 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Finding the Evidence: Localization-aware Answer Prediction for Text Visual Question Answering
Oct 06, 2020
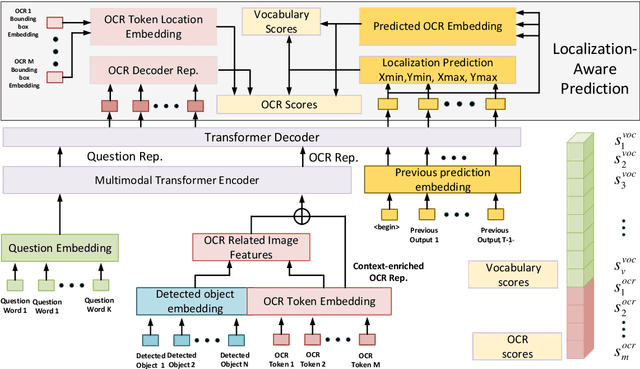
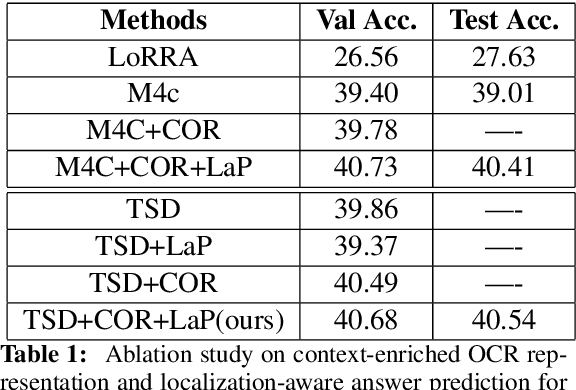

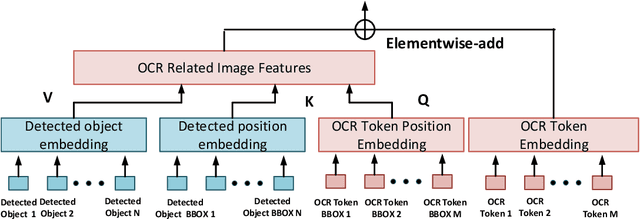
Image text carries essential information to understand the scene and perform reasoning. Text-based visual question answering (text VQA) task focuses on visual questions that require reading text in images. Existing text VQA systems generate an answer by selecting from optical character recognition (OCR) texts or a fixed vocabulary. Positional information of text is underused and there is a lack of evidence for the generated answer. As such, this paper proposes a localization-aware answer prediction network (LaAP-Net) to address this challenge. Our LaAP-Net not only generates the answer to the question but also predicts a bounding box as evidence of the generated answer. Moreover, a context-enriched OCR representation (COR) for multimodal fusion is proposed to facilitate the localization task. Our proposed LaAP-Net outperforms existing approaches on three benchmark datasets for the text VQA task by a noticeable margin.
Improved Lossy Image Compression with Priming and Spatially Adaptive Bit Rates for Recurrent Networks
Mar 29, 2017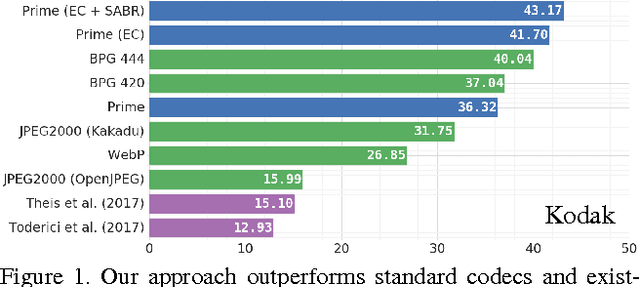

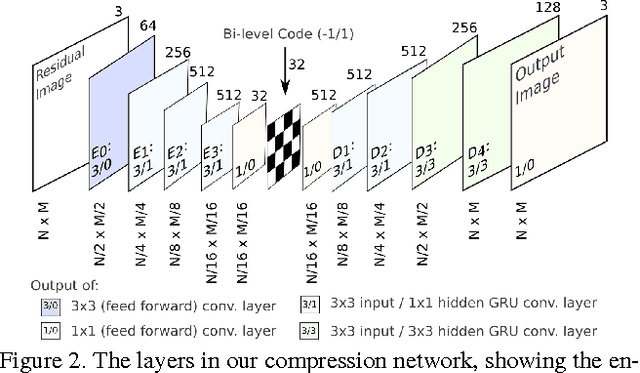
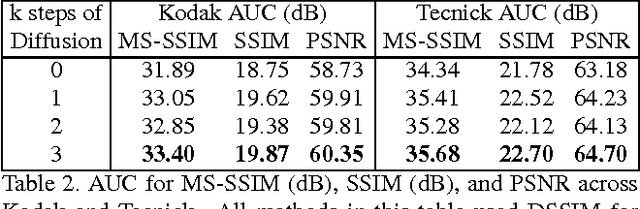
We propose a method for lossy image compression based on recurrent, convolutional neural networks that outperforms BPG (4:2:0 ), WebP, JPEG2000, and JPEG as measured by MS-SSIM. We introduce three improvements over previous research that lead to this state-of-the-art result. First, we show that training with a pixel-wise loss weighted by SSIM increases reconstruction quality according to several metrics. Second, we modify the recurrent architecture to improve spatial diffusion, which allows the network to more effectively capture and propagate image information through the network's hidden state. Finally, in addition to lossless entropy coding, we use a spatially adaptive bit allocation algorithm to more efficiently use the limited number of bits to encode visually complex image regions. We evaluate our method on the Kodak and Tecnick image sets and compare against standard codecs as well recently published methods based on deep neural networks.
Data Augmentation via Mixed Class Interpolation using Cycle-Consistent Generative Adversarial Networks Applied to Cross-Domain Imagery
May 05, 2020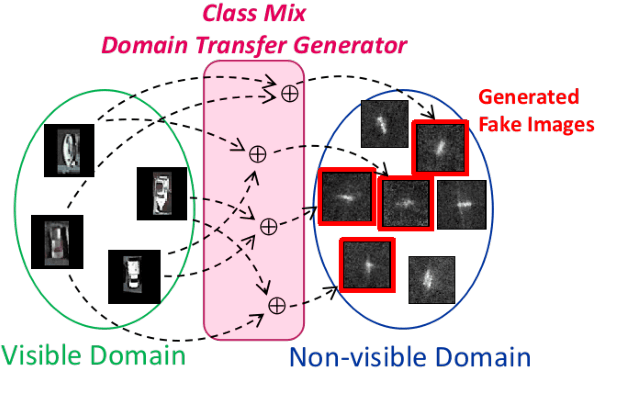
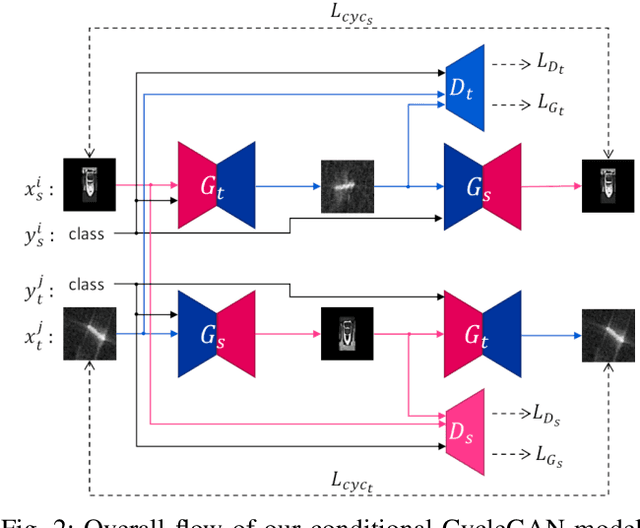


Machine learning driven object detection and classification within non-visible imagery has an important role in many fields such as night vision, all-weather surveillance and aviation security. However, such applications often suffer due to the limited quantity and variety of non-visible spectral domain imagery, where by contrast the high data availability in visible-band imagery readily enables contemporary deep learning driven detection and classification approaches. To address this problem, this paper proposes and evaluates a novel data augmentation approach that leverages the more readily available visible-band imagery via a generative domain transfer model. The model can synthesise large volumes of non-visible domain imagery by image translation from the visible image domain. Furthermore, we show that the generation of interpolated mixed class (non-visible domain) image examples via our novel Conditional CycleGAN Mixup Augmentation (C2GMA) methodology can lead to a significant improvement in the quality for non-visible domain classification tasks that otherwise suffer due to limited data availability. Focusing on classification within the Synthetic Aperture Radar (SAR) domain, our approach is evaluated on a variation of the Statoil/C-CORE Iceberg Classifier Challenge dataset and achieves 75.4% accuracy, demonstrating a significant improvement when compared against traditional data augmentation strategies.
Using a Bi-directional LSTM Model with Attention Mechanism trained on MIDI Data for Generating Unique Music
Nov 02, 2020


Generating music is an interesting and challenging problem in the field of machine learning. Mimicking human creativity has been popular in recent years, especially in the field of computer vision and image processing. With the advent of GANs, it is possible to generate new similar images, based on trained data. But this cannot be done for music similarly, as music has an extra temporal dimension. So it is necessary to understand how music is represented in digital form. When building models that perform this generative task, the learning and generation part is done in some high-level representation such as MIDI (Musical Instrument Digital Interface) or scores. This paper proposes a bi-directional LSTM (Long short-term memory) model with attention mechanism capable of generating similar type of music based on MIDI data. The music generated by the model follows the theme/style of the music the model is trained on. Also, due to the nature of MIDI, the tempo, instrument, and other parameters can be defined, and changed, post generation.
Deep Hashing for Secure Multimodal Biometrics
Dec 29, 2020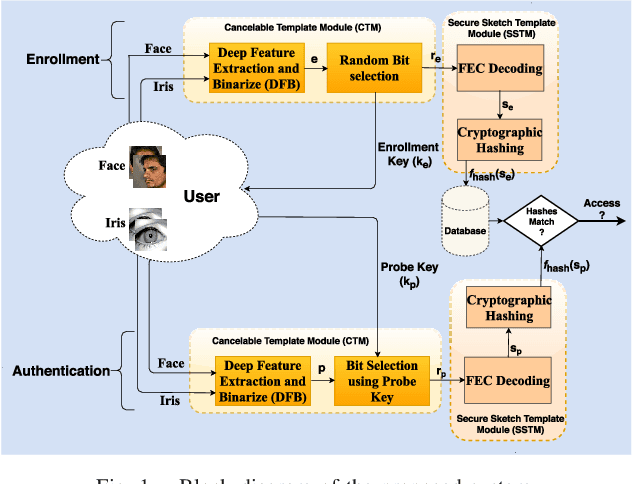
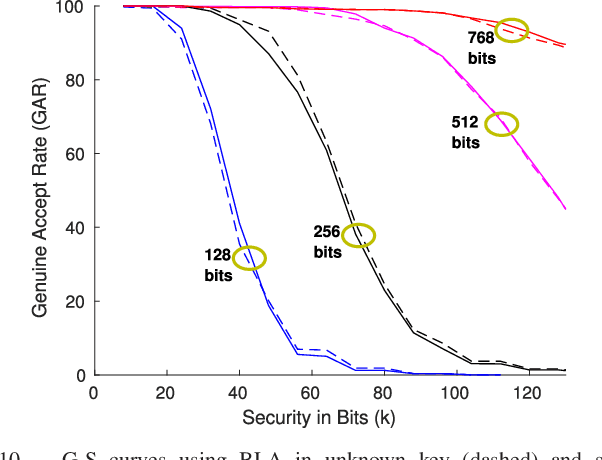
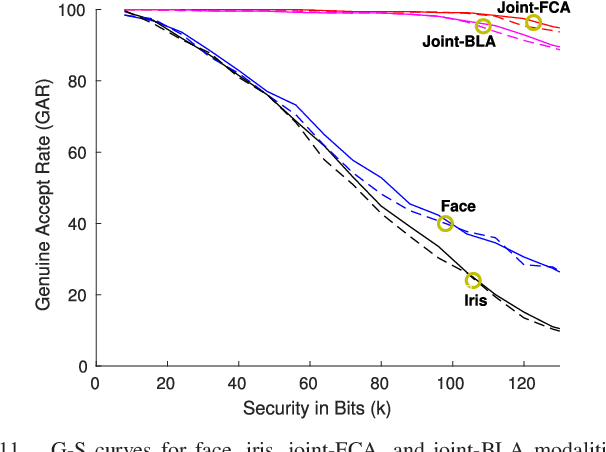
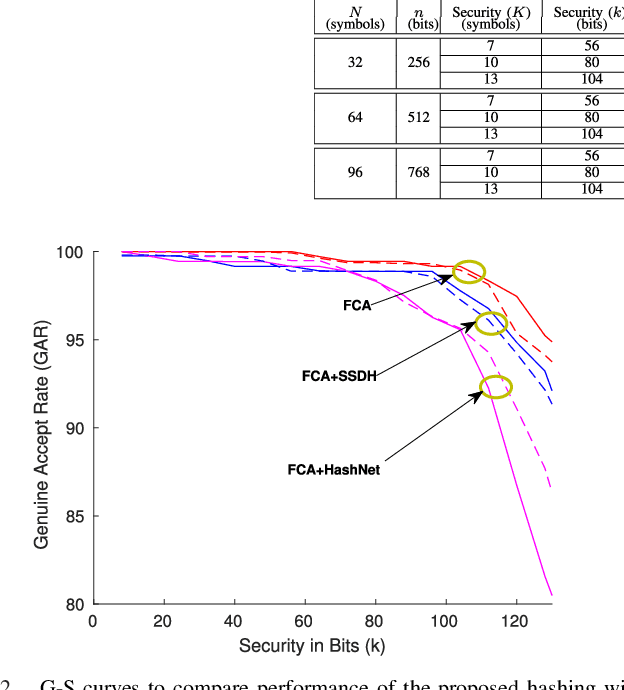
When compared to unimodal systems, multimodal biometric systems have several advantages, including lower error rate, higher accuracy, and larger population coverage. However, multimodal systems have an increased demand for integrity and privacy because they must store multiple biometric traits associated with each user. In this paper, we present a deep learning framework for feature-level fusion that generates a secure multimodal template from each user's face and iris biometrics. We integrate a deep hashing (binarization) technique into the fusion architecture to generate a robust binary multimodal shared latent representation. Further, we employ a hybrid secure architecture by combining cancelable biometrics with secure sketch techniques and integrate it with a deep hashing framework, which makes it computationally prohibitive to forge a combination of multiple biometrics that pass the authentication. The efficacy of the proposed approach is shown using a multimodal database of face and iris and it is observed that the matching performance is improved due to the fusion of multiple biometrics. Furthermore, the proposed approach also provides cancelability and unlinkability of the templates along with improved privacy of the biometric data. Additionally, we also test the proposed hashing function for an image retrieval application using a benchmark dataset. The main goal of this paper is to develop a method for integrating multimodal fusion, deep hashing, and biometric security, with an emphasis on structural data from modalities like face and iris. The proposed approach is in no way a general biometric security framework that can be applied to all biometric modalities, as further research is needed to extend the proposed framework to other unconstrained biometric modalities.
Multi-Modal Active Learning for Automatic Liver Fibrosis Diagnosis based on Ultrasound Shear Wave Elastography
Nov 02, 2020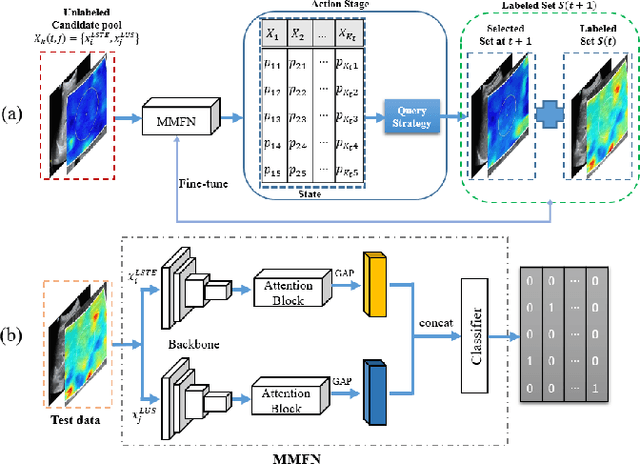
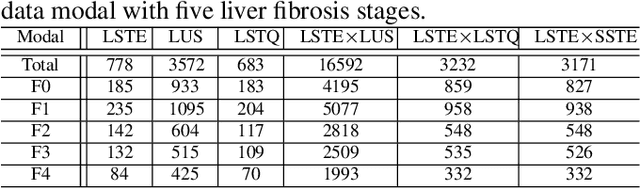
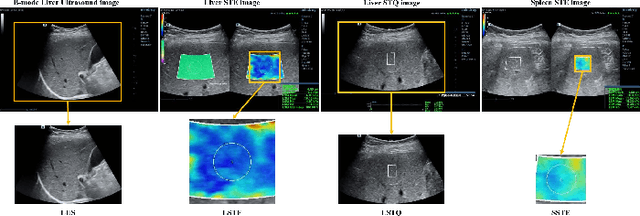
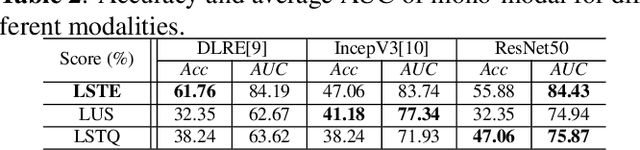
With the development of radiomics, noninvasive diagnosis like ultrasound (US) imaging plays a very important role in automatic liver fibrosis diagnosis (ALFD). Due to the noisy data, expensive annotations of US images, the application of Artificial Intelligence (AI) assisting approaches encounters a bottleneck. Besides, the use of mono-modal US data limits the further improve of the classification results. In this work, we innovatively propose a multi-modal fusion network with active learning (MMFN-AL) for ALFD to exploit the information of multiple modalities, eliminate the noisy data and reduce the annotation cost. Four image modalities including US and three types of shear wave elastography (SWEs) are exploited. A new dataset containing these modalities from 214 candidates is well-collected and pre-processed, with the labels obtained from the liver biopsy results. Experimental results show that our proposed method outperforms the state-of-the-art performance using less than 30% data, and by using only around 80% data, the proposed fusion network achieves high AUC 89.27% and accuracy 70.59%.
Reinterpreting the Transformation Posterior in Probabilistic Image Registration
Apr 07, 2016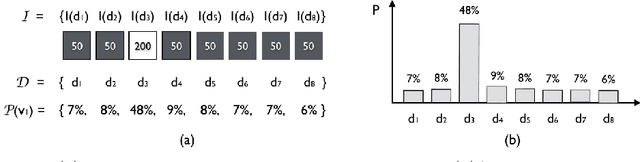
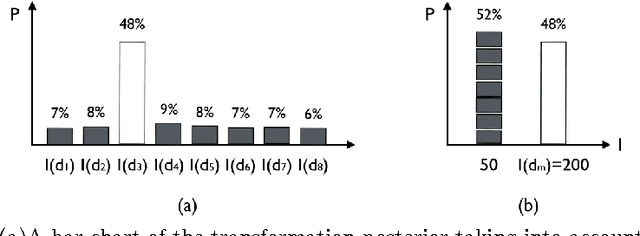
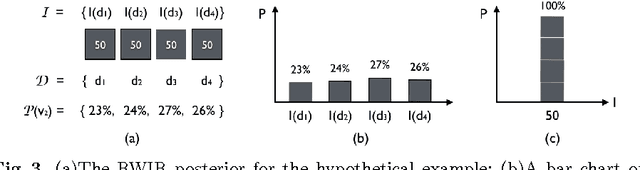
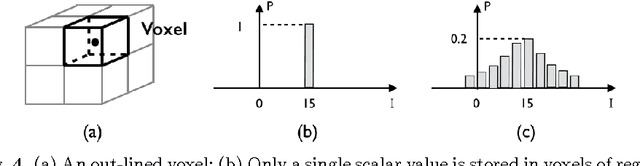
Probabilistic image registration methods estimate the posterior distribution of transformation. The conventional way of interpreting the transformation posterior is to use the mode as the most likely transformation and assign its corresponding intensity to the registered voxel. Meanwhile, summary statistics of the posterior are employed to evaluate the registration uncertainty, that is the trustworthiness of the registered image. Despite the wide acceptance, this convention has never been justified. In this paper, based on illustrative examples, we question the correctness and usefulness of conventional methods. In order to faithfully translate the transformation posterior, we propose to encode the variability of values into a novel data type called ensemble fields. Ensemble fields can serve as a complement to the registered image and a foundation for developing advanced methods to characterize the uncertainty in registration-based tasks. We demonstrate the potential of ensemble fields by pilot examples
"Name that manufacturer". Relating image acquisition bias with task complexity when training deep learning models: experiments on head CT
Aug 19, 2020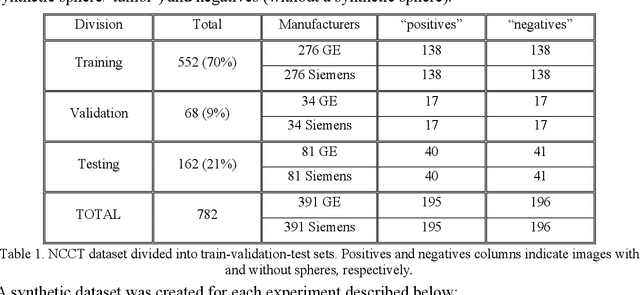
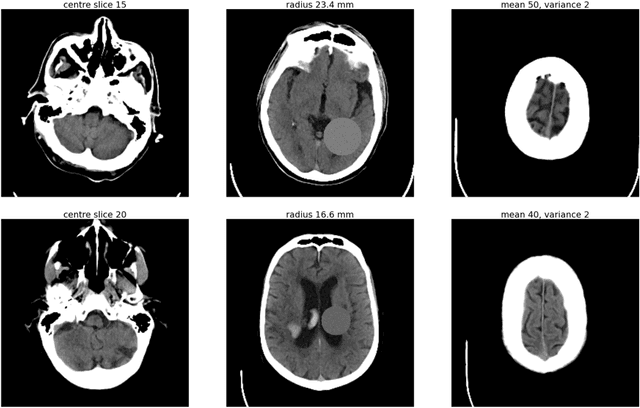
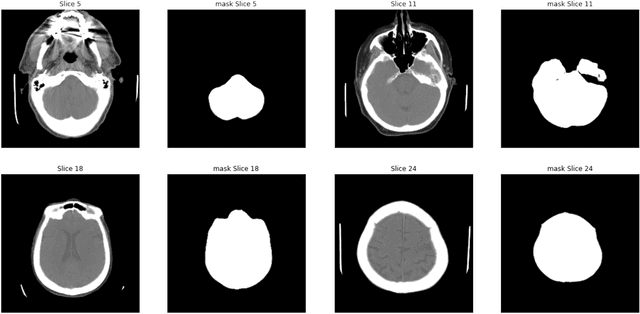

As interest in applying machine learning techniques for medical images continues to grow at a rapid pace, models are starting to be developed and deployed for clinical applications. In the clinical AI model development lifecycle (described by Lu et al. [1]), a crucial phase for machine learning scientists and clinicians is the proper design and collection of the data cohort. The ability to recognize various forms of biases and distribution shifts in the dataset is critical at this step. While it remains difficult to account for all potential sources of bias, techniques can be developed to identify specific types of bias in order to mitigate their impact. In this work we analyze how the distribution of scanner manufacturers in a dataset can contribute to the overall bias of deep learning models. We evaluate convolutional neural networks (CNN) for both classification and segmentation tasks, specifically two state-of-the-art models: ResNet [2] for classification and U-Net [3] for segmentation. We demonstrate that CNNs can learn to distinguish the imaging scanner manufacturer and that this bias can substantially impact model performance for both classification and segmentation tasks. By creating an original synthesis dataset of brain data mimicking the presence of more or less subtle lesions we also show that this bias is related to the difficulty of the task. Recognition of such bias is critical to develop robust, generalizable models that will be crucial for clinical applications in real-world data distributions.
GeoNet++: Iterative Geometric Neural Network with Edge-Aware Refinement for Joint Depth and Surface Normal Estimation
Dec 13, 2020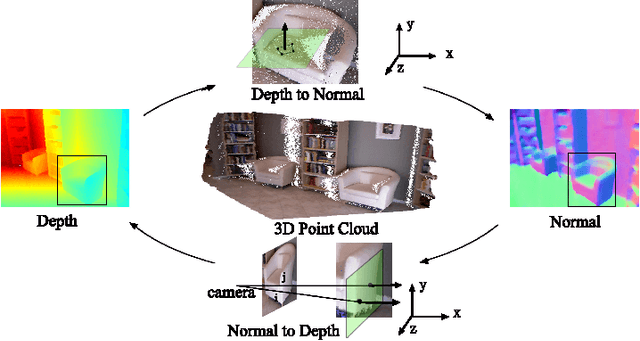
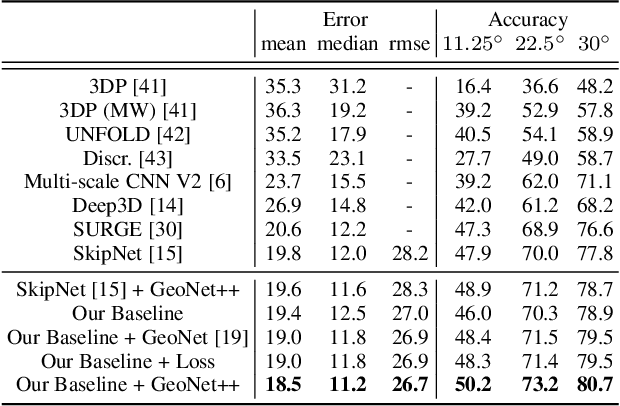
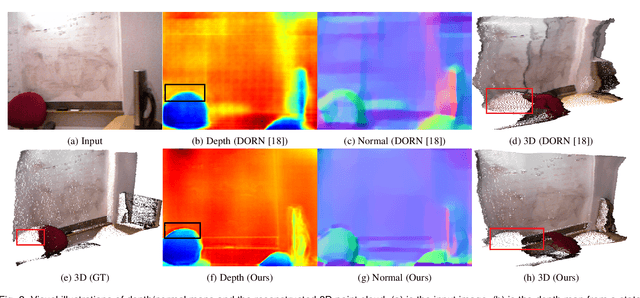
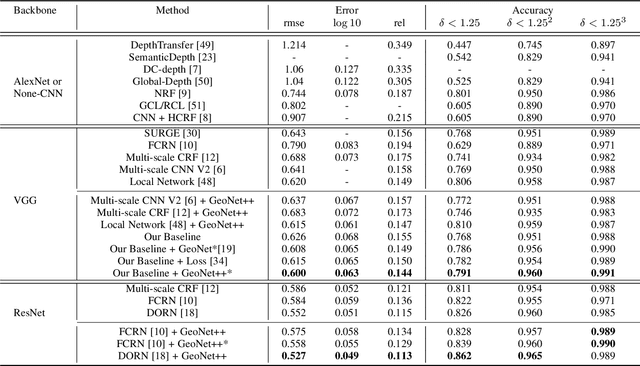
In this paper, we propose a geometric neural network with edge-aware refinement (GeoNet++) to jointly predict both depth and surface normal maps from a single image. Building on top of two-stream CNNs, GeoNet++ captures the geometric relationships between depth and surface normals with the proposed depth-to-normal and normal-to-depth modules. In particular, the "depth-to-normal" module exploits the least square solution of estimating surface normals from depth to improve their quality, while the "normal-to-depth" module refines the depth map based on the constraints on surface normals through kernel regression. Boundary information is exploited via an edge-aware refinement module. GeoNet++ effectively predicts depth and surface normals with strong 3D consistency and sharp boundaries resulting in better reconstructed 3D scenes. Note that GeoNet++ is generic and can be used in other depth/normal prediction frameworks to improve the quality of 3D reconstruction and pixel-wise accuracy of depth and surface normals. Furthermore, we propose a new 3D geometric metric (3DGM) for evaluating depth prediction in 3D. In contrast to current metrics that focus on evaluating pixel-wise error/accuracy, 3DGM measures whether the predicted depth can reconstruct high-quality 3D surface normals. This is a more natural metric for many 3D application domains. Our experiments on NYUD-V2 and KITTI datasets verify that GeoNet++ produces fine boundary details, and the predicted depth can be used to reconstruct high-quality 3D surfaces. Code has been made publicly available.
DehazeNet: An End-to-End System for Single Image Haze Removal
May 17, 2016Single image haze removal is a challenging ill-posed problem. Existing methods use various constraints/priors to get plausible dehazing solutions. The key to achieve haze removal is to estimate a medium transmission map for an input hazy image. In this paper, we propose a trainable end-to-end system called DehazeNet, for medium transmission estimation. DehazeNet takes a hazy image as input, and outputs its medium transmission map that is subsequently used to recover a haze-free image via atmospheric scattering model. DehazeNet adopts Convolutional Neural Networks (CNN) based deep architecture, whose layers are specially designed to embody the established assumptions/priors in image dehazing. Specifically, layers of Maxout units are used for feature extraction, which can generate almost all haze-relevant features. We also propose a novel nonlinear activation function in DehazeNet, called Bilateral Rectified Linear Unit (BReLU), which is able to improve the quality of recovered haze-free image. We establish connections between components of the proposed DehazeNet and those used in existing methods. Experiments on benchmark images show that DehazeNet achieves superior performance over existing methods, yet keeps efficient and easy to use.