 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 262 TOPS Hyperdimensional Photonic AI Accelerator powered by a Si3N4 microcomb laser
Mar 05, 2025



The ever-increasing volume of data has necessitated a new computing paradigm, embodied through Artificial Intelligence (AI) and Large Language Models (LLMs). Digital electronic AI computing systems, however, are gradually reaching their physical plateaus, stimulating extensive research towards next-generation AI accelerators. Photonic Neural Networks (PNNs), with their unique ability to capitalize on the interplay of multiple physical dimensions including time, wavelength, and space, have been brought forward with a credible promise for boosting computational power and energy efficiency in AI processors. In this article, we experimentally demonstrate a novel multidimensional arrayed waveguide grating router (AWGR)-based photonic AI accelerator that can execute tensor multiplications at a record-high total computational power of 262 TOPS, offering a ~24x improvement over the existing waveguide-based optical accelerators. It consists of a 16x16 AWGR that exploits the time-, wavelength- and space- division multiplexing (T-WSDM) for weight and input encoding together with an integrated Si3N4-based frequency comb for multi-wavelength generation. The photonic AI accelerator has been experimentally validated in both Fully-Connected (FC) and Convolutional NN (NNs) models, with the FC and CNN being trained for DDoS attack identification and MNIST classification, respectively. The experimental inference at 32 Gbaud achieved a Cohen's kappa score of 0.867 for DDoS detection and an accuracy of 92.14% for MNIST classification, respectively, closely matching the software performance.
Large Models in Dialogue for Active Perception and Anomaly Detection
Jan 27, 2025



Autonomous aerial monitoring is an important task aimed at gathering information from areas that may not be easily accessible by humans. At the same time, this task often requires recognizing anomalies from a significant distance or not previously encountered in the past. In this paper, we propose a novel framework that leverages the advanced capabilities provided by Large Language Models (LLMs) to actively collect information and perform anomaly detection in novel scenes. To this end, we propose an LLM based model dialogue approach, in which two deep learning models engage in a dialogue to actively control a drone to increase perception and anomaly detection accuracy. We conduct our experiments in a high fidelity simulation environment where an LLM is provided with a predetermined set of natural language movement commands mapped into executable code functions. Additionally, we deploy a multimodal Visual Question Answering (VQA) model charged with the task of visual question answering and captioning. By engaging the two models in conversation, the LLM asks exploratory questions while simultaneously flying a drone into different parts of the scene, providing a novel way to implement active perception. By leveraging LLMs reasoning ability, we output an improved detailed description of the scene going beyond existing static perception approaches. In addition to information gathering, our approach is utilized for anomaly detection and our results demonstrate the proposed methods effectiveness in informing and alerting about potential hazards.
Using Part-based Representations for Explainable Deep Reinforcement Learning
Aug 22, 2024Utilizing deep learning models to learn part-based representations holds significant potential for interpretable-by-design approaches, as these models incorporate latent causes obtained from feature representations through simple addition. However, training a part-based learning model presents challenges, particularly in enforcing non-negative constraints on the model's parameters, which can result in training difficulties such as instability and convergence issues. Moreover, applying such approaches in Deep Reinforcement Learning (RL) is even more demanding due to the inherent instabilities that impact many optimization methods. In this paper, we propose a non-negative training approach for actor models in RL, enabling the extraction of part-based representations that enhance interpretability while adhering to non-negative constraints. To this end, we employ a non-negative initialization technique, as well as a modified sign-preserving training method, which can ensure better gradient flow compared to existing approaches. We demonstrate the effectiveness of the proposed approach using the well-known Cartpole benchmark.
Deep Active Perception for Object Detection using Navigation Proposals
Dec 15, 2023Deep Learning (DL) has brought significant advances to robotics vision tasks. However, most existing DL methods have a major shortcoming, they rely on a static inference paradigm inherent in traditional computer vision pipelines. On the other hand, recent studies have found that active perception improves the perception abilities of various models by going beyond these static paradigms. Despite the significant potential of active perception, it poses several challenges, primarily involving significant changes in training pipelines for deep learning models. To overcome these limitations, in this work, we propose a generic supervised active perception pipeline for object detection that can be trained using existing off-the-shelf object detectors, while also leveraging advances in simulation environments. To this end, the proposed method employs an additional neural network architecture that estimates better viewpoints in cases where the object detector confidence is insufficient. The proposed method was evaluated on synthetic datasets, constructed within the Webots robotics simulator, showcasing its effectiveness in two object detection cases.
Non-negative isomorphic neural networks for photonic neuromorphic accelerators
Oct 02, 2023



Neuromorphic photonic accelerators are becoming increasingly popular, since they can significantly improve computation speed and energy efficiency, leading to femtojoule per MAC efficiency. However, deploying existing DL models on such platforms is not trivial, since a great range of photonic neural network architectures relies on incoherent setups and power addition operational schemes that cannot natively represent negative quantities. This results in additional hardware complexity that increases cost and reduces energy efficiency. To overcome this, we can train non-negative neural networks and potentially exploit the full range of incoherent neuromorphic photonic capabilities. However, existing approaches cannot achieve the same level of accuracy as their regular counterparts, due to training difficulties, as also recent evidence suggests. To this end, we introduce a methodology to obtain the non-negative isomorphic equivalents of regular neural networks that meet requirements of neuromorphic hardware, overcoming the aforementioned limitations. Furthermore, we also introduce a sign-preserving optimization approach that enables training of such isomorphic networks in a non-negative manner.
Multiplicative update rules for accelerating deep learning training and increasing robustness
Jul 14, 2023



Even nowadays, where Deep Learning (DL) has achieved state-of-the-art performance in a wide range of research domains, accelerating training and building robust DL models remains a challenging task. To this end, generations of researchers have pursued to develop robust methods for training DL architectures that can be less sensitive to weight distributions, model architectures and loss landscapes. However, such methods are limited to adaptive learning rate optimizers, initialization schemes, and clipping gradients without investigating the fundamental rule of parameters update. Although multiplicative updates have contributed significantly to the early development of machine learning and hold strong theoretical claims, to best of our knowledge, this is the first work that investigate them in context of DL training acceleration and robustness. In this work, we propose an optimization framework that fits to a wide range of optimization algorithms and enables one to apply alternative update rules. To this end, we propose a novel multiplicative update rule and we extend their capabilities by combining it with a traditional additive update term, under a novel hybrid update method. We claim that the proposed framework accelerates training, while leading to more robust models in contrast to traditionally used additive update rule and we experimentally demonstrate their effectiveness in a wide range of task and optimization methods. Such tasks ranging from convex and non-convex optimization to difficult image classification benchmarks applying a wide range of traditionally used optimization methods and Deep Neural Network (DNN) architectures.
Variational Voxel Pseudo Image Tracking
Feb 12, 2023


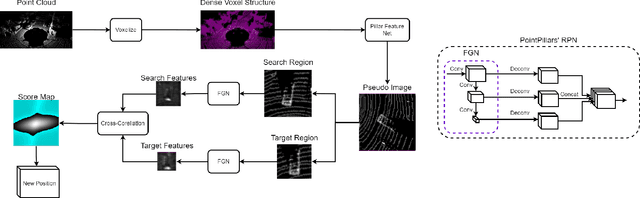
Uncertainty estimation is an important task for critical problems, such as robotics and autonomous driving, because it allows creating statistically better perception models and signaling the model's certainty in its predictions to the decision method or a human supervisor. In this paper, we propose a Variational Neural Network-based version of a Voxel Pseudo Image Tracking (VPIT) method for 3D Single Object Tracking. The Variational Feature Generation Network of the proposed Variational VPIT computes features for target and search regions and the corresponding uncertainties, which are later combined using an uncertainty-aware cross-correlation module in one of two ways: by computing similarity between the corresponding uncertainties and adding it to the regular cross-correlation values, or by penalizing the uncertain feature channels to increase influence of the certain features. In experiments, we show that both methods improve tracking performance, while penalization of uncertain features provides the best uncertainty quality.
A Novel Dataset for Evaluating and Alleviating Domain Shift for Human Detection in Agricultural Fields
Sep 27, 2022


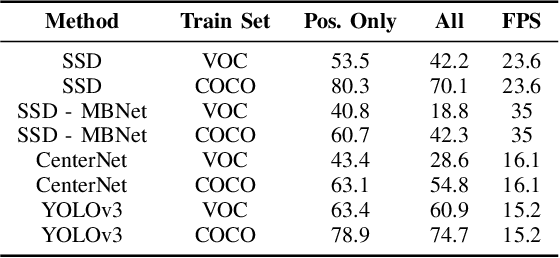
In this paper we evaluate the impact of domain shift on human detection models trained on well known object detection datasets when deployed on data outside the distribution of the training set, as well as propose methods to alleviate such phenomena based on the available annotations from the target domain. Specifically, we introduce the OpenDR Humans in Field dataset, collected in the context of agricultural robotics applications, using the Robotti platform, allowing for quantitatively measuring the impact of domain shift in such applications. Furthermore, we examine the importance of manual annotation by evaluating three distinct scenarios concerning the training data: a) only negative samples, i.e., no depicted humans, b) only positive samples, i.e., only images which contain humans, and c) both negative and positive samples. Our results indicate that good performance can be achieved even when using only negative samples, if additional consideration is given to the training process. We also find that positive samples increase performance especially in terms of better localization. The dataset is publicly available for download at https://github.com/opendr-eu/datasets.
MLGWSC-1: The first Machine Learning Gravitational-Wave Search Mock Data Challenge
Sep 22, 2022
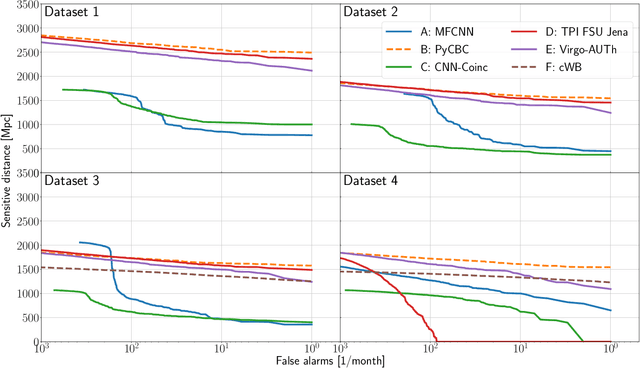
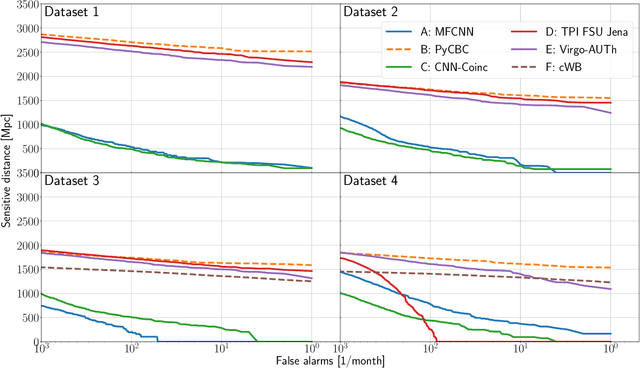
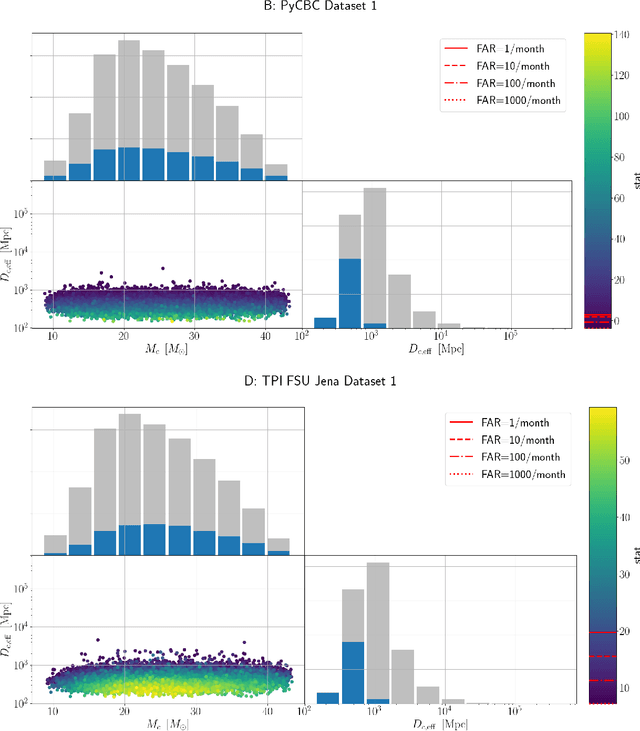
We present the results of the first Machine Learning Gravitational-Wave Search Mock Data Challenge (MLGWSC-1). For this challenge, participating groups had to identify gravitational-wave signals from binary black hole mergers of increasing complexity and duration embedded in progressively more realistic noise. The final of the 4 provided datasets contained real noise from the O3a observing run and signals up to a duration of 20 seconds with the inclusion of precession effects and higher order modes. We present the average sensitivity distance and runtime for the 6 entered algorithms derived from 1 month of test data unknown to the participants prior to submission. Of these, 4 are machine learning algorithms. We find that the best machine learning based algorithms are able to achieve up to 95% of the sensitive distance of matched-filtering based production analyses for simulated Gaussian noise at a false-alarm rate (FAR) of one per month. In contrast, for real noise, the leading machine learning search achieved 70%. For higher FARs the differences in sensitive distance shrink to the point where select machine learning submissions outperform traditional search algorithms at FARs $\geq 200$ per month on some datasets. Our results show that current machine learning search algorithms may already be sensitive enough in limited parameter regions to be useful for some production settings. To improve the state-of-the-art, machine learning algorithms need to reduce the false-alarm rates at which they are capable of detecting signals and extend their validity to regions of parameter space where modeled searches are computationally expensive to run. Based on our findings we compile a list of research areas that we believe are the most important to elevate machine learning searches to an invaluable tool in gravitational-wave signal detection.
VPIT: Real-time Embedded Single Object 3D Tracking Using Voxel Pseudo Images
Jun 06, 2022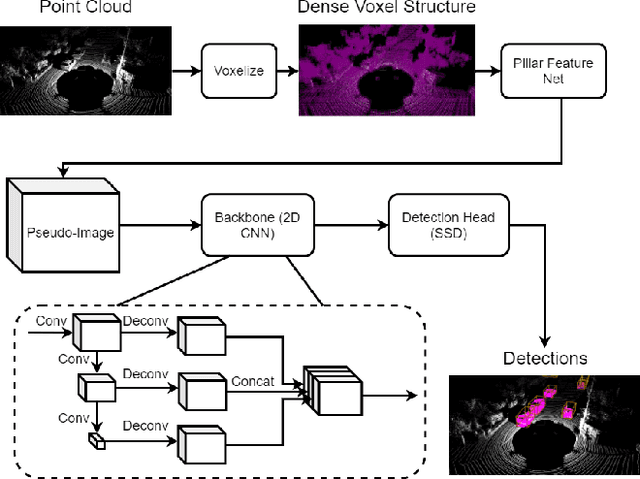


In this paper, we propose a novel voxel-based 3D single object tracking (3D SOT) method called Voxel Pseudo Image Tracking (VPIT). VPIT is the first method that uses voxel pseudo images for 3D SOT. The input point cloud is structured by pillar-based voxelization, and the resulting pseudo image is used as an input to a 2D-like Siamese SOT method. The pseudo image is created in the Bird's-eye View (BEV) coordinates, and therefore the objects in it have constant size. Thus, only the object rotation can change in the new coordinate system and not the object scale. For this reason, we replace multi-scale search with a multi-rotation search, where differently rotated search regions are compared against a single target representation to predict both position and rotation of the object. Experiments on KITTI Tracking dataset show that VPIT is the fastest 3D SOT method and maintains competitive Success and Precision values. Application of a SOT method in a real-world scenario meets with limitations such as lower computational capabilities of embedded devices and a latency-unforgiving environment, where the method is forced to skip certain data frames if the inference speed is not high enough. We implement a real-time evaluation protocol and show that other methods lose most of their performance on embedded devices, while VPIT maintains its ability to track the object.