 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TAnoGAN: Time Series Anomaly Detection with Generative Adversarial Networks
Aug 21, 2020
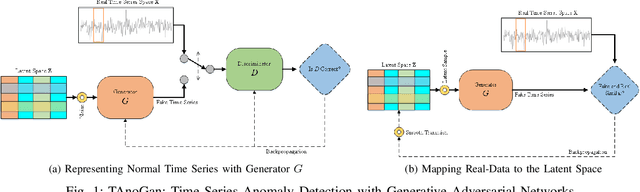
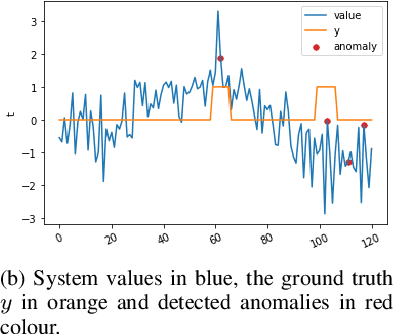
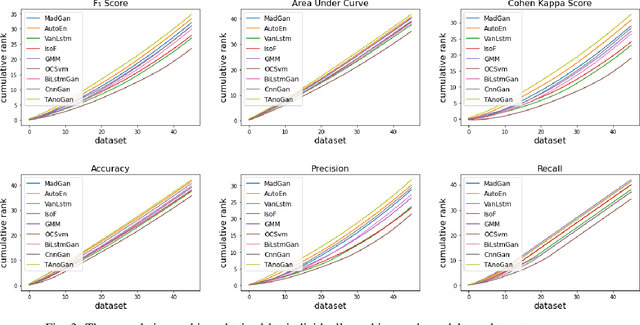
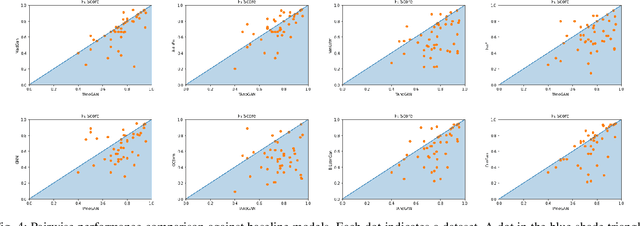
Anomaly detection in time series data is a significant problem faced in many application areas. Recently, Generative Adversarial Networks (GAN) have gained attention for generation and anomaly detection in image domain. In this paper, we propose a novel GAN-based unsupervised method called TAnoGan for detecting anomalies in time series when a small number of data points are available. We evaluate TAnoGan with 46 real-world time series datasets that cover a variety of domains. Extensive experimental results show that TAnoGan performs better than traditional and neural network models.
Fracking Deep Convolutional Image Descriptors
Feb 25, 2015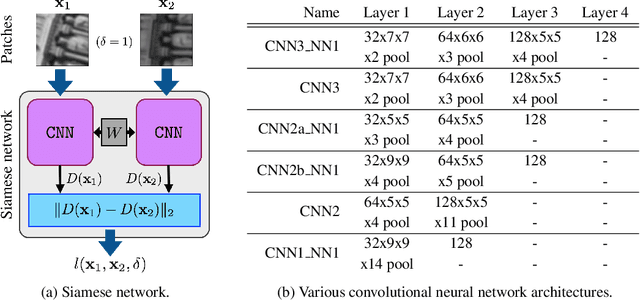
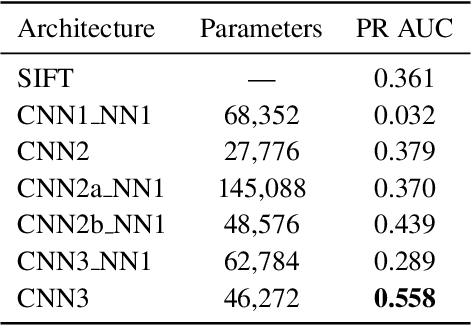

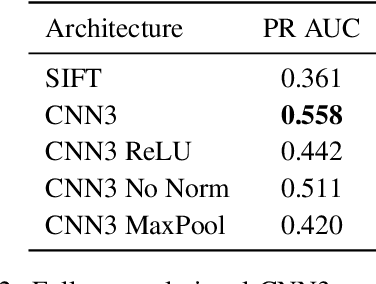
In this paper we propose a novel framework for learning local image descriptors in a discriminative manner. For this purpose we explore a siamese architecture of Deep Convolutional Neural Networks (CNN), with a Hinge embedding loss on the L2 distance between descriptors. Since a siamese architecture uses pairs rather than single image patches to train, there exist a large number of positive samples and an exponential number of negative samples. We propose to explore this space with a stochastic sampling of the training set, in combination with an aggressive mining strategy over both the positive and negative samples which we denote as "fracking". We perform a thorough evaluation of the architecture hyper-parameters, and demonstrate large performance gains compared to both standard CNN learning strategies, hand-crafted image descriptors like SIFT, and the state-of-the-art on learned descriptors: up to 2.5x vs SIFT and 1.5x vs the state-of-the-art in terms of the area under the curve (AUC) of the Precision-Recall curve.
Move to See Better: Towards Self-Supervised Amodal Object Detection
Nov 30, 2020
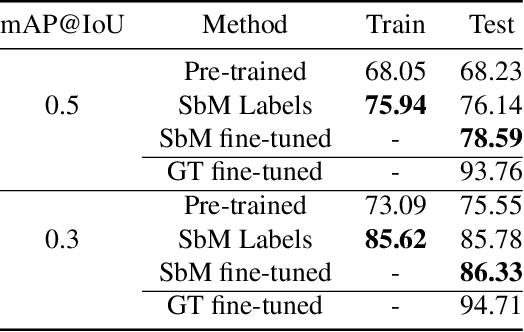
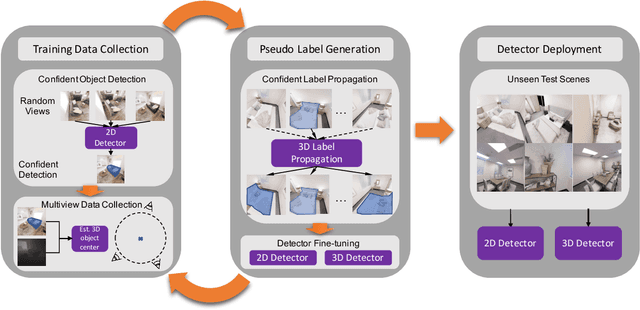
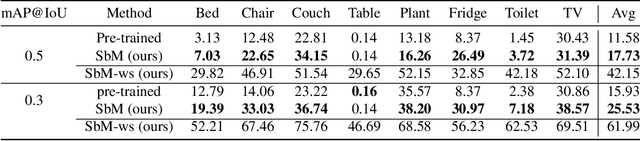
Humans learn to better understand the world by moving around their environment to get more informative viewpoints of the scene. Most methods for 2D visual recognition tasks such as object detection and segmentation treat images of the same scene as individual samples and do not exploit object permanence in multiple views. Generalization to novel scenes and views thus requires additional training with lots of human annotations. In this paper, we propose a self-supervised framework to improve an object detector in unseen scenarios by moving an agent around in a 3D environment and aggregating multi-view RGB-D information. We unproject confident 2D object detections from the pre-trained detector and perform unsupervised 3D segmentation on the point cloud. The segmented 3D objects are then re-projected to all other views to obtain pseudo-labels for fine-tuning. Experiments on both indoor and outdoor datasets show that (1) our framework performs high-quality 3D segmentation from raw RGB-D data and a pre-trained 2D detector; (2) fine-tuning with self-supervision improves the 2D detector significantly where an unseen RGB image is given as input at test time; (3) training a 3D detector with self-supervision outperforms a comparable self-supervised method by a large margin.
Solving Phase Retrieval with a Learned Reference
Jul 29, 2020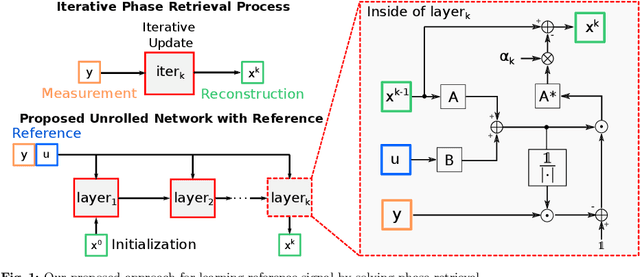

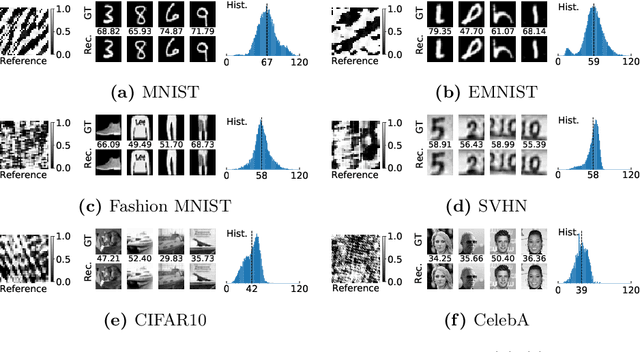
Fourier phase retrieval is a classical problem that deals with the recovery of an image from the amplitude measurements of its Fourier coefficients. Conventional methods solve this problem via iterative (alternating) minimization by leveraging some prior knowledge about the structure of the unknown image. The inherent ambiguities about shift and flip in the Fourier measurements make this problem especially difficult; and most of the existing methods use several random restarts with different permutations. In this paper, we assume that a known (learned) reference is added to the signal before capturing the Fourier amplitude measurements. Our method is inspired by the principle of adding a reference signal in holography. To recover the signal, we implement an iterative phase retrieval method as an unrolled network. Then we use back propagation to learn the reference that provides us the best reconstruction for a fixed number of phase retrieval iterations. We performed a number of simulations on a variety of datasets under different conditions and found that our proposed method for phase retrieval via unrolled network and learned reference provides near-perfect recovery at fixed (small) computational cost. We compared our method with standard Fourier phase retrieval methods and observed significant performance enhancement using the learned reference.
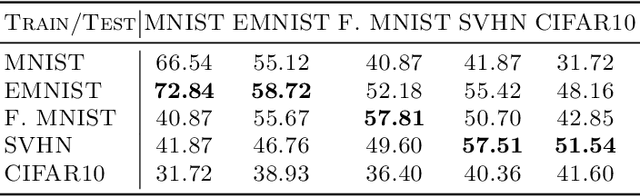
Improving Pairwise Ranking for Multi-label Image Classification
Jun 01, 2017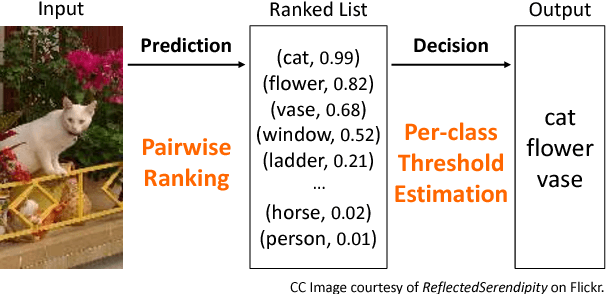
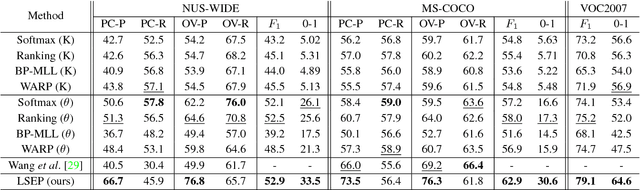

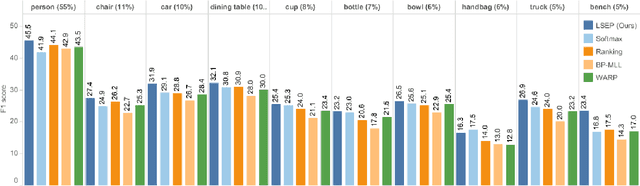
Learning to rank has recently emerged as an attractive technique to train deep convolutional neural networks for various computer vision tasks. Pairwise ranking, in particular, has been successful in multi-label image classification, achieving state-of-the-art results on various benchmarks. However, most existing approaches use the hinge loss to train their models, which is non-smooth and thus is difficult to optimize especially with deep networks. Furthermore, they employ simple heuristics, such as top-k or thresholding, to determine which labels to include in the output from a ranked list of labels, which limits their use in the real-world setting. In this work, we propose two techniques to improve pairwise ranking based multi-label image classification: (1) we propose a novel loss function for pairwise ranking, which is smooth everywhere and thus is easier to optimize; and (2) we incorporate a label decision module into the model, estimating the optimal confidence thresholds for each visual concept. We provide theoretical analyses of our loss function in the Bayes consistency and risk minimization framework, and show its benefit over existing pairwise ranking formulations. We demonstrate the effectiveness of our approach on three large-scale datasets, VOC2007, NUS-WIDE and MS-COCO, achieving the best reported results in the literature.
Adaptive Linear Span Network for Object Skeleton Detection
Nov 08, 2020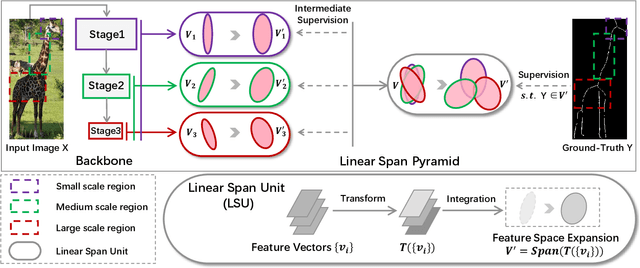
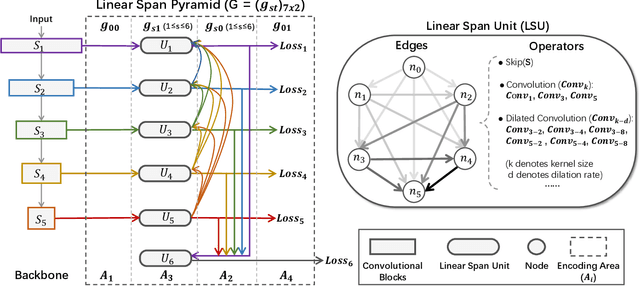
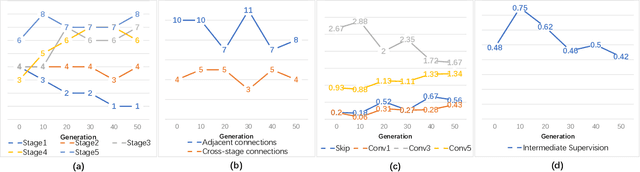

Conventional networks for object skeleton detection are usually hand-crafted. Although effective, they require intensive priori knowledge to configure representative features for objects in different scale granularity.In this paper, we propose adaptive linear span network (AdaLSN), driven by neural architecture search (NAS), to automatically configure and integrate scale-aware features for object skeleton detection. AdaLSN is formulated with the theory of linear span, which provides one of the earliest explanations for multi-scale deep feature fusion. AdaLSN is materialized by defining a mixed unit-pyramid search space, which goes beyond many existing search spaces using unit-level or pyramid-level features.Within the mixed space, we apply genetic architecture search to jointly optimize unit-level operations and pyramid-level connections for adaptive feature space expansion. AdaLSN substantiates its versatility by achieving significantly higher accuracy and latency trade-off compared with state-of-the-arts. It also demonstrates general applicability to image-to-mask tasks such as edge detection and road extraction. Code is available at \href{https://github.com/sunsmarterjie/SDL-Skeleton}{\color{magenta}github.com/sunsmarterjie/SDL-Skeleton}.
Debiased-CAM for bias-agnostic faithful visual explanations of deep convolutional networks
Dec 10, 2020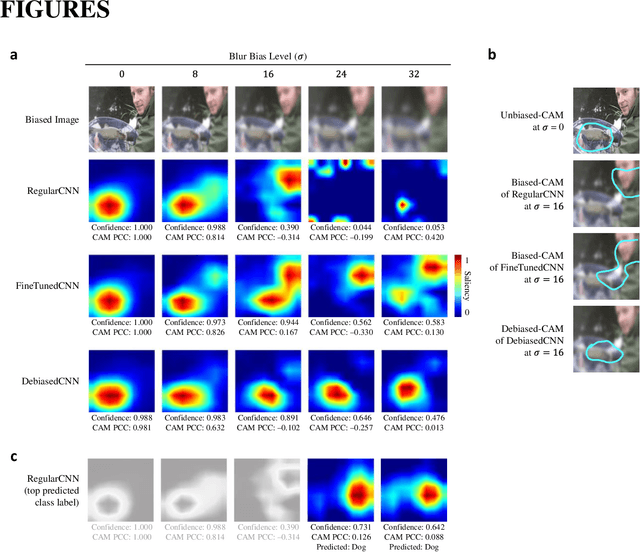
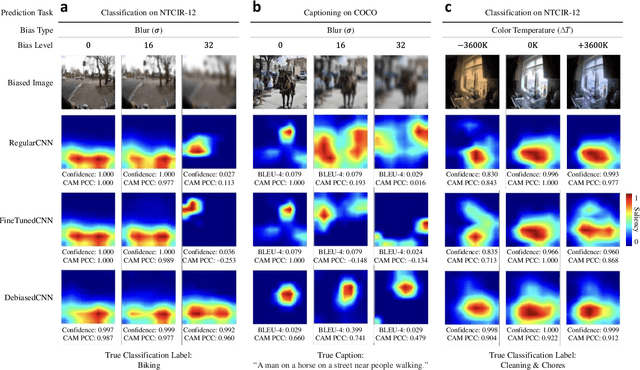
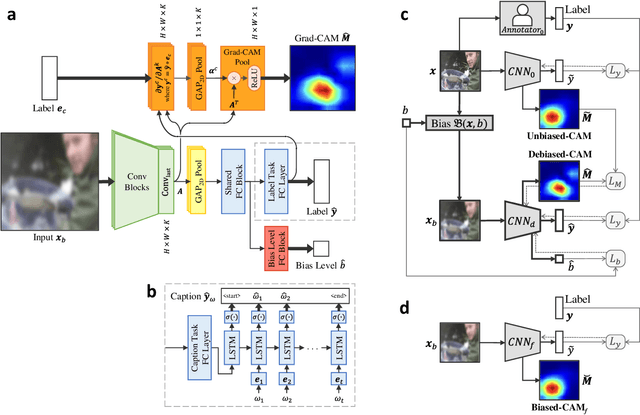
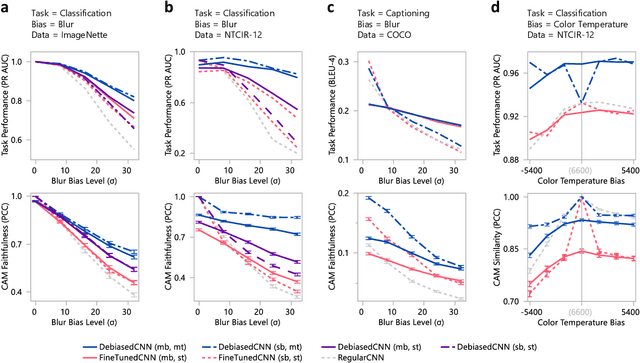
Class activation maps (CAMs) explain convolutional neural network predictions by identifying salient pixels, but they become misaligned and misleading when explaining predictions on images under bias, such as images blurred accidentally or deliberately for privacy protection, or images with improper white balance. Despite model fine-tuning to improve prediction performance on these biased images, we demonstrate that CAM explanations become more deviated and unfaithful with increased image bias. We present Debiased-CAM to recover explanation faithfulness across various bias types and levels by training a multi-input, multi-task model with auxiliary tasks for CAM and bias level predictions. With CAM as a prediction task, explanations are made tunable by retraining the main model layers and made faithful by self-supervised learning from CAMs of unbiased images. The model provides representative, bias-agnostic CAM explanations about the predictions on biased images as if generated from their unbiased form. In four simulation studies with different biases and prediction tasks, Debiased-CAM improved both CAM faithfulness and task performance. We further conducted two controlled user studies to validate its truthfulness and helpfulness, respectively. Quantitative and qualitative analyses of participant responses confirmed Debiased-CAM as more truthful and helpful. Debiased-CAM thus provides a basis to generate more faithful and relevant explanations for a wide range of real-world applications with various sources of bias.
KPRNet: Improving projection-based LiDAR semantic segmentation
Aug 21, 2020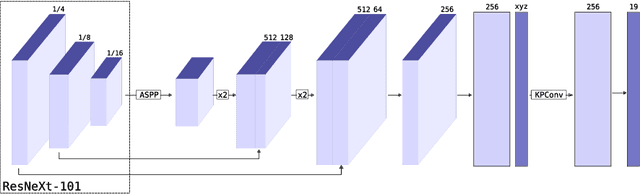
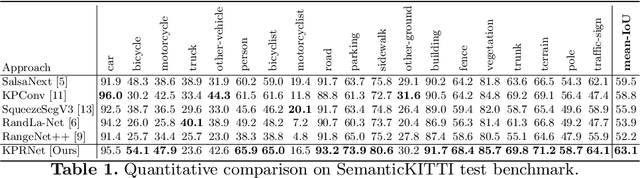
Semantic segmentation is an important component in the perception systems of autonomous vehicles. In this work, we adopt recent advances in both image and point cloud segmentation to achieve a better accuracy in the task of segmenting LiDAR scans. KPRNet improves the convolutional neural network architecture of 2D projection methods and utilizes KPConv to replace the commonly used post-processing techniques with a learnable point-wise component which allows us to obtain more accurate 3D labels. With these improvements our model outperforms the current best method on the SemanticKITTI benchmark, reaching an mIoU of 63.1.
ViDi: Descriptive Visual Data Clustering as Radiologist Assistant in COVID-19 Streamline Diagnostic
Nov 30, 2020
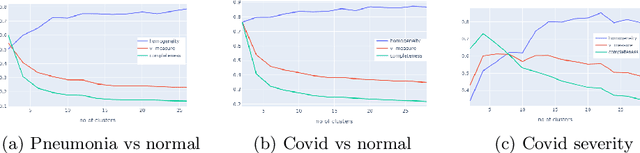

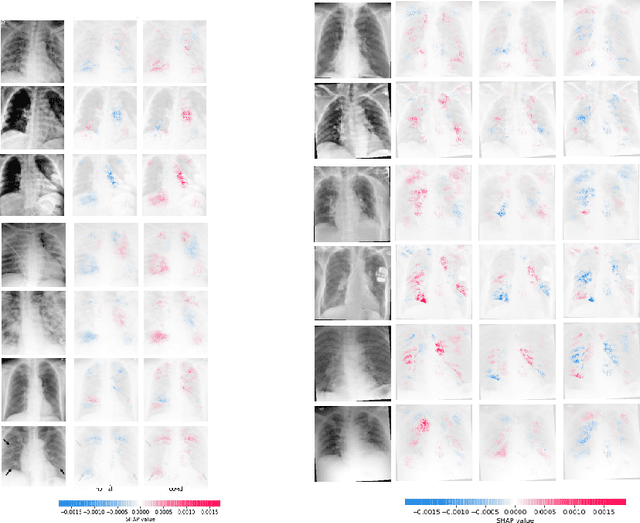
In the light of the COVID-19 pandemic, deep learning methods have been widely investigated in detecting COVID-19 from chest X-rays. However, a more pragmatic approach to applying AI methods to a medical diagnosis is designing a framework that facilitates human-machine interaction and expert decision making. Studies have shown that categorization can play an essential rule in accelerating real-world decision making. Inspired by descriptive document clustering, we propose a domain-independent explanatory clustering framework to group contextually related instances and support radiologists' decision making. While most descriptive clustering approaches employ domain-specific characteristics to form meaningful clusters, we focus on model-level explanation as a more general-purpose element of every learning process to achieve cluster homogeneity. We employ DeepSHAP to generate homogeneous clusters in terms of disease severity and describe the clusters using favorable and unfavorable saliency maps, which visualize the class discriminating regions of an image. These human-interpretable maps complement radiologist knowledge to investigate the whole cluster at once. Besides, as part of this study, we evaluate a model based on VGG-19, which can identify COVID and pneumonia cases with a positive predictive value of 95% and 97%, respectively, comparable to the recent explainable approaches for COVID diagnosis.
Block Shuffle: A Method for High-resolution Fast Style Transfer with Limited Memory
Aug 09, 2020
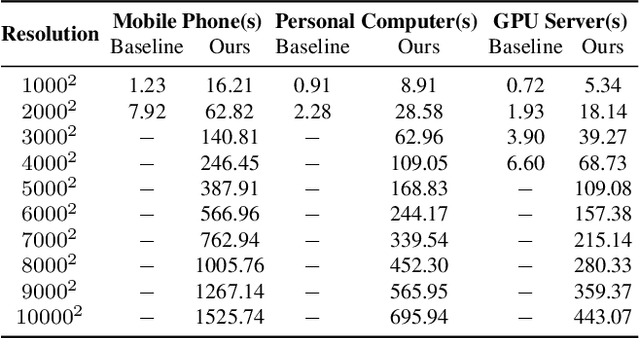
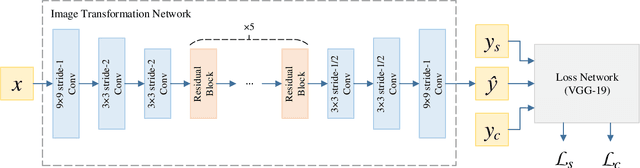
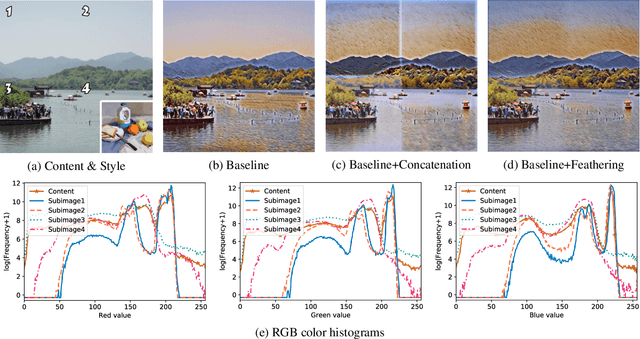
Fast Style Transfer is a series of Neural Style Transfer algorithms that use feed-forward neural networks to render input images. Because of the high dimension of the output layer, these networks require much memory for computation. Therefore, for high-resolution images, most mobile devices and personal computers cannot stylize them, which greatly limits the application scenarios of Fast Style Transfer. At present, the two existing solutions are purchasing more memory and using the feathering-based method, but the former requires additional cost, and the latter has poor image quality. To solve this problem, we propose a novel image synthesis method named \emph{block shuffle}, which converts a single task with high memory consumption to multiple subtasks with low memory consumption. This method can act as a plug-in for Fast Style Transfer without any modification to the network architecture. We use the most popular Fast Style Transfer repository on GitHub as the baseline. Experiments show that the quality of high-resolution images generated by our method is better than that of the feathering-based method. Although our method is an order of magnitude slower than the baseline, it can stylize high-resolution images with limited memory, which is impossible with the baseline. The code and models will be made available on \url{https://github.com/czczup/block-shuffle}.