 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Loss Balancing for Noise-Robust GRPO in Generative Recommendation
Jun 07, 2026Reinforcement learning (RL) presents a promising avenue for enhancing generative recommendation beyond supervised imitation, leveraging reward signals to guide policy improvement. However, its efficacy is critically contingent on the trustworthiness of the reward model for the samples it evaluates. In practice, production rankers, the widely adopted reward models, are trained on exposure-biased logs, leading to sample-dependent inaccuracies that violate this assumption. Our stratified analysis uncovers a consistent pattern: reward guidance is most beneficial when the policy exhibits uncertainty and the ranker can effectively discriminate the ground-truth item from rollout negatives. On other samples, the reward signal is either negligible or detrimental, highlighting the risk of uniform RL application. To address such an issue, we introduce AdaGRPO, a novel framework that treats reward-guided optimization as selective admission rather than uniform pressure. Training is anchored in supervised negative log-likelihood, while the GRPO objective is gated by a binary, per-sample clip determined by two rollout diagnostics: policy-side difficulty and reward discriminability. Instances failing either diagnostic default to pure supervision, ensuring stability and mitigating the amplification of noisy gradients. We validate AdaGRPO on a large-scale e-commerce dataset. At the best intermediate checkpoint, it elevates HR@10 from 11.01% to 12.18% while constraining hallucination below 0.22%, and maintains robustness at the final checkpoint (HR@10 11.63%, hallucination 0.27%), outperforming fixed NLL--GRPO mixtures across the retrieval--validity frontier. In production A/B tests, AdaGRPO achieves statistically significant gains in click-through rate and dwell time, confirming its practical utility.
GenRec: A Preference-Oriented Generative Framework for Large-Scale Recommendation
Apr 16, 2026Generative Retrieval (GR) offers a promising paradigm for recommendation through next-token prediction (NTP). However, scaling it to large-scale industrial systems introduces three challenges: (i) within a single request, the identical model inputs may produce inconsistent outputs due to the pagination request mechanism; (ii) the prohibitive cost of encoding long user behavior sequences with multi-token item representations based on semantic IDs, and (iii) aligning the generative policy with nuanced user preference signals. We present GenRec, a preference-oriented generative framework deployed on the JD App that addresses above challenges within a single decoder-only architecture. For training objective, we propose Page-wise NTP task, which supervises over an entire interaction page rather than each interacted item individually, providing denser gradient signal and resolving the one-to-many ambiguity of point-wise training. On the prefilling side, an asymmetric linear Token Merger compresses multi-token Semantic IDs in the prompt while preserving full-resolution decoding, reducing input length by ~2X with negligible accuracy loss. To further align outputs with user satisfaction, we introduce GRPO-SR, a reinforcement learning method that pairs Group Relative Policy Optimization with NLL regularization for training stability, and employs Hybrid Rewards combining a dense reward model with a relevance gate to mitigate reward hacking. In month-long online A/B tests serving production traffic, GenRec achieves 9.5% improvement in click count and 8.7% in transaction count over the existing pipeline.
NS-VLA: Towards Neuro-Symbolic Vision-Language-Action Models
Mar 10, 2026Vision-Language-Action (VLA) models are formulated to ground instructions in visual context and generate action sequences for robotic manipulation. Despite recent progress, VLA models still face challenges in learning related and reusable primitives, reducing reliance on large-scale data and complex architectures, and enabling exploration beyond demonstrations. To address these challenges, we propose a novel Neuro-Symbolic Vision-Language-Action (NS-VLA) framework via online reinforcement learning (RL). It introduces a symbolic encoder to embedding vision and language features and extract structured primitives, utilizes a symbolic solver for data-efficient action sequencing, and leverages online RL to optimize generation via expansive exploration. Experiments on robotic manipulation benchmarks demonstrate that NS-VLA outperforms previous methods in both one-shot training and data-perturbed settings, while simultaneously exhibiting superior zero-shot generalizability, high data efficiency and expanded exploration space. Our code is available.
UAGLNet: Uncertainty-Aggregated Global-Local Fusion Network with Cooperative CNN-Transformer for Building Extraction
Dec 15, 2025Building extraction from remote sensing images is a challenging task due to the complex structure variations of the buildings. Existing methods employ convolutional or self-attention blocks to capture the multi-scale features in the segmentation models, while the inherent gap of the feature pyramids and insufficient global-local feature integration leads to inaccurate, ambiguous extraction results. To address this issue, in this paper, we present an Uncertainty-Aggregated Global-Local Fusion Network (UAGLNet), which is capable to exploit high-quality global-local visual semantics under the guidance of uncertainty modeling. Specifically, we propose a novel cooperative encoder, which adopts hybrid CNN and transformer layers at different stages to capture the local and global visual semantics, respectively. An intermediate cooperative interaction block (CIB) is designed to narrow the gap between the local and global features when the network becomes deeper. Afterwards, we propose a Global-Local Fusion (GLF) module to complementarily fuse the global and local representations. Moreover, to mitigate the segmentation ambiguity in uncertain regions, we propose an Uncertainty-Aggregated Decoder (UAD) to explicitly estimate the pixel-wise uncertainty to enhance the segmentation accuracy. Extensive experiments demonstrate that our method achieves superior performance to other state-of-the-art methods. Our code is available at https://github.com/Dstate/UAGLNet
Multimodal Propaganda Processing
Feb 17, 2023


Propaganda campaigns have long been used to influence public opinion via disseminating biased and/or misleading information. Despite the increasing prevalence of propaganda content on the Internet, few attempts have been made by AI researchers to analyze such content. We introduce the task of multimodal propaganda processing, where the goal is to automatically analyze propaganda content. We believe that this task presents a long-term challenge to AI researchers and that successful processing of propaganda could bring machine understanding one important step closer to human understanding. We discuss the technical challenges associated with this task and outline the steps that need to be taken to address it.
End-to-End Neural Discourse Deixis Resolution in Dialogue
Dec 03, 2022



We adapt Lee et al.'s (2018) span-based entity coreference model to the task of end-to-end discourse deixis resolution in dialogue, specifically by proposing extensions to their model that exploit task-specific characteristics. The resulting model, dd-utt, achieves state-of-the-art results on the four datasets in the CODI-CRAC 2021 shared task.
Segmenting Epipolar Line
Oct 11, 2020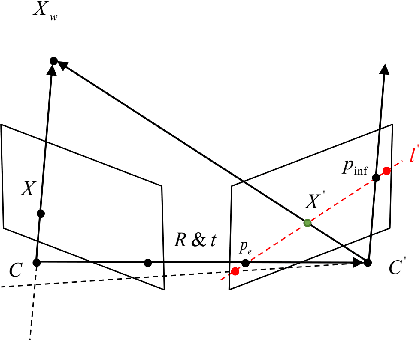


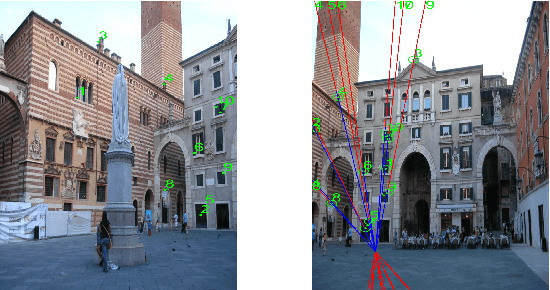
Identifying feature correspondence between two images is a fundamental procedure in three-dimensional computer vision. Usually the feature search space is confined by the epipolar line. Using the cheirality constraint, this paper finds that the feature search space can be restrained to one of two or three segments of the epipolar line that are defined by the epipole and a so-called virtual infinity point.
Clue: Cross-modal Coherence Modeling for Caption Generation
May 02, 2020


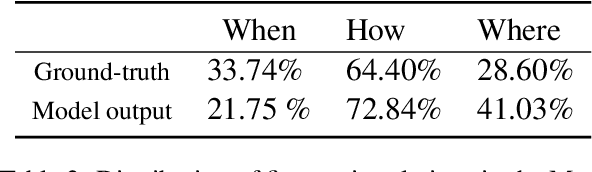
We use coherence relations inspired by computational models of discourse to study the information needs and goals of image captioning. Using an annotation protocol specifically devised for capturing image--caption coherence relations, we annotate 10,000 instances from publicly-available image--caption pairs. We introduce a new task for learning inferences in imagery and text, coherence relation prediction, and show that these coherence annotations can be exploited to learn relation classifiers as an intermediary step, and also train coherence-aware, controllable image captioning models. The results show a dramatic improvement in the consistency and quality of the generated captions with respect to information needs specified via coherence relations.