 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Differentially Private Synthetic Medical Data Generation using Convolutional GANs
Dec 22, 2020
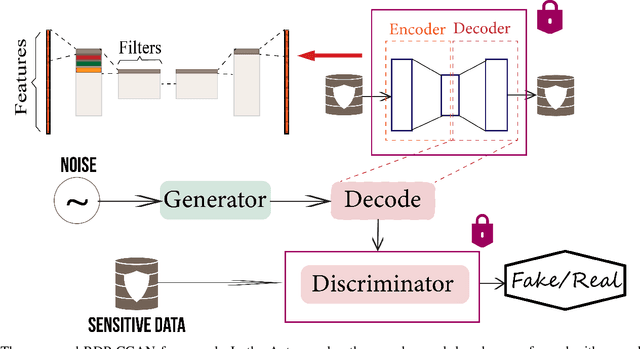
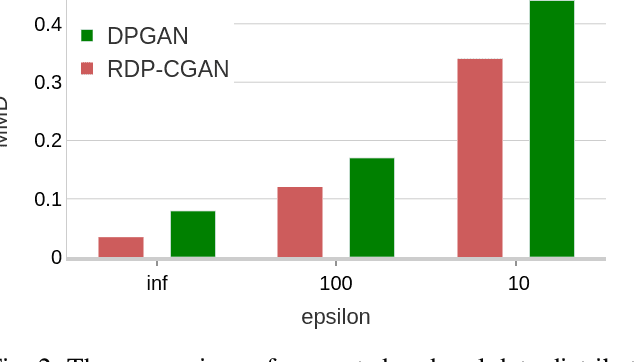
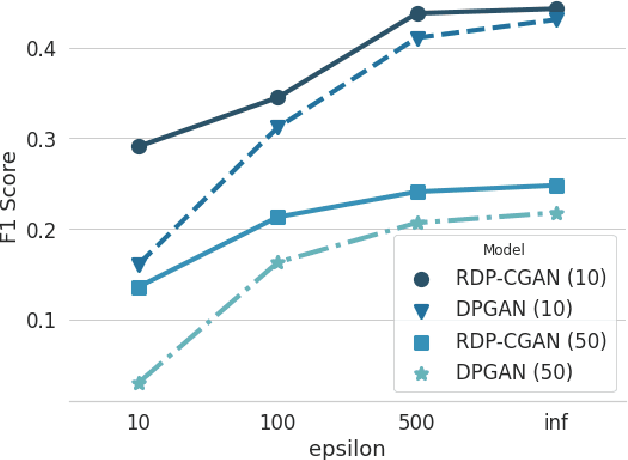
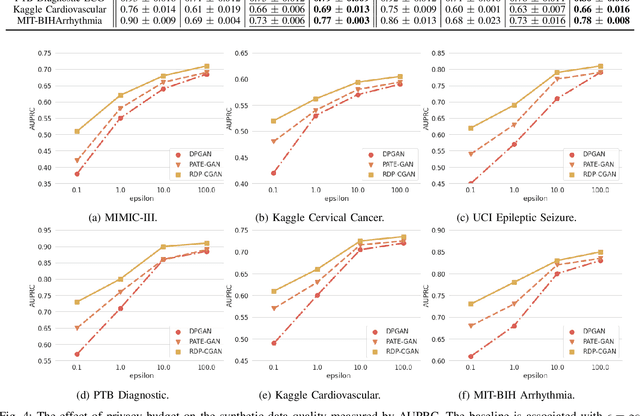
Deep learning models have demonstrated superior performance in several application problems, such as image classification and speech processing. However, creating a deep learning model using health record data requires addressing certain privacy challenges that bring unique concerns to researchers working in this domain. One effective way to handle such private data issues is to generate realistic synthetic data that can provide practically acceptable data quality and correspondingly the model performance. To tackle this challenge, we develop a differentially private framework for synthetic data generation using R\'enyi differential privacy. Our approach builds on convolutional autoencoders and convolutional generative adversarial networks to preserve some of the critical characteristics of the generated synthetic data. In addition, our model can also capture the temporal information and feature correlations that might be present in the original data. We demonstrate that our model outperforms existing state-of-the-art models under the same privacy budget using several publicly available benchmark medical datasets in both supervised and unsupervised settings.
ResFeats: Residual Network Based Features for Image Classification
Nov 21, 2016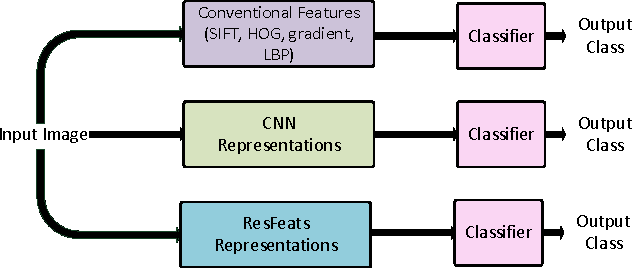
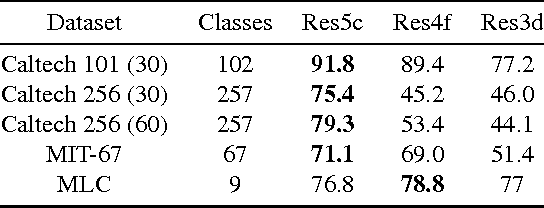

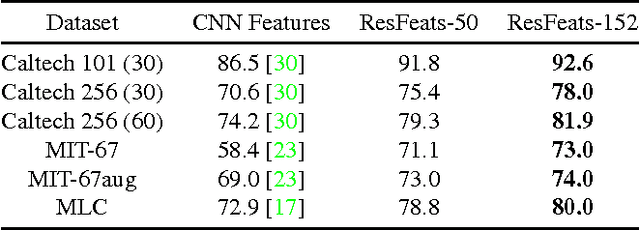
Deep residual networks have recently emerged as the state-of-the-art architecture in image segmentation and object detection. In this paper, we propose new image features (called ResFeats) extracted from the last convolutional layer of deep residual networks pre-trained on ImageNet. We propose to use ResFeats for diverse image classification tasks namely, object classification, scene classification and coral classification and show that ResFeats consistently perform better than their CNN counterparts on these classification tasks. Since the ResFeats are large feature vectors, we propose to use PCA for dimensionality reduction. Experimental results are provided to show the effectiveness of ResFeats with state-of-the-art classification accuracies on Caltech-101, Caltech-256 and MLC datasets and a significant performance improvement on MIT-67 dataset compared to the widely used CNN features.
Deep multi-modal networks for book genre classification based on its cover
Nov 15, 2020
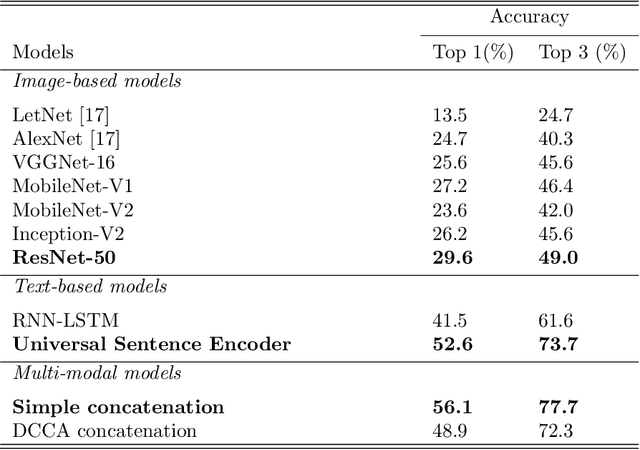
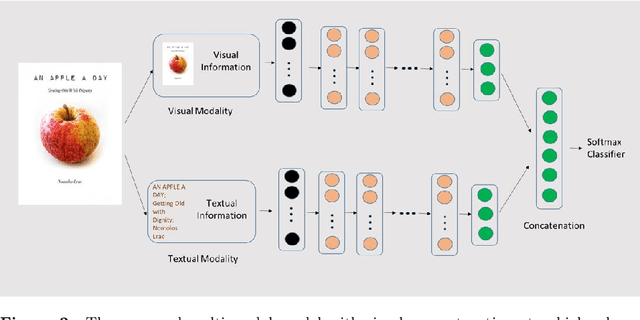
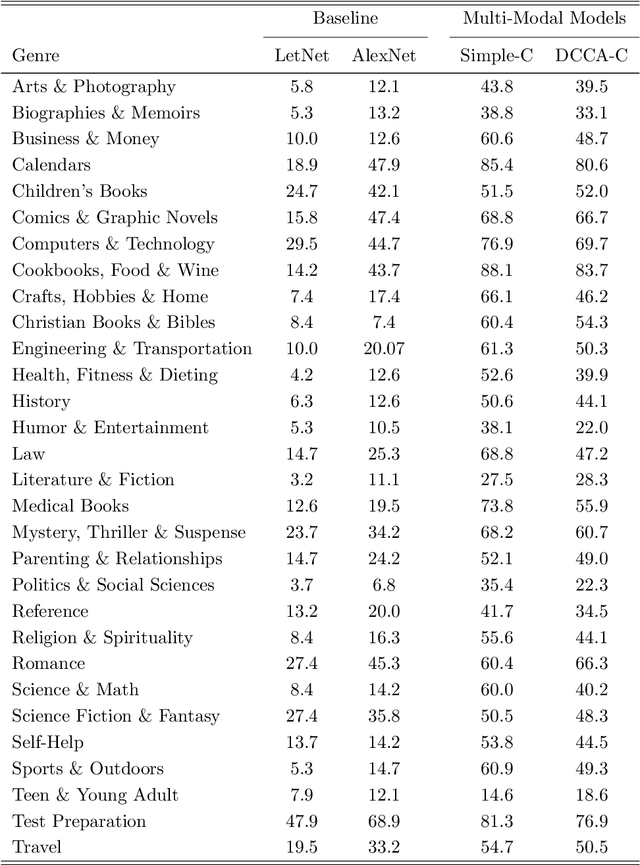
Book covers are usually the very first impression to its readers and they often convey important information about the content of the book. Book genre classification based on its cover would be utterly beneficial to many modern retrieval systems, considering that the complete digitization of books is an extremely expensive task. At the same time, it is also an extremely challenging task due to the following reasons: First, there exists a wide variety of book genres, many of which are not concretely defined. Second, book covers, as graphic designs, vary in many different ways such as colors, styles, textual information, etc, even for books of the same genre. Third, book cover designs may vary due to many external factors such as country, culture, target reader populations, etc. With the growing competitiveness in the book industry, the book cover designers and typographers push the cover designs to its limit in the hope of attracting sales. The cover-based book classification systems become a particularly exciting research topic in recent years. In this paper, we propose a multi-modal deep learning framework to solve this problem. The contribution of this paper is four-fold. First, our method adds an extra modality by extracting texts automatically from the book covers. Second, image-based and text-based, state-of-the-art models are evaluated thoroughly for the task of book cover classification. Third, we develop an efficient and salable multi-modal framework based on the images and texts shown on the covers only. Fourth, a thorough analysis of the experimental results is given and future works to improve the performance is suggested. The results show that the multi-modal framework significantly outperforms the current state-of-the-art image-based models. However, more efforts and resources are needed for this classification task in order to reach a satisfactory level.
How to Make an Image More Memorable? A Deep Style Transfer Approach
Apr 06, 2017
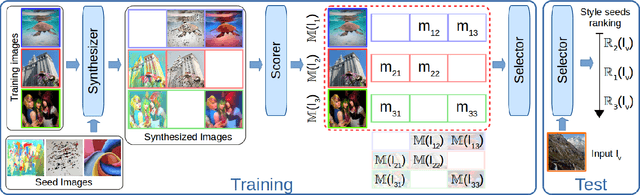
Recent works have shown that it is possible to automatically predict intrinsic image properties like memorability. In this paper, we take a step forward addressing the question: "Can we make an image more memorable?". Methods for automatically increasing image memorability would have an impact in many application fields like education, gaming or advertising. Our work is inspired by the popular editing-by-applying-filters paradigm adopted in photo editing applications, like Instagram and Prisma. In this context, the problem of increasing image memorability maps to that of retrieving "memorabilizing" filters or style "seeds". Still, users generally have to go through most of the available filters before finding the desired solution, thus turning the editing process into a resource and time consuming task. In this work, we show that it is possible to automatically retrieve the best style seeds for a given image, thus remarkably reducing the number of human attempts needed to find a good match. Our approach leverages from recent advances in the field of image synthesis and adopts a deep architecture for generating a memorable picture from a given input image and a style seed. Importantly, to automatically select the best style a novel learning-based solution, also relying on deep models, is proposed. Our experimental evaluation, conducted on publicly available benchmarks, demonstrates the effectiveness of the proposed approach for generating memorable images through automatic style seed selection
Strategy and Benchmark for Converting Deep Q-Networks to Event-Driven Spiking Neural Networks
Sep 30, 2020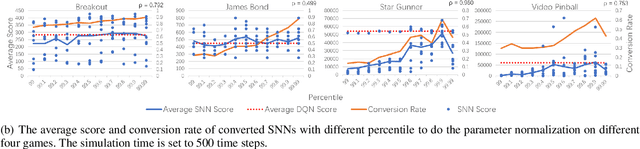
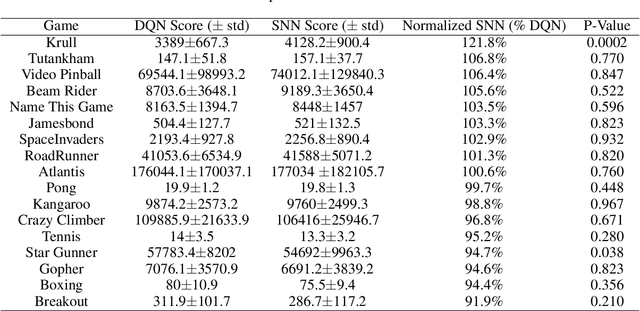
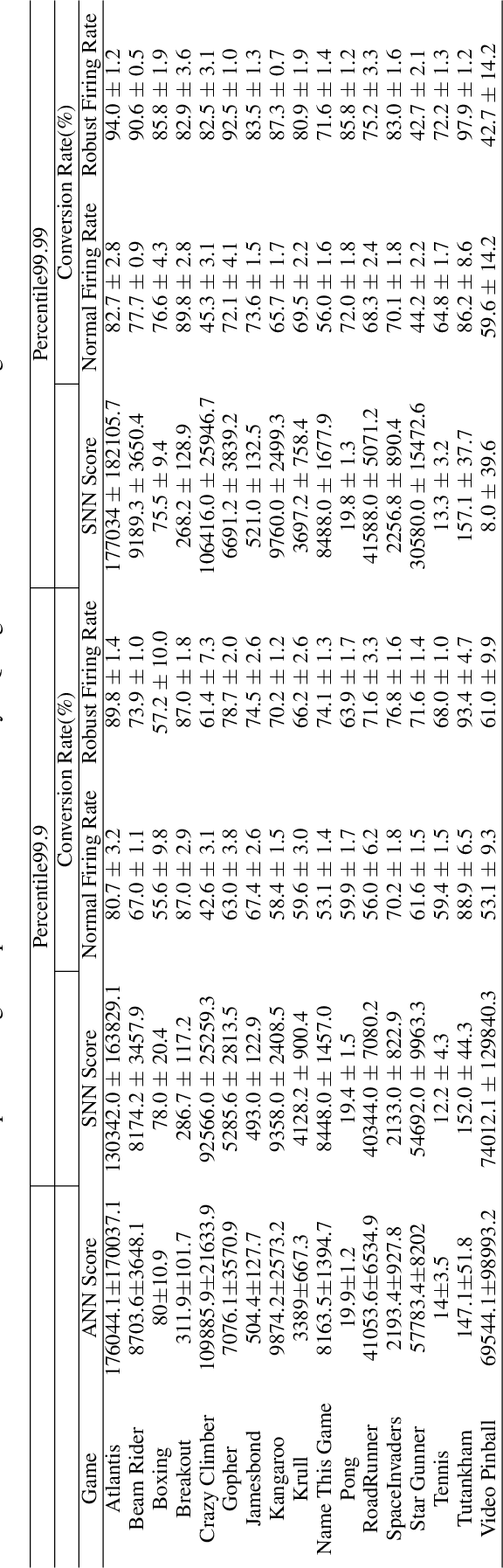
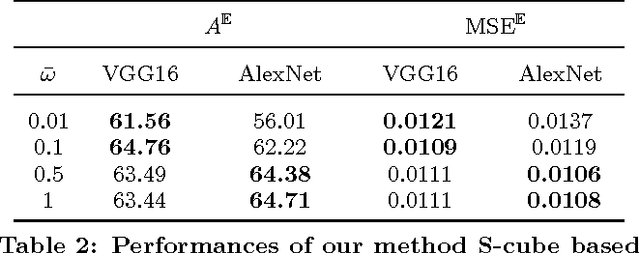
Spiking neural networks (SNNs) have great potential for energy-efficient implementation of Deep Neural Networks (DNNs) on dedicated neuromorphic hardware. Recent studies demonstrated competitive performance of SNNs compared with DNNs on image classification tasks, including CIFAR-10 and ImageNet data. The present work focuses on using SNNs in combination with deep reinforcement learning in ATARI games, which involves additional complexity as compared to image classification. We review the theory of converting DNNs to SNNs and extending the conversion to Deep Q-Networks (DQNs). We propose a robust representation of the firing rate to reduce the error during the conversion process. In addition, we introduce a new metric to evaluate the conversion process by comparing the decisions made by the DQN and SNN, respectively. We also analyze how the simulation time and parameter normalization influence the performance of converted SNNs. We achieve competitive scores on 17 top-performing Atari games. To the best of our knowledge, our work is the first to achieve state-of-the-art performance on multiple Atari games with SNNs. Our work serves as a benchmark for the conversion of DQNs to SNNs and paves the way for further research on solving reinforcement learning tasks with SNNs.
Distribution Adaptive INT8 Quantization for Training CNNs
Feb 09, 2021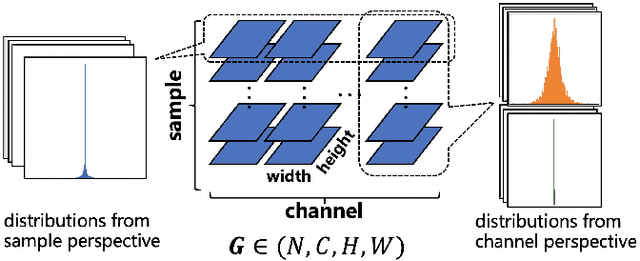
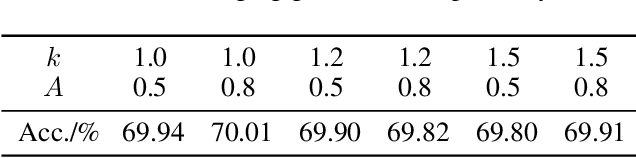
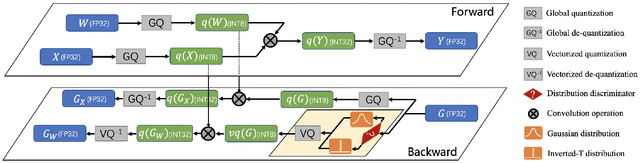

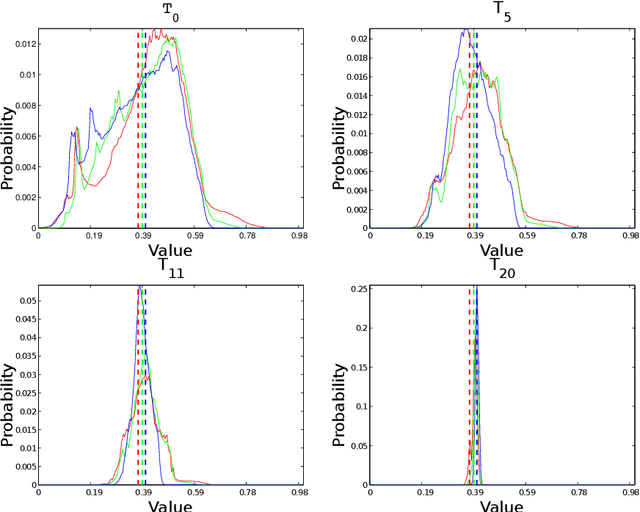
Researches have demonstrated that low bit-width (e.g., INT8) quantization can be employed to accelerate the inference process. It makes the gradient quantization very promising since the backward propagation requires approximately twice more computation than forward one. Due to the variability and uncertainty of gradient distribution, a lot of methods have been proposed to attain training stability. However, most of them ignore the channel-wise gradient distributions and the impact of gradients with different magnitudes, resulting in the degradation of final accuracy. In this paper, we propose a novel INT8 quantization training framework for convolutional neural network to address the above issues. Specifically, we adopt Gradient Vectorized Quantization to quantize the gradient, based on the observation that layer-wise gradients contain multiple distributions along the channel dimension. Then, Magnitude-aware Clipping Strategy is introduced by taking the magnitudes of gradients into consideration when minimizing the quantization error, and we present a theoretical derivation to solve the quantization parameters of different distributions. Experimental results on broad range of computer vision tasks, such as image classification, object detection and video classification, demonstrate that the proposed Distribution Adaptive INT8 Quantization training method has achieved almost lossless training accuracy for different backbones, including ResNet, MobileNetV2, InceptionV3, VGG and AlexNet, which is superior to the state-of-the-art techniques. Moreover, we further implement the INT8 kernel that can accelerate the training iteration more than 200% under the latest Turing architecture, i.e., our method excels on both training accuracy and speed.
Single Image Restoration for Participating Media Based on Prior Fusion
Jan 11, 2017
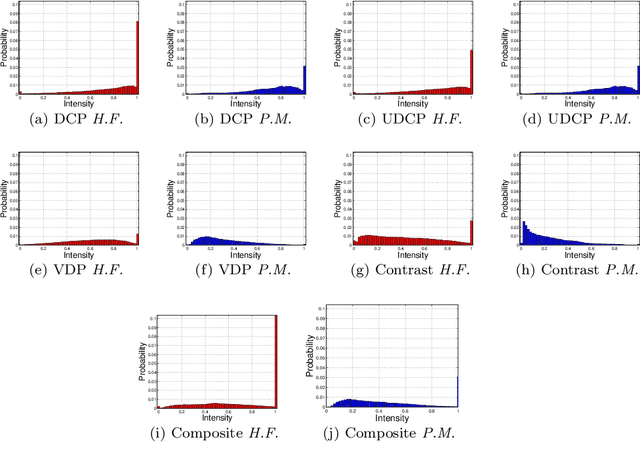
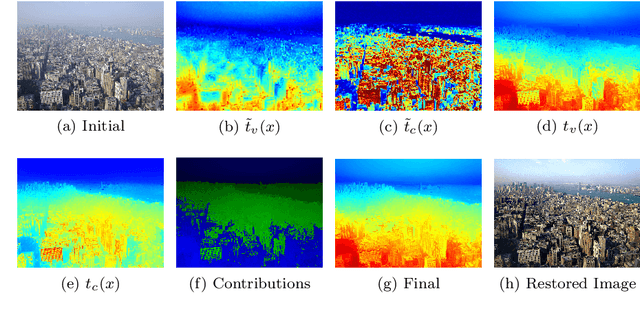
This paper describes a method to restore degraded images captured in a participating media -- fog, turbid water, sand storm, etc. Differently from the related work that only deal with a medium, we obtain generality by using an image formation model and a fusion of new image priors. The model considers the image color variation produced by the medium. The proposed restoration method is based on the fusion of these priors and supported by statistics collected on images acquired in both non-participating and participating media. The key of the method is to fuse two complementary measures --- local contrast and color data. The obtained results on underwater and foggy images demonstrate the capabilities of the proposed method. Moreover, we evaluated our method using a special dataset for which a ground-truth image is available.
Density Map Guided Object Detection in Aerial Images
Apr 12, 2020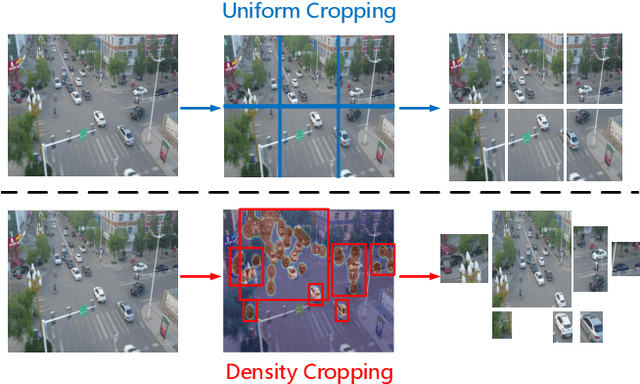

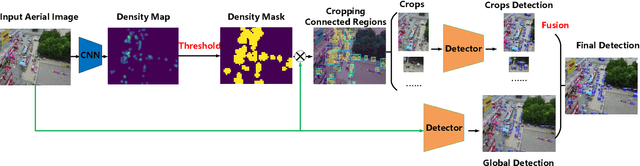
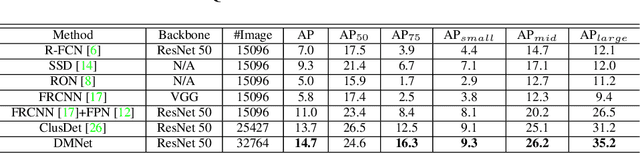
Object detection in high-resolution aerial images is a challenging task because of 1) the large variation in object size, and 2) non-uniform distribution of objects. A common solution is to divide the large aerial image into small (uniform) crops and then apply object detection on each small crop. In this paper, we investigate the image cropping strategy to address these challenges. Specifically, we propose a Density-Map guided object detection Network (DMNet), which is inspired from the observation that the object density map of an image presents how objects distribute in terms of the pixel intensity of the map. As pixel intensity varies, it is able to tell whether a region has objects or not, which in turn provides guidance for cropping images statistically. DMNet has three key components: a density map generation module, an image cropping module and an object detector. DMNet generates a density map and learns scale information based on density intensities to form cropping regions. Extensive experiments show that DMNet achieves state-of-the-art performance on two popular aerial image datasets, i.e. VisionDrone and UAVDT.
Cross-modal registration using point clouds and graph-matching in the context of correlative microscopies
Dec 01, 2020
Correlative microscopy aims at combining two or more modalities to gain more information than the one provided by one modality on the same biological structure. Registration is needed at different steps of correlative microscopies workflows. Biologists want to select the image content used for registration not to introduce bias in the correlation of unknown structures. Intensity-based methods might not allow this selection and might be too slow when the images are very large. We propose an approach based on point clouds created from selected content by the biologist. These point clouds may be prone to big differences in densities but also missing parts and outliers. In this paper we present a method of registration for point clouds based on graph building and graph matching, and compare the method to iterative closest point based methods.
SENTRY: Selective Entropy Optimization via Committee Consistency for Unsupervised Domain Adaptation
Dec 21, 2020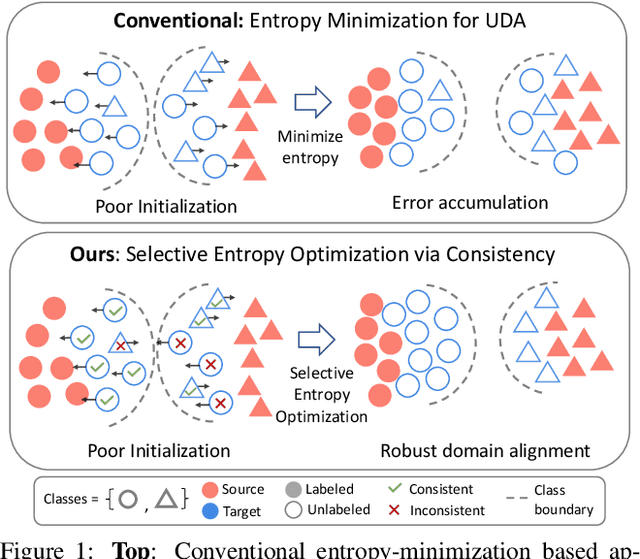
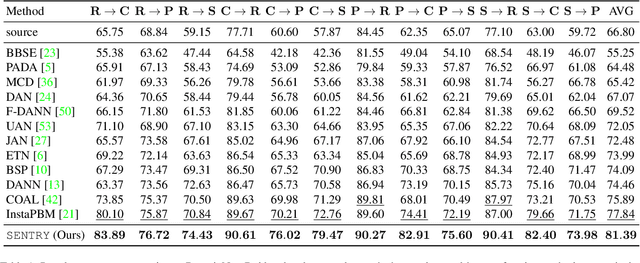
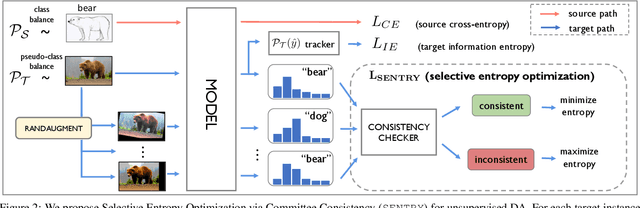
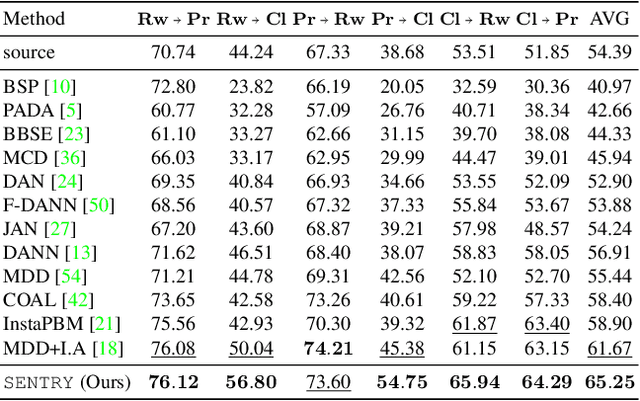
Many existing approaches for unsupervised domain adaptation (UDA) focus on adapting under only data distribution shift and offer limited success under additional cross-domain label distribution shift. Recent work based on self-training using target pseudo-labels has shown promise, but on challenging shifts pseudo-labels may be highly unreliable, and using them for self-training may cause error accumulation and domain misalignment. We propose Selective Entropy Optimization via Committee Consistency (SENTRY), a UDA algorithm that judges the reliability of a target instance based on its predictive consistency under a committee of random image transformations. Our algorithm then selectively minimizes predictive entropy to increase confidence on highly consistent target instances, while maximizing predictive entropy to reduce confidence on highly inconsistent ones. In combination with pseudo-label based approximate target class balancing, our approach leads to significant improvements over the state-of-the-art on 27/31 domain shifts from standard UDA benchmarks as well as benchmarks designed to stress-test adaptation under label distribution shift.