 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobots Understanding Contextual Information in Human-Centered Environments using Weakly Supervised Mask Data Distillation
Paper and Code
Dec 15, 2020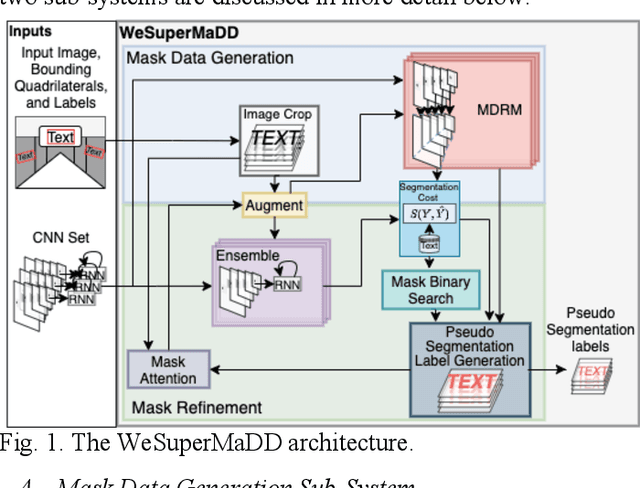


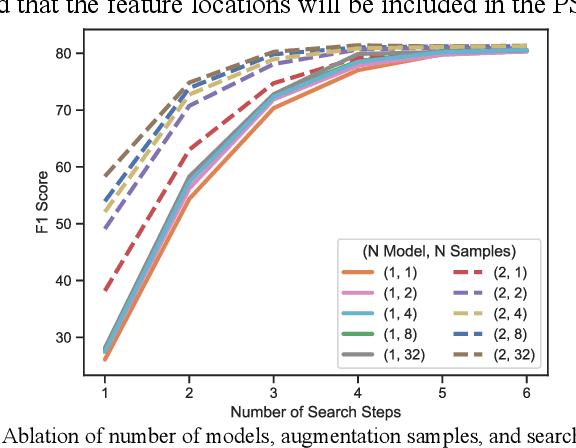
Contextual information in human environments, such as signs, symbols, and objects provide important information for robots to use for exploration and navigation. To identify and segment contextual information from complex images obtained in these environments, data-driven methods such as Convolutional Neural Networks (CNNs) are used. However, these methods require large amounts of human labeled data which are slow and time-consuming to obtain. Weakly supervised methods address this limitation by generating pseudo segmentation labels (PSLs). In this paper, we present the novel Weakly Supervised Mask Data Distillation (WeSuperMaDD) architecture for autonomously generating PSLs using CNNs not specifically trained for the task of context segmentation; i.e., CNNs trained for object classification, image captioning, etc. WeSuperMaDD uniquely generates PSLs using learned image features from sparse and limited diversity data; common in robot navigation tasks in human-centred environments (malls, grocery stores). Our proposed architecture uses a new mask refinement system which automatically searches for the PSL with the fewest foreground pixels that satisfies cost constraints. This removes the need for handcrafted heuristic rules. Extensive experiments successfully validated the performance of WeSuperMaDD in generating PSLs for datasets with text of various scales, fonts, and perspectives in multiple indoor/outdoor environments. A comparison with Naive, GrabCut, and Pyramid methods found a significant improvement in label and segmentation quality. Moreover, a context segmentation CNN trained using the WeSuperMaDD architecture achieved measurable improvements in accuracy compared to one trained with Naive PSLs. Our method also had comparable performance to existing state-of-the-art text detection and segmentation methods on real datasets without requiring segmentation labels for training.