 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Detect 3D Objects from Point Clouds in Real Time
Jun 05, 2020
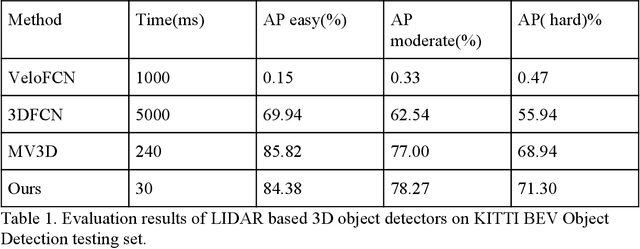
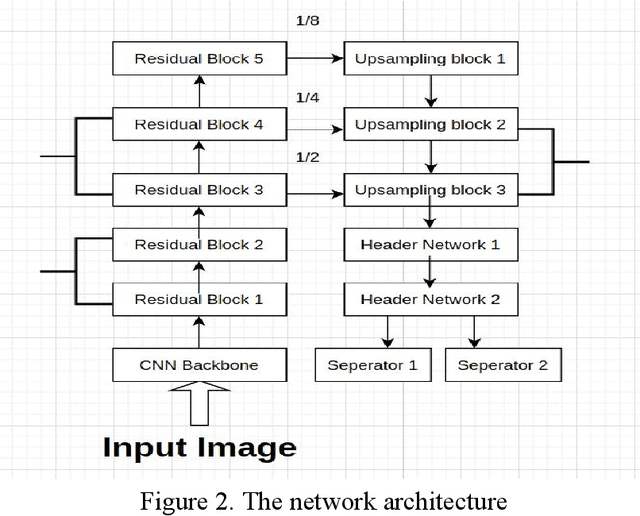
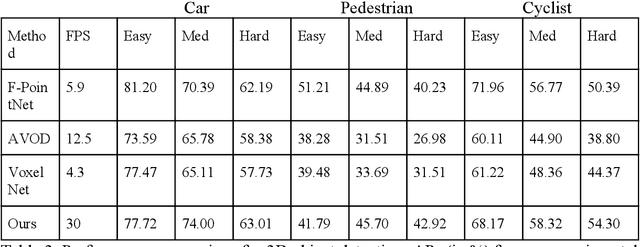
In this paper, we present a combined architecture using dilated and transposed convolutional neural networks for accurate and efficient semantic image segmentation. In contrast to previous fully convolutional neural networks such as FCN with almost all computation shared on the entire image, we propose an additional architecture which we have named as dilated - transposed fully convolutional neural networks. To achieve this goal, we used dilated convolutional layers in downsampling and transposed convolutional layers in upsampling layers. We have used skip connections in between the blocks formed by convolutions and max pooling layers. This type of architecture has been used successfully in the past for image classification using residual network. In addition we also found selu activation function instead of relu to give better results on the test set images. We reason this is the due to avoiding the model getting stuck in a local minimum, thus experiencing a famous vanishing gradient problem in case with relu activation function. Meanwhile, our result achieved pixel wise class accuracy of 88% on the test set and mean Intersection Over Union(IOU) value of 53.5 which is better than the state of the art using the previous fully convolutional neural networks.
MTStereo 2.0: improved accuracy of stereo depth estimation withMax-trees
Jun 27, 2020



Efficient yet accurate extraction of depth from stereo image pairs is required by systems with low power resources, such as robotics and embedded systems. State-of-the-art stereo matching methods based on convolutional neural networks require intensive computations on GPUs and are difficult to deploy on embedded systems. In this paper, we propose a stereo matching method, called MTStereo 2.0, for limited-resource systems that require efficient and accurate depth estimation. It is based on a Max-tree hierarchical representation of image pairs, which we use to identify matching regions along image scan-lines. The method includes a cost function that considers similarity of region contextual information based on the Max-trees and a disparity border preserving cost aggregation approach. MTStereo 2.0 improves on its predecessor MTStereo 1.0 as it a) deploys a more robust cost function, b) performs more thorough detection of incorrect matches, c) computes disparity maps with pixel-level rather than node-level precision. MTStereo provides accurate sparse and semi-dense depth estimation and does not require intensive GPU computations like methods based on CNNs. Thus it can run on embedded and robotics devices with low-power requirements. We tested the proposed approach on several benchmark data sets, namely KITTI 2015, Driving, FlyingThings3D, Middlebury 2014, Monkaa and the TrimBot2020 garden data sets, and achieved competitive accuracy and efficiency. The code is available at https://github.com/rbrandt1/MaxTreeS.
Appearance Harmonization for Single Image Shadow Removal
Mar 21, 2016
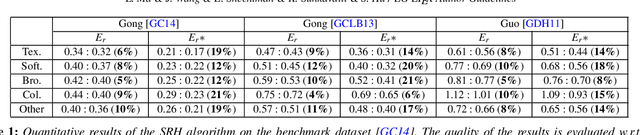


Shadows often create unwanted artifacts in photographs, and removing them can be very challenging. Previous shadow removal methods often produce de-shadowed regions that are visually inconsistent with the rest of the image. In this work we propose a fully automatic shadow region harmonization approach that improves the appearance compatibility of the de-shadowed region as typically produced by previous methods. It is based on a shadow-guided patch-based image synthesis approach that reconstructs the shadow region using patches sampled from non-shadowed regions. The result is then refined based on the reconstruction confidence to handle unique image patterns. Many shadow removal results and comparisons are show the effectiveness of our improvement. Quantitative evaluation on a benchmark dataset suggests that our automatic shadow harmonization approach effectively improves upon the state-of-the-art.
Paying Attention to Descriptions Generated by Image Captioning Models
Aug 04, 2017
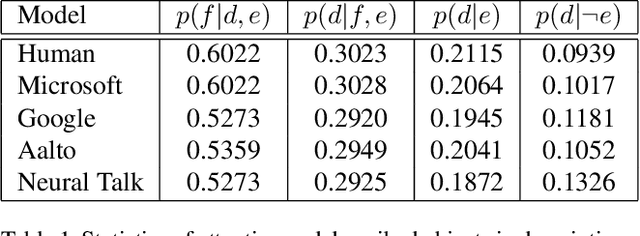
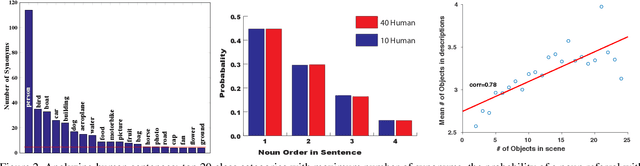
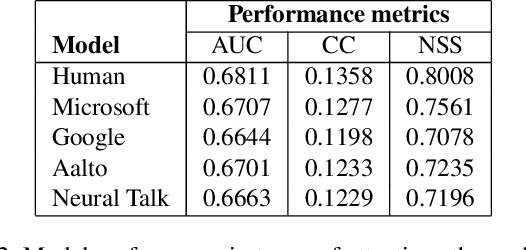
To bridge the gap between humans and machines in image understanding and describing, we need further insight into how people describe a perceived scene. In this paper, we study the agreement between bottom-up saliency-based visual attention and object referrals in scene description constructs. We investigate the properties of human-written descriptions and machine-generated ones. We then propose a saliency-boosted image captioning model in order to investigate benefits from low-level cues in language models. We learn that (1) humans mention more salient objects earlier than less salient ones in their descriptions, (2) the better a captioning model performs, the better attention agreement it has with human descriptions, (3) the proposed saliency-boosted model, compared to its baseline form, does not improve significantly on the MS COCO database, indicating explicit bottom-up boosting does not help when the task is well learnt and tuned on a data, (4) a better generalization is, however, observed for the saliency-boosted model on unseen data.
DeformNet: Free-Form Deformation Network for 3D Shape Reconstruction from a Single Image
Aug 11, 2017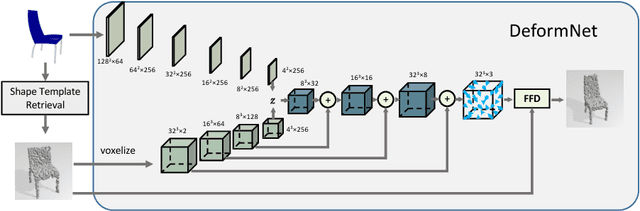


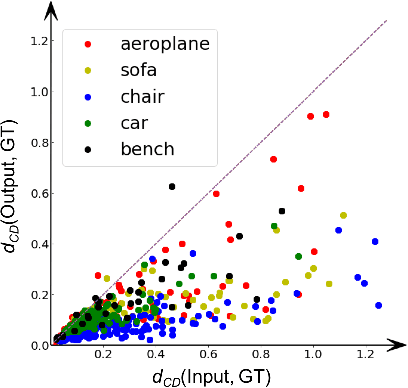
3D reconstruction from a single image is a key problem in multiple applications ranging from robotic manipulation to augmented reality. Prior methods have tackled this problem through generative models which predict 3D reconstructions as voxels or point clouds. However, these methods can be computationally expensive and miss fine details. We introduce a new differentiable layer for 3D data deformation and use it in DeformNet to learn a model for 3D reconstruction-through-deformation. DeformNet takes an image input, searches the nearest shape template from a database, and deforms the template to match the query image. We evaluate our approach on the ShapeNet dataset and show that - (a) the Free-Form Deformation layer is a powerful new building block for Deep Learning models that manipulate 3D data (b) DeformNet uses this FFD layer combined with shape retrieval for smooth and detail-preserving 3D reconstruction of qualitatively plausible point clouds with respect to a single query image (c) compared to other state-of-the-art 3D reconstruction methods, DeformNet quantitatively matches or outperforms their benchmarks by significant margins. For more information, visit: https://deformnet-site.github.io/DeformNet-website/ .
Domain Adaptation with Morphologic Segmentation
Jun 16, 2020


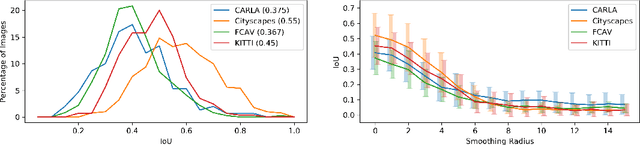
We present a novel domain adaptation framework that uses morphologic segmentation to translate images from arbitrary input domains (real and synthetic) into a uniform output domain. Our framework is based on an established image-to-image translation pipeline that allows us to first transform the input image into a generalized representation that encodes morphology and semantics - the edge-plus-segmentation map (EPS) - which is then transformed into an output domain. Images transformed into the output domain are photo-realistic and free of artifacts that are commonly present across different real (e.g. lens flare, motion blur, etc.) and synthetic (e.g. unrealistic textures, simplified geometry, etc.) data sets. Our goal is to establish a preprocessing step that unifies data from multiple sources into a common representation that facilitates training downstream tasks in computer vision. This way, neural networks for existing tasks can be trained on a larger variety of training data, while they are also less affected by overfitting to specific data sets. We showcase the effectiveness of our approach by qualitatively and quantitatively evaluating our method on four data sets of simulated and real data of urban scenes. Additional results can be found on the project website available at http://jonathank.de/research/eps/ .
COCOI: Contact-aware Online Context Inference for Generalizable Non-planar Pushing
Nov 23, 2020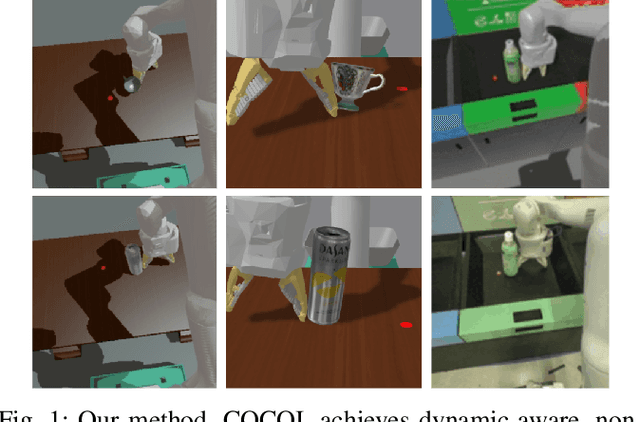
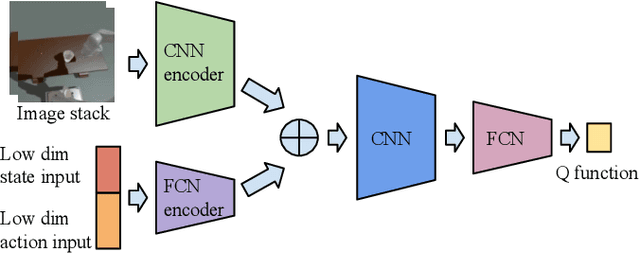
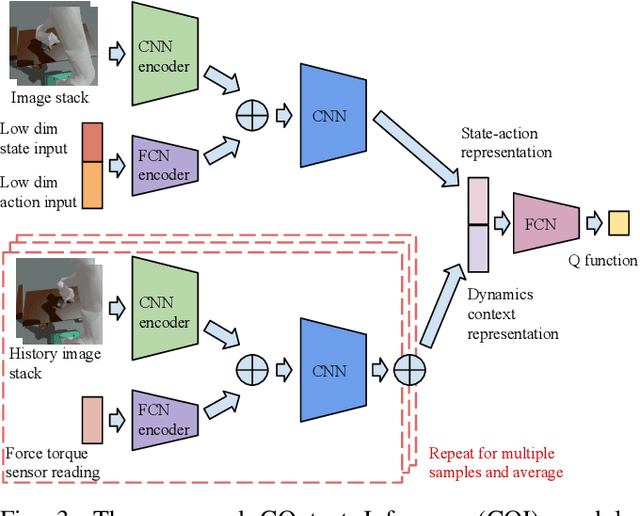
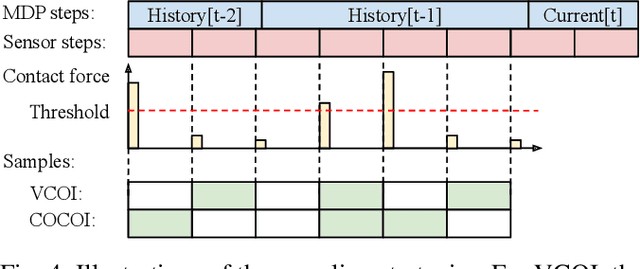
General contact-rich manipulation problems are long-standing challenges in robotics due to the difficulty of understanding complicated contact physics. Deep reinforcement learning (RL) has shown great potential in solving robot manipulation tasks. However, existing RL policies have limited adaptability to environments with diverse dynamics properties, which is pivotal in solving many contact-rich manipulation tasks. In this work, we propose Contact-aware Online COntext Inference (COCOI), a deep RL method that encodes a context embedding of dynamics properties online using contact-rich interactions. We study this method based on a novel and challenging non-planar pushing task, where the robot uses a monocular camera image and wrist force torque sensor reading to push an object to a goal location while keeping it upright. We run extensive experiments to demonstrate the capability of COCOI in a wide range of settings and dynamics properties in simulation, and also in a sim-to-real transfer scenario on a real robot (Video: https://youtu.be/nrmJYksh1Kc)
multi-patch aggregation models for resampling detection
Mar 03, 2020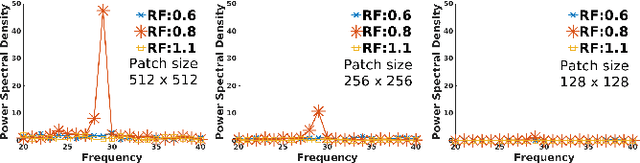

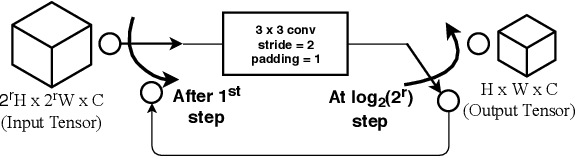
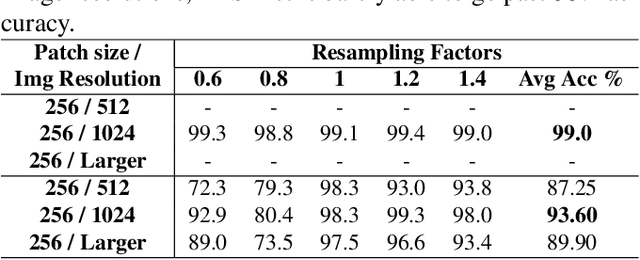
Images captured nowadays are of varying dimensions with smartphones and DSLR's allowing users to choose from a list of available image resolutions. It is therefore imperative for forensic algorithms such as resampling detection to scale well for images of varying dimensions. However, in our experiments, we observed that many state-of-the-art forensic algorithms are sensitive to image size and their performance quickly degenerates when operated on images of diverse dimensions despite re-training them using multiple image sizes. To handle this issue, we propose a novel pooling strategy called ITERATIVE POOLING. This pooling strategy can dynamically adjust input tensors in a discrete without much loss of information as in ROI Max-pooling. This pooling strategy can be used with any of the existing deep models and for demonstration purposes, we show its utility on Resnet-18 for the case of resampling detection a fundamental operation for any image sought of image manipulation. Compared to existing strategies and Max-pooling it gives up to 7-8% improvement on public datasets.
Super-resolution Variational Auto-Encoders
Jun 30, 2020

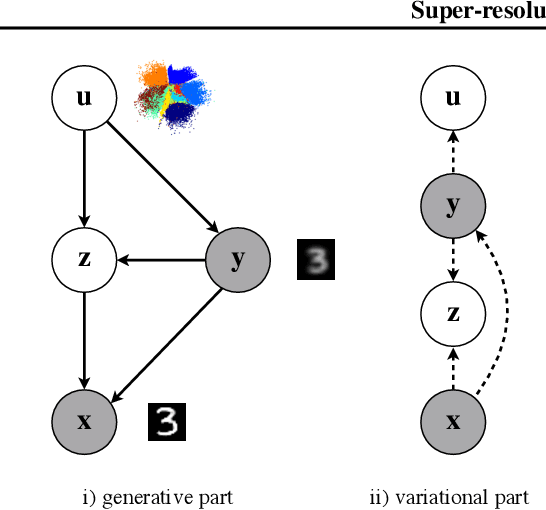
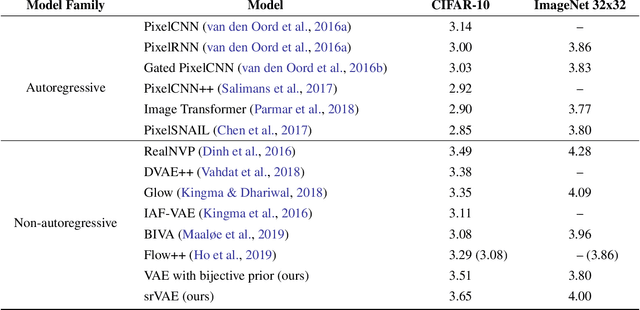
The framework of variational autoencoders (VAEs) provides a principled method for jointly learning latent-variable models and corresponding inference models. However, the main drawback of this approach is the blurriness of the generated images. Some studies link this effect to the objective function, namely, the (negative) log-likelihood. Here, we propose to enhance VAEs by adding a random variable that is a downscaled version of the original image and still use the log-likelihood function as the learning objective. Further, by providing the downscaled image as an input to the decoder, it can be used in a manner similar to the super-resolution. We present empirically that the proposed approach performs comparably to VAEs in terms of the negative log-likelihood, but it obtains a better FID score in data synthesis.
Understanding the robustness of deep neural network classifiers for breast cancer screening
Mar 23, 2020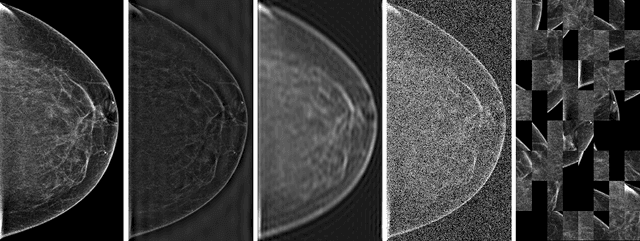

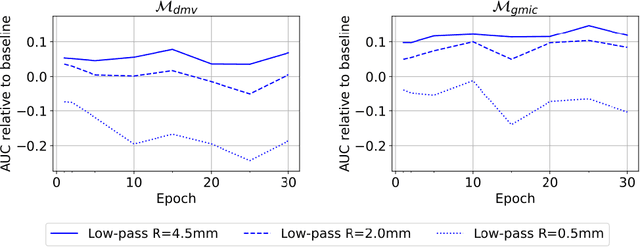
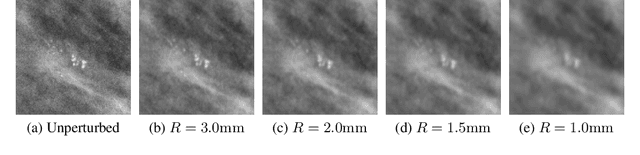
Deep neural networks (DNNs) show promise in breast cancer screening, but their robustness to input perturbations must be better understood before they can be clinically implemented. There exists extensive literature on this subject in the context of natural images that can potentially be built upon. However, it cannot be assumed that conclusions about robustness will transfer from natural images to mammogram images, due to significant differences between the two image modalities. In order to determine whether conclusions will transfer, we measure the sensitivity of a radiologist-level screening mammogram image classifier to four commonly studied input perturbations that natural image classifiers are sensitive to. We find that mammogram image classifiers are also sensitive to these perturbations, which suggests that we can build on the existing literature. We also perform a detailed analysis on the effects of low-pass filtering, and find that it degrades the visibility of clinically meaningful features called microcalcifications. Since low-pass filtering removes semantically meaningful information that is predictive of breast cancer, we argue that it is undesirable for mammogram image classifiers to be invariant to it. This is in contrast to natural images, where we do not want DNNs to be sensitive to low-pass filtering due to its tendency to remove information that is human-incomprehensible.