 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDegradation-Agnostic Statistical Facial Feature Transformation for Blind Face Restoration in Adverse Weather Conditions
Jul 10, 2025With the increasing deployment of intelligent CCTV systems in outdoor environments, there is a growing demand for face recognition systems optimized for challenging weather conditions. Adverse weather significantly degrades image quality, which in turn reduces recognition accuracy. Although recent face image restoration (FIR) models based on generative adversarial networks (GANs) and diffusion models have shown progress, their performance remains limited due to the lack of dedicated modules that explicitly address weather-induced degradations. This leads to distorted facial textures and structures. To address these limitations, we propose a novel GAN-based blind FIR framework that integrates two key components: local Statistical Facial Feature Transformation (SFFT) and Degradation-Agnostic Feature Embedding (DAFE). The local SFFT module enhances facial structure and color fidelity by aligning the local statistical distributions of low-quality (LQ) facial regions with those of high-quality (HQ) counterparts. Complementarily, the DAFE module enables robust statistical facial feature extraction under adverse weather conditions by aligning LQ and HQ encoder representations, thereby making the restoration process adaptive to severe weather-induced degradations. Experimental results demonstrate that the proposed degradation-agnostic SFFT model outperforms existing state-of-the-art FIR methods based on GAN and diffusion models, particularly in suppressing texture distortions and accurately reconstructing facial structures. Furthermore, both the SFFT and DAFE modules are empirically validated in enhancing structural fidelity and perceptual quality in face restoration under challenging weather scenarios.
Locally Grouped and Scale-Guided Attention for Dense Pest Counting
Aug 29, 2024This study introduces a new dense pest counting problem to predict densely distributed pests captured by digital traps. Unlike traditional detection-based counting models for sparsely distributed objects, trap-based pest counting must deal with dense pest distributions that pose challenges such as severe occlusion, wide pose variation, and similar appearances in colors and textures. To address these problems, it is essential to incorporate the local attention mechanism, which identifies locally important and unimportant areas to learn locally grouped features, thereby enhancing discriminative performance. Accordingly, this study presents a novel design that integrates locally grouped and scale-guided attention into a multiscale CenterNet framework. To group local features with similar attributes, a straightforward method is introduced using the heatmap predicted by the first hourglass containing pest centroid information, which eliminates the need for complex clustering models. To enhance attentiveness, the pixel attention module transforms the heatmap into a learnable map. Subsequently, scale-guided attention is deployed to make the object and background features more discriminative, achieving multiscale feature fusion. Through experiments, the proposed model is verified to enhance object features based on local grouping and discriminative feature attention learning. Additionally, the proposed model is highly effective in overcoming occlusion and pose variation problems, making it more suitable for dense pest counting. In particular, the proposed model outperforms state-of-the-art models by a large margin, with a remarkable contribution to dense pest counting.
ROI-Aware Multiscale Cross-Attention Vision Transformer for Pest Image Identification
Dec 28, 2023The pests captured with imaging devices may be relatively small in size compared to the entire images, and complex backgrounds have colors and textures similar to those of the pests, which hinders accurate feature extraction and makes pest identification challenging. The key to pest identification is to create a model capable of detecting regions of interest (ROIs) and transforming them into better ones for attention and discriminative learning. To address these problems, we will study how to generate and update the ROIs via multiscale cross-attention fusion as well as how to be highly robust to complex backgrounds and scale problems. Therefore, we propose a novel ROI-aware multiscale cross-attention vision transformer (ROI-ViT). The proposed ROI-ViT is designed using dual branches, called Pest and ROI branches, which take different types of maps as input: Pest images and ROI maps. To render such ROI maps, ROI generators are built using soft segmentation and a class activation map and then integrated into the ROI-ViT backbone. Additionally, in the dual branch, complementary feature fusion and multiscale hierarchies are implemented via a novel multiscale cross-attention fusion. The class token from the Pest branch is exchanged with the patch tokens from the ROI branch, and vice versa. The experimental results show that the proposed ROI-ViT achieves 81.81%, 99.64%, and 84.66% for IP102, D0, and SauTeg pest datasets, respectively, outperforming state-of-the-art (SOTA) models, such as MViT, PVT, DeiT, Swin-ViT, and EfficientNet. More importantly, for the new challenging dataset IP102(CBSS) that contains only pest images with complex backgrounds and small sizes, the proposed model can maintain high recognition accuracy, whereas that of other SOTA models decrease sharply, demonstrating that our model is more robust to complex background and scale problems.
Trap-Based Pest Counting: Multiscale and Deformable Attention CenterNet Integrating Internal LR and HR Joint Feature Learning
Apr 05, 2023Pest counting, which predicts the number of pests in the early stage, is very important because it enables rapid pest control, reduces damage to crops, and improves productivity. In recent years, light traps have been increasingly used to lure and photograph pests for pest counting. However, pest images have a wide range of variability in pest appearance owing to severe occlusion, wide pose variation, and even scale variation. This makes pest counting more challenging. To address these issues, this study proposes a new pest counting model referred to as multiscale and deformable attention CenterNet (Mada-CenterNet) for internal low-resolution (LR) and high-resolution (HR) joint feature learning. Compared with the conventional CenterNet, the proposed Mada-CenterNet adopts a multiscale heatmap generation approach in a two-step fashion to predict LR and HR heatmaps adaptively learned to scale variations, that is, changes in the number of pests. In addition, to overcome the pose and occlusion problems, a new between-hourglass skip connection based on deformable and multiscale attention is designed to ensure internal LR and HR joint feature learning and incorporate geometric deformation, thereby resulting in an improved pest counting accuracy. Through experiments, the proposed Mada-CenterNet is verified to generate the HR heatmap more accurately and improve pest counting accuracy owing to multiscale heatmap generation, joint internal feature learning, and deformable and multiscale attention. In addition, the proposed model is confirmed to be effective in overcoming severe occlusions and variations in pose and scale. The experimental results show that the proposed model outperforms state-of-the-art crowd counting and object detection models.
Heavy Rain Face Image Restoration: Integrating Physical Degradation Model and Facial Component Guided Adversarial Learning
Apr 18, 2022
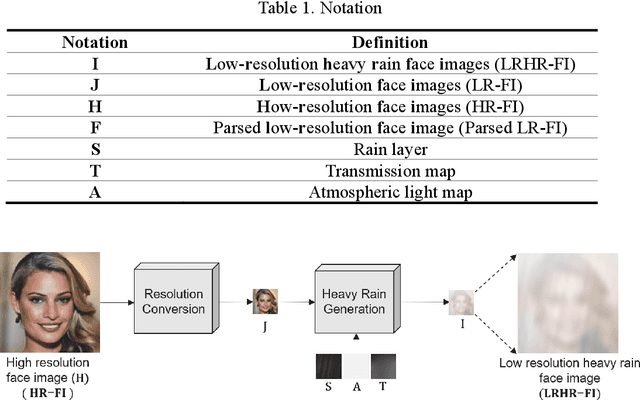
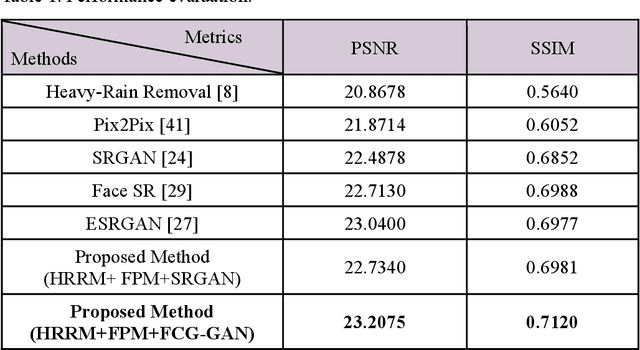

With the recent increase in intelligent CCTVs for visual surveillance, a new image degradation that integrates resolution conversion and synthetic rain models is required. For example, in heavy rain, face images captured by CCTV from a distance have significant deterioration in both visibility and resolution. Unlike traditional image degradation models (IDM), such as rain removal and superresolution, this study addresses a new IDM referred to as a scale-aware heavy rain model and proposes a method for restoring high-resolution face images (HR-FIs) from low-resolution heavy rain face images (LRHR-FI). To this end, a 2-stage network is presented. The first stage generates low-resolution face images (LR-FIs), from which heavy rain has been removed from the LRHR-FIs to improve visibility. To realize this, an interpretable IDM-based network is constructed to predict physical parameters, such as rain streaks, transmission maps, and atmospheric light. In addition, the image reconstruction loss is evaluated to enhance the estimates of the physical parameters. For the second stage, which aims to reconstruct the HR-FIs from the LR-FIs outputted in the first stage, facial component guided adversarial learning (FCGAL) is applied to boost facial structure expressions. To focus on informative facial features and reinforce the authenticity of facial components, such as the eyes and nose, a face-parsing-guided generator and facial local discriminators are designed for FCGAL. The experimental results verify that the proposed approach based on physical-based network design and FCGAL can remove heavy rain and increase the resolution and visibility simultaneously. Moreover, the proposed heavy-rain face image restoration outperforms state-of-the-art models of heavy rain removal, image-to-image translation, and superresolution.
New Image Captioning Encoder via Semantic Visual Feature Matching for Heavy Rain Images
May 31, 2021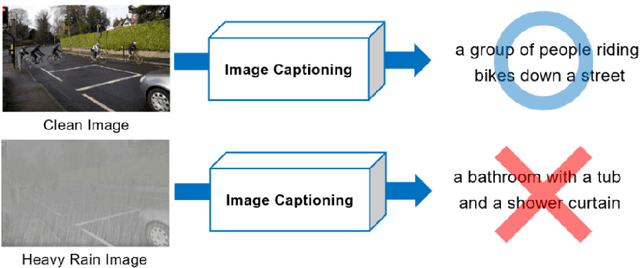
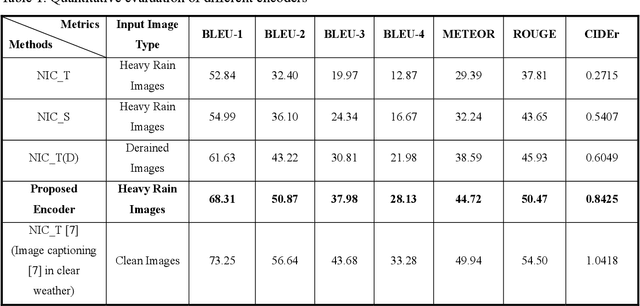

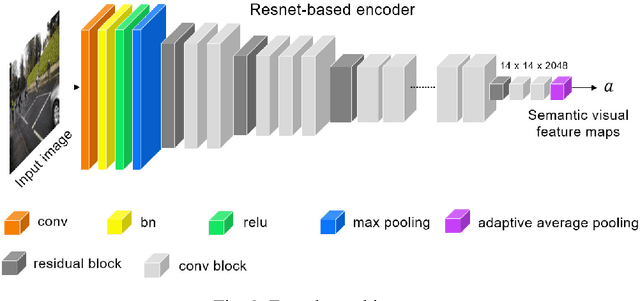
Image captioning generates text that describes scenes from input images. It has been developed for high quality images taken in clear weather. However, in bad weather conditions, such as heavy rain, snow, and dense fog, the poor visibility owing to rain streaks, rain accumulation, and snowflakes causes a serious degradation of image quality. This hinders the extraction of useful visual features and results in deteriorated image captioning performance. To address practical issues, this study introduces a new encoder for captioning heavy rain images. The central idea is to transform output features extracted from heavy rain input images into semantic visual features associated with words and sentence context. To achieve this, a target encoder is initially trained in an encoder-decoder framework to associate visual features with semantic words. Subsequently, the objects in a heavy rain image are rendered visible by using an initial reconstruction subnetwork (IRS) based on a heavy rain model. The IRS is then combined with another semantic visual feature matching subnetwork (SVFMS) to match the output features of the IRS with the semantic visual features of the pretrained target encoder. The proposed encoder is based on the joint learning of the IRS and SVFMS. It is is trained in an end-to-end manner, and then connected to the pretrained decoder for image captioning. It is experimentally demonstrated that the proposed encoder can generate semantic visual features associated with words even from heavy rain images, thereby increasing the accuracy of the generated captions.
Structure-Aware Layer Decomposition Learning Based on Gaussian Convolution Model for Inverse Halftoning
Dec 27, 2020


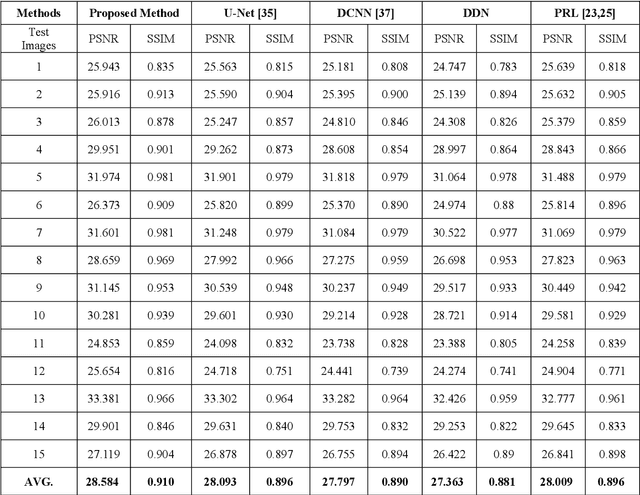
Layer decomposition to separate an input image into base and detail layers has been steadily used for image restoration. Existing residual networks based on an additive model require residual layers with a small output range for fast convergence and visual quality improvement. However, in inverse halftoning, homogenous dot patterns hinder a small output range from the residual layers. Therefore, a new layer decomposition network based on the Gaussian convolution model (GCM) and structure-aware deblurring strategy is presented to achieve residual learning for both the base and detail layers. For the base layer, a new GCM-based residual subnetwork is presented. The GCM utilizes a statistical distribution, in which the image difference between a blurred continuous-tone image and a blurred halftoned image with a Gaussian filter can result in a narrow output range. Subsequently, the GCM-based residual subnetwork uses a Gaussian-filtered halftoned image as input and outputs the image difference as residual, thereby generating the base layer, i.e., the Gaussian-blurred continuous-tone image. For the detail layer, a new structure-aware residual deblurring subnetwork (SARDS) is presented. To remove the Gaussian blurring of the base layer, the SARDS uses the predicted base layer as input and outputs the deblurred version. To more effectively restore image structures such as lines and texts, a new image structure map predictor is incorporated into the deblurring network to induce structure-adaptive learning. This paper provides a method to realize the residual learning of both the base and detail layers based on the GCM and SARDS. In addition, it is verified that the proposed method surpasses state-of-the-art methods based on U-Net, direct deblurring networks, and progressively residual networks.
Inverse Halftoning Through Structure-Aware Deep Convolutional Neural Networks
May 02, 2019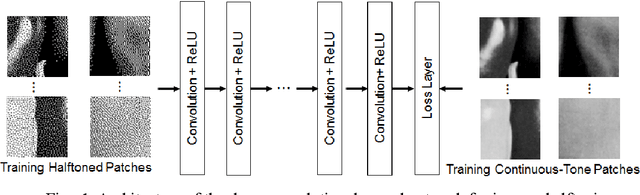

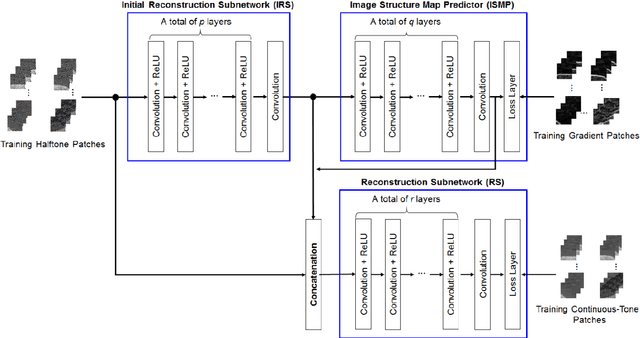
The primary issue in inverse halftoning is removing noisy dots on flat areas and restoring image structures (e.g., lines, patterns) on textured areas. Hence, a new structure-aware deep convolutional neural network that incorporates two subnetworks is proposed in this paper. One subnetwork is for image structure prediction while the other is for continuous-tone image reconstruction. First, to predict image structures, patch pairs comprising continuous-tone patches and the corresponding halftoned patches generated through digital halftoning are trained. Subsequently, gradient patches are generated by convolving gradient filters with the continuous-tone patches. The subnetwork for the image structure prediction is trained using the mini-batch gradient descent algorithm given the halftoned patches and gradient patches, which are fed into the input and loss layers of the subnetwork, respectively. Next, the predicted map including the image structures is stacked on the top of the input halftoned image through a fusion layer and fed into the image reconstruction subnetwork such that the entire network is trained adaptively to the image structures. The experimental results confirm that the proposed structure-aware network can remove noisy dot-patterns well on flat areas and restore details clearly on textured areas. Furthermore, it is demonstrated that the proposed method surpasses the conventional state-of-the-art methods based on deep convolutional neural networks and locally learned dictionaries.
Apple Leaf Disease Identification through Region-of-Interest-Aware Deep Convolutional Neural Network
Mar 25, 2019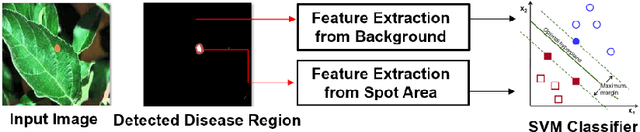
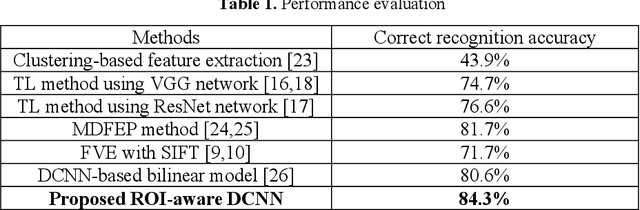
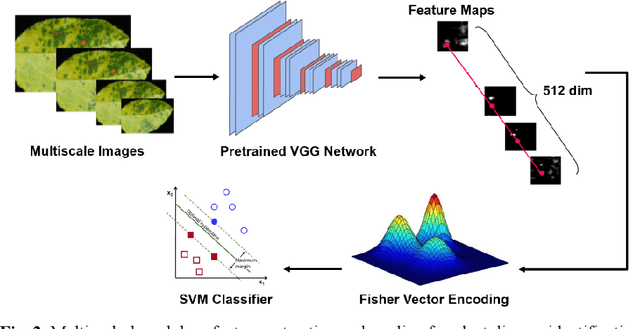
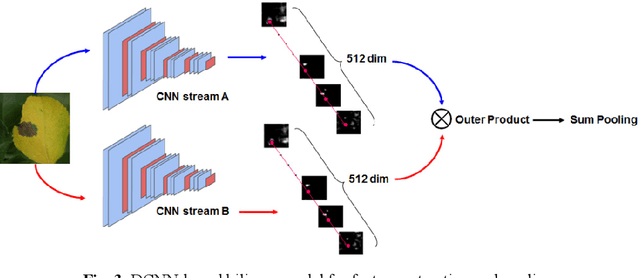
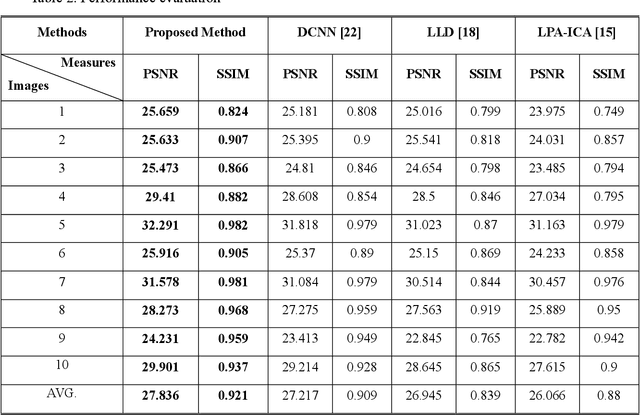
A new method of recognizing apple leaf diseases through region-of-interest-aware deep convolutional neural network is proposed in this paper. The primary idea is that leaf disease symptoms appear in the leaf area whereas the background region contains no useful information regarding leaf diseases. To realize this idea, two subnetworks are first designed. One is for the division of the input image into three areas: background, leaf area, and spot area indicating the leaf diseases, which is the region of interest, and the other is for the classification of leaf diseases. The two subnetworks exhibit the architecture types of an encoder-decoder network and VGG network, respectively; subsequently, they are trained separately through transfer learning with a new training set containing class information, according to the types of leaf diseases and the ground truth images where the background, leaf area, and spot area are separated. Next, to connect these subnetworks and subsequently train the connected whole network in an end-to-end manner, the predicted ROI feature map is stacked on the top of the input image through a fusion layer, and subsequently fed into the subnetwork used for the leaf disease identification. The experimental results indicate that correct recognition accuracy can be increased using the predicted ROI feature map. It is also shown that the proposed method obtains better performance than the conventional state-of-the-art methods: transfer-learning-based methods, bilinear model, and multiscale-based deep feature extraction, and pooling approach.
Multimodal Fusion via a Series of Transfers for Noise Removal
Jan 22, 2017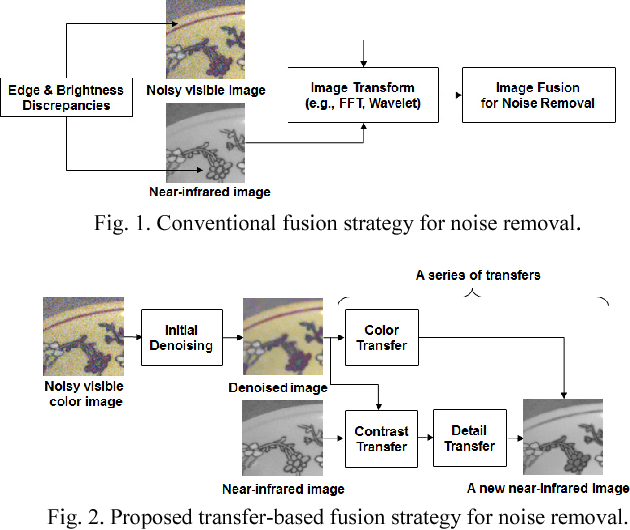


Near-infrared imaging has been considered as a solution to provide high quality photographs in dim lighting conditions. This imaging system captures two types of multimodal images: one is near-infrared gray image (NGI) and the other is the visible color image (VCI). NGI is noise-free but it is grayscale, whereas the VCI has colors but it contains noise. Moreover, there exist serious edge and brightness discrepancies between NGI and VCI. To deal with this problem, a new transfer-based fusion method is proposed for noise removal. Different from conventional fusion approaches, the proposed method conducts a series of transfers: contrast, detail, and color transfers. First, the proposed contrast and detail transfers aim at solving the serious discrepancy problem, thereby creating a new noise-free and detail-preserving NGI. Second, the proposed color transfer models the unknown colors from the denoised VCI via a linear transform, and then transfers natural-looking colors into the newly generated NGI. Experimental results show that the proposed transfer-based fusion method is highly successful in solving the discrepancy problem, thereby describing edges and textures clearly as well as removing noise completely on the fused images. Most of all, the proposed method is superior to conventional fusion methods and guided filtering, and even the state-of-the-art fusion methods based on scale map and layer decomposition.