 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultigrid-in-Channels Neural Network Architectures
Nov 19, 2020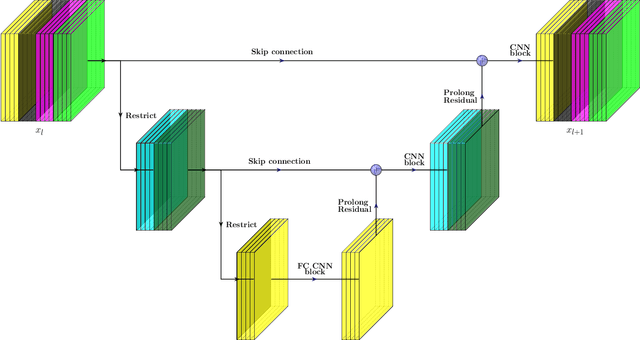
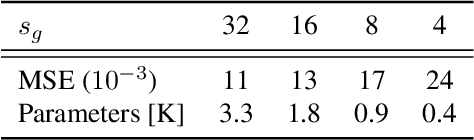
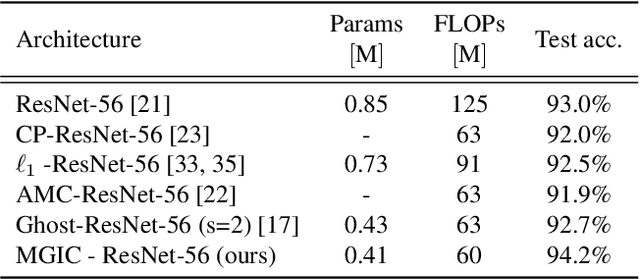
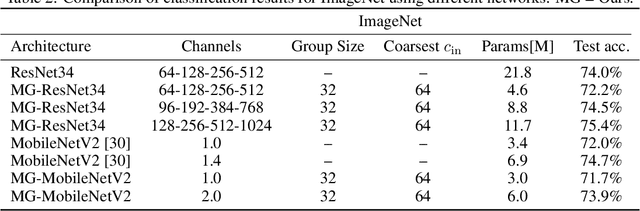
We present a multigrid-in-channels (MGIC) approach that tackles the quadratic growth of the number of parameters with respect to the number of channels in standard convolutional neural networks (CNNs). It has been shown that there is a redundancy in standard CNNs, as networks with light or sparse convolution operators yield similar performance to full networks. However, the number of parameters in the former networks also scales quadratically in width, while in the latter case, the parameters typically have random sparsity patterns, hampering hardware efficiency. Our approach for building CNN architectures scales linearly with respect to the network's width while retaining full coupling of the channels as in standard CNNs. To this end, we replace each convolution block with its MGIC block utilizing a hierarchy of lightweight convolutions. Our extensive experiments on image classification, segmentation, and point cloud classification show that applying this strategy to different architectures like ResNet and MobileNetV3 considerably reduces the number of parameters while obtaining similar or better accuracy. For example, we obtain 76.1% top-1 accuracy on ImageNet with a lightweight network with similar parameters and FLOPs to MobileNetV3.
Multigrid-in-Channels Architectures for Wide Convolutional Neural Networks
Jun 11, 2020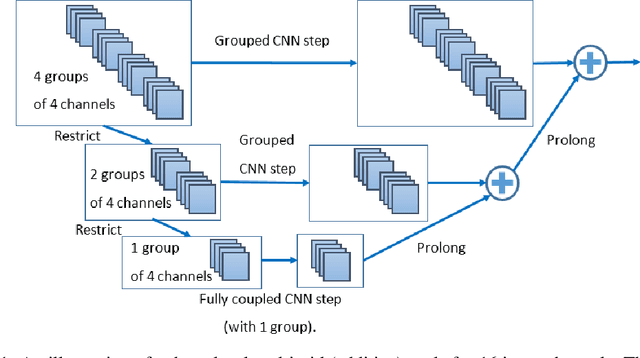
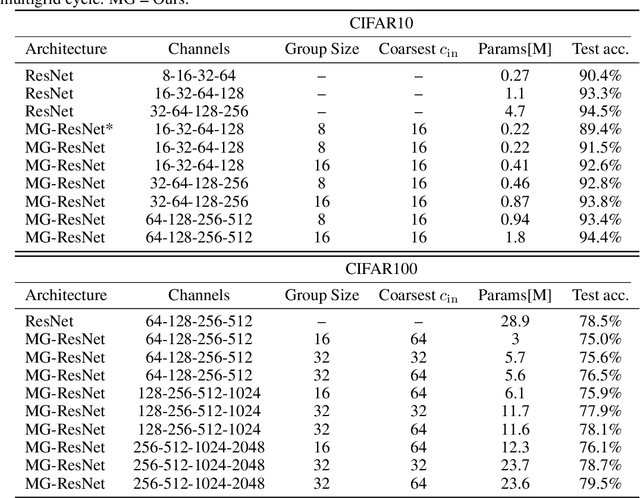
We present a multigrid approach that combats the quadratic growth of the number of parameters with respect to the number of channels in standard convolutional neural networks (CNNs). It has been shown that there is a redundancy in standard CNNs, as networks with much sparser convolution operators can yield similar performance to full networks. The sparsity patterns that lead to such behavior, however, are typically random, hampering hardware efficiency. In this work, we present a multigrid-in-channels approach for building CNN architectures that achieves full coupling of the channels, and whose number of parameters is linearly proportional to the width of the network. To this end, we replace each convolution layer in a generic CNN with a multilevel layer consisting of structured (i.e., grouped) convolutions. Our examples from supervised image classification show that applying this strategy to residual networks and MobileNetV2 considerably reduces the number of parameters without negatively affecting accuracy. Therefore, we can widen networks without dramatically increasing the number of parameters or operations.
LeanConvNets: Low-cost Yet Effective Convolutional Neural Networks
Oct 29, 2019
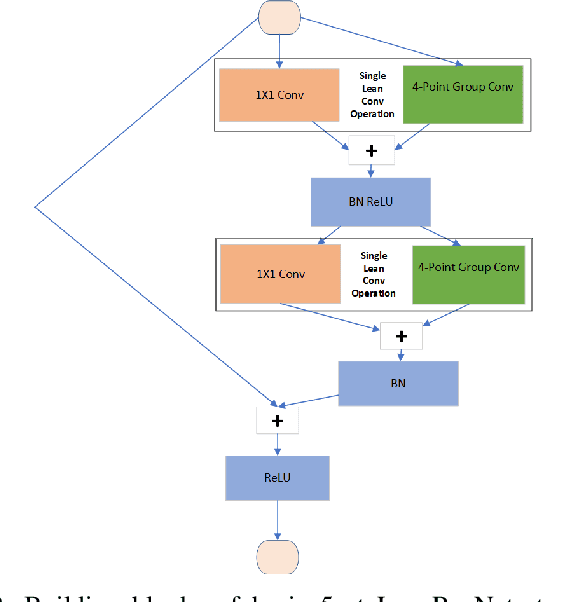
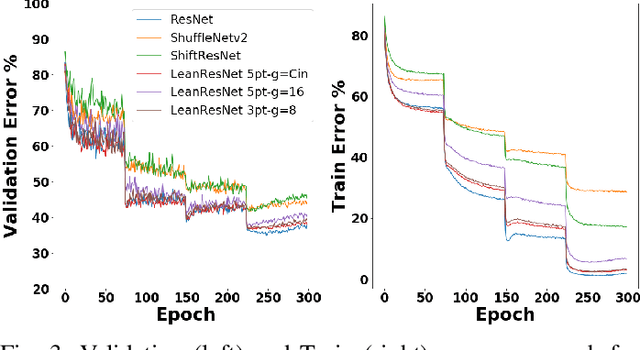
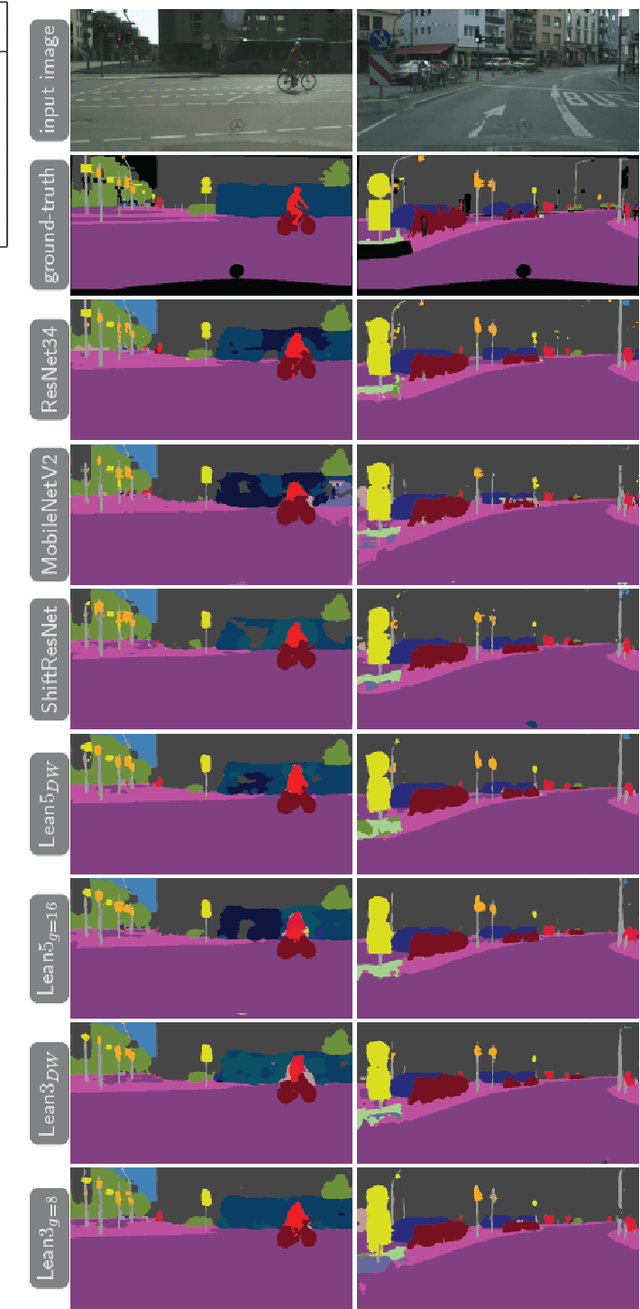
Convolutional Neural Networks (CNNs) have become indispensable for solving machine learning tasks in speech recognition, computer vision, and other areas that involve high-dimensional data. A CNN filters the input feature using a network containing spatial convolution operators with compactly supported stencils. In practice, the input data and the hidden features consist of a large number of channels, which in most CNNs are fully coupled by the convolution operators. This coupling leads to immense computational cost in the training and prediction phase. In this paper, we introduce LeanConvNets that are derived by sparsifying fully-coupled operators in existing CNNs. Our goal is to improve the efficiency of CNNs by reducing the number of weights, floating point operations and latency times, with minimal loss of accuracy. Our lean convolution operators involve tuning parameters that controls the trade-off between the network's accuracy and computational costs. These convolutions can be used in a wide range of existing networks, and we exemplify their use in residual networks (ResNets) and U-Nets. Using a range of benchmark problems from image classification and semantic segmentation, we demonstrate that the resulting LeanConvNet's accuracy is close to state-of-the-art networks while being computationally less expensive. In our tests, the lean versions of ResNet and U-net slightly outperforms comparable reduced architectures such as MobileNets and ShuffleNets.
LeanResNet: A Low-cost Yet Effective Convolutional Residual Networks
May 16, 2019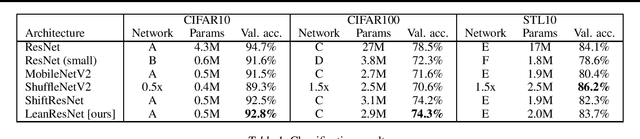
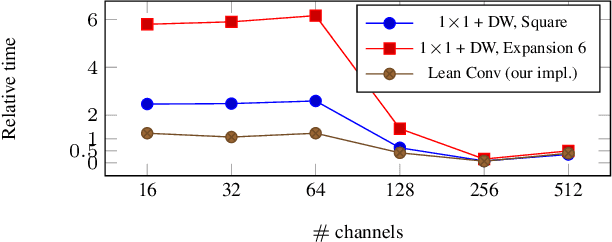
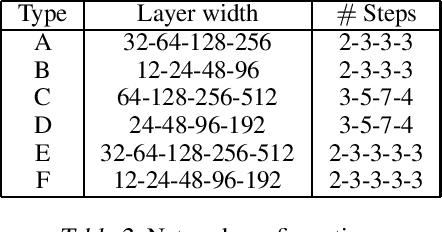
Convolutional Neural Networks (CNNs) filter the input data using spatial convolution operators with compact stencils. Commonly, the convolution operators couple features from all channels, which leads to immense computational cost in the training of and prediction with CNNs. To improve the efficiency of CNNs, we introduce lean convolution operators that reduce the number of parameters and computational complexity, and can be used in a wide range of existing CNNs. Here, we exemplify their use in residual networks (ResNets), which have been very reliable for a few years now and analyzed intensively. In our experiments on three image classification problems, the proposed LeanResNet yields results that are comparable to other recently proposed reduced architectures using similar number of parameters.