 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
When Relation Networks meet GANs: Relation GANs with Triplet Loss
Feb 25, 2020
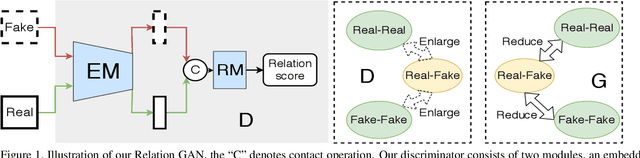
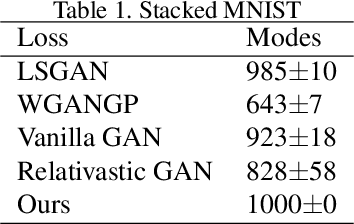
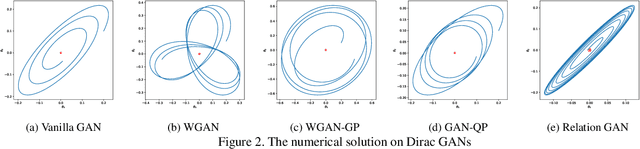
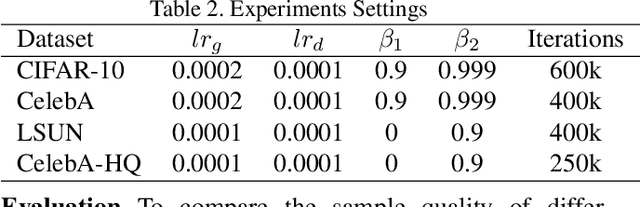
Though recent research has achieved remarkable progress in generating realistic images with generative adversarial networks (GANs), the lack of training stability is still a lingering concern of most GANs, especially on high-resolution inputs and complex datasets. Since the randomly generated distribution can hardly overlap with the real distribution, training GANs often suffers from the gradient vanishing problem. A number of approaches have been proposed to address this issue by constraining the discriminator's capabilities using empirical techniques, like weight clipping, gradient penalty, spectral normalization etc. In this paper, we provide a more principled approach as an alternative solution to this issue. Instead of training the discriminator to distinguish real and fake input samples, we investigate the relationship between paired samples by training the discriminator to separate paired samples from the same distribution and those from different distributions. To this end, we explore a relation network architecture for the discriminator and design a triplet loss which performs better generalization and stability. Extensive experiments on benchmark datasets show that the proposed relation discriminator and new loss can provide significant improvement on variable vision tasks including unconditional and conditional image generation and image translation. Our source codes are available on the website: \url{https://github.com/JosephineRabbit/Relation-GAN}
deepsing: Generating Sentiment-aware Visual Stories using Cross-modal Music Translation
Dec 11, 2019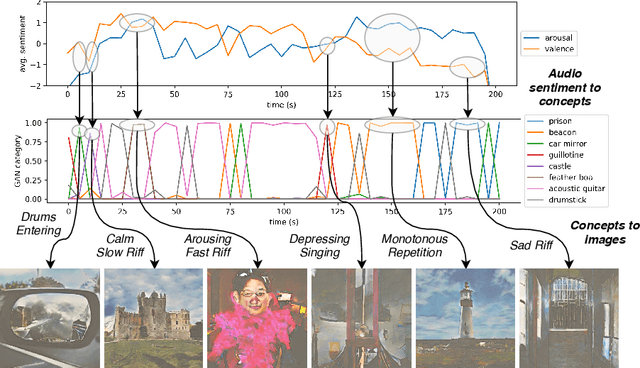

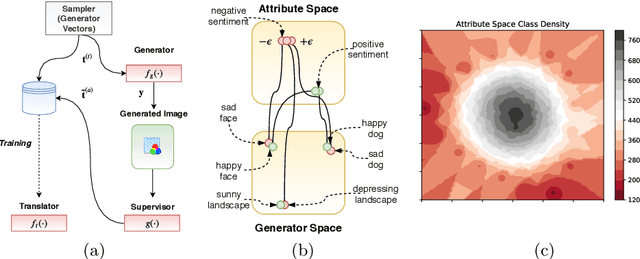
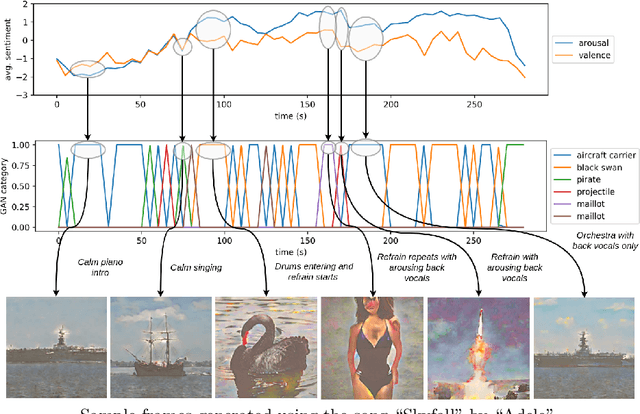
In this paper we propose a deep learning method for performing attributed-based music-to-image translation. The proposed method is applied for synthesizing visual stories according to the sentiment expressed by songs. The generated images aim to induce the same feelings to the viewers, as the original song does, reinforcing the primary aim of music, i.e., communicating feelings. The process of music-to-image translation poses unique challenges, mainly due to the unstable mapping between the different modalities involved in this process. In this paper, we employ a trainable cross-modal translation method to overcome this limitation, leading to the first, to the best of our knowledge, deep learning method for generating sentiment-aware visual stories. Various aspects of the proposed method are extensively evaluated and discussed using different songs.
Enhancement of Image Resolution by Binarization
Nov 21, 2011Image segmentation is one of the principal approaches of image processing. The choice of the most appropriate Binarization algorithm for each case proved to be a very interesting procedure itself. In this paper, we have done the comparison study between the various algorithms based on Binarization algorithms and propose a methodologies for the validation of Binarization algorithms. In this work we have developed two novel algorithms to determine threshold values for the pixels value of the gray scale image. The performance estimation of the algorithm utilizes test images with, the evaluation metrics for Binarization of textual and synthetic images. We have achieved better resolution of the image by using the Binarization method of optimum thresholding techniques.
* 5 pages, 8 figures
Large-scale Gastric Cancer Screening and Localization Using Multi-task Deep Neural Network
Oct 09, 2019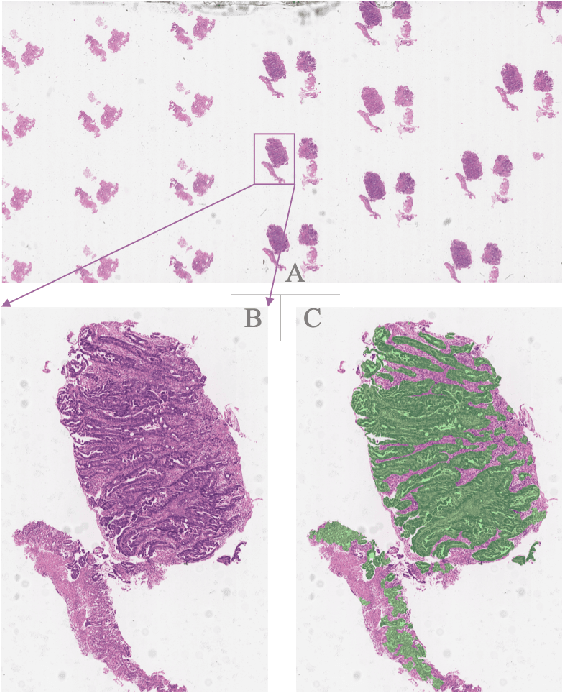
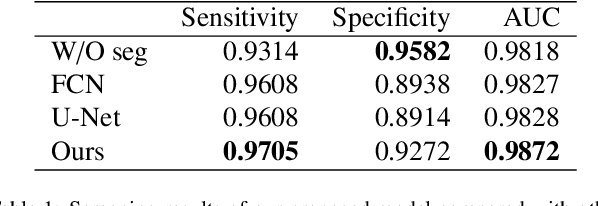
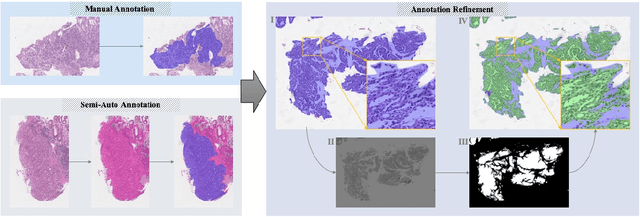
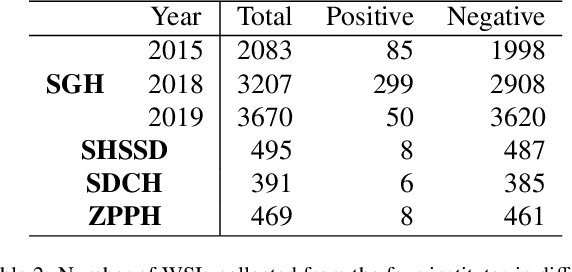
Gastric cancer is one of the most common cancers, which ranks third among the leading causes of cancer death. Biopsy of gastric mucosal is a standard procedure in gastric cancer screening test. However, manual pathological inspection is labor-intensive and time-consuming. Besides, it is challenging for an automated algorithm to locate the small lesion regions in the gigapixel whole-slide image and make the decision correctly. To tackle these issues, we collected large-scale whole-slide image dataset with detailed lesion region annotation and designed a whole-slide image analyzing framework consisting of 3 networks which could not only determine the screen result but also present the suspicious areas to the pathologist for reference. Experiments demonstrated that our proposed framework achieves sensitivity of 97.05% and specificity of 92.72% in screening task and Dice coefficient of 0.8331 in segmentation task. Furthermore, we tested our best model in real-world scenario on 10, 316 whole-slide images collected from 4 medical centers.
Art2Real: Unfolding the Reality of Artworks via Semantically-Aware Image-to-Image Translation
Nov 26, 2018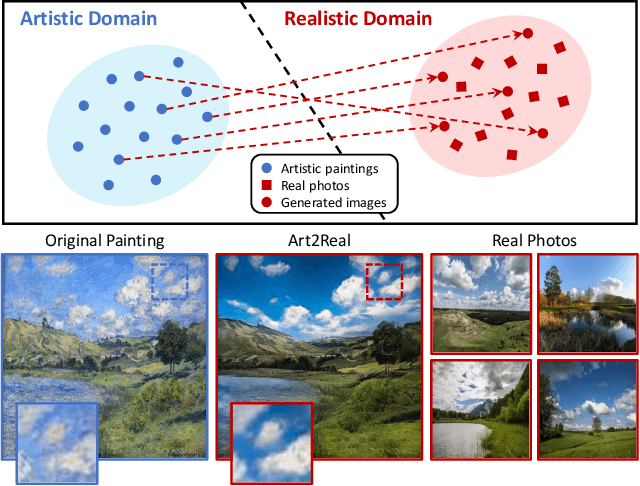
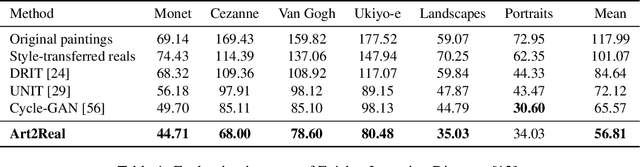
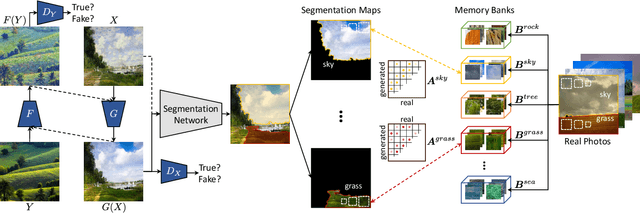

The applicability of computer vision to real paintings and artworks has been rarely investigated, even though a vast heritage would greatly benefit from techniques which can understand and process data from the artistic domain. This is partially due to the small amount of annotated artistic data, which is not even comparable to that of natural images captured by cameras. In this paper, we propose a semantic-aware architecture which can translate artworks to photo-realistic visualizations, thus reducing the gap between visual features of artistic and realistic data. Our architecture can generate natural images by retrieving and learning details from real photos through a similarity matching strategy which leverages a weakly-supervised semantic understanding of the scene. Experimental results show that the proposed technique leads to increased realism and to a reduction in domain shift, which improves the performance of pre-trained architectures for classification, detection, and segmentation. Code will be made publicly available.
Multigrid-in-Channels Architectures for Wide Convolutional Neural Networks
Jun 11, 2020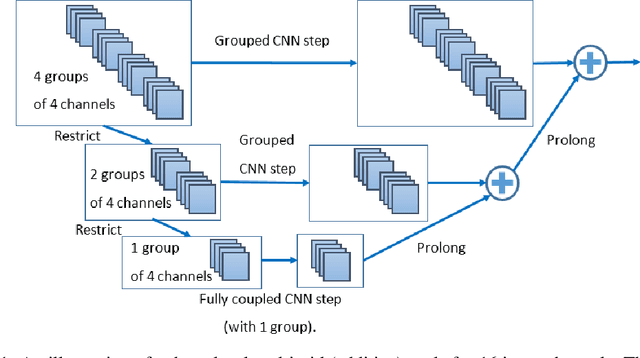
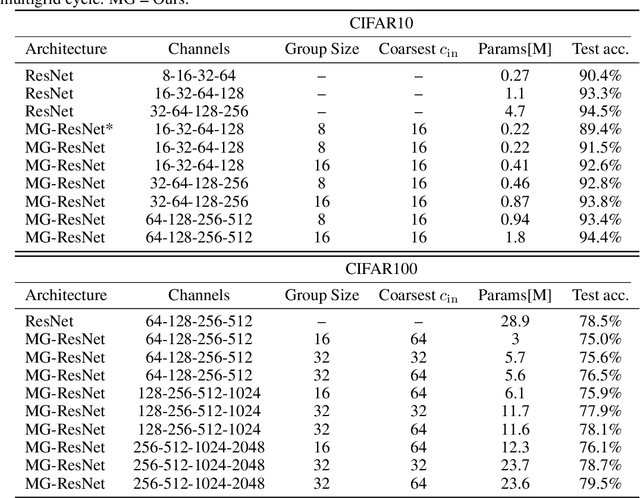
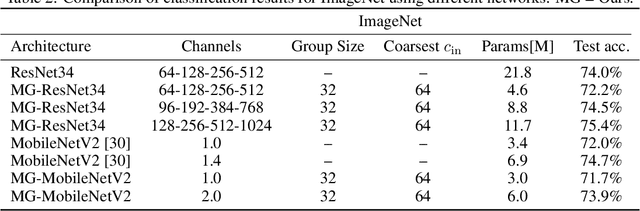
We present a multigrid approach that combats the quadratic growth of the number of parameters with respect to the number of channels in standard convolutional neural networks (CNNs). It has been shown that there is a redundancy in standard CNNs, as networks with much sparser convolution operators can yield similar performance to full networks. The sparsity patterns that lead to such behavior, however, are typically random, hampering hardware efficiency. In this work, we present a multigrid-in-channels approach for building CNN architectures that achieves full coupling of the channels, and whose number of parameters is linearly proportional to the width of the network. To this end, we replace each convolution layer in a generic CNN with a multilevel layer consisting of structured (i.e., grouped) convolutions. Our examples from supervised image classification show that applying this strategy to residual networks and MobileNetV2 considerably reduces the number of parameters without negatively affecting accuracy. Therefore, we can widen networks without dramatically increasing the number of parameters or operations.
Quantization in Relative Gradient Angle Domain For Building Polygon Estimation
Jul 10, 2020
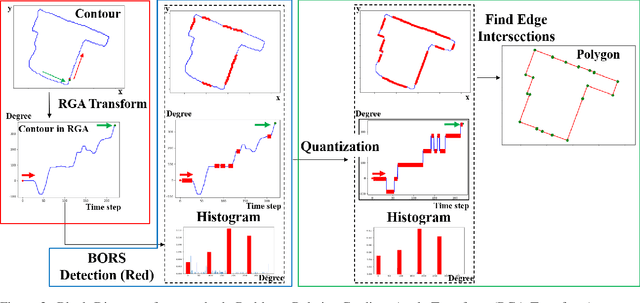
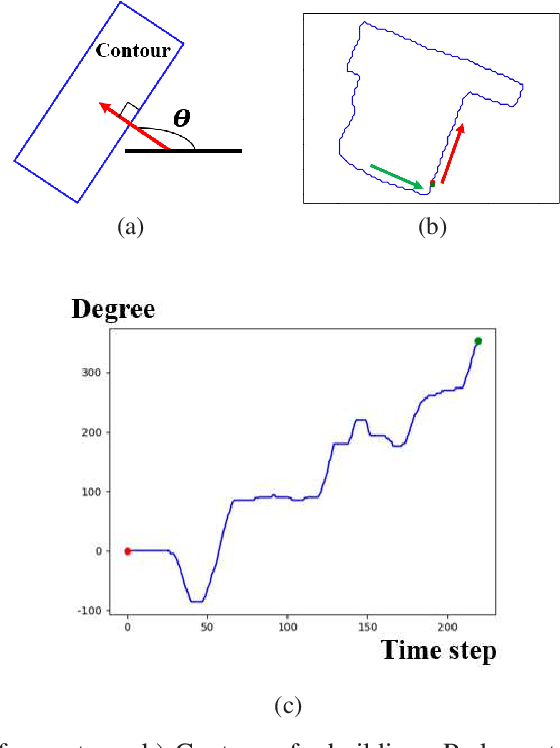
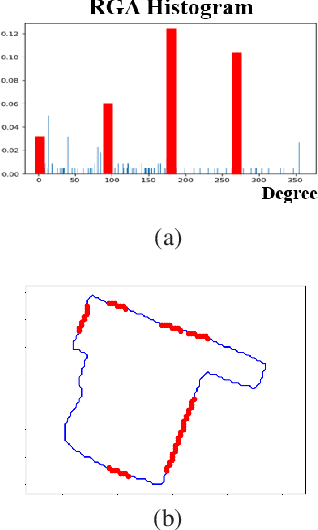
Building footprint extraction in remote sensing data benefits many important applications, such as urban planning and population estimation. Recently, rapid development of Convolutional Neural Networks (CNNs) and open-sourced high resolution satellite building image datasets have pushed the performance boundary further for automated building extractions. However, CNN approaches often generate imprecise building morphologies including noisy edges and round corners. In this paper, we leverage the performance of CNNs, and propose a module that uses prior knowledge of building corners to create angular and concise building polygons from CNN segmentation outputs. We describe a new transform, Relative Gradient Angle Transform (RGA Transform) that converts object contours from time vs. space to time vs. angle. We propose a new shape descriptor, Boundary Orientation Relation Set (BORS), to describe angle relationship between edges in RGA domain, such as orthogonality and parallelism. Finally, we develop an energy minimization framework that makes use of the angle relationship in BORS to straighten edges and reconstruct sharp corners, and the resulting corners create a polygon. Experimental results demonstrate that our method refines CNN output from a rounded approximation to a more clear-cut angular shape of the building footprint.
Smoothed Geometry for Robust Attribution
Jun 11, 2020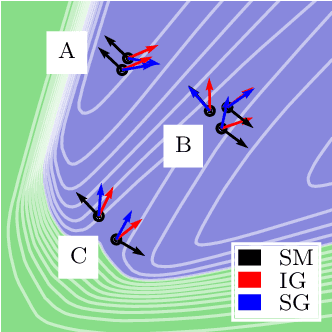
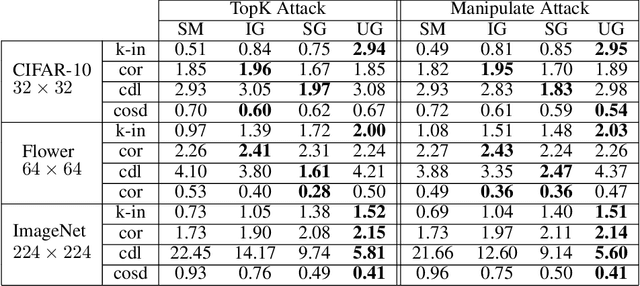
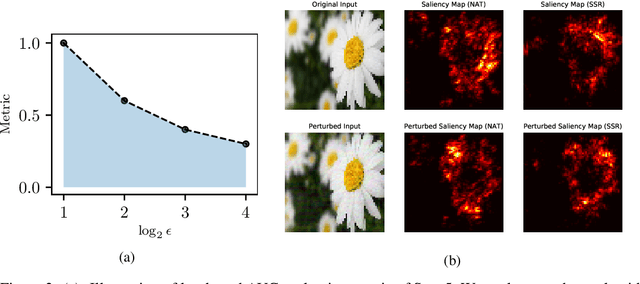
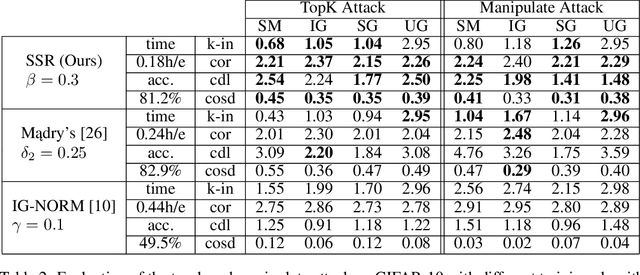
Feature attributions are a popular tool for explaining the behavior of Deep Neural Networks (DNNs), but have recently been shown to be vulnerable to attacks that produce divergent explanations for nearby inputs. This lack of robustness is especially problematic in high-stakes applications where adversarially-manipulated explanations could impair safety and trustworthiness. Building on a geometric understanding of these attacks presented in recent work, we identify Lipschitz continuity conditions on models' gradient that lead to robust gradient-based attributions, and observe that smoothness may also be related to the ability of an attack to transfer across multiple attribution methods. To mitigate these attacks in practice, we propose an inexpensive regularization method that promotes these conditions in DNNs, as well as a stochastic smoothing technique that does not require re-training. Our experiments on a range of image models demonstrate that both of these mitigations consistently improve attribution robustness, and confirm the role that smooth geometry plays in these attacks on real, large-scale models.
Cumulant GAN
Jun 11, 2020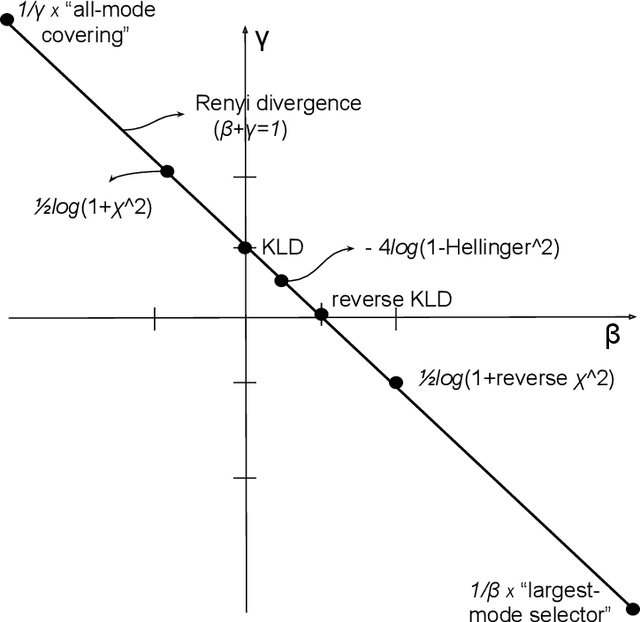
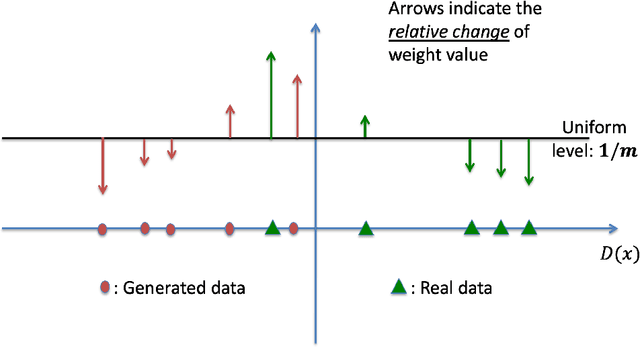
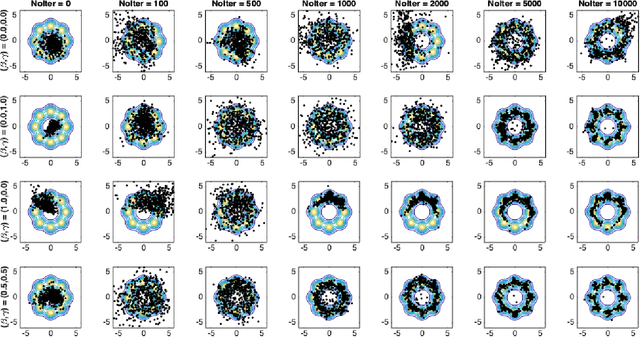
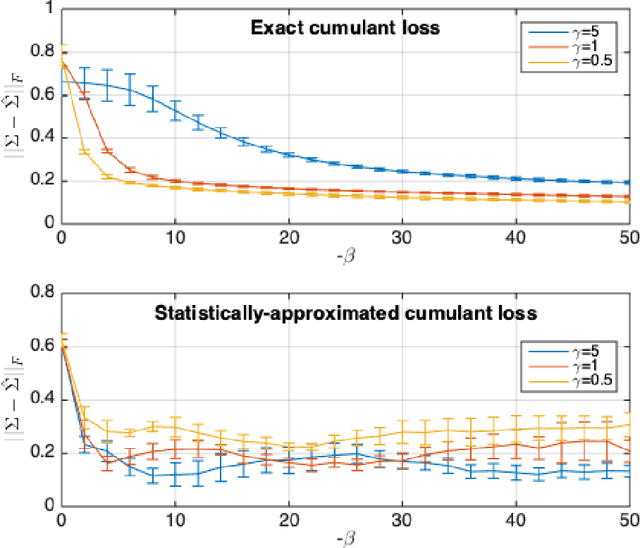
Despite the continuous improvements of Generative Adversarial Networks (GANs), stability and performance challenges still remain. In this work, we propose a novel loss function for GAN training aiming both for deeper theoretical understanding and improved performance of the underlying optimization problem. The new loss function is based on cumulant generating functions and relies on a recently-derived variational formula. We show that the corresponding optimization is equivalent to R\'enyi divergence minimization, thus offering a (partially) unified perspective of GAN losses: the R\'enyi family encompasses Kullback-Leibler divergence (KLD), reverse KLD, Hellinger distance and $\chi^2$-divergence. Wasserstein loss function is also included in the proposed cumulant GAN formulation. In terms of stability, we rigorously prove the convergence of the gradient descent algorithm for linear generator and linear discriminator for Gaussian distributions. Moreover, we numerically show that synthetic image generation trained on CIFAR-10 dataset is substantially improved in terms of inception score when weaker discriminators are considered.
What makes instance discrimination good for transfer learning?
Jun 11, 2020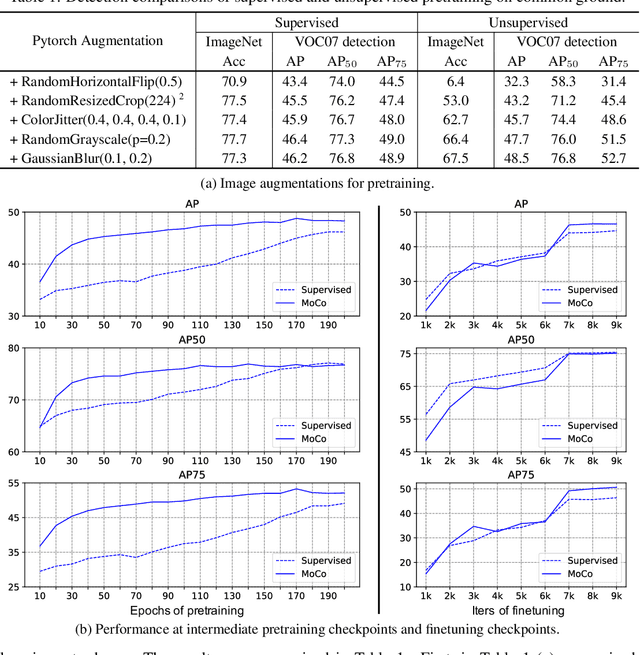
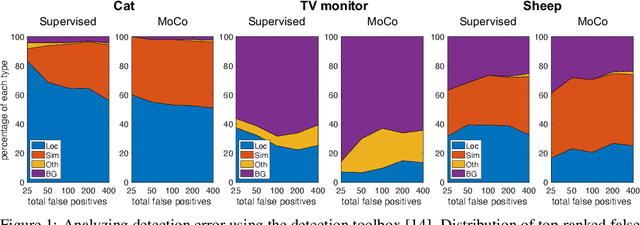
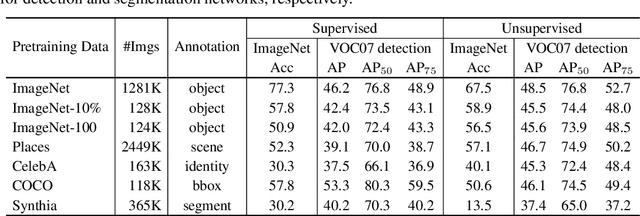

Unsupervised visual pretraining based on the instance discrimination pretext task has shown significant progress. Notably, in the recent work of MoCo, unsupervised pretraining has shown to surpass the supervised counterpart for finetuning downstream applications such as object detection on PASCAL VOC. It comes as a surprise that image annotations would be better left unused for transfer learning. In this work, we investigate the following problems: What makes instance discrimination pretraining good for transfer learning? What knowledge is actually learned and transferred from unsupervised pretraining? From this understanding of unsupervised pretraining, can we make supervised pretraining great again? Our findings are threefold. First, what truly matters for this detection transfer is low-level and mid-level representations, not high-level representations. Second, the intra-category invariance enforced by the traditional supervised model weakens transferability by increasing task misalignment. Finally, supervised pretraining can be strengthened by following an exemplar-based approach without explicit constraints among the instances within the same category.