 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial nets with perceptual losses for text-to-image synthesis
Aug 30, 2017

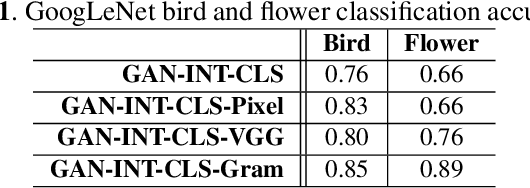
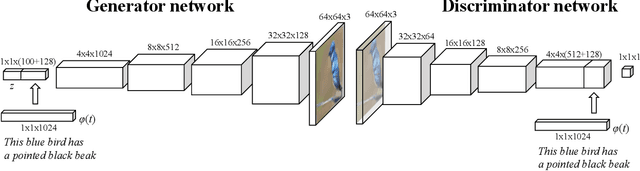

Recent approaches in generative adversarial networks (GANs) can automatically synthesize realistic images from descriptive text. Despite the overall fair quality, the generated images often expose visible flaws that lack structural definition for an object of interest. In this paper, we aim to extend state of the art for GAN-based text-to-image synthesis by improving perceptual quality of generated images. Differentiated from previous work, our synthetic image generator optimizes on perceptual loss functions that measure pixel, feature activation, and texture differences against a natural image. We present visually more compelling synthetic images of birds and flowers generated from text descriptions in comparison to some of the most prominent existing work.
Convolution Neural Network Hyperparameter Optimization Using Simplified Swarm Optimization
Mar 06, 2021
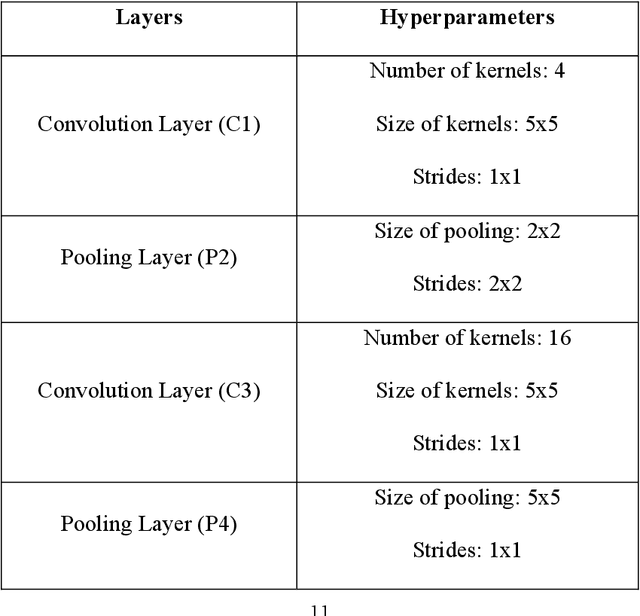
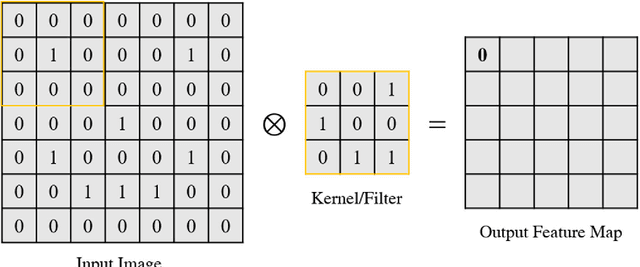
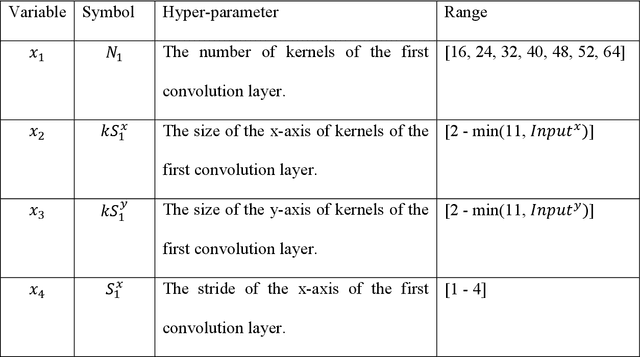
Among the machine learning approaches applied in computer vision, Convolutional Neural Network (CNN) is widely used in the field of image recognition. However, although existing CNN models have been proven to be efficient, it is not easy to find a network architecture with better performance. Some studies choose to optimize the network architecture, while others chose to optimize the hyperparameters, such as the number and size of convolutional kernels, convolutional strides, pooling size, etc. Most of them are designed manually, which requires relevant expertise and takes a lot of time. Therefore, this study proposes the idea of applying Simplified Swarm Optimization (SSO) on the hyperparameter optimization of LeNet models while using MNIST, Fashion MNIST, and Cifar10 as validation. The experimental results show that the proposed algorithm has higher accuracy than the original LeNet model, and it only takes a very short time to find a better hyperparameter configuration after training. In addition, we also analyze the output shape of the feature map after each layer, and surprisingly, the results were mostly rectangular. The contribution of the study is to provide users with a simpler way to get better results with the existing model., and this study can also be applied to other CNN architectures.
Hyperspectral Classification Based on Lightweight 3-D-CNN With Transfer Learning
Dec 07, 2020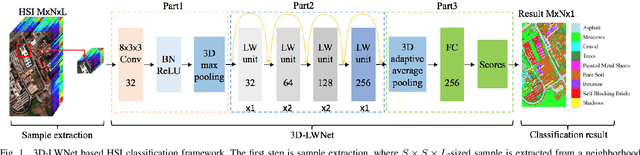
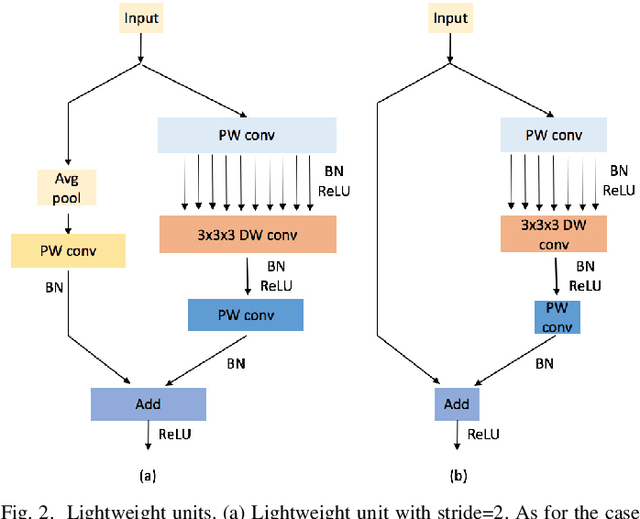
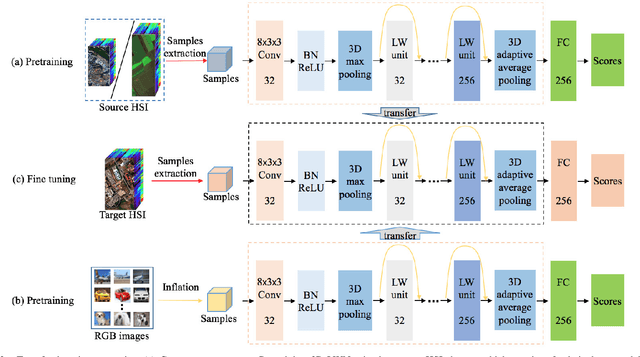
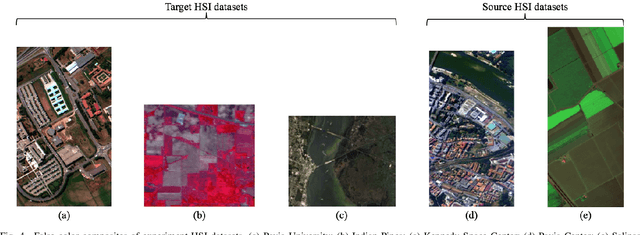
Recently, hyperspectral image (HSI) classification approaches based on deep learning (DL) models have been proposed and shown promising performance. However, because of very limited available training samples and massive model parameters, DL methods may suffer from overfitting. In this paper, we propose an end-to-end 3-D lightweight convolutional neural network (CNN) (abbreviated as 3-D-LWNet) for limited samples-based HSI classification. Compared with conventional 3-D-CNN models, the proposed 3-D-LWNet has a deeper network structure, less parameters, and lower computation cost, resulting in better classification performance. To further alleviate the small sample problem, we also propose two transfer learning strategies: 1) cross-sensor strategy, in which we pretrain a 3-D model in the source HSI data sets containing a greater number of labeled samples and then transfer it to the target HSI data sets and 2) cross-modal strategy, in which we pretrain a 3-D model in the 2-D RGB image data sets containing a large number of samples and then transfer it to the target HSI data sets. In contrast to previous approaches, we do not impose restrictions over the source data sets, in which they do not have to be collected by the same sensors as the target data sets. Experiments on three public HSI data sets captured by different sensors demonstrate that our model achieves competitive performance for HSI classification compared to several state-of-the-art methods
* 16 pages. Accepted to IEEE Trans. Geosci. Remote Sens. Code is available at: https://github.com/hkzhang91/LWNet
Learning a Virtual Codec Based on Deep Convolutional Neural Network to Compress Image
Jan 16, 2018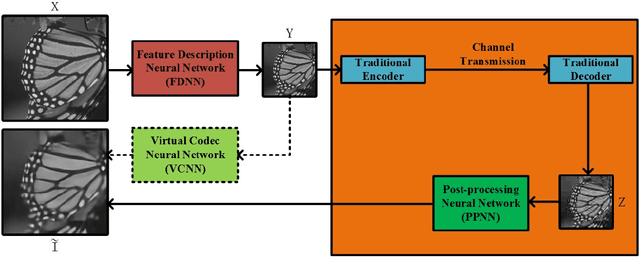
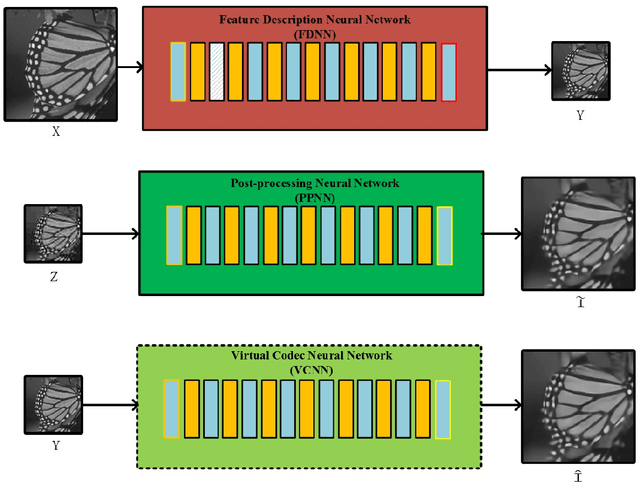

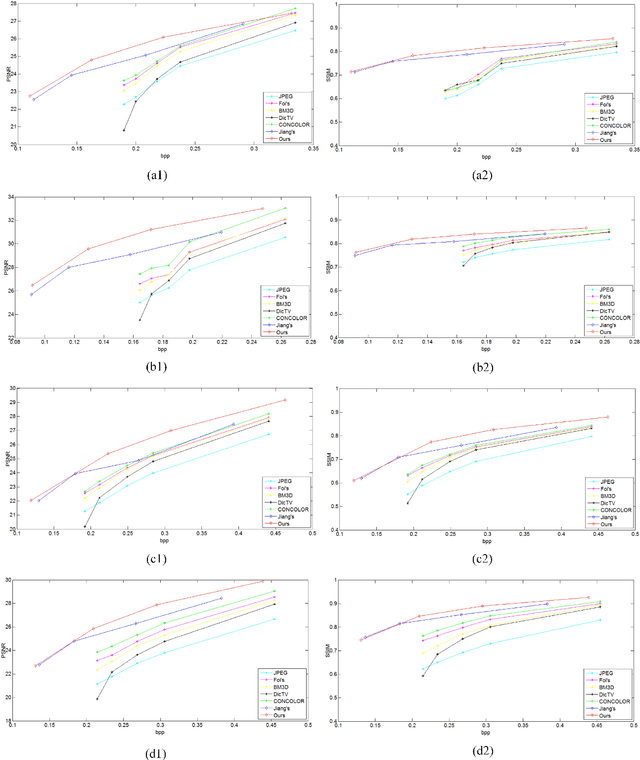
Although deep convolutional neural network has been proved to efficiently eliminate coding artifacts caused by the coarse quantization of traditional codec, it's difficult to train any neural network in front of the encoder for gradient's back-propagation. In this paper, we propose an end-to-end image compression framework based on convolutional neural network to resolve the problem of non-differentiability of the quantization function in the standard codec. First, the feature description neural network is used to get a valid description in the low-dimension space with respect to the ground-truth image so that the amount of image data is greatly reduced for storage or transmission. After image's valid description, standard image codec such as JPEG is leveraged to further compress image, which leads to image's great distortion and compression artifacts, especially blocking artifacts, detail missing, blurring, and ringing artifacts. Then, we use a post-processing neural network to remove these artifacts. Due to the challenge of directly learning a non-linear function for a standard codec based on convolutional neural network, we propose to learn a virtual codec neural network to approximate the projection from the valid description image to the post-processed compressed image, so that the gradient could be efficiently back-propagated from the post-processing neural network to the feature description neural network during training. Meanwhile, an advanced learning algorithm is proposed to train our deep neural networks for compression. Obviously, the priority of the proposed method is compatible with standard existing codecs and our learning strategy can be easily extended into these codecs based on convolutional neural network. Experimental results have demonstrated the advances of the proposed method as compared to several state-of-the-art approaches, especially at very low bit-rate.
Instance Map based Image Synthesis with a Denoising Generative Adversarial Network
Jan 10, 2018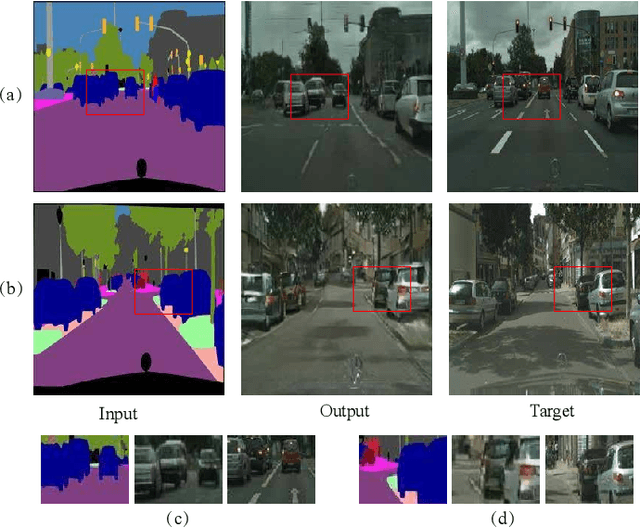



Semantic layouts based Image synthesizing, which has benefited from the success of Generative Adversarial Network (GAN), has drawn much attention in these days. How to enhance the synthesis image equality while keeping the stochasticity of the GAN is still a challenge. We propose a novel denoising framework to handle this problem. The overlapped objects generation is another challenging task when synthesizing images from a semantic layout to a realistic RGB photo. To overcome this deficiency, we include a one-hot semantic label map to force the generator paying more attention on the overlapped objects generation. Furthermore, we improve the loss function of the discriminator by considering perturb loss and cascade layer loss to guide the generation process. We applied our methods on the Cityscapes, Facades and NYU datasets and demonstrate the image generation ability of our model.
A General Framework for Hypercomplex-valued Extreme Learning Machines
Jan 15, 2021
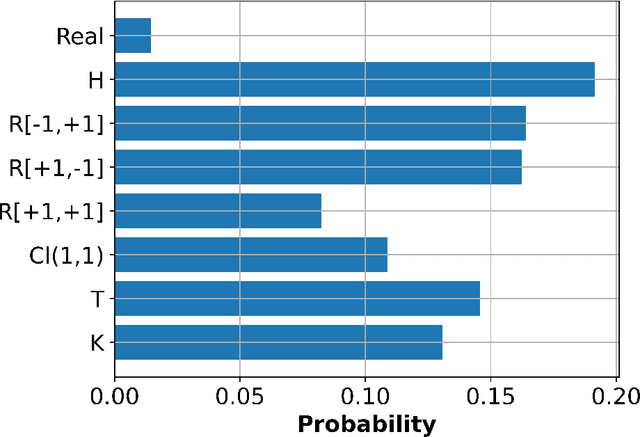
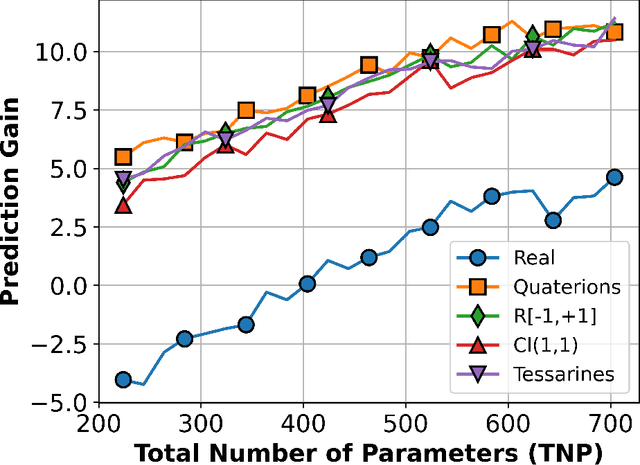

This paper aims to establish a framework for extreme learning machines (ELMs) on general hypercomplex algebras. Hypercomplex neural networks are machine learning models that feature higher-dimension numbers as parameters, inputs, and outputs. Firstly, we review broad hypercomplex algebras and show a framework to operate in these algebras through real-valued linear algebra operations in a robust manner. We proceed to explore a handful of well-known four-dimensional examples. Then, we propose the hypercomplex-valued ELMs and derive their learning using a hypercomplex-valued least-squares problem. Finally, we compare real and hypercomplex-valued ELM models' performance in an experiment on time-series prediction and another on color image auto-encoding. The computational experiments highlight the excellent performance of hypercomplex-valued ELMs to treat high-dimensional data, including models based on unusual hypercomplex algebras.
Multi-Stage Raw Video Denoising with Adversarial Loss and Gradient Mask
Mar 05, 2021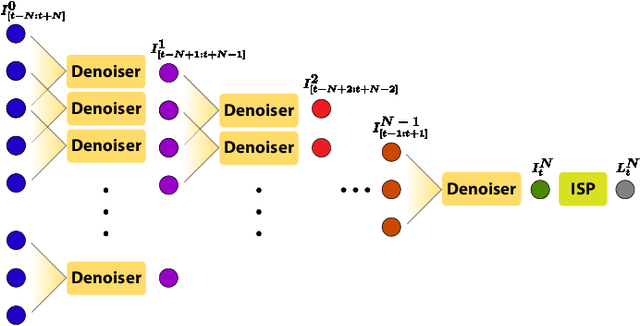
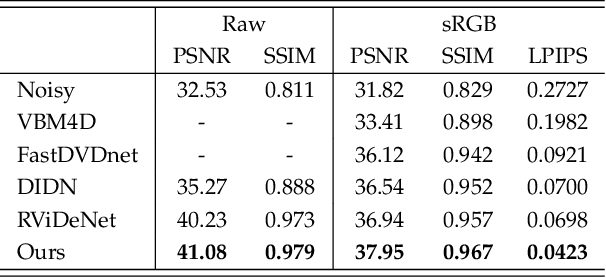

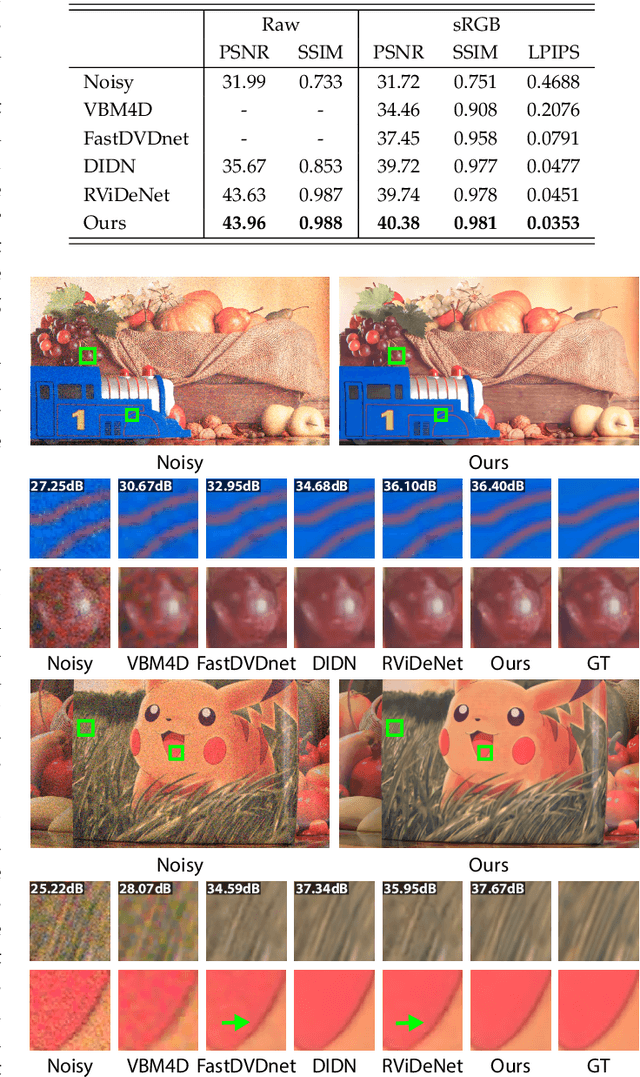
In this paper, we propose a learning-based approach for denoising raw videos captured under low lighting conditions. We propose to do this by first explicitly aligning the neighboring frames to the current frame using a convolutional neural network (CNN). We then fuse the registered frames using another CNN to obtain the final denoised frame. To avoid directly aligning the temporally distant frames, we perform the two processes of alignment and fusion in multiple stages. Specifically, at each stage, we perform the denoising process on three consecutive input frames to generate the intermediate denoised frames which are then passed as the input to the next stage. By performing the process in multiple stages, we can effectively utilize the information of neighboring frames without directly aligning the temporally distant frames. We train our multi-stage system using an adversarial loss with a conditional discriminator. Specifically, we condition the discriminator on a soft gradient mask to prevent introducing high-frequency artifacts in smooth regions. We show that our system is able to produce temporally coherent videos with realistic details. Furthermore, we demonstrate through extensive experiments that our approach outperforms state-of-the-art image and video denoising methods both numerically and visually.
ExAD: An Ensemble Approach for Explanation-based Adversarial Detection
Mar 22, 2021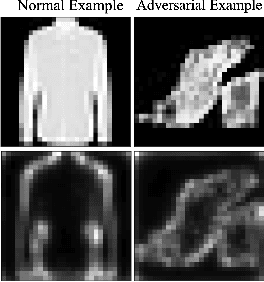
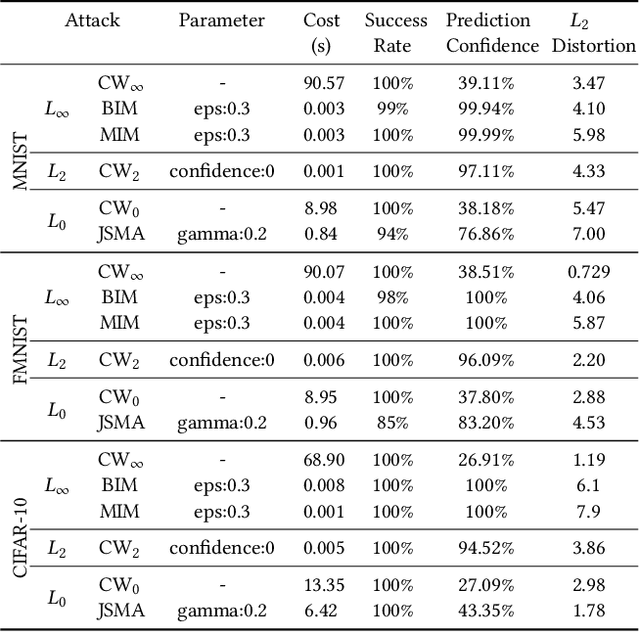
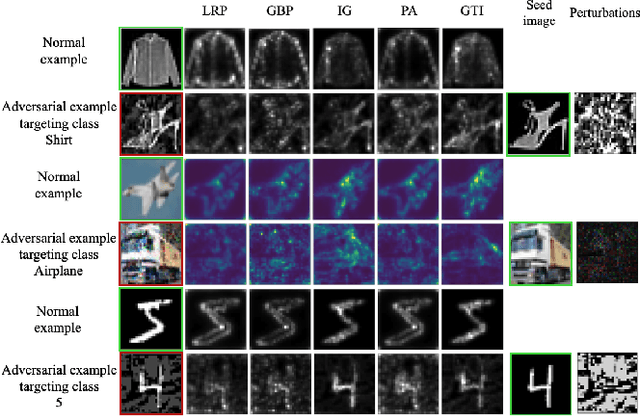
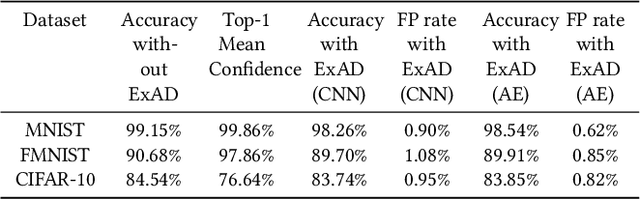
Recent research has shown Deep Neural Networks (DNNs) to be vulnerable to adversarial examples that induce desired misclassifications in the models. Such risks impede the application of machine learning in security-sensitive domains. Several defense methods have been proposed against adversarial attacks to detect adversarial examples at test time or to make machine learning models more robust. However, while existing methods are quite effective under blackbox threat model, where the attacker is not aware of the defense, they are relatively ineffective under whitebox threat model, where the attacker has full knowledge of the defense. In this paper, we propose ExAD, a framework to detect adversarial examples using an ensemble of explanation techniques. Each explanation technique in ExAD produces an explanation map identifying the relevance of input variables for the model's classification. For every class in a dataset, the system includes a detector network, corresponding to each explanation technique, which is trained to distinguish between normal and abnormal explanation maps. At test time, if the explanation map of an input is detected as abnormal by any detector model of the classified class, then we consider the input to be an adversarial example. We evaluate our approach using six state-of-the-art adversarial attacks on three image datasets. Our extensive evaluation shows that our mechanism can effectively detect these attacks under blackbox threat model with limited false-positives. Furthermore, we find that our approach achieves promising results in limiting the success rate of whitebox attacks.
Robots Understanding Contextual Information in Human-Centered Environments using Weakly Supervised Mask Data Distillation
Dec 15, 2020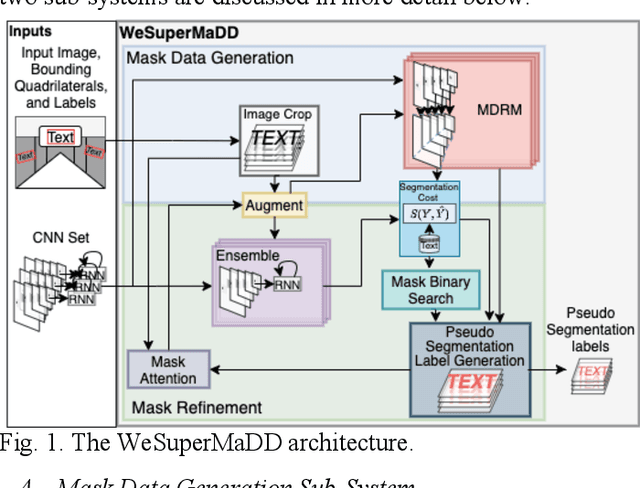


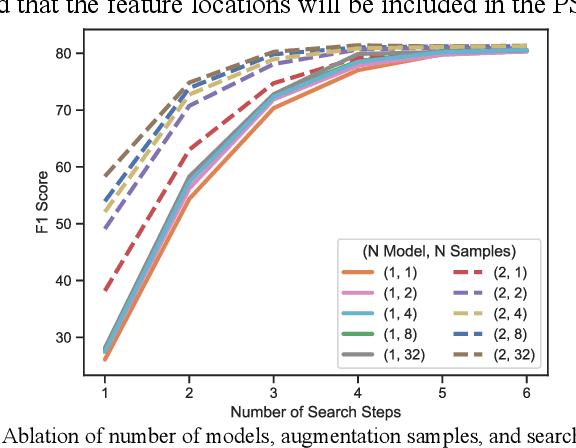
Contextual information in human environments, such as signs, symbols, and objects provide important information for robots to use for exploration and navigation. To identify and segment contextual information from complex images obtained in these environments, data-driven methods such as Convolutional Neural Networks (CNNs) are used. However, these methods require large amounts of human labeled data which are slow and time-consuming to obtain. Weakly supervised methods address this limitation by generating pseudo segmentation labels (PSLs). In this paper, we present the novel Weakly Supervised Mask Data Distillation (WeSuperMaDD) architecture for autonomously generating PSLs using CNNs not specifically trained for the task of context segmentation; i.e., CNNs trained for object classification, image captioning, etc. WeSuperMaDD uniquely generates PSLs using learned image features from sparse and limited diversity data; common in robot navigation tasks in human-centred environments (malls, grocery stores). Our proposed architecture uses a new mask refinement system which automatically searches for the PSL with the fewest foreground pixels that satisfies cost constraints. This removes the need for handcrafted heuristic rules. Extensive experiments successfully validated the performance of WeSuperMaDD in generating PSLs for datasets with text of various scales, fonts, and perspectives in multiple indoor/outdoor environments. A comparison with Naive, GrabCut, and Pyramid methods found a significant improvement in label and segmentation quality. Moreover, a context segmentation CNN trained using the WeSuperMaDD architecture achieved measurable improvements in accuracy compared to one trained with Naive PSLs. Our method also had comparable performance to existing state-of-the-art text detection and segmentation methods on real datasets without requiring segmentation labels for training.
Appearance Learning for Image-based Motion Estimation in Tomography
Jun 18, 2020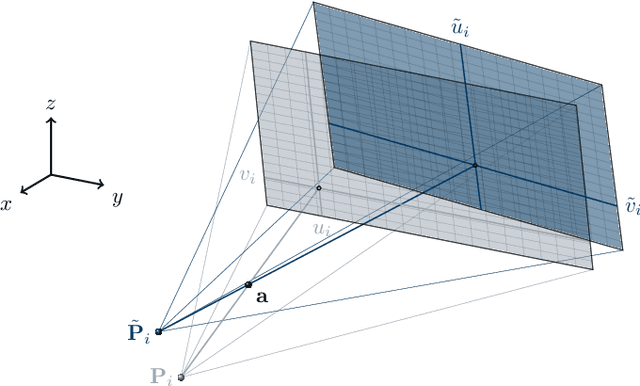
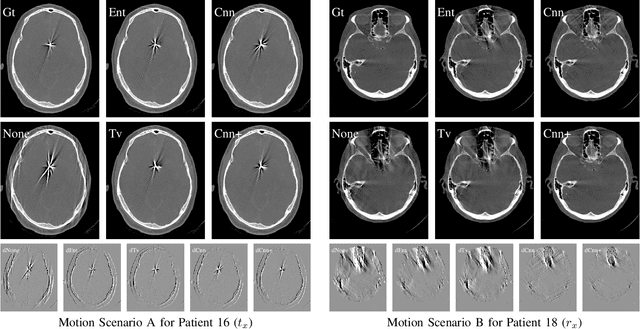
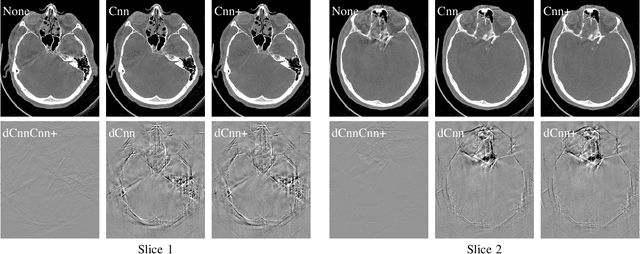
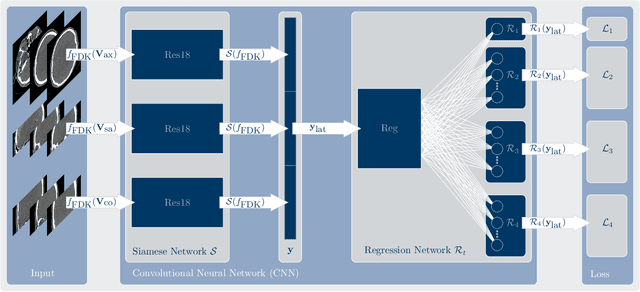
In tomographic imaging, anatomical structures are reconstructed by applying a pseudo-inverse forward model to acquired signals. Geometric information within this process is usually depending on the system setting only, i. e., the scanner position or readout direction. Patient motion therefore corrupts the geometry alignment in the reconstruction process resulting in motion artifacts. We propose an appearance learning approach recognizing the structures of rigid motion independently from the scanned object. To this end, we train a siamese triplet network to predict the reprojection error (RPE) for the complete acquisition as well as an approximate distribution of the RPE along the single views from the reconstructed volume in a multi-task learning approach. The RPE measures the motioninduced geometric deviations independent of the object based on virtual marker positions, which are available during training. We train our network using 27 patients and deploy a 21-4-2 split for training, validation and testing. In average, we achieve a residual mean RPE of 0.013mm with an inter-patient standard deviation of 0.022 mm. This is twice the accuracy compared to previously published results. In a motion estimation benchmark the proposed approach achieves superior results in comparison with two state-of-the-art measures in nine out of twelve experiments. The clinical applicability of the proposed method is demonstrated on a motion-affected clinical dataset.