 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIGEOCLIP: Unified Geospatial Contrastive Learning
Apr 13, 2026The growing availability of co-located geospatial data spanning aerial imagery, street-level views, elevation models, text, and geographic coordinates offers a unique opportunity for multimodal representation learning. We introduce UNIGEOCLIP, a massively multimodal contrastive framework to jointly align five complementary geospatial modalities in a single unified embedding space. Unlike prior approaches that fuse modalities or rely on a central pivot representation, our method performs all-to-all contrastive alignment, enabling seamless comparison, retrieval, and reasoning across arbitrary combinations of modalities. We further propose a scaled latitude-longitude encoder that improves spatial representation by capturing multi-scale geographic structure. Extensive experiments across downstream geospatial tasks demonstrate that UNIGEOCLIP consistently outperforms single-modality contrastive models and coordinate-only baselines, highlighting the benefits of holistic multimodal geospatial alignment. A reference implementation is available at https://gastruc.github.io/unigeoclip.
Scaling Image Geo-Localization to Continent Level
Oct 30, 2025Determining the precise geographic location of an image at a global scale remains an unsolved challenge. Standard image retrieval techniques are inefficient due to the sheer volume of images (>100M) and fail when coverage is insufficient. Scalable solutions, however, involve a trade-off: global classification typically yields coarse results (10+ kilometers), while cross-view retrieval between ground and aerial imagery suffers from a domain gap and has been primarily studied on smaller regions. This paper introduces a hybrid approach that achieves fine-grained geo-localization across a large geographic expanse the size of a continent. We leverage a proxy classification task during training to learn rich feature representations that implicitly encode precise location information. We combine these learned prototypes with embeddings of aerial imagery to increase robustness to the sparsity of ground-level data. This enables direct, fine-grained retrieval over areas spanning multiple countries. Our extensive evaluation demonstrates that our approach can localize within 200m more than 68\% of queries of a dataset covering a large part of Europe. The code is publicly available at https://scaling-geoloc.github.io.
PointNeRF++: A multi-scale, point-based Neural Radiance Field
Dec 04, 2023



Point clouds offer an attractive source of information to complement images in neural scene representations, especially when few images are available. Neural rendering methods based on point clouds do exist, but they do not perform well when the point cloud quality is low -- e.g., sparse or incomplete, which is often the case with real-world data. We overcome these problems with a simple representation that aggregates point clouds at multiple scale levels with sparse voxel grids at different resolutions. To deal with point cloud sparsity, we average across multiple scale levels -- but only among those that are valid, i.e., that have enough neighboring points in proximity to the ray of a pixel. To help model areas without points, we add a global voxel at the coarsest scale, thus unifying "classical" and point-based NeRF formulations. We validate our method on the NeRF Synthetic, ScanNet, and KITTI-360 datasets, outperforming the state of the art by a significant margin.
SNAP: Self-Supervised Neural Maps for Visual Positioning and Semantic Understanding
Jun 08, 2023



Semantic 2D maps are commonly used by humans and machines for navigation purposes, whether it's walking or driving. However, these maps have limitations: they lack detail, often contain inaccuracies, and are difficult to create and maintain, especially in an automated fashion. Can we use raw imagery to automatically create better maps that can be easily interpreted by both humans and machines? We introduce SNAP, a deep network that learns rich neural 2D maps from ground-level and overhead images. We train our model to align neural maps estimated from different inputs, supervised only with camera poses over tens of millions of StreetView images. SNAP can resolve the location of challenging image queries beyond the reach of traditional methods, outperforming the state of the art in localization by a large margin. Moreover, our neural maps encode not only geometry and appearance but also high-level semantics, discovered without explicit supervision. This enables effective pre-training for data-efficient semantic scene understanding, with the potential to unlock cost-efficient creation of more detailed maps.
GECCO: Geometrically-Conditioned Point Diffusion Models
Mar 10, 2023Diffusion models generating images conditionally on text, such as Dall-E 2 and Stable Diffusion, have recently made a splash far beyond the computer vision community. Here, we tackle the related problem of generating point clouds, both unconditionally, and conditionally with images. For the latter, we introduce a novel geometrically-motivated conditioning scheme based on projecting sparse image features into the point cloud and attaching them to each individual point, at every step in the denoising process. This approach improves geometric consistency and yields greater fidelity than current methods relying on unstructured, global latent codes. Additionally, we show how to apply recent continuous-time diffusion schemes. Our method performs on par or above the state of art on conditional and unconditional experiments on synthetic data, while being faster, lighter, and delivering tractable likelihoods. We show it can also scale to diverse indoors scenes.
TUSK: Task-Agnostic Unsupervised Keypoints
Jun 16, 2022
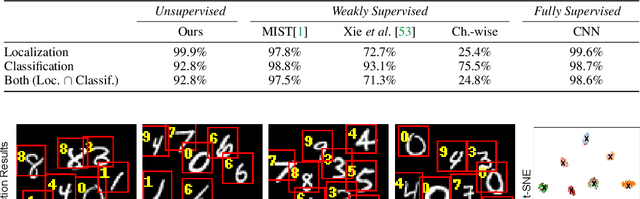
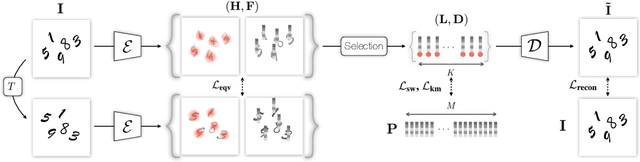

Existing unsupervised methods for keypoint learning rely heavily on the assumption that a specific keypoint type (e.g. elbow, digit, abstract geometric shape) appears only once in an image. This greatly limits their applicability, as each instance must be isolated before applying the method-an issue that is never discussed or evaluated. We thus propose a novel method to learn Task-agnostic, UnSupervised Keypoints (TUSK) which can deal with multiple instances. To achieve this, instead of the commonly-used strategy of detecting multiple heatmaps, each dedicated to a specific keypoint type, we use a single heatmap for detection, and enable unsupervised learning of keypoint types through clustering. Specifically, we encode semantics into the keypoints by teaching them to reconstruct images from a sparse set of keypoints and their descriptors, where the descriptors are forced to form distinct clusters in feature space around learned prototypes. This makes our approach amenable to a wider range of tasks than any previous unsupervised keypoint method: we show experiments on multiple-instance detection and classification, object discovery, and landmark detection-all unsupervised-with performance on par with the state of the art, while also being able to deal with multiple instances.
COTR: Correspondence Transformer for Matching Across Images
Mar 25, 2021
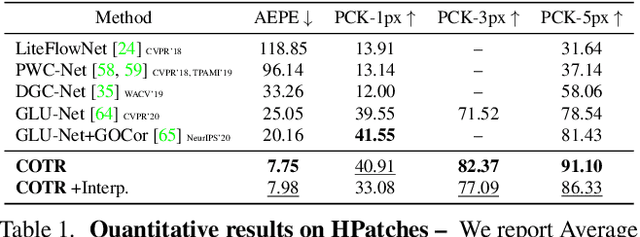
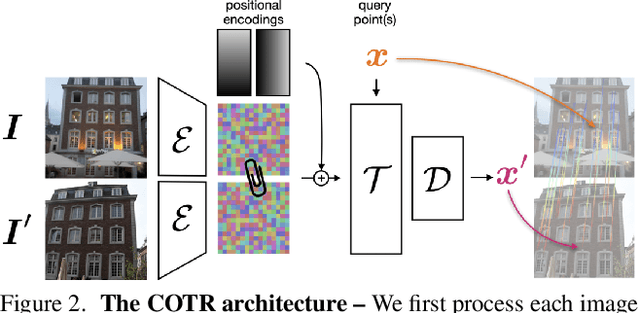
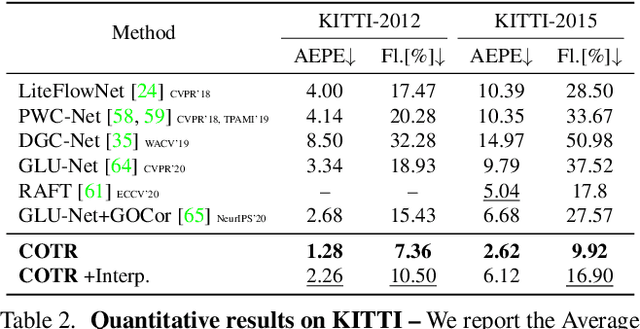
We propose a novel framework for finding correspondences in images based on a deep neural network that, given two images and a query point in one of them, finds its correspondence in the other. By doing so, one has the option to query only the points of interest and retrieve sparse correspondences, or to query all points in an image and obtain dense mappings. Importantly, in order to capture both local and global priors, and to let our model relate between image regions using the most relevant among said priors, we realize our network using a transformer. At inference time, we apply our correspondence network by recursively zooming in around the estimates, yielding a multiscale pipeline able to provide highly-accurate correspondences. Our method significantly outperforms the state of the art on both sparse and dense correspondence problems on multiple datasets and tasks, ranging from wide-baseline stereo to optical flow, without any retraining for a specific dataset. We commit to releasing data, code, and all the tools necessary to train from scratch and ensure reproducibility.
DISK: Learning local features with policy gradient
Jun 24, 2020
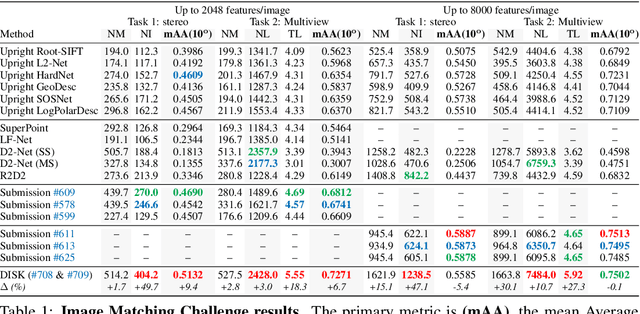

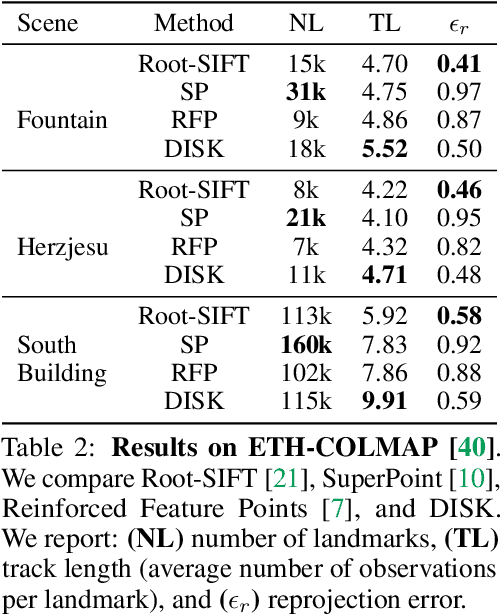
Local feature frameworks are difficult to learn in an end-to-end fashion, due to the discreteness inherent to the selection and matching of sparse keypoints. We introduce DISK (DIScrete Keypoints), a novel method that overcomes these obstacles by leveraging principles from Reinforcement Learning (RL), optimizing end-to-end for a high number of correct feature matches. Our simple yet expressive probabilistic model lets us keep the training and inference regimes close, while maintaining good enough convergence properties to reliably train from scratch. Our features can be extracted very densely while remaining discriminative, challenging commonly held assumptions about what constitutes a good keypoint, as showcased in Fig. 1, and deliver state-of-the-art results on three public benchmarks.
Image Matching across Wide Baselines: From Paper to Practice
Mar 03, 2020
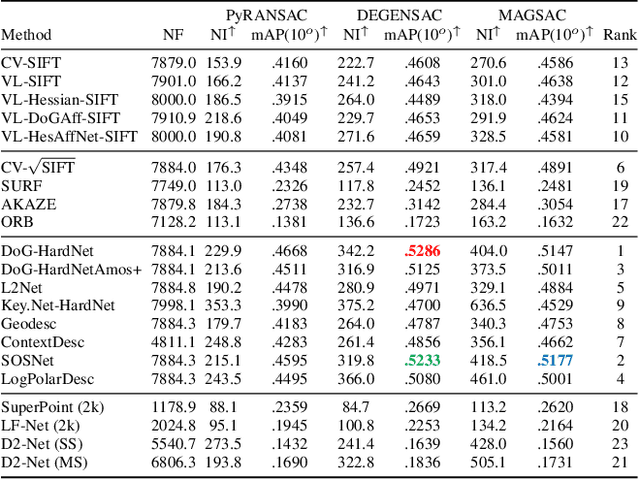

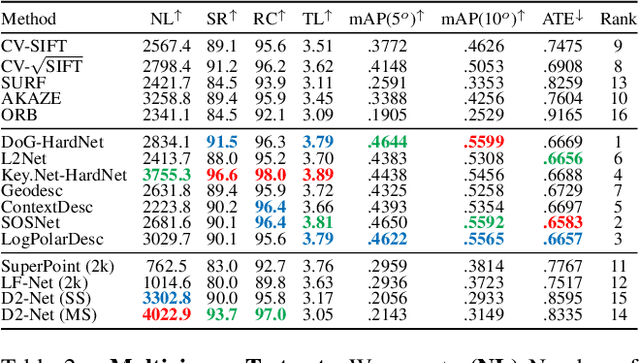
We introduce a comprehensive benchmark for local features and robust estimation algorithms, focusing on the downstream task -- the accuracy of the reconstructed camera pose -- as our primary metric. Our pipeline's modular structure allows us to easily integrate, configure, and combine methods and heuristics. We demonstrate this by embedding dozens of popular algorithms and evaluating them, from seminal works to the cutting edge of machine learning research. We show that with proper settings, classical solutions may still outperform the perceived state of the art. Besides establishing the actual state of the art, the experiments conducted in this paper reveal unexpected properties of SfM pipelines that can be exploited to help improve their performance, for both algorithmic and learned methods. Data and code are online https://github.com/vcg-uvic/image-matching-benchmark, providing an easy-to-use and flexible framework for the benchmarking of local feature and robust estimation methods, both alongside and against top-performing methods. This work provides the basis for an open challenge on wide-baseline image matching https://vision.uvic.ca/image-matching-challenge .
Beyond Cartesian Representations for Local Descriptors
Aug 15, 2019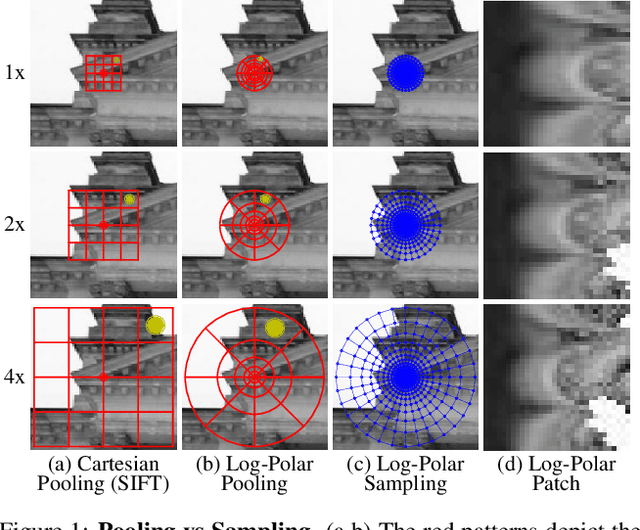
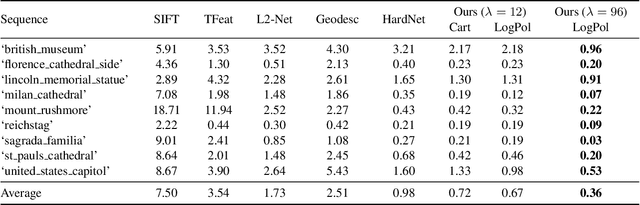

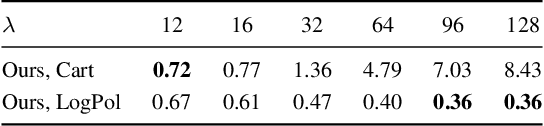
The dominant approach for learning local patch descriptors relies on small image regions whose scale must be properly estimated a priori by a keypoint detector. In other words, if two patches are not in correspondence, their descriptors will not match. A strategy often used to alleviate this problem is to "pool" the pixel-wise features over log-polar regions, rather than regularly spaced ones. By contrast, we propose to extract the "support region" directly with a log-polar sampling scheme. We show that this provides us with a better representation by simultaneously oversampling the immediate neighbourhood of the point and undersampling regions far away from it. We demonstrate that this representation is particularly amenable to learning descriptors with deep networks. Our models can match descriptors across a much wider range of scales than was possible before, and also leverage much larger support regions without suffering from occlusions. We report state-of-the-art results on three different datasets.