 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeShifter: 3D Variations Using Multiscale and Sparse Point-Voxel Diffusion
Feb 04, 2025



This paper proposes ShapeShifter, a new 3D generative model that learns to synthesize shape variations based on a single reference model. While generative methods for 3D objects have recently attracted much attention, current techniques often lack geometric details and/or require long training times and large resources. Our approach remedies these issues by combining sparse voxel grids and point, normal, and color sampling within a multiscale neural architecture that can be trained efficiently and in parallel. We show that our resulting variations better capture the fine details of their original input and can handle more general types of surfaces than previous SDF-based methods. Moreover, we offer interactive generation of 3D shape variants, allowing more human control in the design loop if needed.
Bayesian Experimental Design via Contrastive Diffusions
Oct 15, 2024Bayesian Optimal Experimental Design (BOED) is a powerful tool to reduce the cost of running a sequence of experiments. When based on the Expected Information Gain (EIG), design optimization corresponds to the maximization of some intractable expected {\it contrast} between prior and posterior distributions. Scaling this maximization to high dimensional and complex settings has been an issue due to BOED inherent computational complexity. In this work, we introduce an {\it expected posterior} distribution with cost-effective sampling properties and provide a tractable access to the EIG contrast maximization via a new EIG gradient expression. Diffusion-based samplers are used to compute the dynamics of the expected posterior and ideas from bi-level optimization are leveraged to derive an efficient joint sampling-optimization loop, without resorting to lower bound approximations of the EIG. The resulting efficiency gain allows to extend BOED to the well-tested generative capabilities of diffusion models. By incorporating generative models into the BOED framework, we expand its scope and its use in scenarios that were previously impractical. Numerical experiments and comparison with state-of-the-art methods show the potential of the approach.
PoNQ: a Neural QEM-based Mesh Representation
Mar 19, 2024



Although polygon meshes have been a standard representation in geometry processing, their irregular and combinatorial nature hinders their suitability for learning-based applications. In this work, we introduce a novel learnable mesh representation through a set of local 3D sample Points and their associated Normals and Quadric error metrics (QEM) w.r.t. the underlying shape, which we denote PoNQ. A global mesh is directly derived from PoNQ by efficiently leveraging the knowledge of the local quadric errors. Besides marking the first use of QEM within a neural shape representation, our contribution guarantees both topological and geometrical properties by ensuring that a PoNQ mesh does not self-intersect and is always the boundary of a volume. Notably, our representation does not rely on a regular grid, is supervised directly by the target surface alone, and also handles open surfaces with boundaries and/or sharp features. We demonstrate the efficacy of PoNQ through a learning-based mesh prediction from SDF grids and show that our method surpasses recent state-of-the-art techniques in terms of both surface and edge-based metrics.
PASOA- PArticle baSed Bayesian Optimal Adaptive design
Feb 11, 2024We propose a new procedure named PASOA, for Bayesian experimental design, that performs sequential design optimization by simultaneously providing accurate estimates of successive posterior distributions for parameter inference. The sequential design process is carried out via a contrastive estimation principle, using stochastic optimization and Sequential Monte Carlo (SMC) samplers to maximise the Expected Information Gain (EIG). As larger information gains are obtained for larger distances between successive posterior distributions, this EIG objective may worsen classical SMC performance. To handle this issue, tempering is proposed to have both a large information gain and an accurate SMC sampling, that we show is crucial for performance. This novel combination of stochastic optimization and tempered SMC allows to jointly handle design optimization and parameter inference. We provide a proof that the obtained optimal design estimators benefit from some consistency property. Numerical experiments confirm the potential of the approach, which outperforms other recent existing procedures.
VoroMesh: Learning Watertight Surface Meshes with Voronoi Diagrams
Aug 28, 2023



In stark contrast to the case of images, finding a concise, learnable discrete representation of 3D surfaces remains a challenge. In particular, while polygon meshes are arguably the most common surface representation used in geometry processing, their irregular and combinatorial structure often make them unsuitable for learning-based applications. In this work, we present VoroMesh, a novel and differentiable Voronoi-based representation of watertight 3D shape surfaces. From a set of 3D points (called generators) and their associated occupancy, we define our boundary representation through the Voronoi diagram of the generators as the subset of Voronoi faces whose two associated (equidistant) generators are of opposite occupancy: the resulting polygon mesh forms a watertight approximation of the target shape's boundary. To learn the position of the generators, we propose a novel loss function, dubbed VoroLoss, that minimizes the distance from ground truth surface samples to the closest faces of the Voronoi diagram which does not require an explicit construction of the entire Voronoi diagram. A direct optimization of the Voroloss to obtain generators on the Thingi32 dataset demonstrates the geometric efficiency of our representation compared to axiomatic meshing algorithms and recent learning-based mesh representations. We further use VoroMesh in a learning-based mesh prediction task from input SDF grids on the ABC dataset, and show comparable performance to state-of-the-art methods while guaranteeing closed output surfaces free of self-intersections.
BPNet: Bézier Primitive Segmentation on 3D Point Clouds
Jul 08, 2023This paper proposes BPNet, a novel end-to-end deep learning framework to learn B\'ezier primitive segmentation on 3D point clouds. The existing works treat different primitive types separately, thus limiting them to finite shape categories. To address this issue, we seek a generalized primitive segmentation on point clouds. Taking inspiration from B\'ezier decomposition on NURBS models, we transfer it to guide point cloud segmentation casting off primitive types. A joint optimization framework is proposed to learn B\'ezier primitive segmentation and geometric fitting simultaneously on a cascaded architecture. Specifically, we introduce a soft voting regularizer to improve primitive segmentation and propose an auto-weight embedding module to cluster point features, making the network more robust and generic. We also introduce a reconstruction module where we successfully process multiple CAD models with different primitives simultaneously. We conducted extensive experiments on the synthetic ABC dataset and real-scan datasets to validate and compare our approach with different baseline methods. Experiments show superior performance over previous work in terms of segmentation, with a substantially faster inference speed.
DAugNet: Unsupervised, Multi-source, Multi-target, and Life-long Domain Adaptation for Semantic Segmentation of Satellite Images
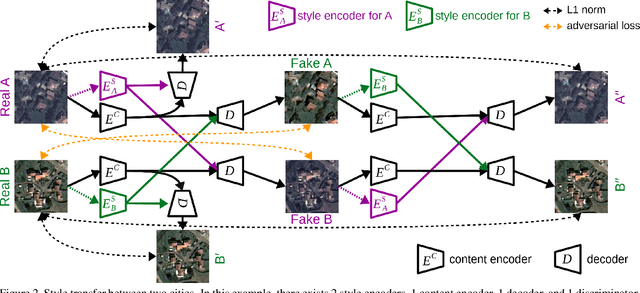
Jun 07, 2020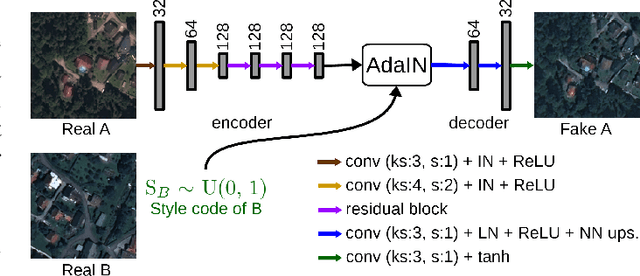


The domain adaptation of satellite images has recently gained an increasing attention to overcome the limited generalization abilities of machine learning models when segmenting large-scale satellite images. Most of the existing approaches seek for adapting the model from one domain to another. However, such single-source and single-target setting prevents the methods from being scalable solutions, since nowadays multiple source and target domains having different data distributions are usually available. Besides, the continuous proliferation of satellite images necessitates the classifiers to adapt to continuously increasing data. We propose a novel approach, coined DAugNet, for unsupervised, multi-source, multi-target, and life-long domain adaptation of satellite images. It consists of a classifier and a data augmentor. The data augmentor, which is a shallow network, is able to perform style transfer between multiple satellite images in an unsupervised manner, even when new data are added over the time. In each training iteration, it provides the classifier with diversified data, which makes the classifier robust to large data distribution difference between the domains. Our extensive experiments prove that DAugNet significantly better generalizes to new geographic locations than the existing approaches.
StandardGAN: Multi-source Domain Adaptation for Semantic Segmentation of Very High Resolution Satellite Images by Data Standardization
Apr 14, 2020
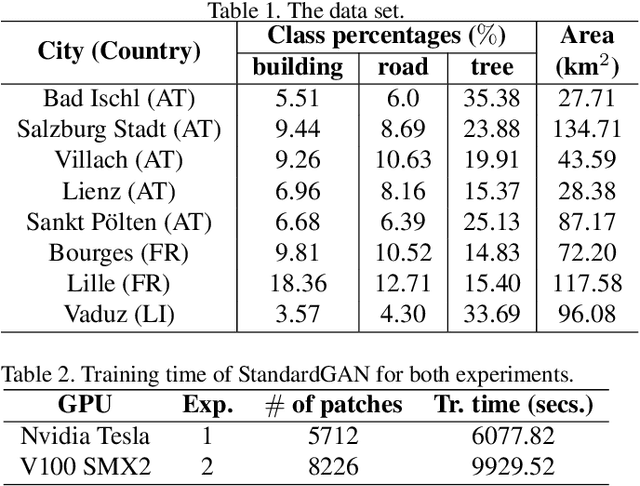
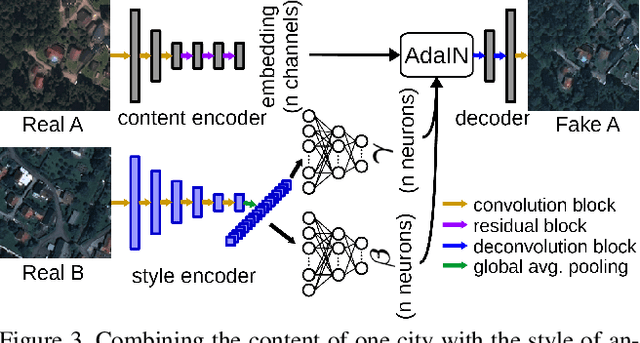
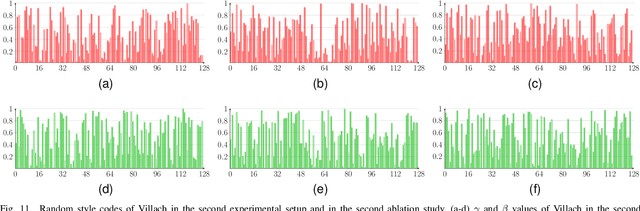
Domain adaptation for semantic segmentation has recently been actively studied to increase the generalization capabilities of deep learning models. The vast majority of the domain adaptation methods tackle single-source case, where the model trained on a single source domain is adapted to a target domain. However, these methods have limited practical real world applications, since usually one has multiple source domains with different data distributions. In this work, we deal with the multi-source domain adaptation problem. Our method, namely StandardGAN, standardizes each source and target domains so that all the data have similar data distributions. We then use the standardized source domains to train a classifier and segment the standardized target domain. We conduct extensive experiments on two remote sensing data sets, in which the first one consists of multiple cities from a single country, and the other one contains multiple cities from different countries. Our experimental results show that the standardized data generated by StandardGAN allow the classifiers to generate significantly better segmentation.
SemI2I: Semantically Consistent Image-to-Image Translation for Domain Adaptation of Remote Sensing Data
Feb 21, 2020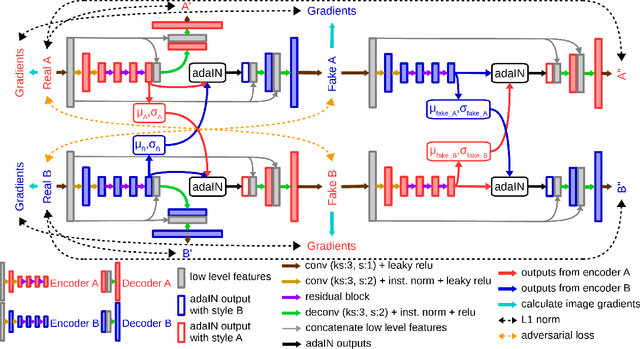
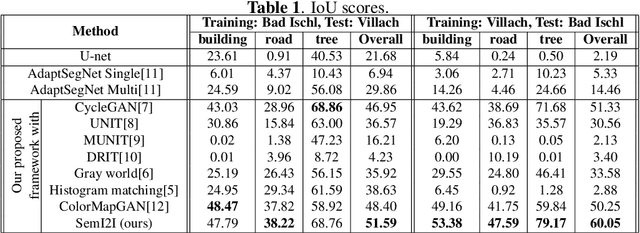

Although convolutional neural networks have been proven to be an effective tool to generate high quality maps from remote sensing images, their performance significantly deteriorates when there exists a large domain shift between training and test data. To address this issue, we propose a new data augmentation approach that transfers the style of test data to training data using generative adversarial networks. Our semantic segmentation framework consists in first training a U-net from the real training data and then fine-tuning it on the test stylized fake training data generated by the proposed approach. Our experimental results prove that our framework outperforms the existing domain adaptation methods.
ColorMapGAN: Unsupervised Domain Adaptation for Semantic Segmentation Using Color Mapping Generative Adversarial Networks
Jul 30, 2019
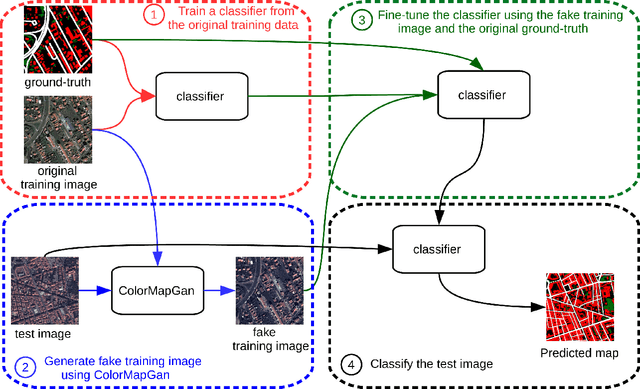
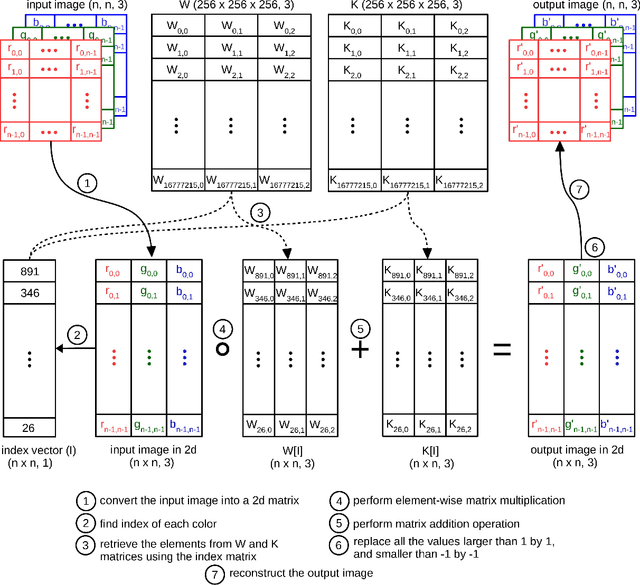
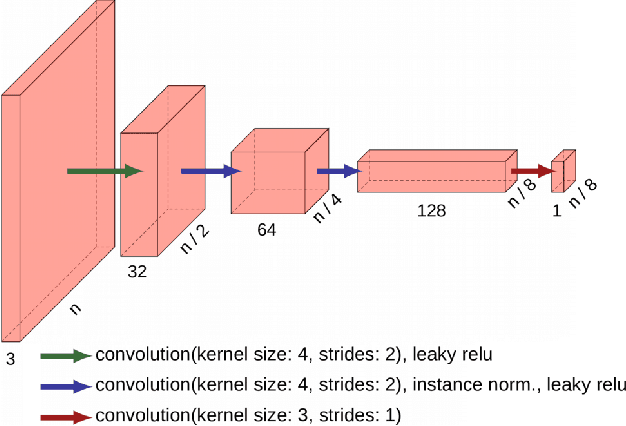
Due to the various reasons such as atmospheric effects and differences in acquisition, it is often the case that there exists a large difference between spectral bands of satellite images collected from different geographic locations. The large shift between spectral distributions of training and test data causes the current state of the art supervised learning approaches to output poor maps. We present a novel end to end semantic segmentation framework that is robust to such shift. The key component of the proposed framework is Color Mapping Generative Adversarial Networks (ColorMapGAN), which can generate fake training images that are semantically exactly the same as training images, but whose spectral distribution is similar to the distribution of the test images. We then use the fake images and the ground-truth for the training images to fine-tune the already trained classifier. Contrary to the existing Generative Adversarial Networks (GAN), the generator in ColorMapGAN does not have any convolutional or pooling layers. It learns to transform the colors of the training data to the colors of the test data by performing only one element-wise matrix multiplication and one matrix addition operations. Thanks to the architecturally simple but powerful design of ColorMapGAN, the proposed framework outperforms the existing approaches with a large margin in terms of both accuracy and computational complexity.