 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Feature Interpolation for Image Content Changes
Jun 19, 2017

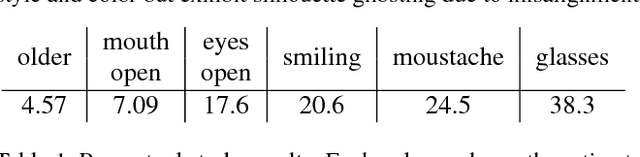

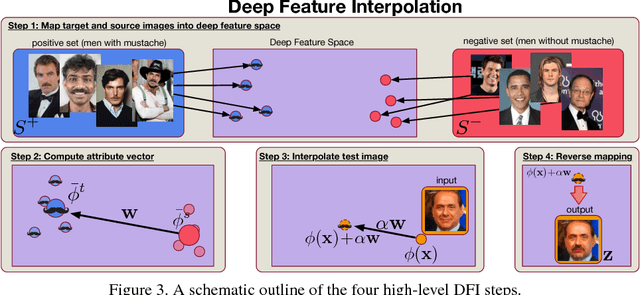
We propose Deep Feature Interpolation (DFI), a new data-driven baseline for automatic high-resolution image transformation. As the name suggests, it relies only on simple linear interpolation of deep convolutional features from pre-trained convnets. We show that despite its simplicity, DFI can perform high-level semantic transformations like "make older/younger", "make bespectacled", "add smile", among others, surprisingly well - sometimes even matching or outperforming the state-of-the-art. This is particularly unexpected as DFI requires no specialized network architecture or even any deep network to be trained for these tasks. DFI therefore can be used as a new baseline to evaluate more complex algorithms and provides a practical answer to the question of which image transformation tasks are still challenging in the rise of deep learning.
Discovering Pattern Structure Using Differentiable Compositing
Oct 17, 2020

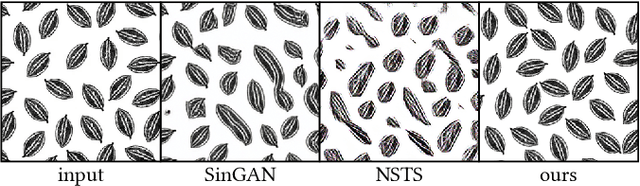
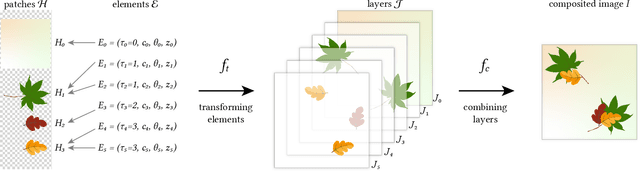
Patterns, which are collections of elements arranged in regular or near-regular arrangements, are an important graphic art form and widely used due to their elegant simplicity and aesthetic appeal. When a pattern is encoded as a flat image without the underlying structure, manually editing the pattern is tedious and challenging as one has to both preserve the individual element shapes and their original relative arrangements. State-of-the-art deep learning frameworks that operate at the pixel level are unsuitable for manipulating such patterns. Specifically, these methods can easily disturb the shapes of the individual elements or their arrangement, and thus fail to preserve the latent structures of the input patterns. We present a novel differentiable compositing operator using pattern elements and use it to discover structures, in the form of a layered representation of graphical objects, directly from raw pattern images. This operator allows us to adapt current deep learning based image methods to effectively handle patterns. We evaluate our method on a range of patterns and demonstrate superiority in the context of pattern manipulations when compared against state-of-the-art
Clue: Cross-modal Coherence Modeling for Caption Generation
May 02, 2020


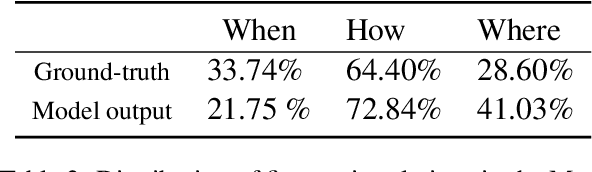
We use coherence relations inspired by computational models of discourse to study the information needs and goals of image captioning. Using an annotation protocol specifically devised for capturing image--caption coherence relations, we annotate 10,000 instances from publicly-available image--caption pairs. We introduce a new task for learning inferences in imagery and text, coherence relation prediction, and show that these coherence annotations can be exploited to learn relation classifiers as an intermediary step, and also train coherence-aware, controllable image captioning models. The results show a dramatic improvement in the consistency and quality of the generated captions with respect to information needs specified via coherence relations.
Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation
Mar 12, 2021
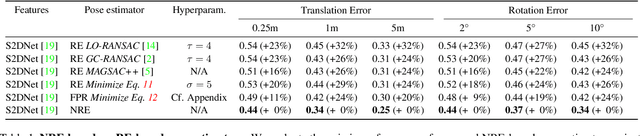
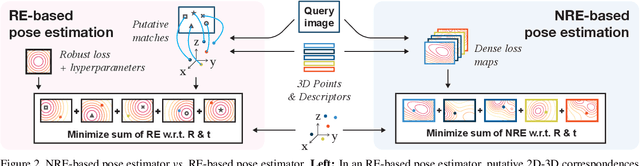
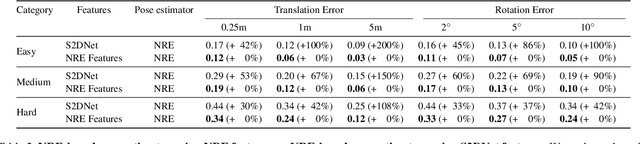
Absolute camera pose estimation is usually addressed by sequentially solving two distinct subproblems: First a feature matching problem that seeks to establish putative 2D-3D correspondences, and then a Perspective-n-Point problem that minimizes, with respect to the camera pose, the sum of so-called Reprojection Errors (RE). We argue that generating putative 2D-3D correspondences 1) leads to an important loss of information that needs to be compensated as far as possible, within RE, through the choice of a robust loss and the tuning of its hyperparameters and 2) may lead to an RE that conveys erroneous data to the pose estimator. In this paper, we introduce the Neural Reprojection Error (NRE) as a substitute for RE. NRE allows to rethink the camera pose estimation problem by merging it with the feature learning problem, hence leveraging richer information than 2D-3D correspondences and eliminating the need for choosing a robust loss and its hyperparameters. Thus NRE can be used as training loss to learn image descriptors tailored for pose estimation. We also propose a coarse-to-fine optimization method able to very efficiently minimize a sum of NRE terms with respect to the camera pose. We experimentally demonstrate that NRE is a good substitute for RE as it significantly improves both the robustness and the accuracy of the camera pose estimate while being computationally and memory highly efficient. From a broader point of view, we believe this new way of merging deep learning and 3D geometry may be useful in other computer vision applications.
Recurrent Neural Networks to Correct Satellite Image Classification Maps
Apr 21, 2017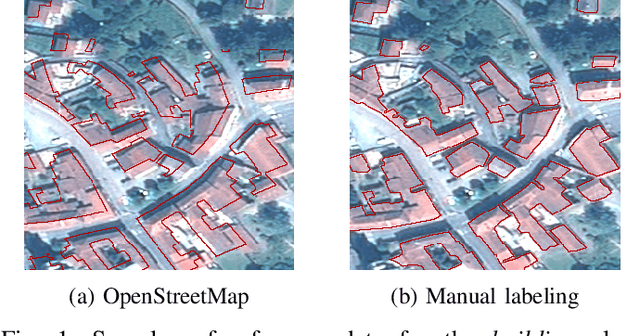

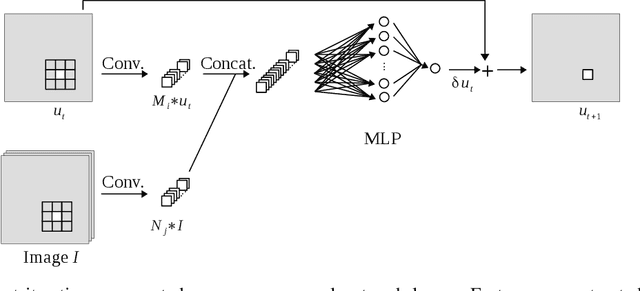

While initially devised for image categorization, convolutional neural networks (CNNs) are being increasingly used for the pixelwise semantic labeling of images. However, the proper nature of the most common CNN architectures makes them good at recognizing but poor at localizing objects precisely. This problem is magnified in the context of aerial and satellite image labeling, where a spatially fine object outlining is of paramount importance. Different iterative enhancement algorithms have been presented in the literature to progressively improve the coarse CNN outputs, seeking to sharpen object boundaries around real image edges. However, one must carefully design, choose and tune such algorithms. Instead, our goal is to directly learn the iterative process itself. For this, we formulate a generic iterative enhancement process inspired from partial differential equations, and observe that it can be expressed as a recurrent neural network (RNN). Consequently, we train such a network from manually labeled data for our enhancement task. In a series of experiments we show that our RNN effectively learns an iterative process that significantly improves the quality of satellite image classification maps.
PPGN: Phrase-Guided Proposal Generation Network For Referring Expression Comprehension
Dec 20, 2020
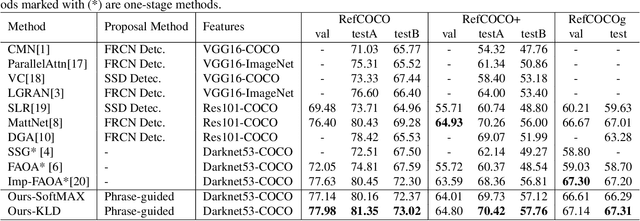
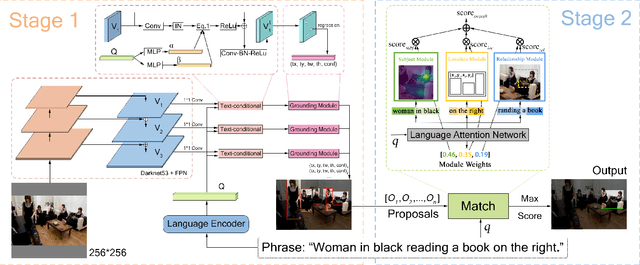
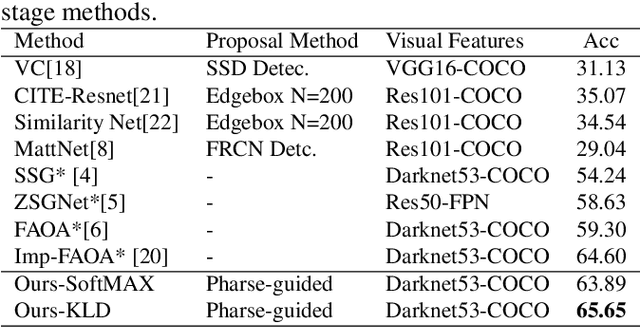
Reference expression comprehension (REC) aims to find the location that the phrase refer to in a given image. Proposal generation and proposal representation are two effective techniques in many two-stage REC methods. However, most of the existing works only focus on proposal representation and neglect the importance of proposal generation. As a result, the low-quality proposals generated by these methods become the performance bottleneck in REC tasks. In this paper, we reconsider the problem of proposal generation, and propose a novel phrase-guided proposal generation network (PPGN). The main implementation principle of PPGN is refining visual features with text and generate proposals through regression. Experiments show that our method is effective and achieve SOTA performance in benchmark datasets.
Universal Adversarial Perturbations Against Semantic Image Segmentation
Jul 31, 2017



While deep learning is remarkably successful on perceptual tasks, it was also shown to be vulnerable to adversarial perturbations of the input. These perturbations denote noise added to the input that was generated specifically to fool the system while being quasi-imperceptible for humans. More severely, there even exist universal perturbations that are input-agnostic but fool the network on the majority of inputs. While recent work has focused on image classification, this work proposes attacks against semantic image segmentation: we present an approach for generating (universal) adversarial perturbations that make the network yield a desired target segmentation as output. We show empirically that there exist barely perceptible universal noise patterns which result in nearly the same predicted segmentation for arbitrary inputs. Furthermore, we also show the existence of universal noise which removes a target class (e.g., all pedestrians) from the segmentation while leaving the segmentation mostly unchanged otherwise.
Depth-Adapted CNN for RGB-D cameras
Sep 23, 2020
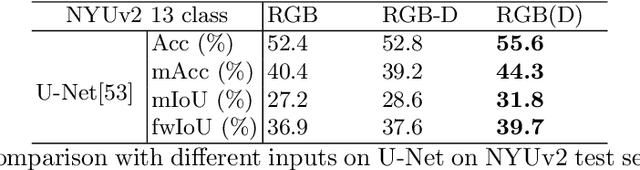
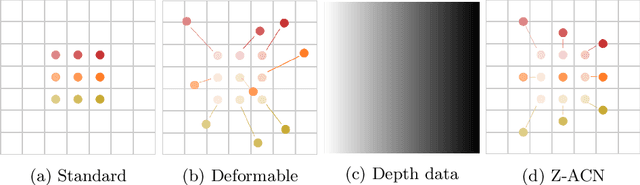
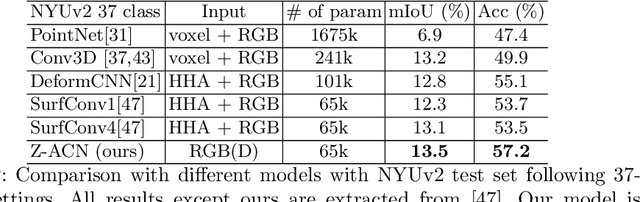
Conventional 2D Convolutional Neural Networks (CNN) extract features from an input image by applying linear filters. These filters compute the spatial coherence by weighting the photometric information on a fixed neighborhood without taking into account the geometric information. We tackle the problem of improving the classical RGB CNN methods by using the depth information provided by the RGB-D cameras. State-of-the-art approaches use depth as an additional channel or image (HHA) or pass from 2D CNN to 3D CNN. This paper proposes a novel and generic procedure to articulate both photometric and geometric information in CNN architecture. The depth data is represented as a 2D offset to adapt spatial sampling locations. The new model presented is invariant to scale and rotation around the X and the Y axis of the camera coordinate system. Moreover, when depth data is constant, our model is equivalent to a regular CNN. Experiments of benchmarks validate the effectiveness of our model.
Beyond the Deep Metric Learning: Enhance the Cross-Modal Matching with Adversarial Discriminative Domain Regularization
Oct 27, 2020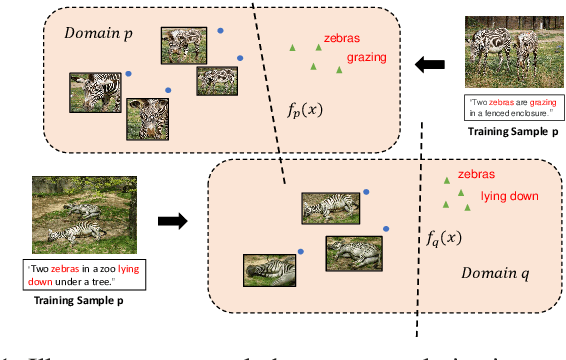
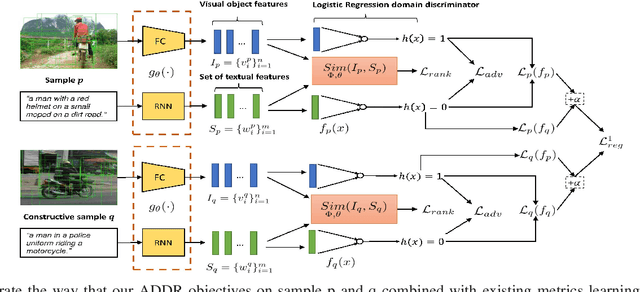
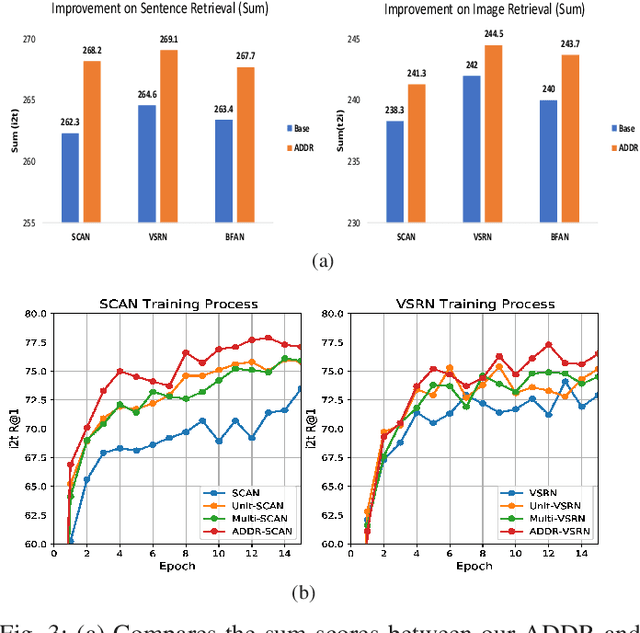

Matching information across image and text modalities is a fundamental challenge for many applications that involve both vision and natural language processing. The objective is to find efficient similarity metrics to compare the similarity between visual and textual information. Existing approaches mainly match the local visual objects and the sentence words in a shared space with attention mechanisms. The matching performance is still limited because the similarity computation is based on simple comparisons of the matching features, ignoring the characteristics of their distribution in the data. In this paper, we address this limitation with an efficient learning objective that considers the discriminative feature distributions between the visual objects and sentence words. Specifically, we propose a novel Adversarial Discriminative Domain Regularization (ADDR) learning framework, beyond the paradigm metric learning objective, to construct a set of discriminative data domains within each image-text pairs. Our approach can generally improve the learning efficiency and the performance of existing metrics learning frameworks by regulating the distribution of the hidden space between the matching pairs. The experimental results show that this new approach significantly improves the overall performance of several popular cross-modal matching techniques (SCAN, VSRN, BFAN) on the MS-COCO and Flickr30K benchmarks.
Scale Optimization for Full-Image-CNN Vehicle Detection
Feb 20, 2018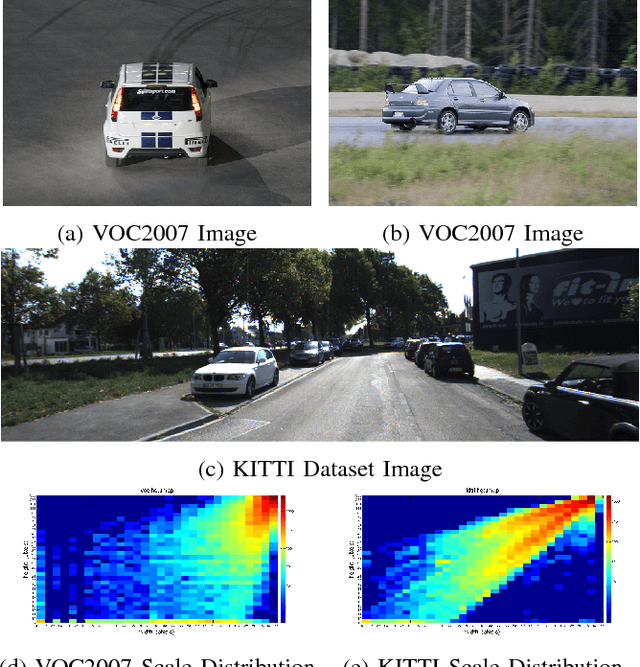
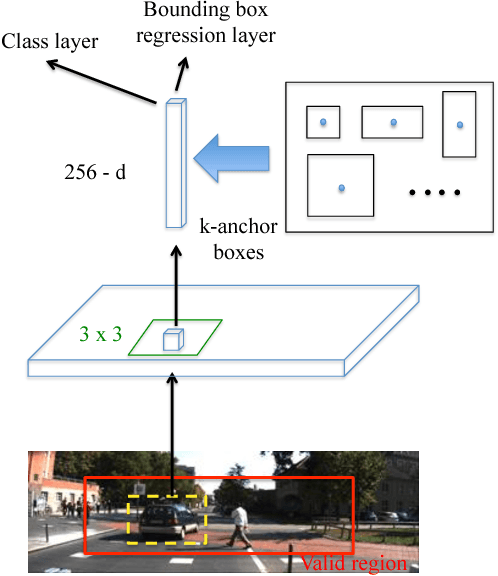
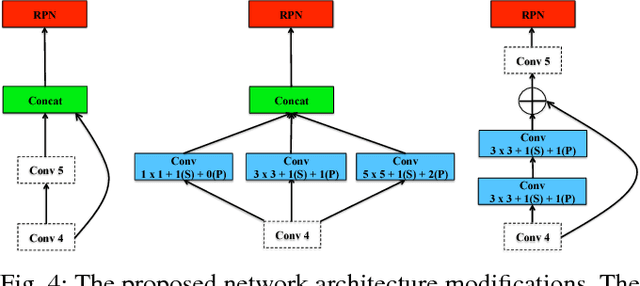
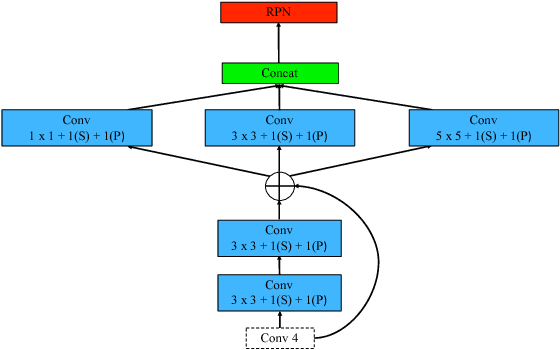
Many state-of-the-art general object detection methods make use of shared full-image convolutional features (as in Faster R-CNN). This achieves a reasonable test-phase computation time while enjoys the discriminative power provided by large Convolutional Neural Network (CNN) models. Such designs excel on benchmarks which contain natural images but which have very unnatural distributions, i.e. they have an unnaturally high-frequency of the target classes and a bias towards a "friendly" or "dominant" object scale. In this paper we present further study of the use and adaptation of the Faster R-CNN object detection method for datasets presenting natural scale distribution and unbiased real-world object frequency. In particular, we show that better alignment of the detector scale sensitivity to the extant distribution improves vehicle detection performance. We do this by modifying both the selection of Region Proposals, and through using more scale-appropriate full-image convolution features within the CNN model. By selecting better scales in the region proposal input and by combining feature maps through careful design of the convolutional neural network, we improve performance on smaller objects. We significantly increase detection AP for the KITTI dataset car class from 76.3% on our baseline Faster R-CNN detector to 83.6% in our improved detector.