 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWrivinder: Towards Spatial Intelligence for Geo-locating Ground Images onto Satellite Imagery
Feb 16, 2026Aligning ground-level imagery with geo-registered satellite maps is crucial for mapping, navigation, and situational awareness, yet remains challenging under large viewpoint gaps or when GPS is unreliable. We introduce Wrivinder, a zero-shot, geometry-driven framework that aggregates multiple ground photographs to reconstruct a consistent 3D scene and align it with overhead satellite imagery. Wrivinder combines SfM reconstruction, 3D Gaussian Splatting, semantic grounding, and monocular depth--based metric cues to produce a stable zenith-view rendering that can be directly matched to satellite context for metrically accurate camera geo-localization. To support systematic evaluation of this task, which lacks suitable benchmarks, we also release MC-Sat, a curated dataset linking multi-view ground imagery with geo-registered satellite tiles across diverse outdoor environments. Together, Wrivinder and MC-Sat provide a first comprehensive baseline and testbed for studying geometry-centered cross-view alignment without paired supervision. In zero-shot experiments, Wrivinder achieves sub-30\,m geolocation accuracy across both dense and large-area scenes, highlighting the promise of geometry-based aggregation for robust ground-to-satellite localization.
CIMGEN: Controlled Image Manipulation by Finetuning Pretrained Generative Models on Limited Data
Jan 23, 2024Content creation and image editing can benefit from flexible user controls. A common intermediate representation for conditional image generation is a semantic map, that has information of objects present in the image. When compared to raw RGB pixels, the modification of semantic map is much easier. One can take a semantic map and easily modify the map to selectively insert, remove, or replace objects in the map. The method proposed in this paper takes in the modified semantic map and alter the original image in accordance to the modified map. The method leverages traditional pre-trained image-to-image translation GANs, such as CycleGAN or Pix2Pix GAN, that are fine-tuned on a limited dataset of reference images associated with the semantic maps. We discuss the qualitative and quantitative performance of our technique to illustrate its capacity and possible applications in the fields of image forgery and image editing. We also demonstrate the effectiveness of the proposed image forgery technique in thwarting the numerous deep learning-based image forensic techniques, highlighting the urgent need to develop robust and generalizable image forensic tools in the fight against the spread of fake media.
MalGrid: Visualization Of Binary Features In Large Malware Corpora
Nov 04, 2022



The number of malware is constantly on the rise. Though most new malware are modifications of existing ones, their sheer number is quite overwhelming. In this paper, we present a novel system to visualize and map millions of malware to points in a 2-dimensional (2D) spatial grid. This enables visualizing relationships within large malware datasets that can be used to develop triage solutions to screen different malware rapidly and provide situational awareness. Our approach links two visualizations within an interactive display. Our first view is a spatial point-based visualization of similarity among the samples based on a reduced dimensional projection of binary feature representations of malware. Our second spatial grid-based view provides a better insight into similarities and differences between selected malware samples in terms of the binary-based visual representations they share. We also provide a case study where the effect of packing on the malware data is correlated with the complexity of the packing algorithm.
CNNs are Myopic
Jun 01, 2022
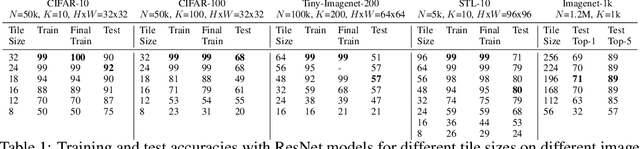
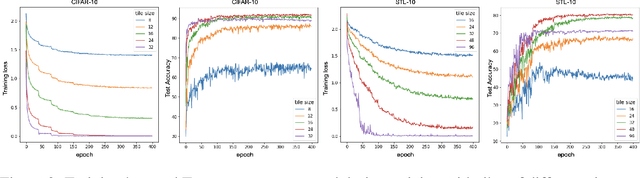

We claim that Convolutional Neural Networks (CNNs) learn to classify images using only small seemingly unrecognizable tiles. We show experimentally that CNNs trained only using such tiles can match or even surpass the performance of CNNs trained on full images. Conversely, CNNs trained on full images show similar predictions on small tiles. We also propose the first a priori theoretical model for convolutional data sets that seems to explain this behavior. This gives additional support to the long standing suspicion that CNNs do not need to understand the global structure of images to achieve state-of-the-art accuracies. Surprisingly it also suggests that over-fitting is not needed either.
OMD: Orthogonal Malware Detection Using Audio, Image, and Static Features
Nov 08, 2021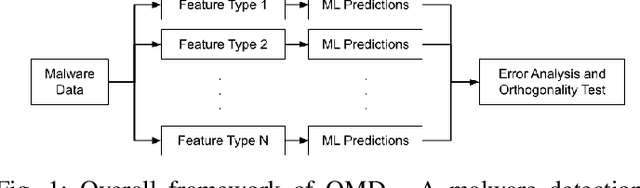
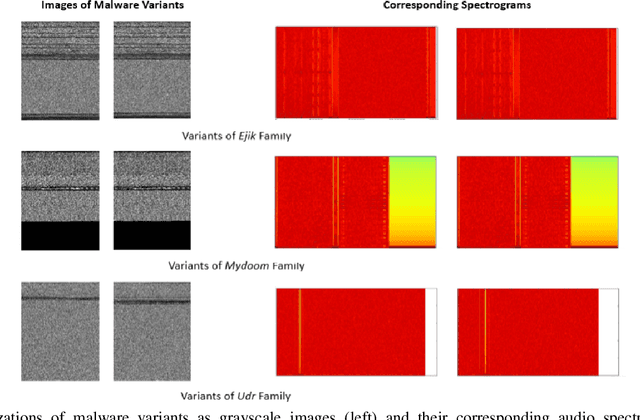
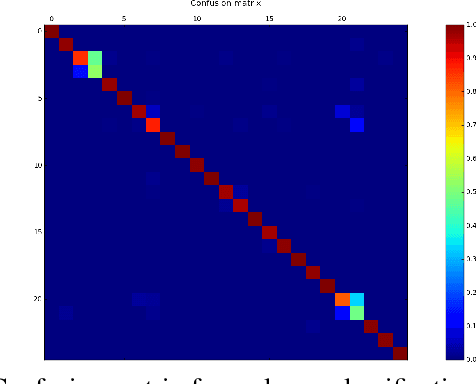
With the growing number of malware and cyber attacks, there is a need for "orthogonal" cyber defense approaches, which are complementary to existing methods by detecting unique malware samples that are not predicted by other methods. In this paper, we propose a novel and orthogonal malware detection (OMD) approach to identify malware using a combination of audio descriptors, image similarity descriptors and other static/statistical features. First, we show how audio descriptors are effective in classifying malware families when the malware binaries are represented as audio signals. Then, we show that the predictions made on the audio descriptors are orthogonal to the predictions made on image similarity descriptors and other static features. Further, we develop a framework for error analysis and a metric to quantify how orthogonal a new feature set (or type) is with respect to other feature sets. This allows us to add new features and detection methods to our overall framework. Experimental results on malware datasets show that our approach provides a robust framework for orthogonal malware detection.
HAPSSA: Holistic Approach to PDF Malware Detection Using Signal and Statistical Analysis
Nov 08, 2021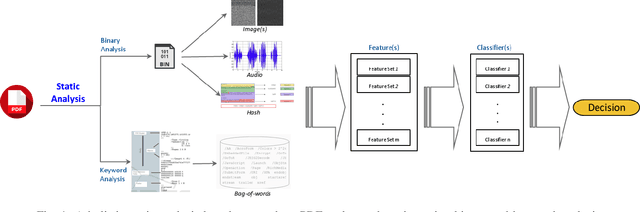
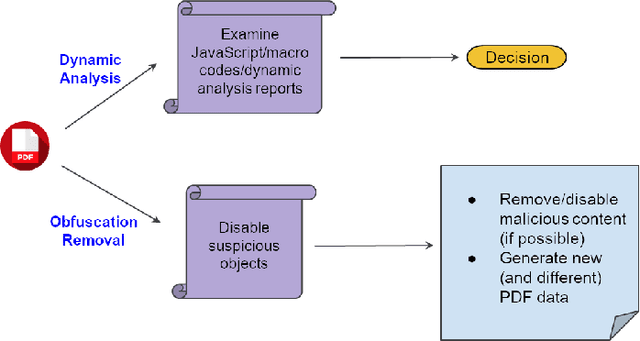
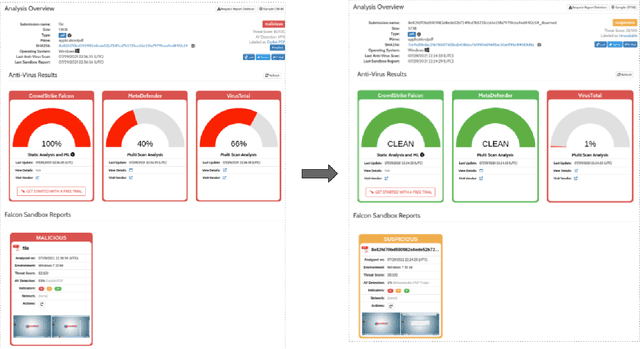
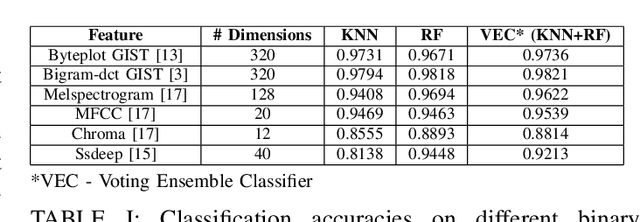
Malicious PDF documents present a serious threat to various security organizations that require modern threat intelligence platforms to effectively analyze and characterize the identity and behavior of PDF malware. State-of-the-art approaches use machine learning (ML) to learn features that characterize PDF malware. However, ML models are often susceptible to evasion attacks, in which an adversary obfuscates the malware code to avoid being detected by an Antivirus. In this paper, we derive a simple yet effective holistic approach to PDF malware detection that leverages signal and statistical analysis of malware binaries. This includes combining orthogonal feature space models from various static and dynamic malware detection methods to enable generalized robustness when faced with code obfuscations. Using a dataset of nearly 30,000 PDF files containing both malware and benign samples, we show that our holistic approach maintains a high detection rate (99.92%) of PDF malware and even detects new malicious files created by simple methods that remove the obfuscation conducted by malware authors to hide their malware, which are undetected by most antiviruses.
Seam Carving Detection and Localization using Two-Stage Deep Neural Networks
Sep 04, 2021
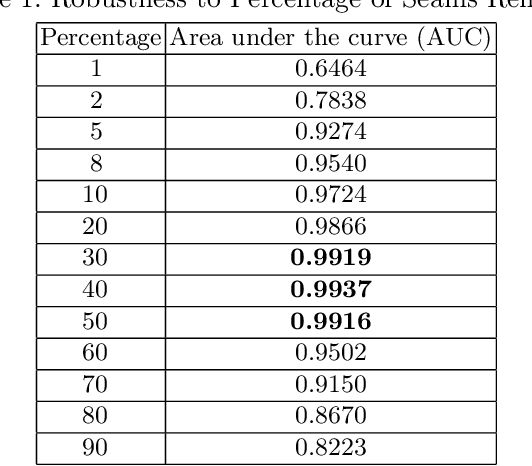
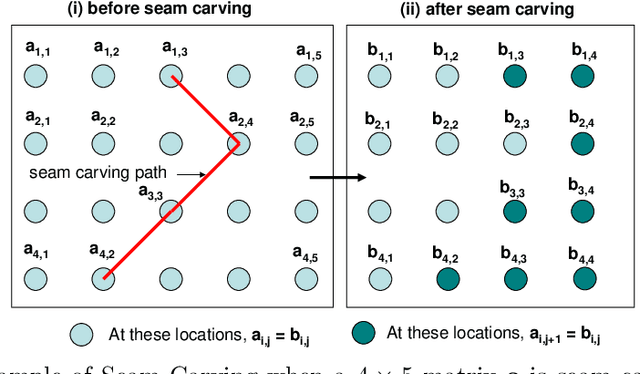
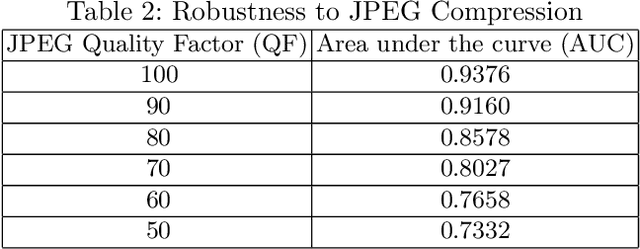
Seam carving is a method to resize an image in a content aware fashion. However, this method can also be used to carve out objects from images. In this paper, we propose a two-step method to detect and localize seam carved images. First, we build a detector to detect small patches in an image that has been seam carved. Next, we compute a heatmap on an image based on the patch detector's output. Using these heatmaps, we build another detector to detect if a whole image is seam carved or not. Our experimental results show that our approach is effective in detecting and localizing seam carved images.
SeeTheSeams: Localized Detection of Seam Carving based Image Forgery in Satellite Imagery
Aug 28, 2021
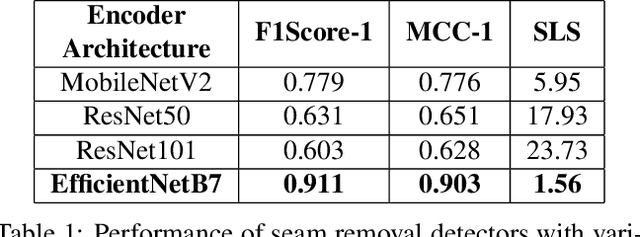

Seam carving is a popular technique for content aware image retargeting. It can be used to deliberately manipulate images, for example, change the GPS locations of a building or insert/remove roads in a satellite image. This paper proposes a novel approach for detecting and localizing seams in such images. While there are methods to detect seam carving based manipulations, this is the first time that robust localization and detection of seam carving forgery is made possible. We also propose a seam localization score (SLS) metric to evaluate the effectiveness of localization. The proposed method is evaluated extensively on a large collection of images from different sources, demonstrating a high level of detection and localization performance across these datasets. The datasets curated during this work will be released to the public.
Holistic Image Manipulation Detection using Pixel Co-occurrence Matrices
Apr 12, 2021

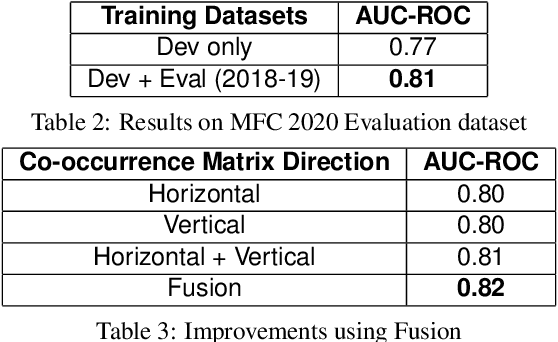
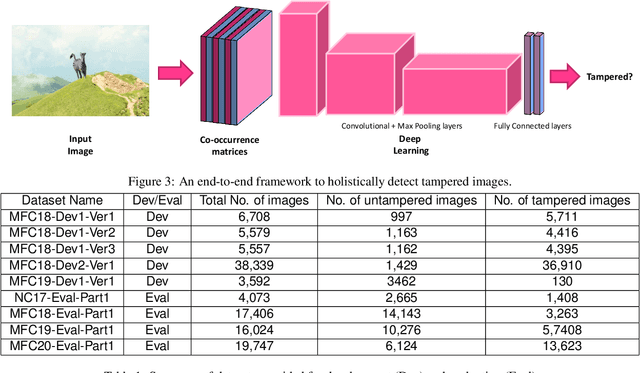
Digital image forensics aims to detect images that have been digitally manipulated. Realistic image forgeries involve a combination of splicing, resampling, region removal, smoothing and other manipulation methods. While most detection methods in literature focus on detecting a particular type of manipulation, it is challenging to identify doctored images that involve a host of manipulations. In this paper, we propose a novel approach to holistically detect tampered images using a combination of pixel co-occurrence matrices and deep learning. We extract horizontal and vertical co-occurrence matrices on three color channels in the pixel domain and train a model using a deep convolutional neural network (CNN) framework. Our method is agnostic to the type of manipulation and classifies an image as tampered or untampered. We train and validate our model on a dataset of more than 86,000 images. Experimental results show that our approach is promising and achieves more than 0.99 area under the curve (AUC) evaluation metric on the training and validation subsets. Further, our approach also generalizes well and achieves around 0.81 AUC on an unseen test dataset comprising more than 19,740 images released as part of the Media Forensics Challenge (MFC) 2020. Our score was highest among all other teams that participated in the challenge, at the time of announcement of the challenge results.
Adversarially Optimized Mixup for Robust Classification
Mar 22, 2021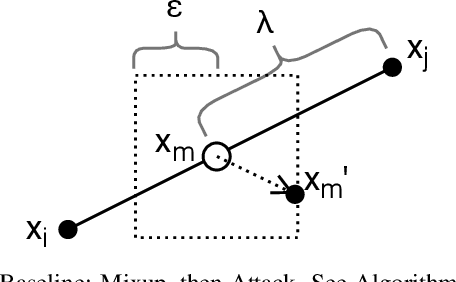
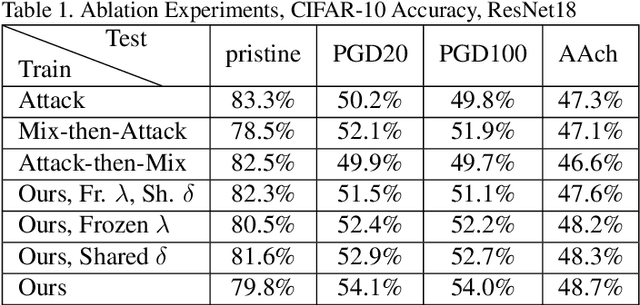
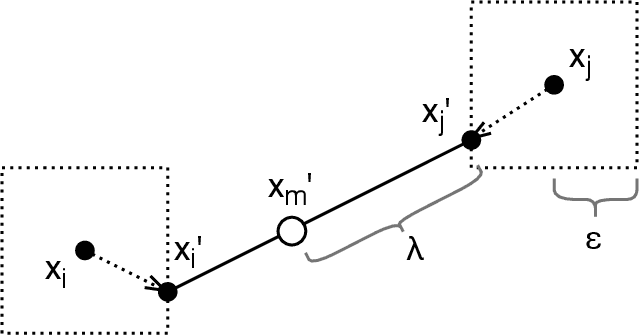
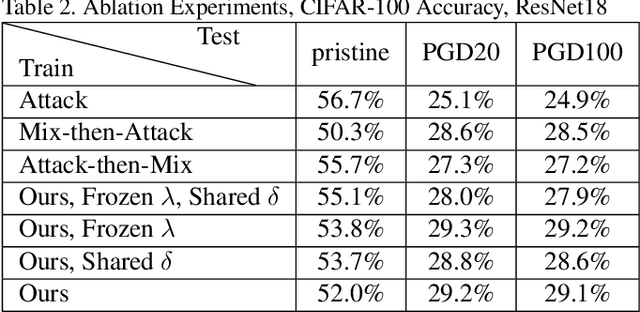
Mixup is a procedure for data augmentation that trains networks to make smoothly interpolated predictions between datapoints. Adversarial training is a strong form of data augmentation that optimizes for worst-case predictions in a compact space around each data-point, resulting in neural networks that make much more robust predictions. In this paper, we bring these ideas together by adversarially probing the space between datapoints, using projected gradient descent (PGD). The fundamental approach in this work is to leverage backpropagation through the mixup interpolation during training to optimize for places where the network makes unsmooth and incongruous predictions. Additionally, we also explore several modifications and nuances, like optimization of the mixup ratio and geometrical label assignment, and discuss their impact on enhancing network robustness. Through these ideas, we have been able to train networks that robustly generalize better; experiments on CIFAR-10 and CIFAR-100 demonstrate consistent improvements in accuracy against strong adversaries, including the recent strong ensemble attack AutoAttack. Our source code would be released for reproducibility.