 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEBNAS: Strengthening Exit Branches in Early-Exit Networks through Hardware-Aware Neural Architecture Search
Dec 11, 2025Early-exit networks are effective solutions for reducing the overall energy consumption and latency of deep learning models by adjusting computation based on the complexity of input data. By incorporating intermediate exit branches into the architecture, they provide less computation for simpler samples, which is particularly beneficial for resource-constrained devices where energy consumption is crucial. However, designing early-exit networks is a challenging and time-consuming process due to the need to balance efficiency and performance. Recent works have utilized Neural Architecture Search (NAS) to design more efficient early-exit networks, aiming to reduce average latency while improving model accuracy by determining the best positions and number of exit branches in the architecture. Another important factor affecting the efficiency and accuracy of early-exit networks is the depth and types of layers in the exit branches. In this paper, we use hardware-aware NAS to strengthen exit branches, considering both accuracy and efficiency during optimization. Our performance evaluation on the CIFAR-10, CIFAR-100, and SVHN datasets demonstrates that our proposed framework, which considers varying depths and layers for exit branches along with adaptive threshold tuning, designs early-exit networks that achieve higher accuracy with the same or lower average number of MACs compared to the state-of-the-art approaches.
FedCode: Communication-Efficient Federated Learning via Transferring Codebooks
Nov 15, 2023Federated Learning (FL) is a distributed machine learning paradigm that enables learning models from decentralized local data. While FL offers appealing properties for clients' data privacy, it imposes high communication burdens for exchanging model weights between a server and the clients. Existing approaches rely on model compression techniques, such as pruning and weight clustering to tackle this. However, transmitting the entire set of weight updates at each federated round, even in a compressed format, limits the potential for a substantial reduction in communication volume. We propose FedCode where clients transmit only codebooks, i.e., the cluster centers of updated model weight values. To ensure a smooth learning curve and proper calibration of clusters between the server and the clients, FedCode periodically transfers model weights after multiple rounds of solely communicating codebooks. This results in a significant reduction in communication volume between clients and the server in both directions, without imposing significant computational overhead on the clients or leading to major performance degradation of the models. We evaluate the effectiveness of FedCode using various publicly available datasets with ResNet-20 and MobileNet backbone model architectures. Our evaluations demonstrate a 12.2-fold data transmission reduction on average while maintaining a comparable model performance with an average accuracy loss of 1.3% compared to FedAvg. Further validation of FedCode performance under non-IID data distributions showcased an average accuracy loss of 2.0% compared to FedAvg while achieving approximately a 12.7-fold data transmission reduction.
PCB Defect Detection Using Denoising Convolutional Autoencoders
Aug 28, 2020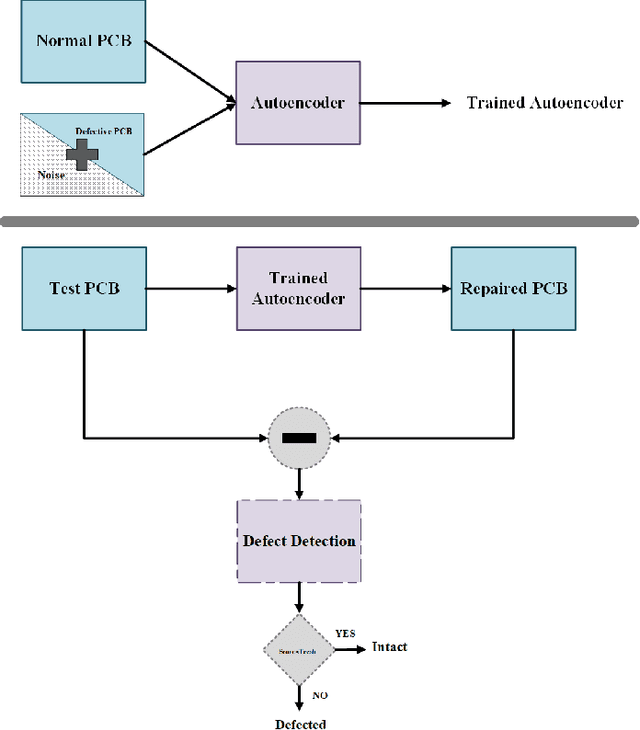
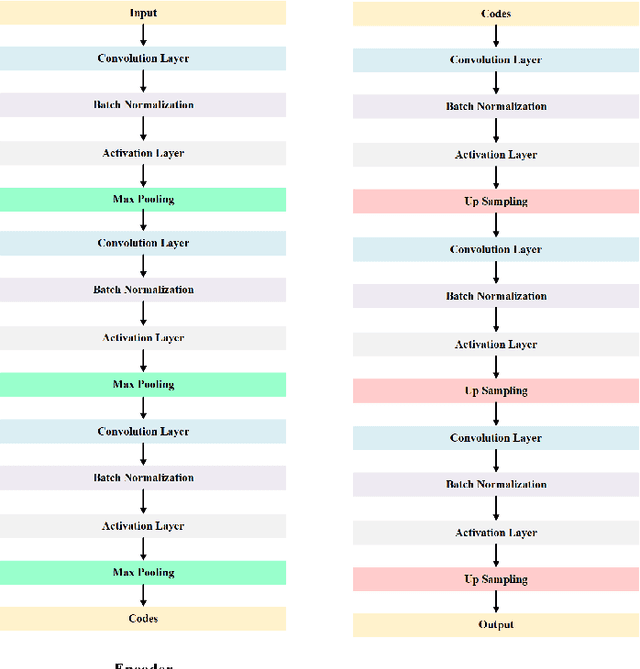

Printed Circuit boards (PCBs) are one of the most important stages in making electronic products. A small defect in PCBs can cause significant flaws in the final product. Hence, detecting all defects in PCBs and locating them is essential. In this paper, we propose an approach based on denoising convolutional autoencoders for detecting defective PCBs and to locate the defects. Denoising autoencoders take a corrupted image and try to recover the intact image. We trained our model with defective PCBs and forced it to repair the defective parts. Our model not only detects all kinds of defects and locates them, but it can also repair them as well. By subtracting the repaired output from the input, the defective parts are located. The experimental results indicate that our model detects the defective PCBs with high accuracy (97.5%) compare to state of the art works.