 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Growing Efficient Deep Networks by Structured Continuous Sparsification
Jul 30, 2020
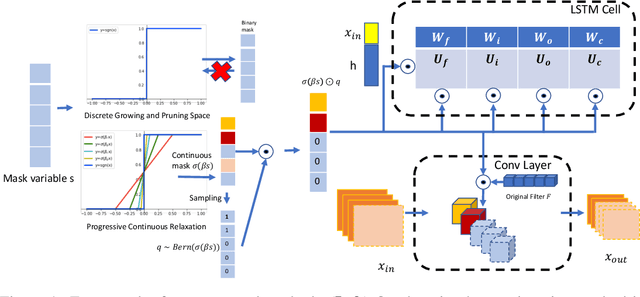
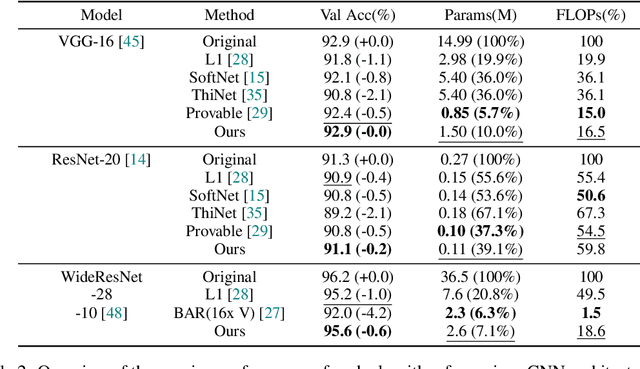
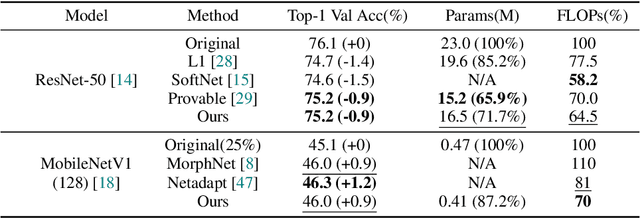
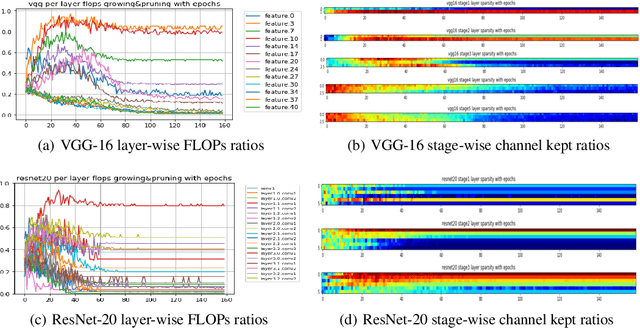
We develop an approach to training deep networks while dynamically adjusting their architecture, driven by a principled combination of accuracy and sparsity objectives. Unlike conventional pruning approaches, our method adopts a gradual continuous relaxation of discrete network structure optimization and then samples sparse subnetworks, enabling efficient deep networks to be trained in a growing and pruning manner. Extensive experiments across CIFAR-10, ImageNet, PASCAL VOC, and Penn Treebank, with convolutional models for image classification and semantic segmentation, and recurrent models for language modeling, show that our training scheme yields efficient networks that are smaller and more accurate than those produced by competing pruning methods.
Learning to Visually Navigate in Photorealistic Environments Without any Supervision
Apr 10, 2020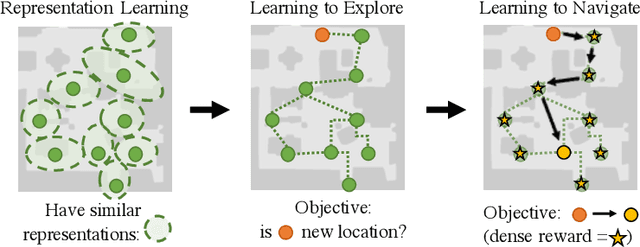
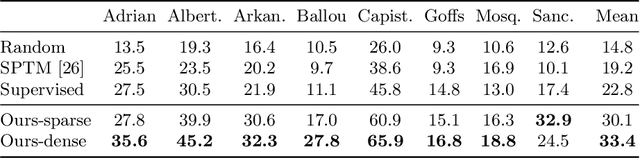
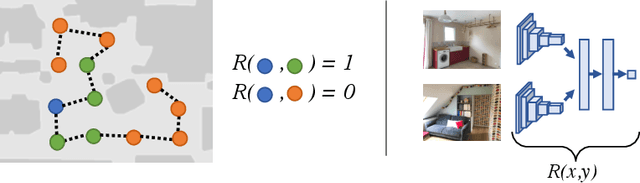
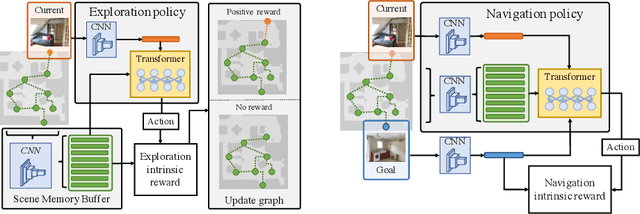
Learning to navigate in a realistic setting where an agent must rely solely on visual inputs is a challenging task, in part because the lack of position information makes it difficult to provide supervision during training. In this paper, we introduce a novel approach for learning to navigate from image inputs without external supervision or reward. Our approach consists of three stages: learning a good representation of first-person views, then learning to explore using memory, and finally learning to navigate by setting its own goals. The model is trained with intrinsic rewards only so that it can be applied to any environment with image observations. We show the benefits of our approach by training an agent to navigate challenging photo-realistic environments from the Gibson dataset with RGB inputs only.
Cost-Effective Active Learning for Deep Image Classification
Jan 13, 2017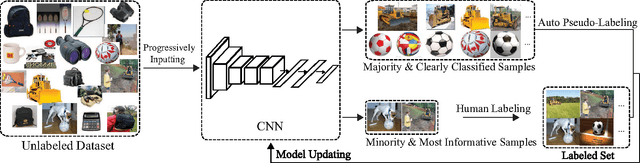

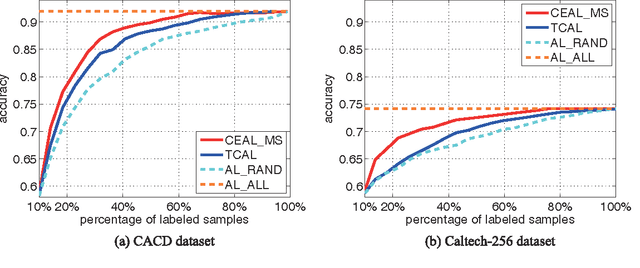
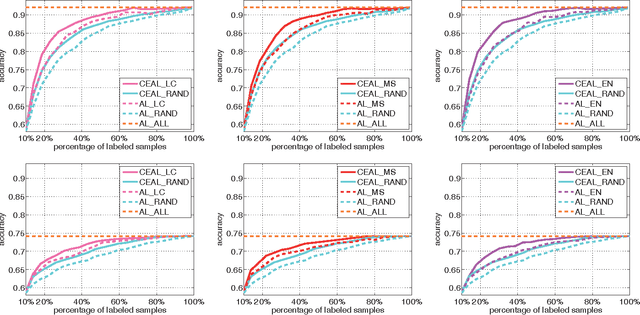
Recent successes in learning-based image classification, however, heavily rely on the large number of annotated training samples, which may require considerable human efforts. In this paper, we propose a novel active learning framework, which is capable of building a competitive classifier with optimal feature representation via a limited amount of labeled training instances in an incremental learning manner. Our approach advances the existing active learning methods in two aspects. First, we incorporate deep convolutional neural networks into active learning. Through the properly designed framework, the feature representation and the classifier can be simultaneously updated with progressively annotated informative samples. Second, we present a cost-effective sample selection strategy to improve the classification performance with less manual annotations. Unlike traditional methods focusing on only the uncertain samples of low prediction confidence, we especially discover the large amount of high confidence samples from the unlabeled set for feature learning. Specifically, these high confidence samples are automatically selected and iteratively assigned pseudo-labels. We thus call our framework "Cost-Effective Active Learning" (CEAL) standing for the two advantages.Extensive experiments demonstrate that the proposed CEAL framework can achieve promising results on two challenging image classification datasets, i.e., face recognition on CACD database [1] and object categorization on Caltech-256 [2].
Multimodal Generative Models for Compositional Representation Learning
Dec 11, 2019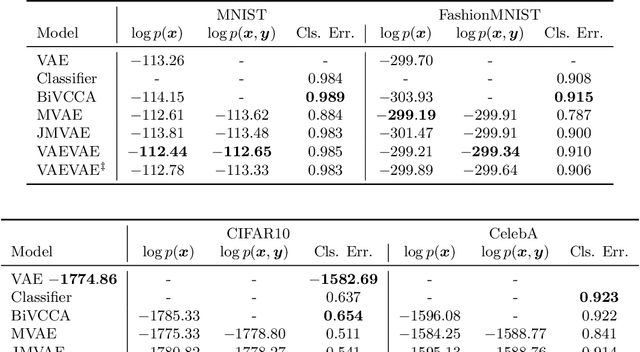
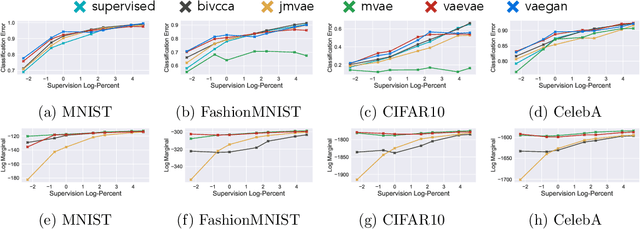
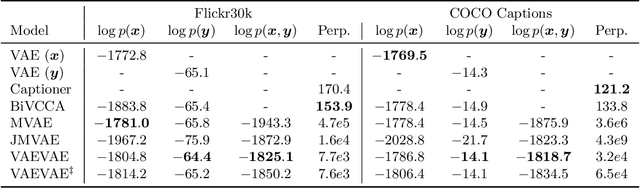
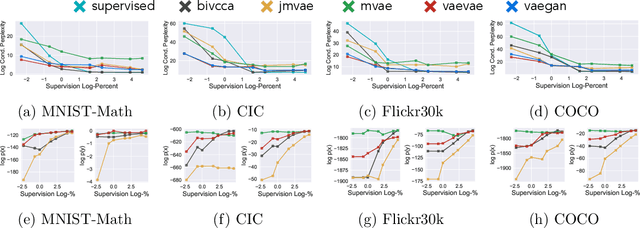
As deep neural networks become more adept at traditional tasks, many of the most exciting new challenges concern multimodality---observations that combine diverse types, such as image and text. In this paper, we introduce a family of multimodal deep generative models derived from variational bounds on the evidence (data marginal likelihood). As part of our derivation we find that many previous multimodal variational autoencoders used objectives that do not correctly bound the joint marginal likelihood across modalities. We further generalize our objective to work with several types of deep generative model (VAE, GAN, and flow-based), and allow use of different model types for different modalities. We benchmark our models across many image, label, and text datasets, and find that our multimodal VAEs excel with and without weak supervision. Additional improvements come from use of GAN image models with VAE language models. Finally, we investigate the effect of language on learned image representations through a variety of downstream tasks, such as compositionally, bounding box prediction, and visual relation prediction. We find evidence that these image representations are more abstract and compositional than equivalent representations learned from only visual data.
S3K: Self-Supervised Semantic Keypoints for Robotic Manipulation via Multi-View Consistency
Oct 13, 2020

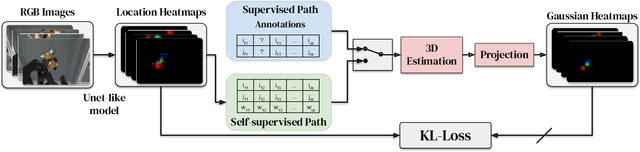
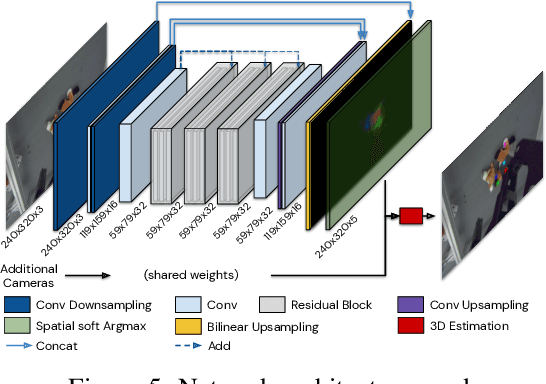
A robot's ability to act is fundamentally constrained by what it can perceive. Many existing approaches to visual representation learning utilize general-purpose training criteria, e.g. image reconstruction, smoothness in latent space, or usefulness for control, or else make use of large datasets annotated with specific features (bounding boxes, segmentations, etc.). However, both approaches often struggle to capture the fine-detail required for precision tasks on specific objects, e.g. grasping and mating a plug and socket. We argue that these difficulties arise from a lack of geometric structure in these models. In this work we advocate semantic 3D keypoints as a visual representation, and present a semi-supervised training objective that can allow instance or category-level keypoints to be trained to 1-5 millimeter-accuracy with minimal supervision. Furthermore, unlike local texture-based approaches, our model integrates contextual information from a large area and is therefore robust to occlusion, noise, and lack of discernible texture. We demonstrate that this ability to locate semantic keypoints enables high level scripting of human understandable behaviours. Finally we show that these keypoints provide a good way to define reward functions for reinforcement learning and are a good representation for training agents.
A Scale and Rotational Invariant Key-point Detector based on Sparse Coding
Oct 13, 2020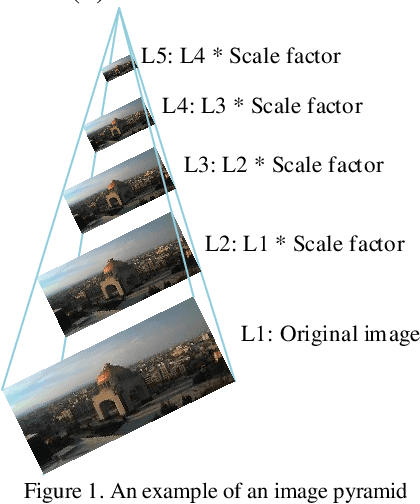
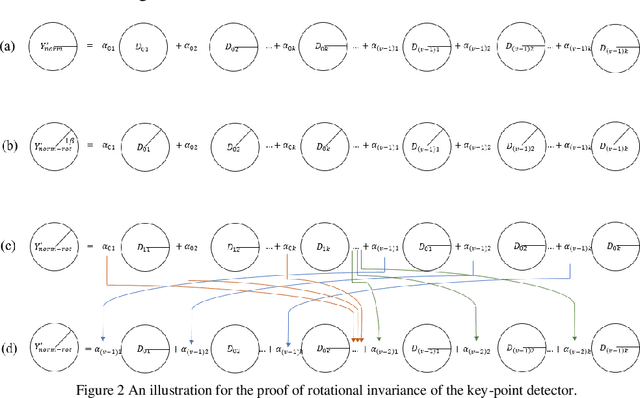


Most popular hand-crafted key-point detectors such as Harris corner, SIFT, SURF aim to detect corners, blobs, junctions or other human defined structures in images. Though being robust with some geometric transformations, unintended scenarios or non-uniform lighting variations could significantly degrade their performance. Hence, a new detector that is flexible with context change and simultaneously robust with both geometric and non-uniform illumination variations is very desirable. In this paper, we propose a solution to this challenging problem by incorporating Scale and Rotation Invariant design (named SRI-SCK) into a recently developed Sparse Coding based Key-point detector (SCK). The SCK detector is flexible in different scenarios and fully invariant to affine intensity change, yet it is not designed to handle images with drastic scale and rotation changes. In SRI-SCK, the scale invariance is implemented with an image pyramid technique while the rotation invariance is realized by combining multiple rotated versions of the dictionary used in the sparse coding step of SCK. Techniques for calculation of key-points' characteristic scales and their sub-pixel accuracy positions are also proposed. Experimental results on three public datasets demonstrate that significantly high repeatability and matching score are achieved.
Editable Neural Networks
Apr 01, 2020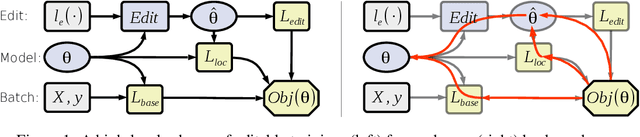



These days deep neural networks are ubiquitously used in a wide range of tasks, from image classification and machine translation to face identification and self-driving cars. In many applications, a single model error can lead to devastating financial, reputational and even life-threatening consequences. Therefore, it is crucially important to correct model mistakes quickly as they appear. In this work, we investigate the problem of neural network editing $-$ how one can efficiently patch a mistake of the model on a particular sample, without influencing the model behavior on other samples. Namely, we propose Editable Training, a model-agnostic training technique that encourages fast editing of the trained model. We empirically demonstrate the effectiveness of this method on large-scale image classification and machine translation tasks.
RealHePoNet: a robust single-stage ConvNet for head pose estimation in the wild
Nov 03, 2020
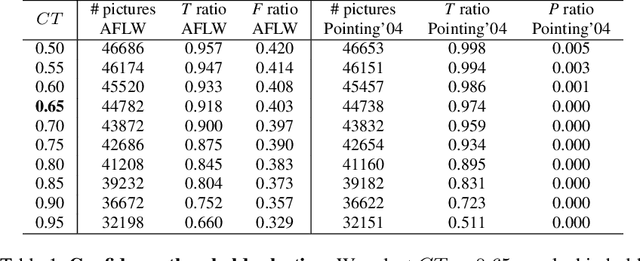

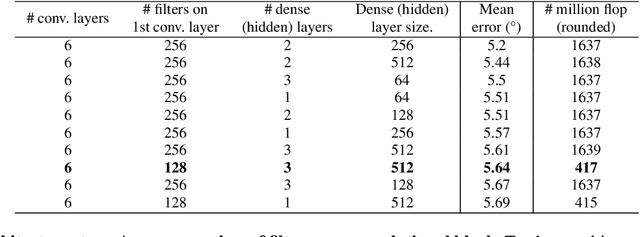
Human head pose estimation in images has applications in many fields such as human-computer interaction or video surveillance tasks. In this work, we address this problem, defined here as the estimation of both vertical (tilt/pitch) and horizontal (pan/yaw) angles, through the use of a single Convolutional Neural Network (ConvNet) model, trying to balance precision and inference speed in order to maximize its usability in real-world applications. Our model is trained over the combination of two datasets: 'Pointing'04' (aiming at covering a wide range of poses) and 'Annotated Facial Landmarks in the Wild' (in order to improve robustness of our model for its use on real-world images). Three different partitions of the combined dataset are defined and used for training, validation and testing purposes. As a result of this work, we have obtained a trained ConvNet model, coined RealHePoNet, that given a low-resolution grayscale input image, and without the need of using facial landmarks, is able to estimate with low error both tilt and pan angles (~4.4{\deg} average error on the test partition). Also, given its low inference time (~6 ms per head), we consider our model usable even when paired with medium-spec hardware (i.e. GTX 1060 GPU). * Code available at: https://github.com/rafabs97/headpose_final * Demo video at: https://www.youtube.com/watch?v=2UeuXh5DjAE
Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections
Sep 01, 2016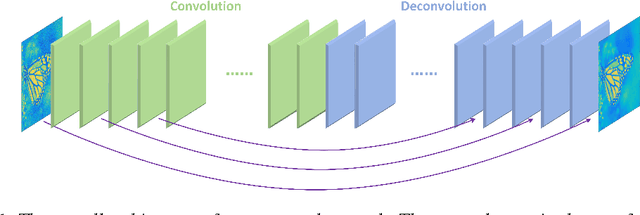
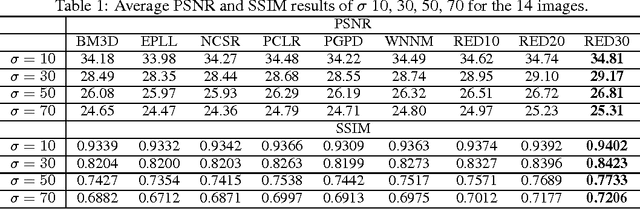
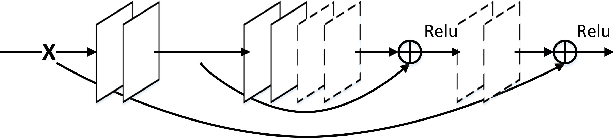
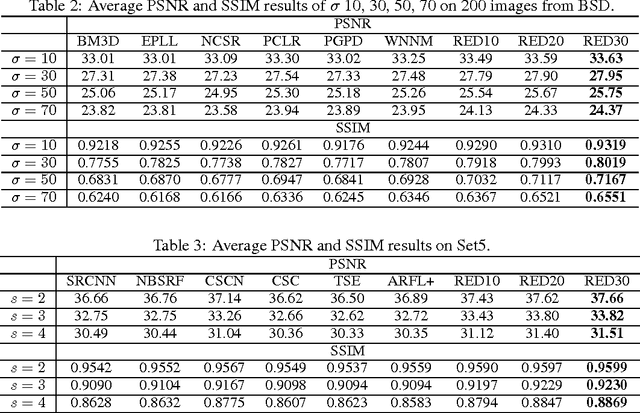
In this paper, we propose a very deep fully convolutional encoding-decoding framework for image restoration such as denoising and super-resolution. The network is composed of multiple layers of convolution and de-convolution operators, learning end-to-end mappings from corrupted images to the original ones. The convolutional layers act as the feature extractor, which capture the abstraction of image contents while eliminating noises/corruptions. De-convolutional layers are then used to recover the image details. We propose to symmetrically link convolutional and de-convolutional layers with skip-layer connections, with which the training converges much faster and attains a higher-quality local optimum. First, The skip connections allow the signal to be back-propagated to bottom layers directly, and thus tackles the problem of gradient vanishing, making training deep networks easier and achieving restoration performance gains consequently. Second, these skip connections pass image details from convolutional layers to de-convolutional layers, which is beneficial in recovering the original image. Significantly, with the large capacity, we can handle different levels of noises using a single model. Experimental results show that our network achieves better performance than all previously reported state-of-the-art methods.
Client Adaptation improves Federated Learning with Simulated Non-IID Clients
Jul 09, 2020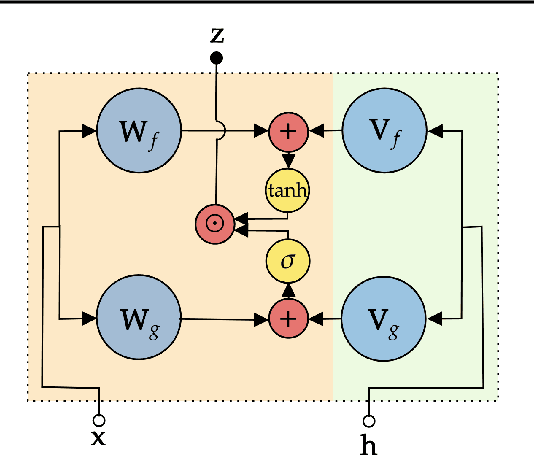
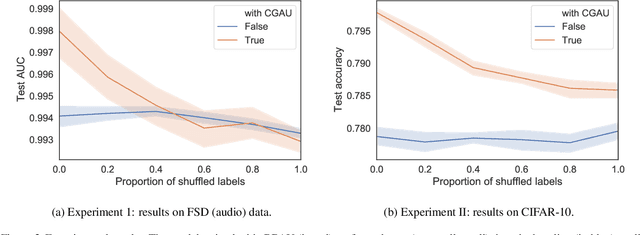
We present a federated learning approach for learning a client adaptable, robust model when data is non-identically and non-independently distributed (non-IID) across clients. By simulating heterogeneous clients, we show that adding learned client-specific conditioning improves model performance, and the approach is shown to work on balanced and imbalanced data set from both audio and image domains. The client adaptation is implemented by a conditional gated activation unit and is particularly beneficial when there are large differences between the data distribution for each client, a common scenario in federated learning.