 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMove to See Better: Towards Self-Supervised Amodal Object Detection
Paper and Code

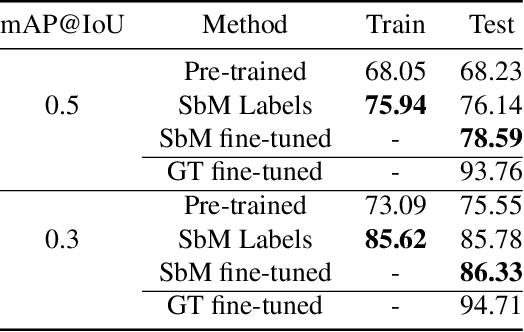
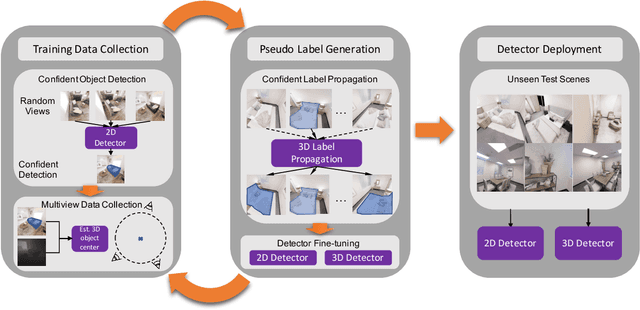
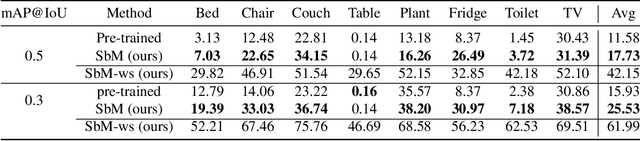
Humans learn to better understand the world by moving around their environment to get more informative viewpoints of the scene. Most methods for 2D visual recognition tasks such as object detection and segmentation treat images of the same scene as individual samples and do not exploit object permanence in multiple views. Generalization to novel scenes and views thus requires additional training with lots of human annotations. In this paper, we propose a self-supervised framework to improve an object detector in unseen scenarios by moving an agent around in a 3D environment and aggregating multi-view RGB-D information. We unproject confident 2D object detections from the pre-trained detector and perform unsupervised 3D segmentation on the point cloud. The segmented 3D objects are then re-projected to all other views to obtain pseudo-labels for fine-tuning. Experiments on both indoor and outdoor datasets show that (1) our framework performs high-quality 3D segmentation from raw RGB-D data and a pre-trained 2D detector; (2) fine-tuning with self-supervision improves the 2D detector significantly where an unseen RGB image is given as input at test time; (3) training a 3D detector with self-supervision outperforms a comparable self-supervised method by a large margin.