 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGesture-to-Gesture Translation in the Wild via Category-Independent Conditional Maps
Jul 31, 2019
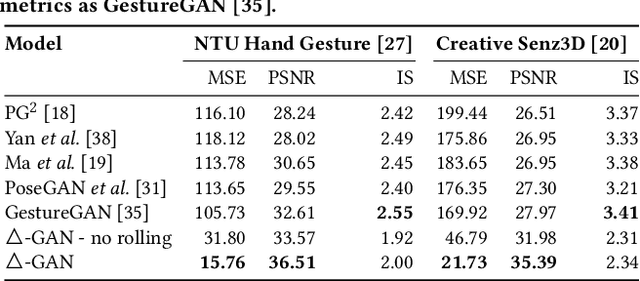
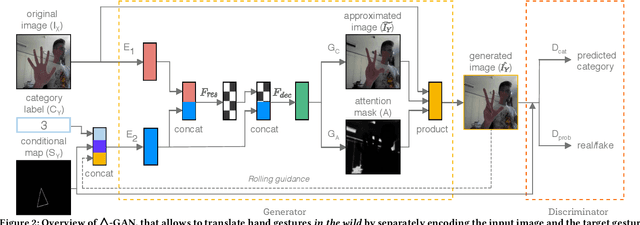
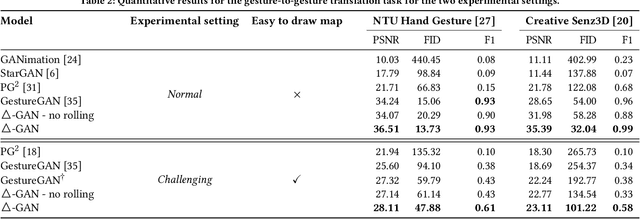
Recent works have shown Generative Adversarial Networks (GANs) to be particularly effective in image-to-image translations. However, in tasks such as body pose and hand gesture translation, existing methods usually require precise annotations, e.g. key-points or skeletons, which are time-consuming to draw. In this work, we propose a novel GAN architecture that decouples the required annotations into a category label - that specifies the gesture type - and a simple-to-draw category-independent conditional map - that expresses the location, rotation and size of the hand gesture. Our architecture synthesizes the target gesture while preserving the background context, thus effectively dealing with gesture translation in the wild. To this aim, we use an attention module and a rolling guidance approach, which loops the generated images back into the network and produces higher quality images compared to competing works. Thus, our GAN learns to generate new images from simple annotations without requiring key-points or skeleton labels. Results on two public datasets show that our method outperforms state of the art approaches both quantitatively and qualitatively. To the best of our knowledge, no work so far has addressed the gesture-to-gesture translation in the wild by requiring user-friendly annotations.
Enhancing Perceptual Attributes with Bayesian Style Generation
Dec 03, 2018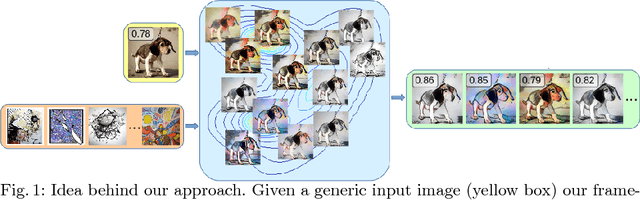

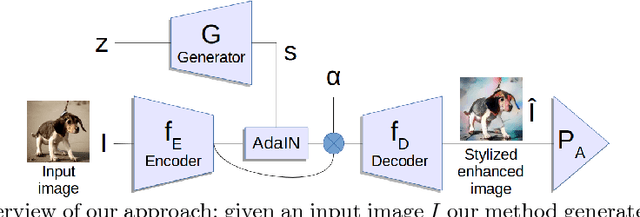
Deep learning has brought an unprecedented progress in computer vision and significant advances have been made in predicting subjective properties inherent to visual data (e.g., memorability, aesthetic quality, evoked emotions, etc.). Recently, some research works have even proposed deep learning approaches to modify images such as to appropriately alter these properties. Following this research line, this paper introduces a novel deep learning framework for synthesizing images in order to enhance a predefined perceptual attribute. Our approach takes as input a natural image and exploits recent models for deep style transfer and generative adversarial networks to change its style in order to modify a specific high-level attribute. Differently from previous works focusing on enhancing a specific property of a visual content, we propose a general framework and demonstrate its effectiveness in two use cases, i.e. increasing image memorability and generating scary pictures. We evaluate the proposed approach on publicly available benchmarks, demonstrating its advantages over state of the art methods.
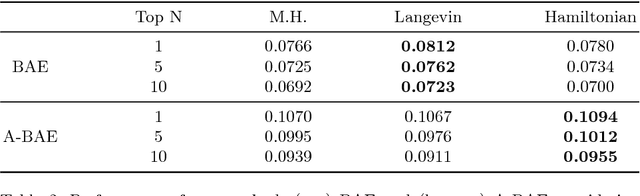
How to Make an Image More Memorable? A Deep Style Transfer Approach
Apr 06, 2017
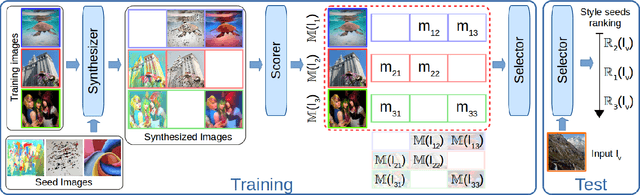
Recent works have shown that it is possible to automatically predict intrinsic image properties like memorability. In this paper, we take a step forward addressing the question: "Can we make an image more memorable?". Methods for automatically increasing image memorability would have an impact in many application fields like education, gaming or advertising. Our work is inspired by the popular editing-by-applying-filters paradigm adopted in photo editing applications, like Instagram and Prisma. In this context, the problem of increasing image memorability maps to that of retrieving "memorabilizing" filters or style "seeds". Still, users generally have to go through most of the available filters before finding the desired solution, thus turning the editing process into a resource and time consuming task. In this work, we show that it is possible to automatically retrieve the best style seeds for a given image, thus remarkably reducing the number of human attempts needed to find a good match. Our approach leverages from recent advances in the field of image synthesis and adopts a deep architecture for generating a memorable picture from a given input image and a style seed. Importantly, to automatically select the best style a novel learning-based solution, also relying on deep models, is proposed. Our experimental evaluation, conducted on publicly available benchmarks, demonstrates the effectiveness of the proposed approach for generating memorable images through automatic style seed selection
Self-Learning Camera: Autonomous Adaptation of Object Detectors to Unlabeled Video Streams
Jun 18, 2014
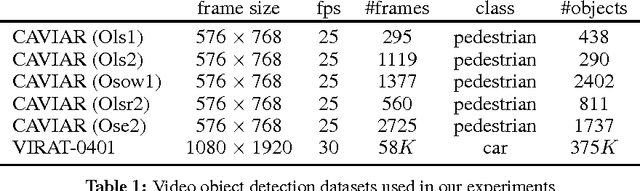

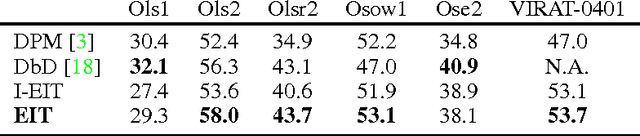
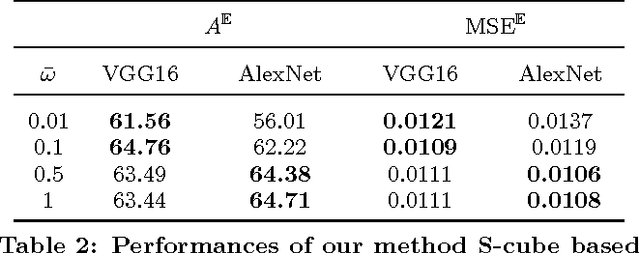
Learning object detectors requires massive amounts of labeled training samples from the specific data source of interest. This is impractical when dealing with many different sources (e.g., in camera networks), or constantly changing ones such as mobile cameras (e.g., in robotics or driving assistant systems). In this paper, we address the problem of self-learning detectors in an autonomous manner, i.e. (i) detectors continuously updating themselves to efficiently adapt to streaming data sources (contrary to transductive algorithms), (ii) without any labeled data strongly related to the target data stream (contrary to self-paced learning), and (iii) without manual intervention to set and update hyper-parameters. To that end, we propose an unsupervised, on-line, and self-tuning learning algorithm to optimize a multi-task learning convex objective. Our method uses confident but laconic oracles (high-precision but low-recall off-the-shelf generic detectors), and exploits the structure of the problem to jointly learn on-line an ensemble of instance-level trackers, from which we derive an adapted category-level object detector. Our approach is validated on real-world publicly available video object datasets.