 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Generative Zero-Shot Learning: An Ensemble Learning Perspective for Recognising Visual Patches
Aug 07, 2020
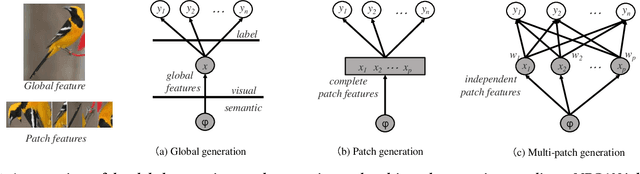
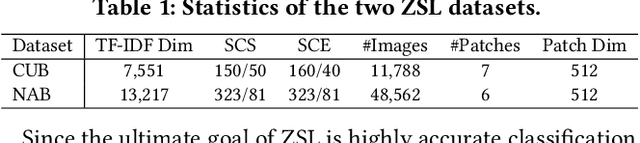
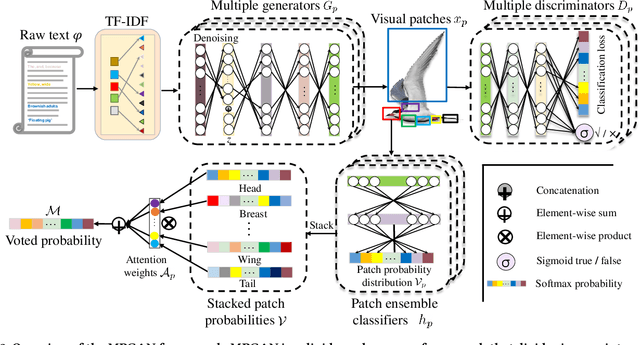
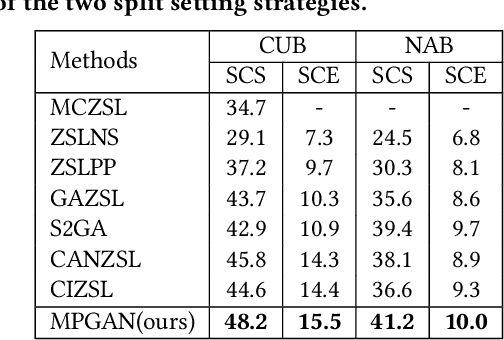
Zero-shot learning (ZSL) is commonly used to address the very pervasive problem of predicting unseen classes in fine-grained image classification and other tasks. One family of solutions is to learn synthesised unseen visual samples produced by generative models from auxiliary semantic information, such as natural language descriptions. However, for most of these models, performance suffers from noise in the form of irrelevant image backgrounds. Further, most methods do not allocate a calculated weight to each semantic patch. Yet, in the real world, the discriminative power of features can be quantified and directly leveraged to improve accuracy and reduce computational complexity. To address these issues, we propose a novel framework called multi-patch generative adversarial nets (MPGAN) that synthesises local patch features and labels unseen classes with a novel weighted voting strategy. The process begins by generating discriminative visual features from noisy text descriptions for a set of predefined local patches using multiple specialist generative models. The features synthesised from each patch for unseen classes are then used to construct an ensemble of diverse supervised classifiers, each corresponding to one local patch. A voting strategy averages the probability distributions output from the classifiers and, given that some patches are more discriminative than others, a discrimination-based attention mechanism helps to weight each patch accordingly. Extensive experiments show that MPGAN has significantly greater accuracy than state-of-the-art methods.
Learning to Deblur and Generate High Frame Rate Video with an Event Camera
Mar 20, 2020
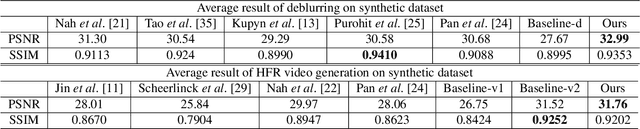
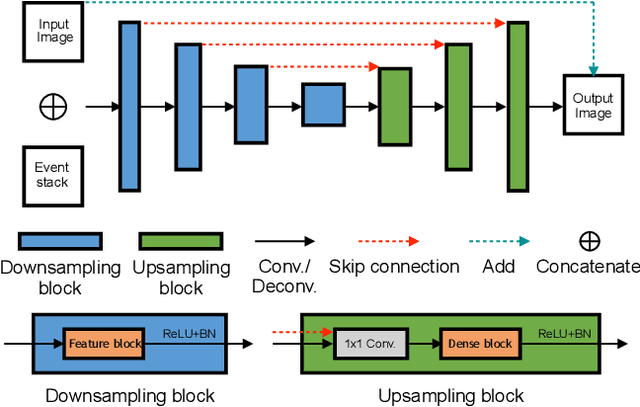
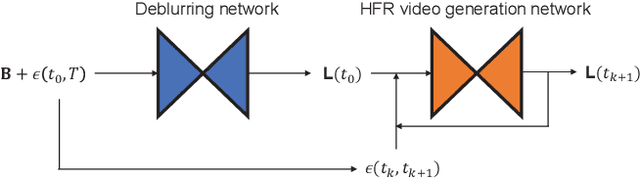
Event cameras are bio-inspired cameras which can measure the change of intensity asynchronously with high temporal resolution. One of the event cameras' advantages is that they do not suffer from motion blur when recording high-speed scenes. In this paper, we formulate the deblurring task on traditional cameras directed by events to be a residual learning one, and we propose corresponding network architectures for effective learning of deblurring and high frame rate video generation tasks. We first train a modified U-Net network to restore a sharp image from a blurry image using corresponding events. Then we train another similar network with different downsampling blocks to generate high frame rate video using the restored sharp image and events. Experiment results show that our method can restore sharper images and videos than state-of-the-art methods.
Image Retargeting by Content-Aware Synthesis
Aug 21, 2014

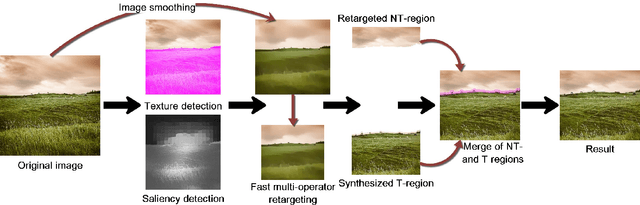

Real-world images usually contain vivid contents and rich textural details, which will complicate the manipulation on them. In this paper, we design a new framework based on content-aware synthesis to enhance content-aware image retargeting. By detecting the textural regions in an image, the textural image content can be synthesized rather than simply distorted or cropped. This method enables the manipulation of textural & non-textural regions with different strategy since they have different natures. We propose to retarget the textural regions by content-aware synthesis and non-textural regions by fast multi-operators. To achieve practical retargeting applications for general images, we develop an automatic and fast texture detection method that can detect multiple disjoint textural regions. We adjust the saliency of the image according to the features of the textural regions. To validate the proposed method, comparisons with state-of-the-art image targeting techniques and a user study were conducted. Convincing visual results are shown to demonstrate the effectiveness of the proposed method.
Efficient Colon Cancer Grading with Graph Neural Networks
Oct 02, 2020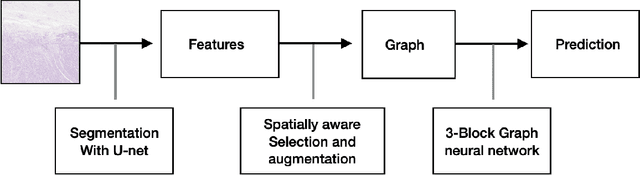
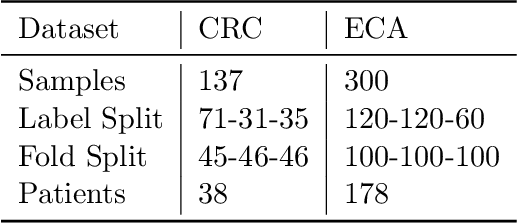
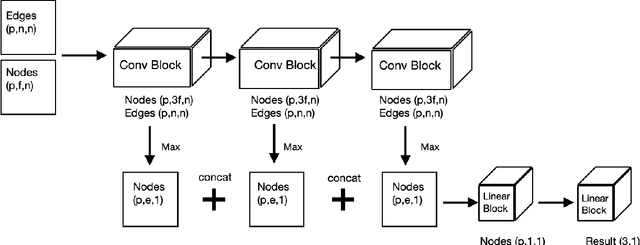
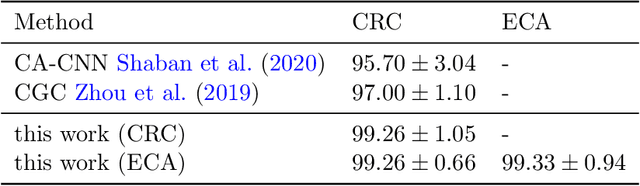
Dealing with the application of grading colorectal cancer images, this work proposes a 3 step pipeline for prediction of cancer levels from a histopathology image. The overall model performs better compared to other state of the art methods on the colorectal cancer grading data set and shows excellent performance for the extended colorectal cancer grading set. The performance improvements can be attributed to two main factors: The feature selection and graph augmentation method described here are spatially aware, but overall pixel position independent. Further, the graph size in terms of nodes becomes stable with respect to the model's prediction and accuracy for sufficiently large models. The graph neural network itself consists of three convolutional blocks and linear layers, which is a rather simple design compared to other networks for this application.
Non-Local Color Image Denoising with Convolutional Neural Networks
Jul 10, 2017


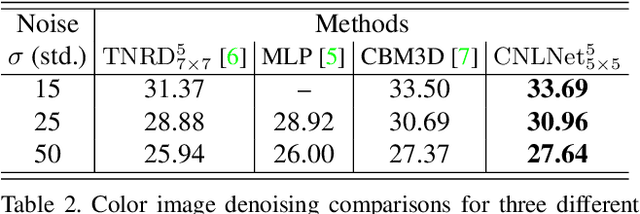
We propose a novel deep network architecture for grayscale and color image denoising that is based on a non-local image model. Our motivation for the overall design of the proposed network stems from variational methods that exploit the inherent non-local self-similarity property of natural images. We build on this concept and introduce deep networks that perform non-local processing and at the same time they significantly benefit from discriminative learning. Experiments on the Berkeley segmentation dataset, comparing several state-of-the-art methods, show that the proposed non-local models achieve the best reported denoising performance both for grayscale and color images for all the tested noise levels. It is also worth noting that this increase in performance comes at no extra cost on the capacity of the network compared to existing alternative deep network architectures. In addition, we highlight a direct link of the proposed non-local models to convolutional neural networks. This connection is of significant importance since it allows our models to take full advantage of the latest advances on GPU computing in deep learning and makes them amenable to efficient implementations through their inherent parallelism.
Pairwise Decomposition of Image Sequences for Active Multi-View Recognition
May 26, 2016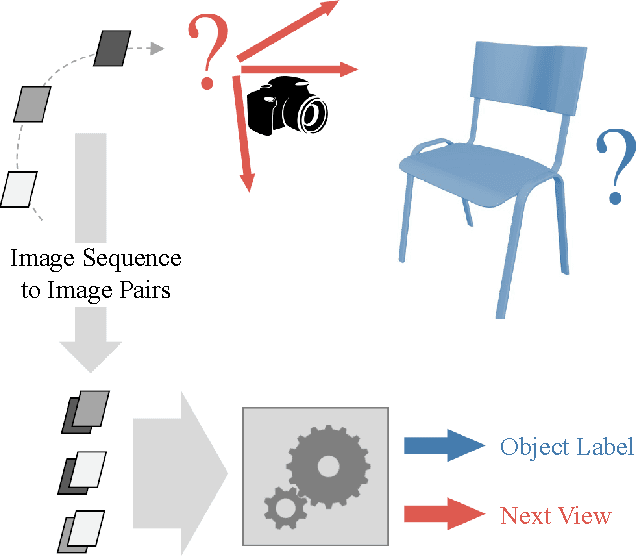
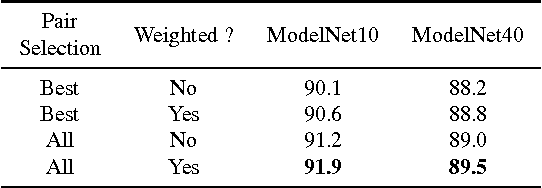
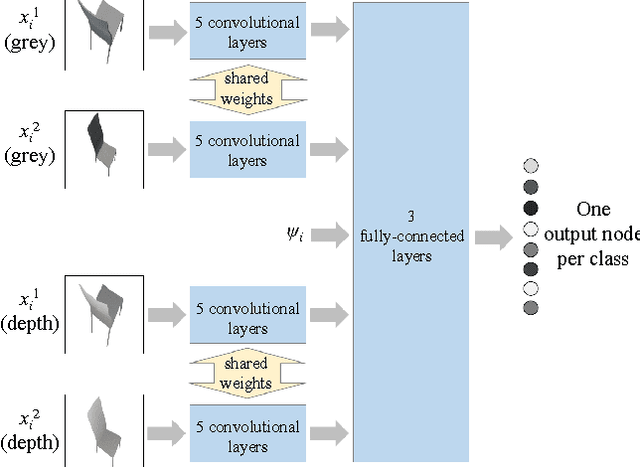
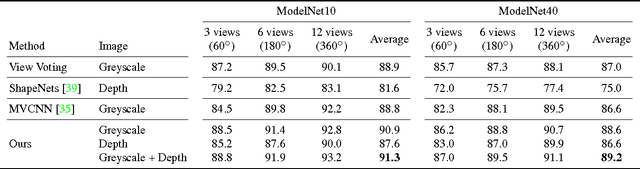
A multi-view image sequence provides a much richer capacity for object recognition than from a single image. However, most existing solutions to multi-view recognition typically adopt hand-crafted, model-based geometric methods, which do not readily embrace recent trends in deep learning. We propose to bring Convolutional Neural Networks to generic multi-view recognition, by decomposing an image sequence into a set of image pairs, classifying each pair independently, and then learning an object classifier by weighting the contribution of each pair. This allows for recognition over arbitrary camera trajectories, without requiring explicit training over the potentially infinite number of camera paths and lengths. Building these pairwise relationships then naturally extends to the next-best-view problem in an active recognition framework. To achieve this, we train a second Convolutional Neural Network to map directly from an observed image to next viewpoint. Finally, we incorporate this into a trajectory optimisation task, whereby the best recognition confidence is sought for a given trajectory length. We present state-of-the-art results in both guided and unguided multi-view recognition on the ModelNet dataset, and show how our method can be used with depth images, greyscale images, or both.
Evolution of active categorical image classification via saccadic eye movement
Jun 16, 2016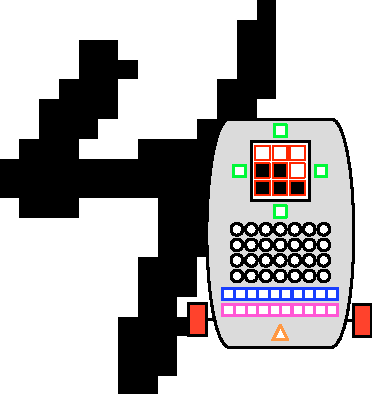
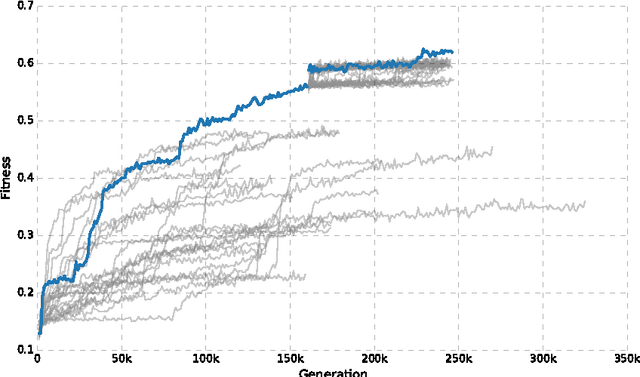
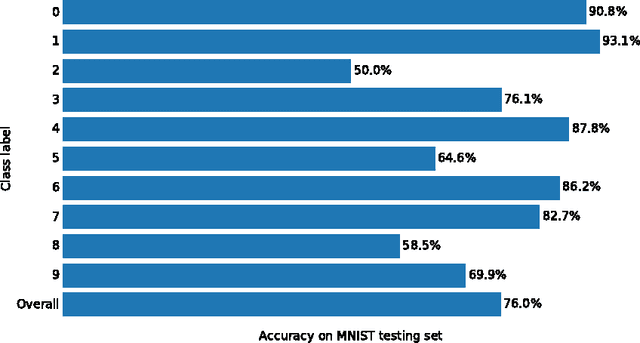
Pattern recognition and classification is a central concern for modern information processing systems. In particular, one key challenge to image and video classification has been that the computational cost of image processing scales linearly with the number of pixels in the image or video. Here we present an intelligent machine (the "active categorical classifier," or ACC) that is inspired by the saccadic movements of the eye, and is capable of classifying images by selectively scanning only a portion of the image. We harness evolutionary computation to optimize the ACC on the MNIST hand-written digit classification task, and provide a proof-of-concept that the ACC works on noisy multi-class data. We further analyze the ACC and demonstrate its ability to classify images after viewing only a fraction of the pixels, and provide insight on future research paths to further improve upon the ACC presented here.
* 10 pages, 5 figures, to appear in PPSN 2016 conference proceedings
Real-Time Edge Classification: Optimal Offloading under Token Bucket Constraints
Nov 05, 2020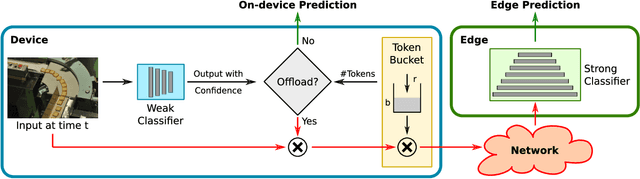
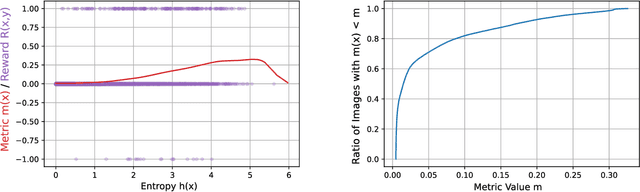
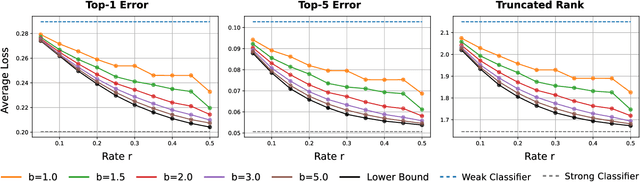
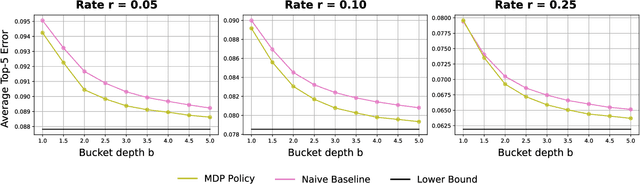
To deploy machine learning-based algorithms for real-time applications with strict latency constraints, we consider an edge-computing setting where a subset of inputs are offloaded to the edge for processing by an accurate but resource-intensive model, and the rest are processed only by a less-accurate model on the device itself. Both models have computational costs that match available compute resources, and process inputs with low-latency. But offloading incurs network delays, and to manage these delays to meet application deadlines, we use a token bucket to constrain the average rate and burst length of transmissions from the device. We introduce a Markov Decision Process-based framework to make offload decisions under these constraints, based on the local model's confidence and the token bucket state, with the goal of minimizing a specified error measure for the application. Beyond isolated decisions for individual devices, we also propose approaches to allow multiple devices connected to the same access switch to share their bursting allocation. We evaluate and analyze the policies derived using our framework on the standard ImageNet image classification benchmark.
A Simple Cache Model for Image Recognition
May 21, 2018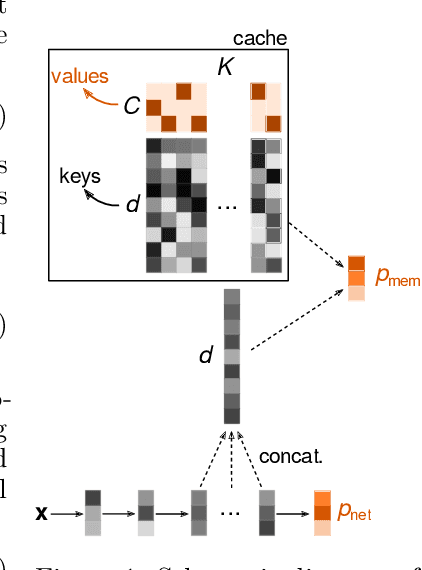
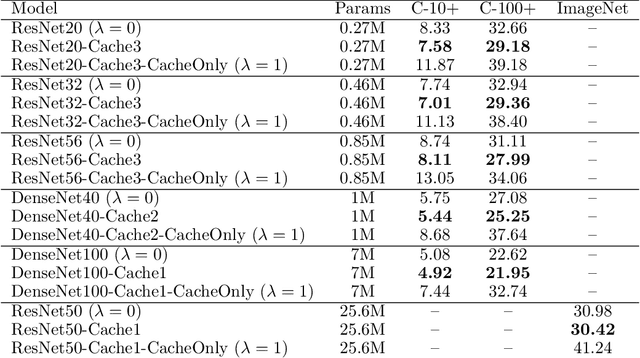
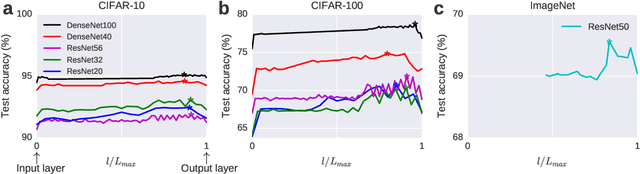

Training large-scale image recognition models is computationally expensive. This raises the question of whether there might be simple ways to improve the test performance of an already trained model without having to re-train or even fine-tune it with new data. Here, we show that, surprisingly, this is indeed possible. The key observation we make is that the layers of a deep network close to the output layer contain independent, easily extractable class-relevant information that is not contained in the output layer itself. We propose to extract this extra class-relevant information using a simple key-value cache memory to improve the classification performance of the model at test time. Our cache memory is directly inspired by a similar cache model previously proposed for language modeling (Grave et al., 2017). This cache component does not require any training or fine-tuning; it can be applied to any pre-trained model and, by properly setting only two hyper-parameters, leads to significant improvements in its classification performance. Improvements are observed across several architectures and datasets. In the cache component, using features extracted from layers close to the output (but not from the output layer itself) as keys leads to the largest improvements. Concatenating features from multiple layers to form keys can further improve performance over using single-layer features as keys. The cache component also has a regularizing effect, a simple consequence of which is that it substantially increases the robustness of models against adversarial attacks.
MSL-RAPTOR: A 6DoF Relative Pose Tracker for Onboard Robotic Perception
Dec 16, 2020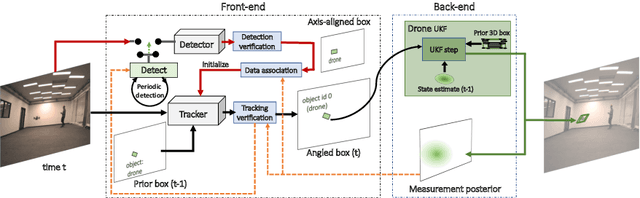
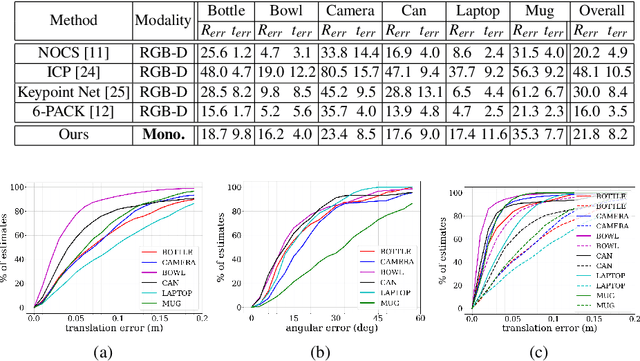
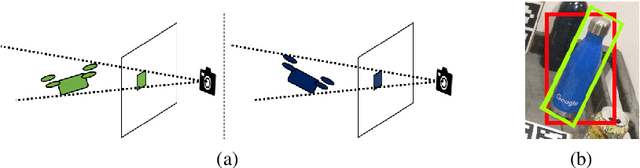

Determining the relative position and orientation of objects in an environment is a fundamental building block for a wide range of robotics applications. To accomplish this task efficiently in practical settings, a method must be fast, use common sensors, and generalize easily to new objects and environments. We present MSL-RAPTOR, a two-stage algorithm for tracking a rigid body with a monocular camera. The image is first processed by an efficient neural network-based front-end to detect new objects and track 2D bounding boxes between frames. The class label and bounding box is passed to the back-end that updates the object's pose using an unscented Kalman filter (UKF). The measurement posterior is fed back to the 2D tracker to improve robustness. The object's class is identified so a class-specific UKF can be used if custom dynamics and constraints are known. Adapting to track the pose of new classes only requires providing a trained 2D object detector or labeled 2D bounding box data, as well as the approximate size of the objects. The performance of MSL-RAPTOR is first verified on the NOCS-REAL275 dataset, achieving results comparable to RGB-D approaches despite not using depth measurements. When tracking a flying drone from onboard another drone, it outperforms the fastest comparable method in speed by a factor of 3, while giving lower translation and rotation median errors by 66% and 23% respectively.