 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillDAG: Self-Evolving Typed Skill Graphs for LLM Skill Selection at Scale
Jun 02, 2026As LLM agents adopt large skill libraries, selecting the right subset becomes a structural problem rather than a similarity-matching one: skills depend on, conflict with, specialize, or duplicate one another, a structure invisible to both full enumeration and embedding similarity. We present SkillDAG, which models inter-skill relationships as a typed directed graph and exposes it to an LLM agent as an inference-time, agent-callable structural retrieval interface, queried and evolved during execution rather than baked into a fixed retrieval pipeline: each search returns vector matches, typed-edge neighbors, and conflict signals, and a propose-then-commit protocol lets the agent register execution-backed edges so the graph accumulates structure across episodes. On ALFWorld and SkillsBench with MiniMax-M2.7, SkillDAG reaches 67.1% success and 27.3% reward, exceeding the strongest reported Graph-of-Skills baseline by +12.8 and +8.6 points; the advantage ports to gpt-5.2-codex, and intrinsic SkillsBench Ret@K rises from 65.5 to 78.2 under matched queries. These gains trace to isolable mechanisms: candidate ranking that stays robust as the pool grows 10x where a fixed seeding-diffusion pipeline degrades, and set-monotone online edits that enlarge ground-truth recall without evicting prior hits.
Unlocking the Black Box of Latent Reasoning: An Interpretability-Guided Approach to Intervention
May 31, 2026Latent reasoning enables Large Language Models (LLMs) to perform multi-step inference within continuous hidden states, offering efficiency gains over explicit Chain-of-Thought (CoT). However, the opacity of these continuous thought vectors hinders their reliability and controllability. This paper bridges the gap between mechanistic interpretability and actionable control. We first present a systematic analysis using structural, causal, and geometric probes, revealing that latent vectors encode compressed, faithful representations of reasoning steps, with early vectors acting as critical causal hubs. Building on this, we operationalize these interpretability insights into a suite of training-free, decode-time interventions that refine the latent reasoning process by imposing the identified geometric and semantic priors. Extensive experiments across multiple model scales and diverse task domains demonstrate that our approaches consistently improve reasoning accuracy. Our interpretability-guided interventions consistently unlock latent capabilities and improve reasoning accuracy without any parameter updates.
SAGE: Semantic-Aware Shared Sampling for Efficient Diffusion
Sep 19, 2025Diffusion models manifest evident benefits across diverse domains, yet their high sampling cost, requiring dozens of sequential model evaluations, remains a major limitation. Prior efforts mainly accelerate sampling via optimized solvers or distillation, which treat each query independently. In contrast, we reduce total number of steps by sharing early-stage sampling across semantically similar queries. To enable such efficiency gains without sacrificing quality, we propose SAGE, a semantic-aware shared sampling framework that integrates a shared sampling scheme for efficiency and a tailored training strategy for quality preservation. Extensive experiments show that SAGE reduces sampling cost by 25.5%, while improving generation quality with 5.0% lower FID, 5.4% higher CLIP, and 160% higher diversity over baselines.
Empowering Mobile Edge Computing by Exploiting Reconfigurable Intelligent Surface
Feb 04, 2021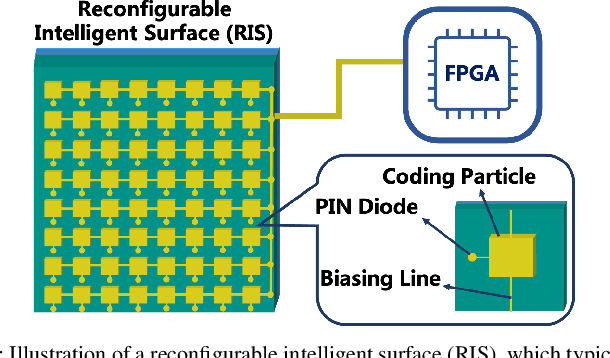
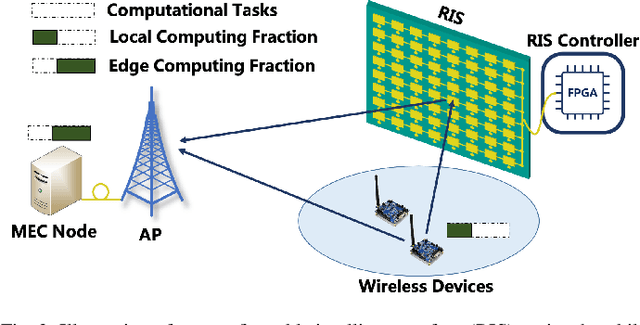
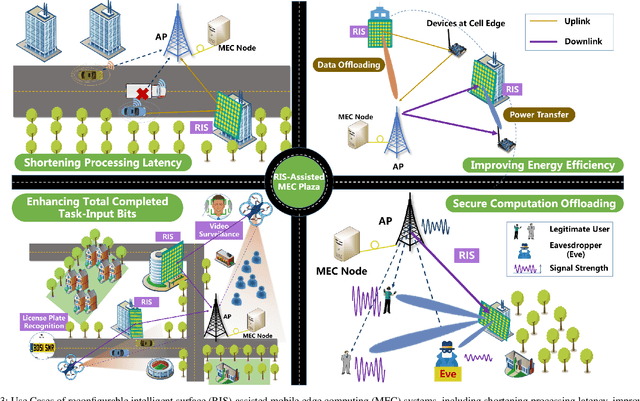
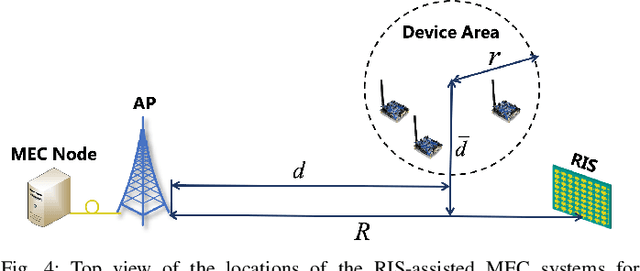
Along with the proliferation of sensors and of smart devices, an explosive volume of data will be generated. However, restricted by their limited physical sizes and low manufacturing costs, these wireless devices are typically equipped with limited computational capabilities and battery lives and thus incapable of processing data time-efficiently. To overcome this issue, the paradigm of mobile edge computing (MEC) is proposed, where wireless devices may offload all or a fraction of their computation tasks to their nearby computing nodes deployed at the network edge. At the time of writing, the benefits of MEC systems have not been fully exploited, predominately because the computation offloading link is still far from the perfect. In this article, we propose to empower the MEC systems by exploiting the emerging technique of reconfigurable intelligent surfaces, which is capable of reconfiguring the wireless propagation environments and hence of enhancing the offloading links. The beneficial role of RISs can be exploited by jointly optimizing both the RISs as well as communications and computing resource allocations of MEC systems, which imposes new research challenges on the systemic design and thus necessitates a specific investigation. Against this background, this article provides an overview of RIS-assisted MEC systems and highlights their four use cases as well as their design challenges and solutions. Then their advantageous performance is validated with the aid of a specific case study. Finally, a guide on future research opportunities is elucidated.
Scale Optimization for Full-Image-CNN Vehicle Detection
Feb 20, 2018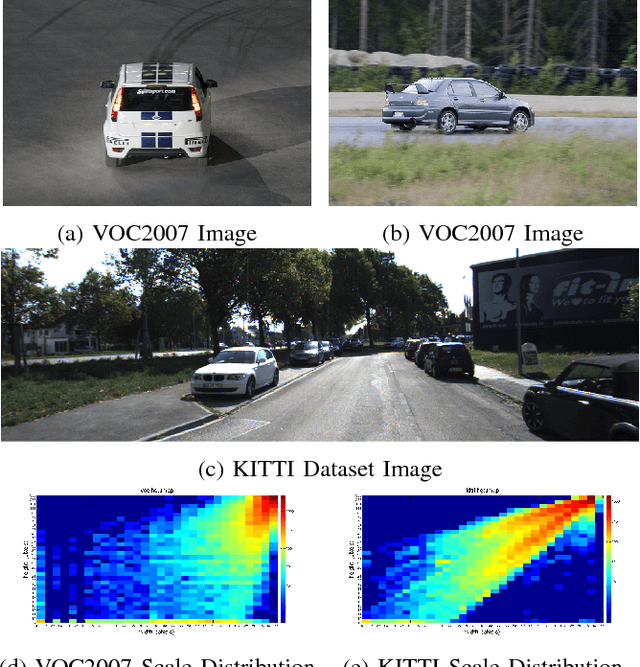
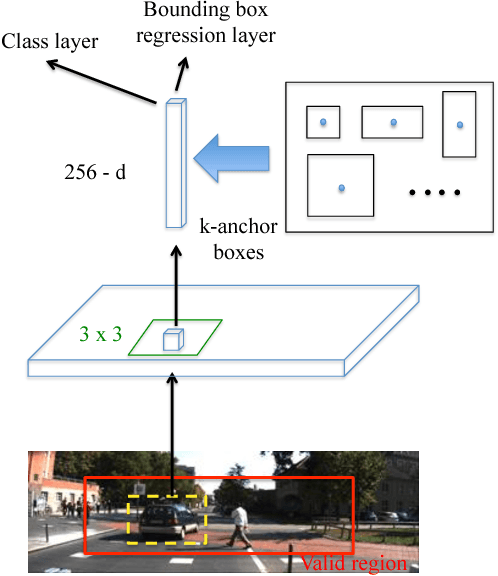
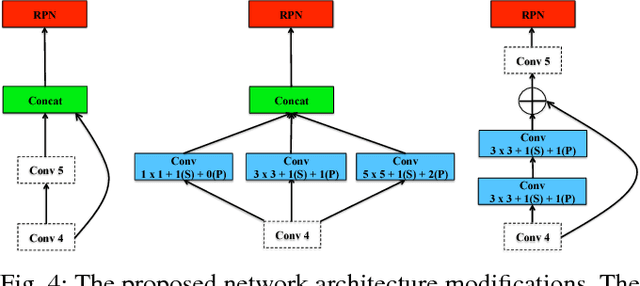
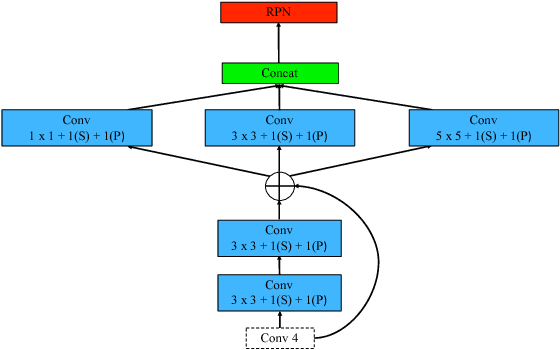
Many state-of-the-art general object detection methods make use of shared full-image convolutional features (as in Faster R-CNN). This achieves a reasonable test-phase computation time while enjoys the discriminative power provided by large Convolutional Neural Network (CNN) models. Such designs excel on benchmarks which contain natural images but which have very unnatural distributions, i.e. they have an unnaturally high-frequency of the target classes and a bias towards a "friendly" or "dominant" object scale. In this paper we present further study of the use and adaptation of the Faster R-CNN object detection method for datasets presenting natural scale distribution and unbiased real-world object frequency. In particular, we show that better alignment of the detector scale sensitivity to the extant distribution improves vehicle detection performance. We do this by modifying both the selection of Region Proposals, and through using more scale-appropriate full-image convolution features within the CNN model. By selecting better scales in the region proposal input and by combining feature maps through careful design of the convolutional neural network, we improve performance on smaller objects. We significantly increase detection AP for the KITTI dataset car class from 76.3% on our baseline Faster R-CNN detector to 83.6% in our improved detector.