 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Near-Infrared Image Dehazing Via Color Regularization
Oct 01, 2016
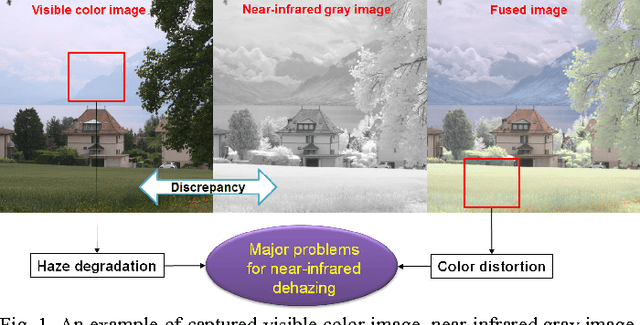



Near-infrared imaging can capture haze-free near-infrared gray images and visible color images, according to physical scattering models, e.g., Rayleigh or Mie models. However, there exist serious discrepancies in brightness and image structures between the near-infrared gray images and the visible color images. The direct use of the near-infrared gray images brings about another color distortion problem in the dehazed images. Therefore, the color distortion should also be considered for near-infrared dehazing. To reflect this point, this paper presents an approach of adding a new color regularization to conventional dehazing framework. The proposed color regularization can model the color prior for unknown haze-free images from two captured images. Thus, natural-looking colors and fine details can be induced on the dehazed images. The experimental results show that the proposed color regularization model can help remove the color distortion and the haze at the same time. Also, the effectiveness of the proposed color regularization is verified by comparing with other conventional regularizations. It is also shown that the proposed color regularization can remove the edge artifacts which arise from the use of the conventional dark prior model.
Multitask Text-to-Visual Embedding with Titles and Clickthrough Data
May 30, 2019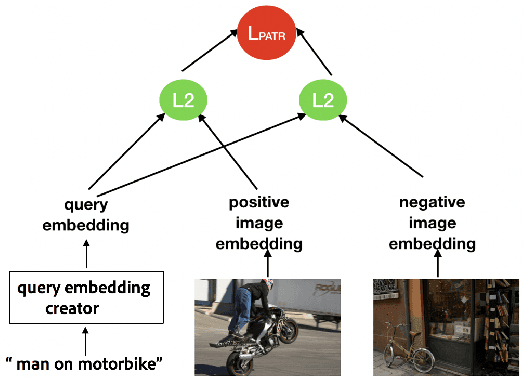
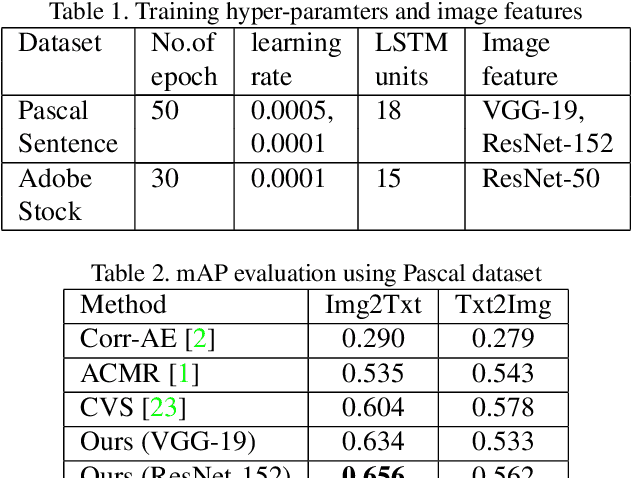

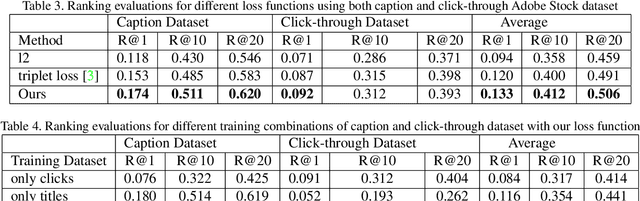
Text-visual (or called semantic-visual) embedding is a central problem in vision-language research. It typically involves mapping of an image and a text description to a common feature space through a CNN image encoder and a RNN language encoder. In this paper, we propose a new method for learning text-visual embedding using both image titles and click-through data from an image search engine. We also propose a new triplet loss function by modeling positive awareness of the embedding, and introduce a novel mini-batch-based hard negative sampling approach for better data efficiency in the learning process. Experimental results show that our proposed method outperforms existing methods, and is also effective for real-world text-to-visual retrieval.
Latent Domain Learning with Dynamic Residual Adapters
Jun 01, 2020

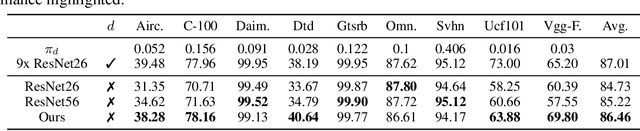
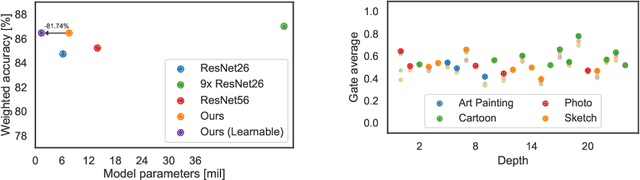
A practical shortcoming of deep neural networks is their specialization to a single task and domain. While recent techniques in domain adaptation and multi-domain learning enable the learning of more domain-agnostic features, their success relies on the presence of domain labels, typically requiring manual annotation and careful curation of datasets. Here we focus on a less explored, but more realistic case: learning from data from multiple domains, without access to domain annotations. In this scenario, standard model training leads to the overfitting of large domains, while disregarding smaller ones. We address this limitation via dynamic residual adapters, an adaptive gating mechanism that helps account for latent domains, coupled with an augmentation strategy inspired by recent style transfer techniques. Our proposed approach is examined on image classification tasks containing multiple latent domains, and we showcase its ability to obtain robust performance across these. Dynamic residual adapters significantly outperform off-the-shelf networks with much larger capacity, and can be incorporated seamlessly with existing architectures in an end-to-end manner.
An Online Platform for Automatic Skull Defect Restoration and Cranial Implant Design
Jun 01, 2020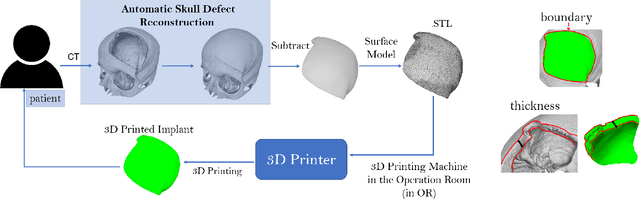
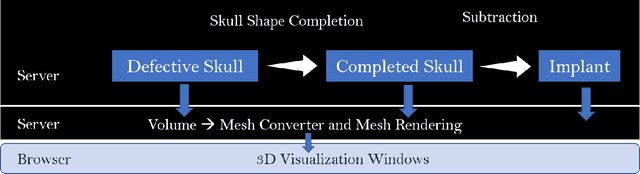
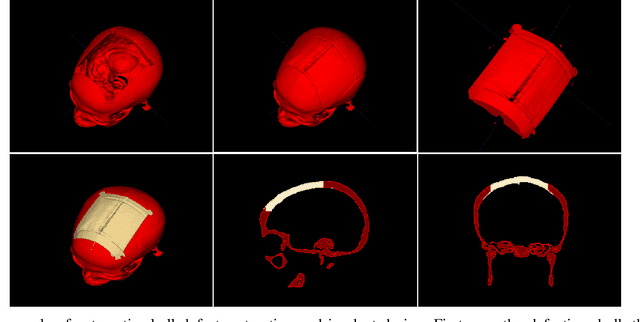
We introduce a fully automatic system for cranial implant design, a common task in cranioplasty operations. The system is currently integrated in Studierfenster (http://studierfenster.tugraz.at/), an online, cloud-based medical image processing platform for medical imaging applications. Enhanced by deep learning algorithms, the system automatically restores the missing part of a skull (i.e., skull shape completion) and generates the desired implant by subtracting the defective skull from the completed skull. The generated implant can be downloaded in the STereoLithography (.stl) format directly via the browser interface of the system. The implant model can then be sent to a 3D printer for in loco implant manufacturing. Furthermore, thanks to the standard format, the user can thereafter load the model into another application for post-processing whenever necessary. Such an automatic cranial implant design system can be integrated into the clinical practice to improve the current routine for surgeries related to skull defect repair (e.g., cranioplasty). Our system, although currently intended for educational and research use only, can be seen as an application of additive manufacturing for fast, patient-specific implant design.
PCAMs: Weakly Supervised Semantic Segmentation Using Point Supervision
Jul 10, 2020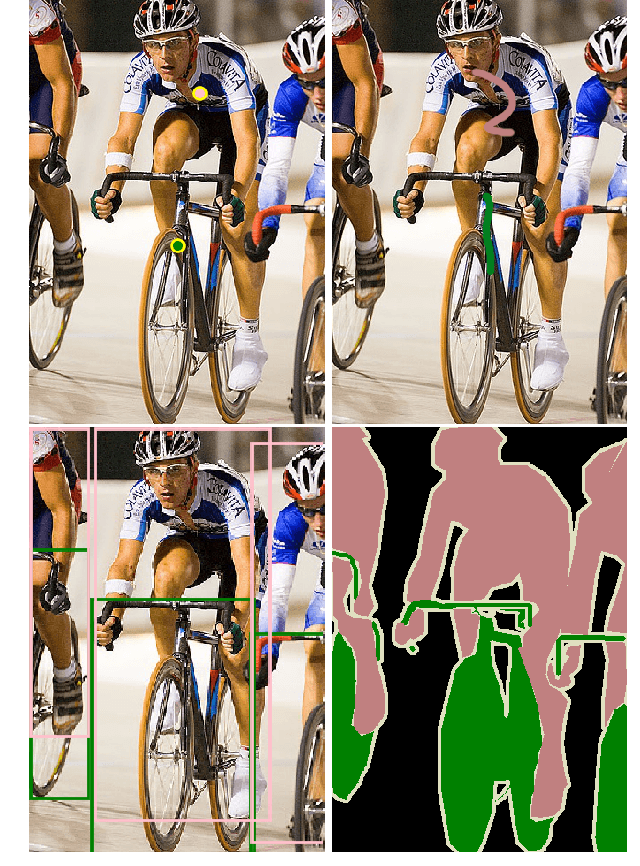
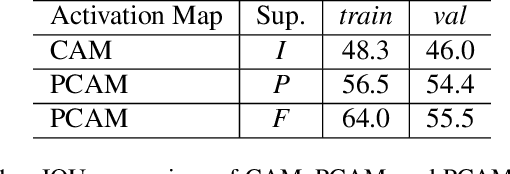
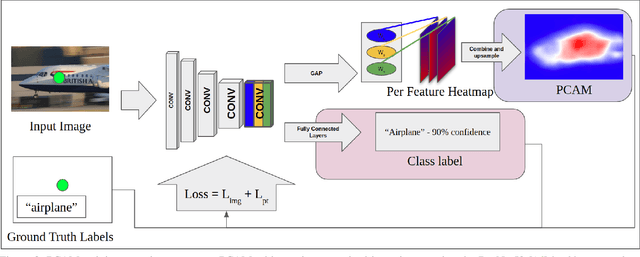

Current state of the art methods for generating semantic segmentation rely heavily on a large set of images that have each pixel labeled with a class of interest label or background. Coming up with such labels, especially in domains that require an expert to do annotations, comes at a heavy cost in time and money. Several methods have shown that we can learn semantic segmentation from less expensive image-level labels, but the effectiveness of point level labels, a healthy compromise between all pixels labelled and none, still remains largely unexplored. This paper presents a novel procedure for producing semantic segmentation from images given some point level annotations. This method includes point annotations in the training of a convolutional neural network (CNN) for producing improved localization and class activation maps. Then, we use another CNN for predicting semantic affinities in order to propagate rough class labels and create pseudo semantic segmentation labels. Finally, we propose training a CNN that is normally fully supervised using our pseudo labels in place of ground truth labels, which further improves performance and simplifies the inference process by requiring just one CNN during inference rather than two. Our method achieves state of the art results for point supervised semantic segmentation on the PASCAL VOC 2012 dataset \cite{everingham2010pascal}, even outperforming state of the art methods for stronger bounding box and squiggle supervision.
Unsupervised Learning of Video Representations via Dense Trajectory Clustering
Jun 28, 2020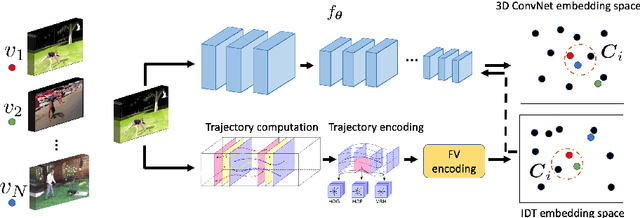
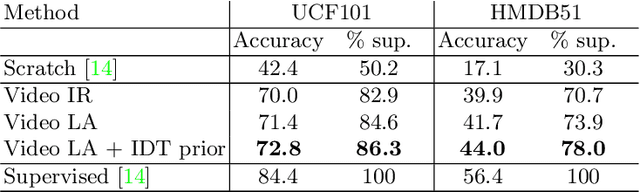
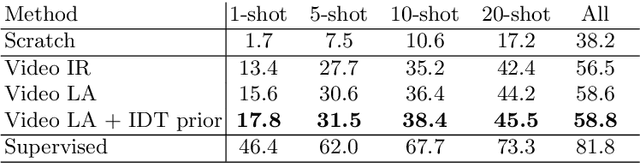

This paper addresses the task of unsupervised learning of representations for action recognition in videos. Previous works proposed to utilize future prediction, or other domain-specific objectives to train a network, but achieved only limited success. In contrast, in the relevant field of image representation learning, simpler, discrimination-based methods have recently bridged the gap to fully-supervised performance. We first propose to adapt two top performing objectives in this class - instance recognition and local aggregation, to the video domain. In particular, the latter approach iterates between clustering the videos in the feature space of a network and updating it to respect the cluster with a non-parametric classification loss. We observe promising performance, but qualitative analysis shows that the learned representations fail to capture motion patterns, grouping the videos based on appearance. To mitigate this issue, we turn to the heuristic-based IDT descriptors, that were manually designed to encode motion patterns in videos. We form the clusters in the IDT space, using these descriptors as a an unsupervised prior in the iterative local aggregation algorithm. Our experiments demonstrates that this approach outperform prior work on UCF101 and HMDB51 action recognition benchmarks. We also qualitatively analyze the learned representations and show that they successfully capture video dynamics.
Towards Diverse and Natural Image Descriptions via a Conditional GAN
Aug 11, 2017
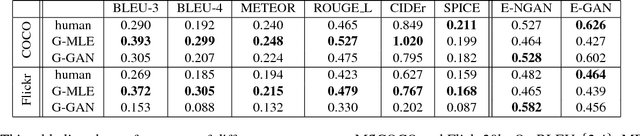
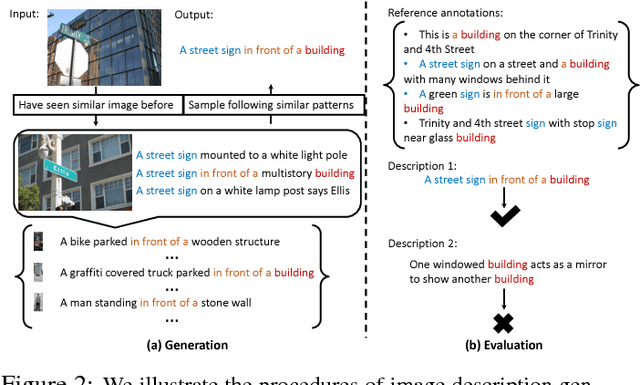

Despite the substantial progress in recent years, the image captioning techniques are still far from being perfect.Sentences produced by existing methods, e.g. those based on RNNs, are often overly rigid and lacking in variability. This issue is related to a learning principle widely used in practice, that is, to maximize the likelihood of training samples. This principle encourages high resemblance to the "ground-truth" captions while suppressing other reasonable descriptions. Conventional evaluation metrics, e.g. BLEU and METEOR, also favor such restrictive methods. In this paper, we explore an alternative approach, with the aim to improve the naturalness and diversity -- two essential properties of human expression. Specifically, we propose a new framework based on Conditional Generative Adversarial Networks (CGAN), which jointly learns a generator to produce descriptions conditioned on images and an evaluator to assess how well a description fits the visual content. It is noteworthy that training a sequence generator is nontrivial. We overcome the difficulty by Policy Gradient, a strategy stemming from Reinforcement Learning, which allows the generator to receive early feedback along the way. We tested our method on two large datasets, where it performed competitively against real people in our user study and outperformed other methods on various tasks.
Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep
Mar 06, 2020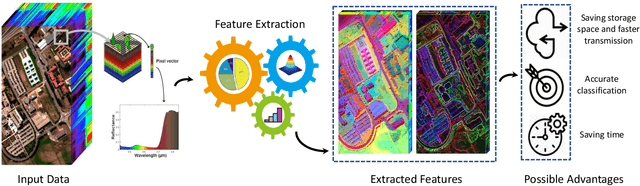
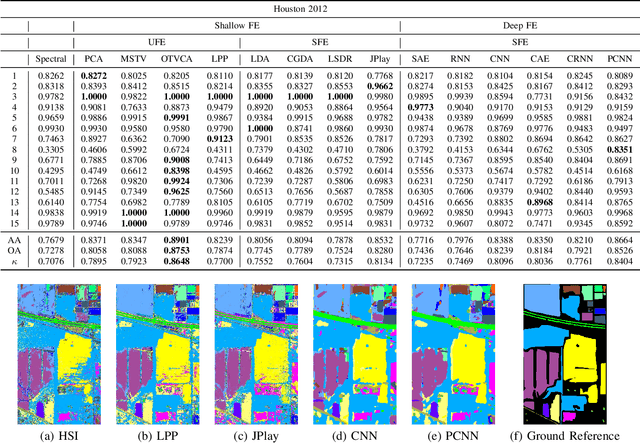
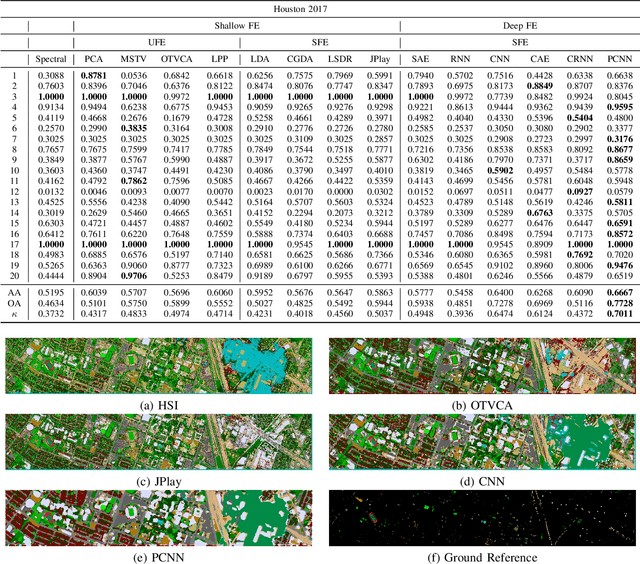

Hyperspectral images provide detailed spectral information through hundreds of (narrow) spectral channels (also known as dimensionality or bands) with continuous spectral information that can accurately classify diverse materials of interest. The increased dimensionality of such data makes it possible to significantly improve data information content but provides a challenge to the conventional techniques (the so-called curse of dimensionality) for accurate analysis of hyperspectral images. Feature extraction, as a vibrant field of research in the hyperspectral community, evolved through decades of research to address this issue and extract informative features suitable for data representation and classification. The advances in feature extraction have been inspired by two fields of research, including the popularization of image and signal processing as well as machine (deep) learning, leading to two types of feature extraction approaches named shallow and deep techniques. This article outlines the advances in feature extraction approaches for hyperspectral imagery by providing a technical overview of the state-of-the-art techniques, providing useful entry points for researchers at different levels, including students, researchers, and senior researchers, willing to explore novel investigations on this challenging topic. In more detail, this paper provides a bird's eye view over shallow (both supervised and unsupervised) and deep feature extraction approaches specifically dedicated to the topic of hyperspectral feature extraction and its application on hyperspectral image classification. Additionally, this paper compares 15 advanced techniques with an emphasis on their methodological foundations in terms of classification accuracies. Furthermore, the codes and libraries are shared at https://github.com/BehnoodRasti/HyFTech-Hyperspectral-Shallow-Deep-Feature-Extraction-Toolbox.
Motion Equivariance OF Event-based Camera Data with the Temporal Normalization Transform
Nov 28, 2019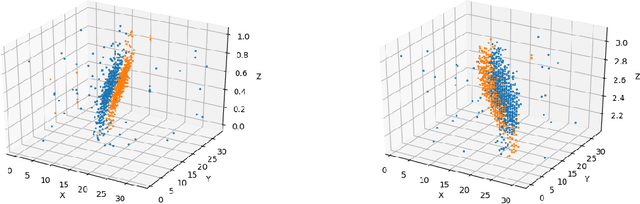
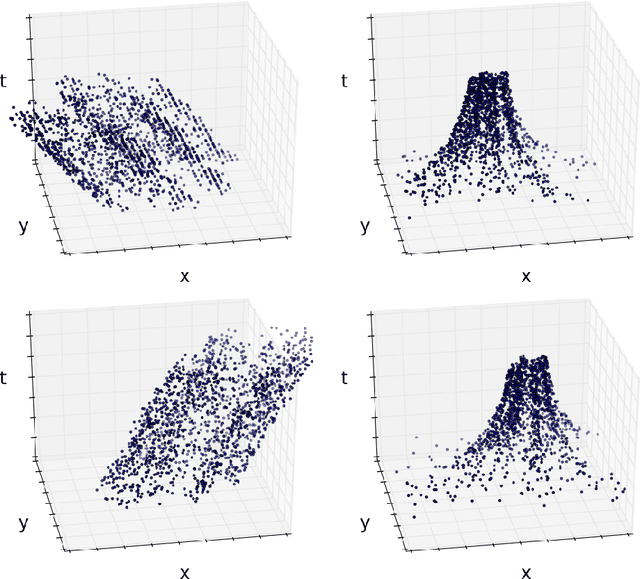

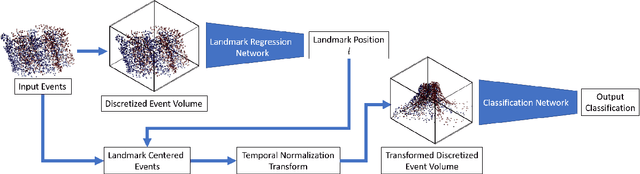
In this work, we focus on using convolution neural networks (CNN) to perform object recognition on the event data. In object recognition, it is important for a neural network to be robust to the variations of the data during testing. For traditional cameras, translations are well handled because CNNs are naturally equivariant to translations. However, because event cameras record the change of light intensity of an image, the geometric shape of event volumes will not only depend on the objects but also on their relative motions with respect to the camera. The deformation of the events caused by motions causes the CNN to be less robust to unseen motions during inference. To address this problem, we would like to explore the equivariance property of CNNs, a well-studied area that demonstrates to produce predictable deformation of features under certain transformations of the input image.
High-Fidelity Image Generation With Fewer Labels
Mar 06, 2019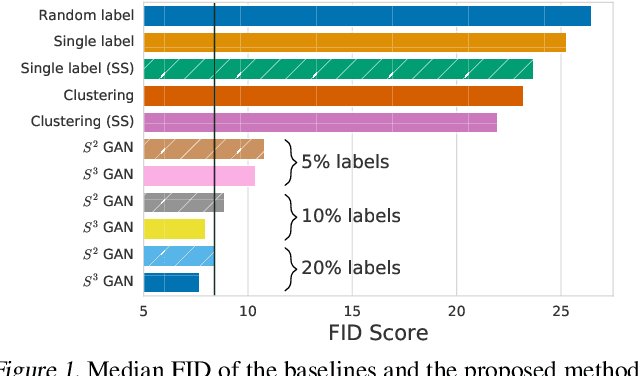

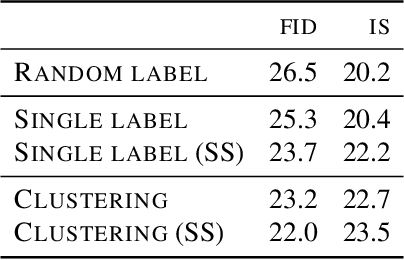
Deep generative models are becoming a cornerstone of modern machine learning. Recent work on conditional generative adversarial networks has shown that learning complex, high-dimensional distributions over natural images is within reach. While the latest models are able to generate high-fidelity, diverse natural images at high resolution, they rely on a vast quantity of labeled data. In this work we demonstrate how one can benefit from recent work on self- and semi-supervised learning to outperform state-of-the-art (SOTA) on both unsupervised ImageNet synthesis, as well as in the conditional setting. In particular, the proposed approach is able to match the sample quality (as measured by FID) of the current state-of-the art conditional model BigGAN on ImageNet using only 10% of the labels and outperform it using 20% of the labels.