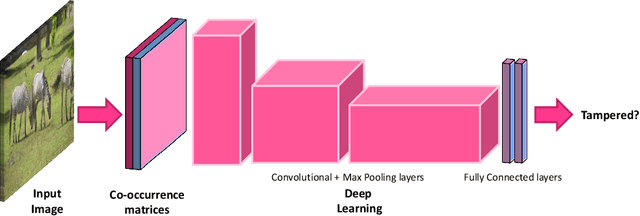
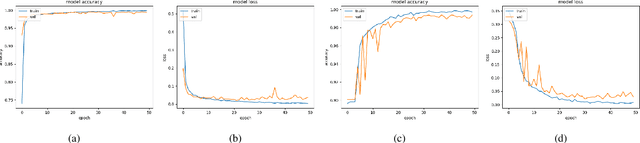
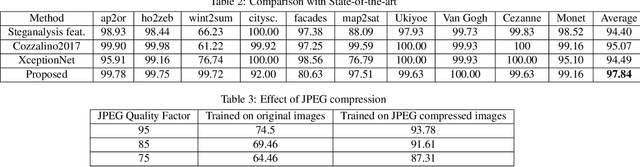
The advent of Generative Adversarial Networks (GANs) has brought about completely novel ways of transforming and manipulating pixels in digital images. GAN based techniques such as Image-to-Image translations, DeepFakes, and other automated methods have become increasingly popular in creating fake images. In this paper, we propose a novel approach to detect GAN generated fake images using a combination of co-occurrence matrices and deep learning. We extract co-occurrence matrices on three color channels in the pixel domain and train a model using a deep convolutional neural network (CNN) framework. Experimental results on two diverse and challenging GAN datasets comprising more than 56,000 images based on unpaired image-to-image translations (cycleGAN [1]) and facial attributes/expressions (StarGAN [2]) show that our approach is promising and achieves more than 99% classification accuracy in both datasets. Further, our approach also generalizes well and achieves good results when trained on one dataset and tested on the other.
PISA: Pixelwise Image Saliency by Aggregating Complementary Appearance Contrast Measures with Edge-Preserving Coherence
May 13, 2015

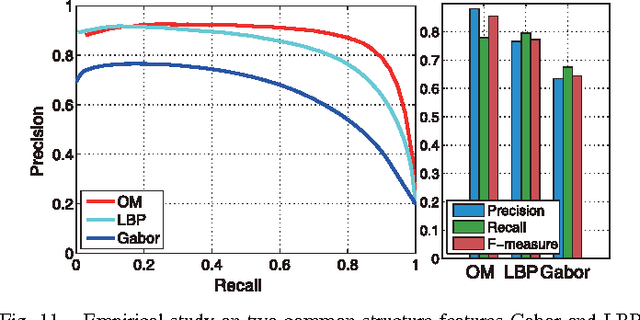

Driven by recent vision and graphics applications such as image segmentation and object recognition, computing pixel-accurate saliency values to uniformly highlight foreground objects becomes increasingly important. In this paper, we propose a unified framework called PISA, which stands for Pixelwise Image Saliency Aggregating various bottom-up cues and priors. It generates spatially coherent yet detail-preserving, pixel-accurate and fine-grained saliency, and overcomes the limitations of previous methods which use homogeneous superpixel-based and color only treatment. PISA aggregates multiple saliency cues in a global context such as complementary color and structure contrast measures with their spatial priors in the image domain. The saliency confidence is further jointly modeled with a neighborhood consistence constraint into an energy minimization formulation, in which each pixel will be evaluated with multiple hypothetical saliency levels. Instead of using global discrete optimization methods, we employ the cost-volume filtering technique to solve our formulation, assigning the saliency levels smoothly while preserving the edge-aware structure details. In addition, a faster version of PISA is developed using a gradient-driven image sub-sampling strategy to greatly improve the runtime efficiency while keeping comparable detection accuracy. Extensive experiments on a number of public datasets suggest that PISA convincingly outperforms other state-of-the-art approaches. In addition, with this work we also create a new dataset containing $800$ commodity images for evaluating saliency detection. The dataset and source code of PISA can be downloaded at http://vision.sysu.edu.cn/project/PISA/
* 14 pages, 14 figures, 1 table, to appear in IEEE Transactions on Image Processing
HyNNA: Improved Performance for Neuromorphic Vision Sensor based Surveillance using Hybrid Neural Network Architecture
Mar 19, 2020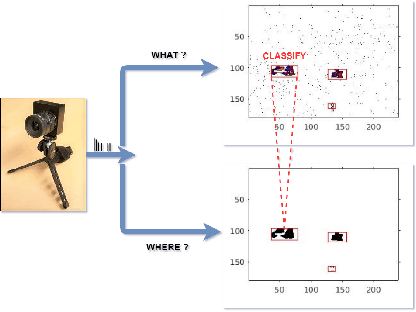
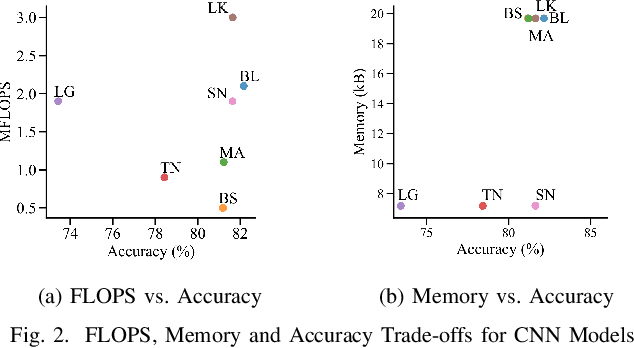

Applications in the Internet of Video Things (IoVT) domain have very tight constraints with respect to power and area. While neuromorphic vision sensors (NVS) may offer advantages over traditional imagers in this domain, the existing NVS systems either do not meet the power constraints or have not demonstrated end-to-end system performance. To address this, we improve on a recently proposed hybrid event-frame approach by using morphological image processing algorithms for region proposal and address the low-power requirement for object detection and classification by exploring various convolutional neural network (CNN) architectures. Specifically, we compare the results obtained from our object detection framework against the state-of-the-art low-power NVS surveillance system and show an improved accuracy of 82.16% from 63.1%. Moreover, we show that using multiple bits does not improve accuracy, and thus, system designers can save power and area by using only single bit event polarity information. In addition, we explore the CNN architecture space for object classification and show useful insights to trade-off accuracy for lower power using lesser memory and arithmetic operations.
Face Anti-Spoofing by Learning Polarization Cues in a Real-World Scenario
Mar 19, 2020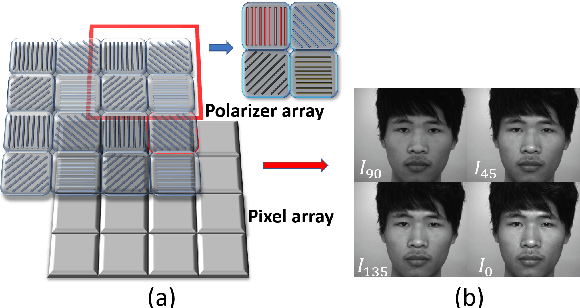
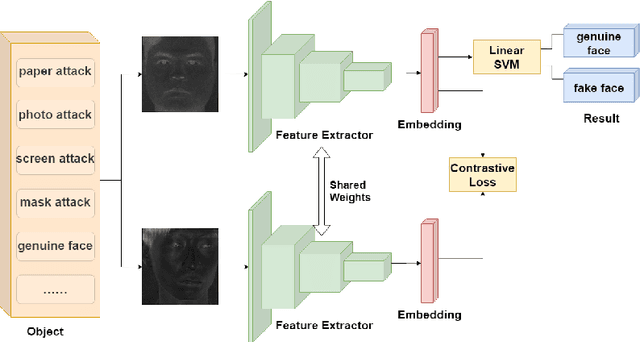
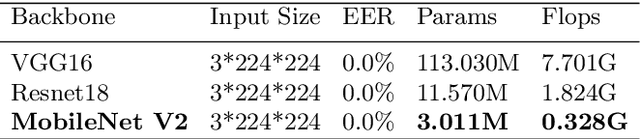
Face anti-spoofing is the key to preventing security breaches in biometric recognition applications. Existing software-based and hardware-based face liveness detection methods are effective in constrained environments or designated datasets only. Deep learning method using RGB and infrared images demands a large amount of training data for new attacks. In this paper, we present a face anti-spoofing method in a real-world scenario by automatic learning the physical characteristics in polarization images of a real face compared to a deceptive attack. A computational framework is developed to extract and classify the unique face features using convolutional neural networks and SVM together. Our real-time polarized face anti-spoofing (PAAS) detection method uses a on-chip integrated polarization imaging sensor with optimized processing algorithms. Extensive experiments demonstrate the advantages of the PAAS technique to counter diverse face spoofing attacks (print, replay, mask) in uncontrolled indoor and outdoor conditions by learning polarized face images of 33 people. A four-directional polarized face image dataset is released to inspire future applications within biometric anti-spoofing field.