 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reversible Image Watermarking for Health Informatics Systems Using Distortion Compensation in Wavelet Domain
Feb 21, 2018
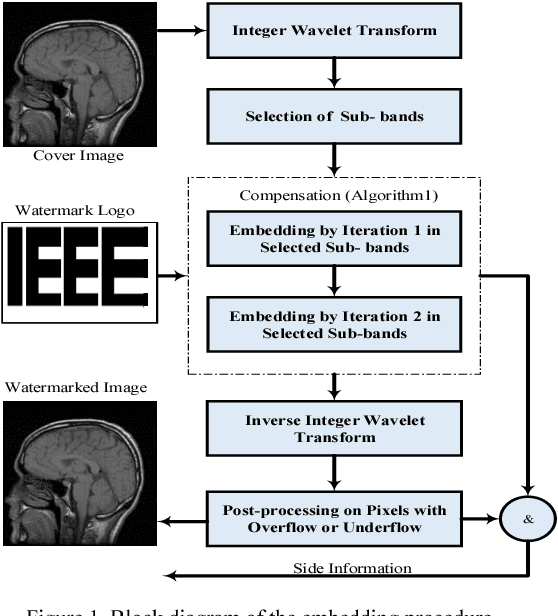
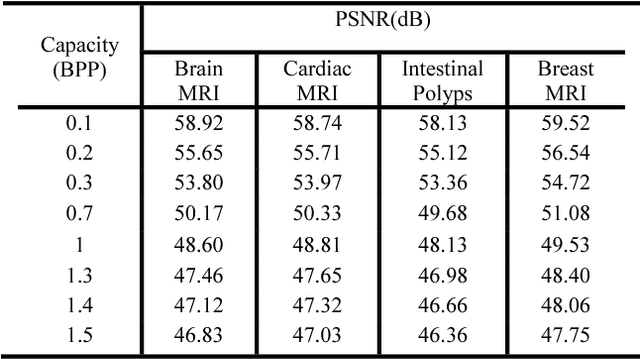
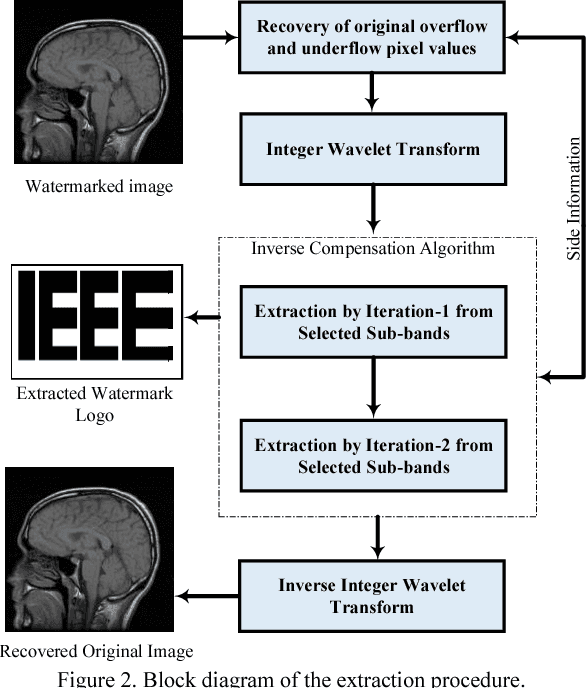
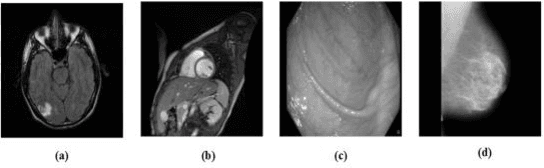
Reversible image watermarking guaranties restoration of both original cover and watermark logo from the watermarked image. Capacity and distortion of the image under reversible watermarking are two important parameters. In this study a reversible watermarking is investigated with focusing on increasing the embedding capacity and reducing the distortion in medical images. Integer wavelet transform is used for embedding where in each iteration, one watermark bit is embedded in one transform coefficient. We devise a novel approach that when a coefficient is modified in an iteration, the produced distortion is compensated in the next iteration. This distortion compensation method would result in low distortion rate. The proposed method is tested on four types of medical images including MRI of brain, cardiac MRI, MRI of breast, and intestinal polyp images. Using a one-level wavelet transform, maximum capacity of 1.5 BPP is obtained. Experimental results demonstrate that the proposed method is superior to the state-of-the-art works in terms of capacity and distortion.
Collaborative Teacher-Student Learning via Multiple Knowledge Transfer
Jan 27, 2021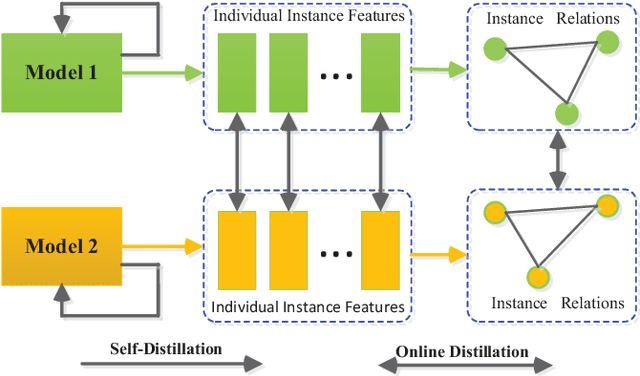

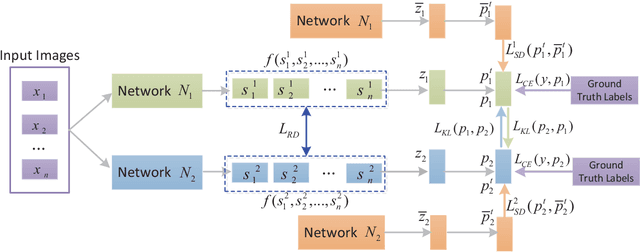
Knowledge distillation (KD), as an efficient and effective model compression technique, has been receiving considerable attention in deep learning. The key to its success is to transfer knowledge from a large teacher network to a small student one. However, most of the existing knowledge distillation methods consider only one type of knowledge learned from either instance features or instance relations via a specific distillation strategy in teacher-student learning. There are few works that explore the idea of transferring different types of knowledge with different distillation strategies in a unified framework. Moreover, the frequently used offline distillation suffers from a limited learning capacity due to the fixed teacher-student architecture. In this paper we propose a collaborative teacher-student learning via multiple knowledge transfer (CTSL-MKT) that prompts both self-learning and collaborative learning. It allows multiple students learn knowledge from both individual instances and instance relations in a collaborative way. While learning from themselves with self-distillation, they can also guide each other via online distillation. The experiments and ablation studies on four image datasets demonstrate that the proposed CTSL-MKT significantly outperforms the state-of-the-art KD methods.
PCB Defect Detection Using Denoising Convolutional Autoencoders
Aug 28, 2020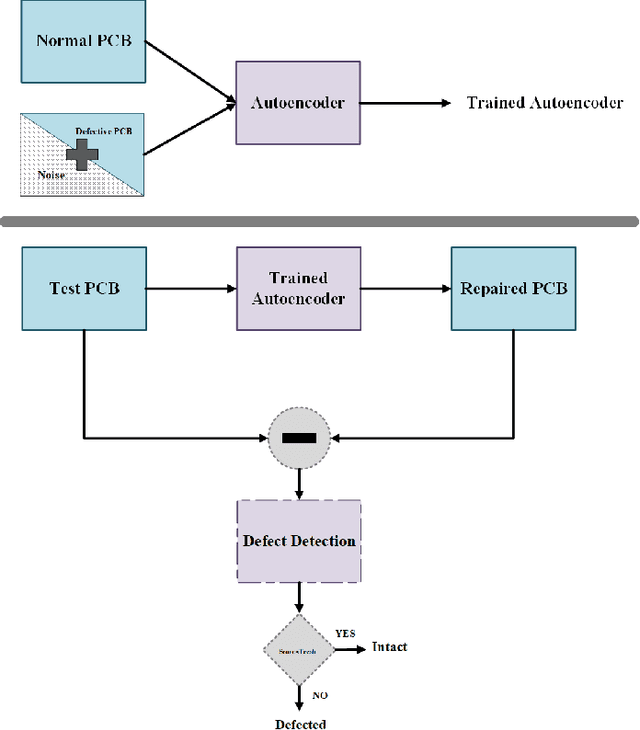
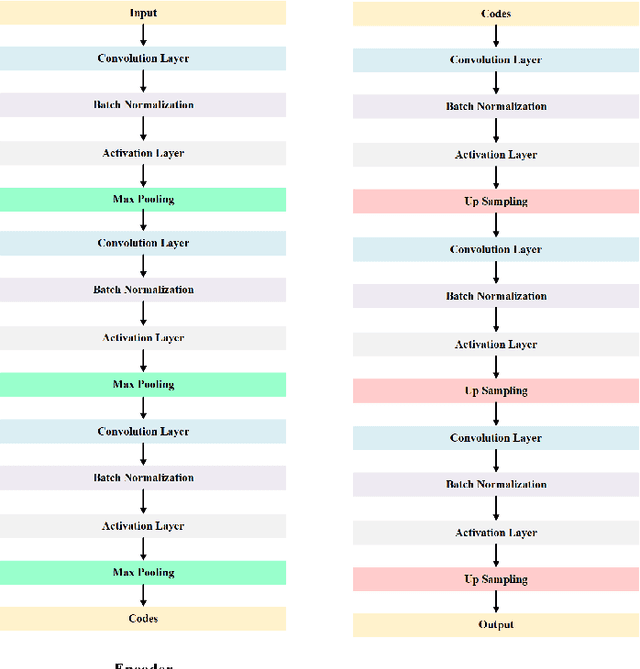

Printed Circuit boards (PCBs) are one of the most important stages in making electronic products. A small defect in PCBs can cause significant flaws in the final product. Hence, detecting all defects in PCBs and locating them is essential. In this paper, we propose an approach based on denoising convolutional autoencoders for detecting defective PCBs and to locate the defects. Denoising autoencoders take a corrupted image and try to recover the intact image. We trained our model with defective PCBs and forced it to repair the defective parts. Our model not only detects all kinds of defects and locates them, but it can also repair them as well. By subtracting the repaired output from the input, the defective parts are located. The experimental results indicate that our model detects the defective PCBs with high accuracy (97.5%) compare to state of the art works.
Learning Spatial-Spectral Prior for Super-Resolution of Hyperspectral Imagery
May 18, 2020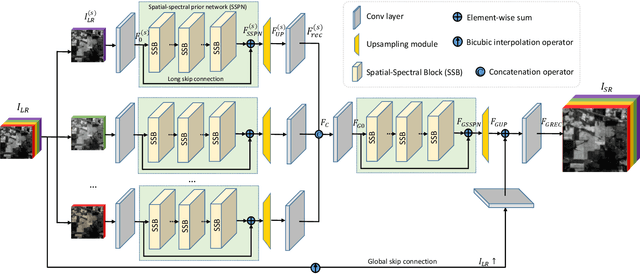
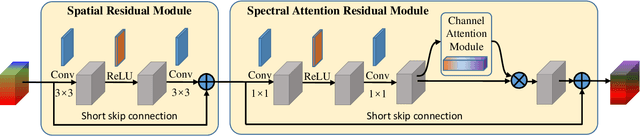


Recently, single gray/RGB image super-resolution reconstruction task has been extensively studied and made significant progress by leveraging the advanced machine learning techniques based on deep convolutional neural networks (DCNNs). However, there has been limited technical development focusing on single hyperspectral image super-resolution due to the high-dimensional and complex spectral patterns in hyperspectral image. In this paper, we make a step forward by investigating how to adapt state-of-the-art residual learning based single gray/RGB image super-resolution approaches for computationally efficient single hyperspectral image super-resolution, referred as SSPSR. Specifically, we introduce a spatial-spectral prior network (SSPN) to fully exploit the spatial information and the correlation between the spectra of the hyperspectral data. Considering that the hyperspectral training samples are scarce and the spectral dimension of hyperspectral image data is very high, it is nontrivial to train a stable and effective deep network. Therefore, a group convolution (with shared network parameters) and progressive upsampling framework is proposed. This will not only alleviate the difficulty in feature extraction due to high-dimension of the hyperspectral data, but also make the training process more stable. To exploit the spatial and spectral prior, we design a spatial-spectral block (SSB), which consists of a spatial residual module and a spectral attention residual module. Experimental results on some hyperspectral images demonstrate that the proposed SSPSR method enhances the details of the recovered high-resolution hyperspectral images, and outperforms state-of-the-arts. The source code is available at \url{https://github.com/junjun-jiang/SSPSR
Image Captioning with Semantic Attention
Mar 12, 2016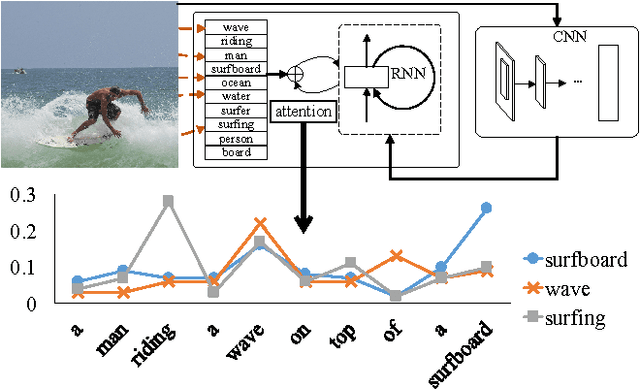
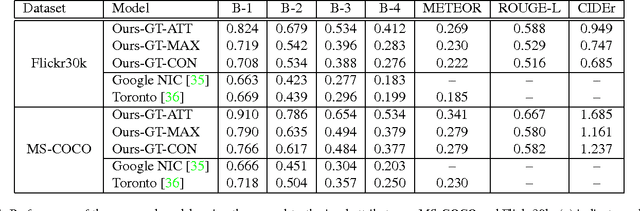
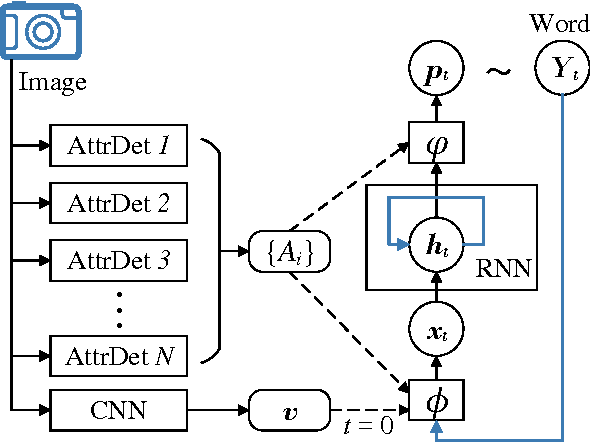
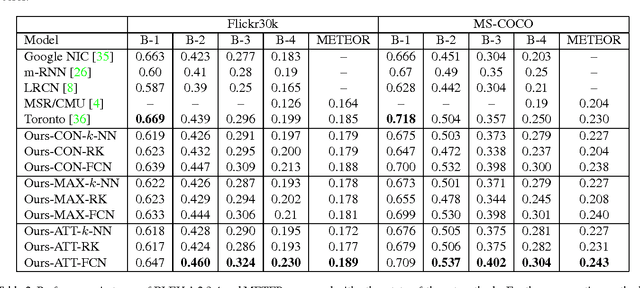
Automatically generating a natural language description of an image has attracted interests recently both because of its importance in practical applications and because it connects two major artificial intelligence fields: computer vision and natural language processing. Existing approaches are either top-down, which start from a gist of an image and convert it into words, or bottom-up, which come up with words describing various aspects of an image and then combine them. In this paper, we propose a new algorithm that combines both approaches through a model of semantic attention. Our algorithm learns to selectively attend to semantic concept proposals and fuse them into hidden states and outputs of recurrent neural networks. The selection and fusion form a feedback connecting the top-down and bottom-up computation. We evaluate our algorithm on two public benchmarks: Microsoft COCO and Flickr30K. Experimental results show that our algorithm significantly outperforms the state-of-the-art approaches consistently across different evaluation metrics.
DLBCL-Morph: Morphological features computed using deep learning for an annotated digital DLBCL image set
Sep 17, 2020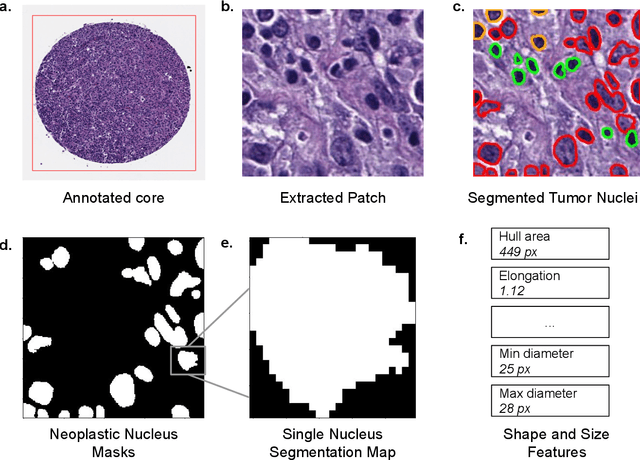
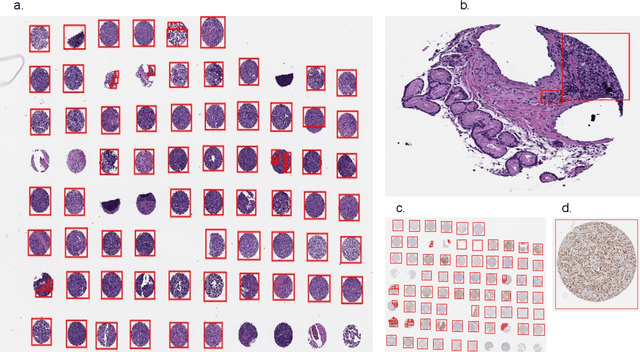
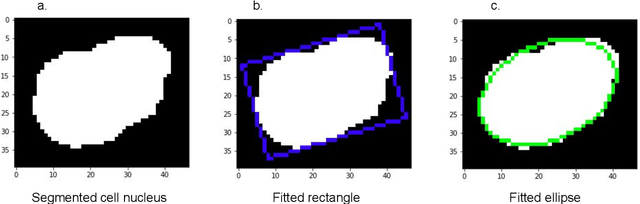
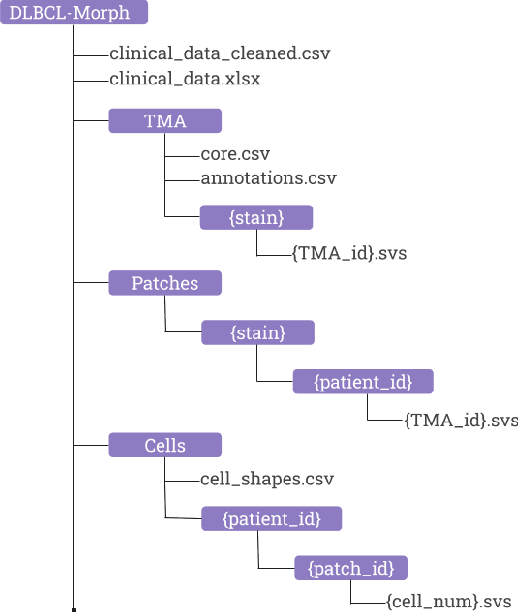
Diffuse Large B-Cell Lymphoma (DLBCL) is the most common non-Hodgkin lymphoma. Though histologically DLBCL shows varying morphologies, no morphologic features have been consistently demonstrated to correlate with prognosis. We present a morphologic analysis of histology sections from 209 DLBCL cases with associated clinical and cytogenetic data. Duplicate tissue core sections were arranged in tissue microarrays (TMAs), and replicate sections were stained with H&E and immunohistochemical stains for CD10, BCL6, MUM1, BCL2, and MYC. The TMAs are accompanied by pathologist-annotated regions-of-interest (ROIs) that identify areas of tissue representative of DLBCL. We used a deep learning model to segment all tumor nuclei in the ROIs, and computed several geometric features for each segmented nucleus. We fit a Cox proportional hazards model to demonstrate the utility of these geometric features in predicting survival outcome, and found that it achieved a C-index (95% CI) of 0.635 (0.574,0.691). Our finding suggests that geometric features computed from tumor nuclei are of prognostic importance, and should be validated in prospective studies.
Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding
Nov 04, 2020
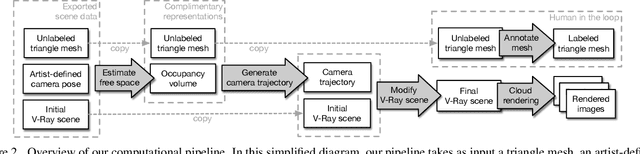

For many fundamental scene understanding tasks, it is difficult or impossible to obtain per-pixel ground truth labels from real images. We address this challenge by introducing Hypersim, a photorealistic synthetic dataset for holistic indoor scene understanding. To create our dataset, we leverage a large repository of synthetic scenes created by professional artists, and we generate 77,400 images of 461 indoor scenes with detailed per-pixel labels and corresponding ground truth geometry. Our dataset: (1) relies exclusively on publicly available 3D assets; (2) includes complete scene geometry, material information, and lighting information for every scene; (3) includes dense per-pixel semantic instance segmentations for every image; and (4) factors every image into diffuse reflectance, diffuse illumination, and a non-diffuse residual term that captures view-dependent lighting effects. Together, these features make our dataset well-suited for geometric learning problems that require direct 3D supervision, multi-task learning problems that require reasoning jointly over multiple input and output modalities, and inverse rendering problems. We analyze our dataset at the level of scenes, objects, and pixels, and we analyze costs in terms of money, annotation effort, and computation time. Remarkably, we find that it is possible to generate our entire dataset from scratch, for roughly half the cost of training a state-of-the-art natural language processing model. All the code we used to generate our dataset will be made available online.
Joint Generative Learning and Super-Resolution For Real-World Camera-Screen Degradation
Sep 14, 2020



In real-world single image super-resolution (SISR) task, the low-resolution image suffers more complicated degradations, not only downsampled by unknown kernels. However, existing SISR methods are generally studied with the synthetic low-resolution generation such as bicubic interpolation (BI), which greatly limits their performance. Recently, some researchers investigate real-world SISR from the perspective of the camera and smartphone. However, except the acquisition equipment, the display device also involves more complicated degradations. In this paper, we focus on the camera-screen degradation and build a real-world dataset (Cam-ScreenSR), where HR images are original ground truths from the previous DIV2K dataset and corresponding LR images are camera-captured versions of HRs displayed on the screen. We conduct extensive experiments to demonstrate that involving more real degradations is positive to improve the generalization of SISR models. Moreover, we propose a joint two-stage model. Firstly, the downsampling degradation GAN(DD-GAN) is trained to model the degradation and produces more various of LR images, which is validated to be efficient for data augmentation. Then the dual residual channel attention network (DuRCAN) learns to recover the SR image. The weighted combination of L1 loss and proposed Laplacian loss are applied to sharpen the high-frequency edges. Extensive experimental results in both typical synthetic and complicated real-world degradations validate the proposed method outperforms than existing SOTA models with less parameters, faster speed and better visual results. Moreover, in real captured photographs, our model also delivers best visual quality with sharper edge, less artifacts, especially appropriate color enhancement, which has not been accomplished by previous methods.
Recent Advances in the Applications of Convolutional Neural Networks to Medical Image Contour Detection
Aug 24, 2017
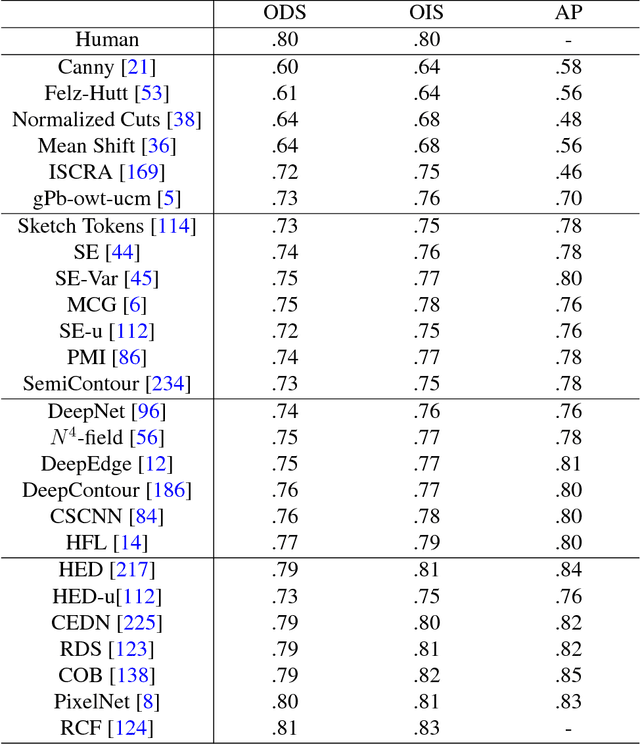
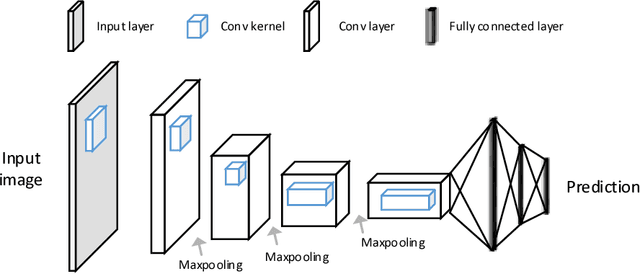
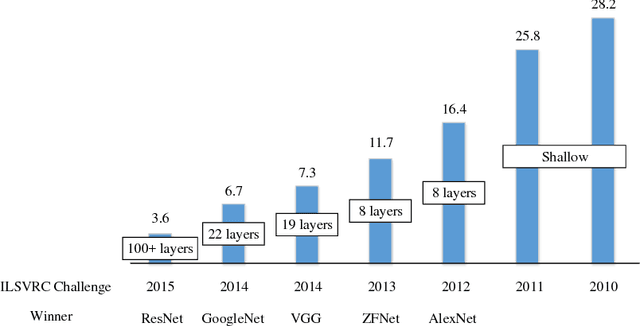
The fast growing deep learning technologies have become the main solution of many machine learning problems for medical image analysis. Deep convolution neural networks (CNNs), as one of the most important branch of the deep learning family, have been widely investigated for various computer-aided diagnosis tasks including long-term problems and continuously emerging new problems. Image contour detection is a fundamental but challenging task that has been studied for more than four decades. Recently, we have witnessed the significantly improved performance of contour detection thanks to the development of CNNs. Beyond purusing performance in existing natural image benchmarks, contour detection plays a particularly important role in medical image analysis. Segmenting various objects from radiology images or pathology images requires accurate detection of contours. However, some problems, such as discontinuity and shape constraints, are insufficiently studied in CNNs. It is necessary to clarify the challenges to encourage further exploration. The performance of CNN based contour detection relies on the state-of-the-art CNN architectures. Careful investigation of their design principles and motivations is critical and beneficial to contour detection. In this paper, we first review recent development of medical image contour detection and point out the current confronting challenges and problems. We discuss the development of general CNNs and their applications in image contours (or edges) detection. We compare those methods in detail, clarify their strengthens and weaknesses. Then we review their recent applications in medical image analysis and point out limitations, with the goal to light some potential directions in medical image analysis. We expect the paper to cover comprehensive technical ingredients of advanced CNNs to enrich the study in the medical image domain.
RCoNet: Deformable Mutual Information Maximization and High-order Uncertainty-aware Learning for Robust COVID-19 Detection
Feb 22, 2021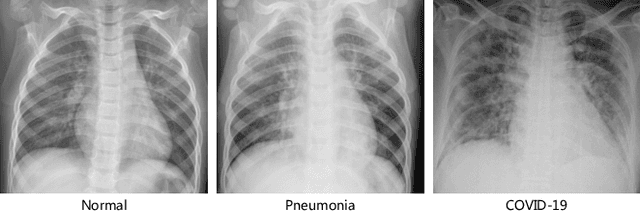
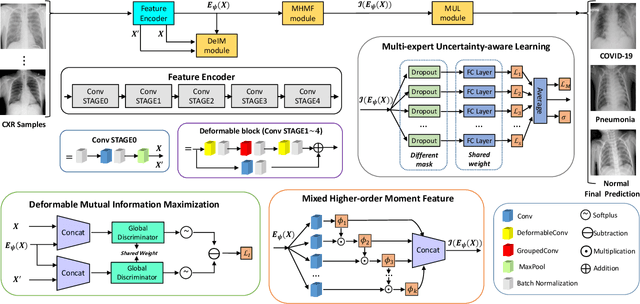
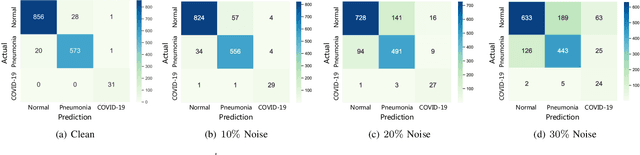
The novel 2019 Coronavirus (COVID-19) infection has spread world widely and is currently a major healthcare challenge around the world. Chest Computed Tomography (CT) and X-ray images have been well recognized to be two effective techniques for clinical COVID-19 disease diagnoses. Due to faster imaging time and considerably lower cost than CT, detecting COVID-19 in chest X-ray (CXR) images is preferred for efficient diagnosis, assessment and treatment. However, considering the similarity between COVID-19 and pneumonia, CXR samples with deep features distributed near category boundaries are easily misclassified by the hyper-planes learned from limited training data. Moreover, most existing approaches for COVID-19 detection focus on the accuracy of prediction and overlook the uncertainty estimation, which is particularly important when dealing with noisy datasets. To alleviate these concerns, we propose a novel deep network named {\em RCoNet$^k_s$} for robust COVID-19 detection which employs {\em Deformable Mutual Information Maximization} (DeIM), {\em Mixed High-order Moment Feature} (MHMF) and {\em Multi-expert Uncertainty-aware Learning} (MUL). With DeIM, the mutual information (MI) between input data and the corresponding latent representations can be well estimated and maximized to capture compact and disentangled representational characteristics. Meanwhile, MHMF can fully explore the benefits of using high-order statistics and extract discriminative features of complex distributions in medical imaging. Finally, MUL creates multiple parallel dropout networks for each CXR image to evaluate uncertainty and thus prevent performance degradation caused by the noise in the data.