 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Video Representations via Dense Trajectory Clustering
Paper and Code
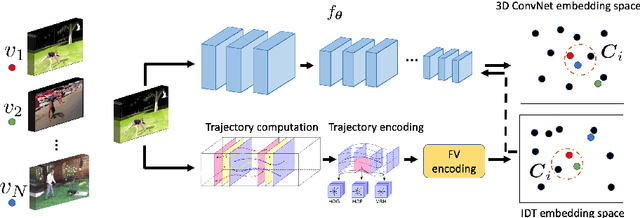
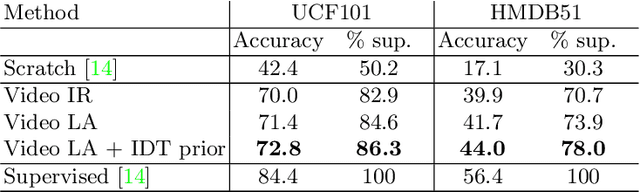
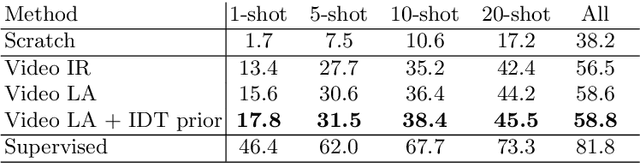

This paper addresses the task of unsupervised learning of representations for action recognition in videos. Previous works proposed to utilize future prediction, or other domain-specific objectives to train a network, but achieved only limited success. In contrast, in the relevant field of image representation learning, simpler, discrimination-based methods have recently bridged the gap to fully-supervised performance. We first propose to adapt two top performing objectives in this class - instance recognition and local aggregation, to the video domain. In particular, the latter approach iterates between clustering the videos in the feature space of a network and updating it to respect the cluster with a non-parametric classification loss. We observe promising performance, but qualitative analysis shows that the learned representations fail to capture motion patterns, grouping the videos based on appearance. To mitigate this issue, we turn to the heuristic-based IDT descriptors, that were manually designed to encode motion patterns in videos. We form the clusters in the IDT space, using these descriptors as a an unsupervised prior in the iterative local aggregation algorithm. Our experiments demonstrates that this approach outperform prior work on UCF101 and HMDB51 action recognition benchmarks. We also qualitatively analyze the learned representations and show that they successfully capture video dynamics.