 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Approximation of Binary-State Network Reliability Function: Algorithm Selection and Reliability Thresholds for Large-Scale Systems
Mar 16, 2025



Network reliability assessment is pivotal for ensuring the robustness of modern infrastructure systems, from power grids to communication networks. While exact reliability computation for binary-state networks is NP-hard, existing approximation methods face critical tradeoffs between accuracy, scalability, and data efficiency. This study evaluates 20 machine learning methods across three reliability regimes full range (0.0-1.0), high reliability (0.9-1.0), and ultra high reliability (0.99-1.0) to address these gaps. We demonstrate that large-scale networks with arc reliability larger than or equal to 0.9 exhibit near-unity system reliability, enabling computational simplifications. Further, we establish a dataset-scale-driven paradigm for algorithm selection: Artificial Neural Networks (ANN) excel with limited data, while Polynomial Regression (PR) achieves superior accuracy in data-rich environments. Our findings reveal ANN's Test-MSE of 7.24E-05 at 30,000 samples and PR's optimal performance (5.61E-05) at 40,000 samples, outperforming traditional Monte Carlo simulations. These insights provide actionable guidelines for balancing accuracy, interpretability, and computational efficiency in reliability engineering, with implications for infrastructure resilience and system optimization.
Application of Long Short-Term Memory Recurrent Neural Networks Based on the BAT-MCS for Binary-State Network Approximated Time-Dependent Reliability Problems
Feb 16, 2022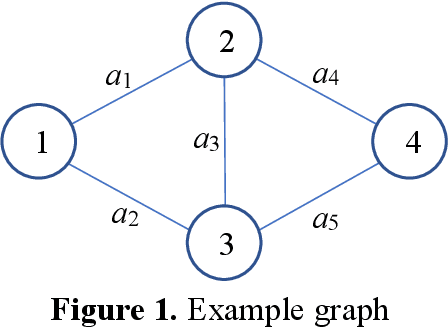
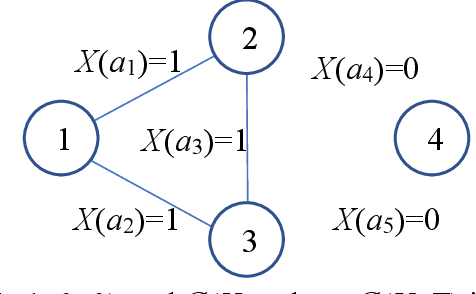
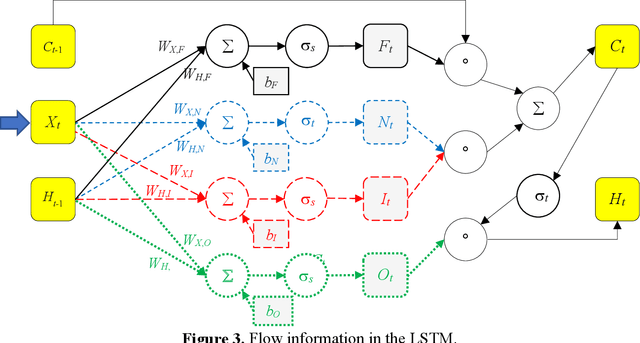
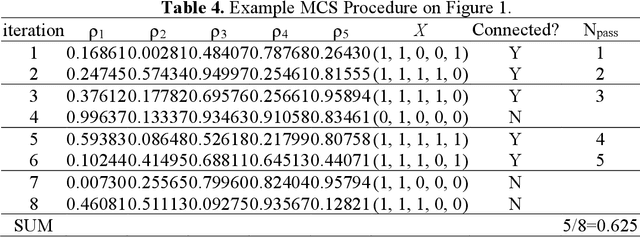
Reliability is an important tool for evaluating the performance of modern networks. Currently, it is NP-hard and #P-hard to calculate the exact reliability of a binary-state network when the reliability of each component is assumed to be fixed. However, this assumption is unrealistic because the reliability of each component always varies with time. To meet this practical requirement, we propose a new algorithm called the LSTM-BAT-MCS, based on long short-term memory (LSTM), the Monte Carlo simulation (MCS), and the binary-adaption-tree algorithm (BAT). The superiority of the proposed LSTM-BAT-MCS was demonstrated by experimental results of three benchmark networks with at most 10-4 mean square error.
PAM: Pose Attention Module for Pose-Invariant Face Recognition
Nov 23, 2021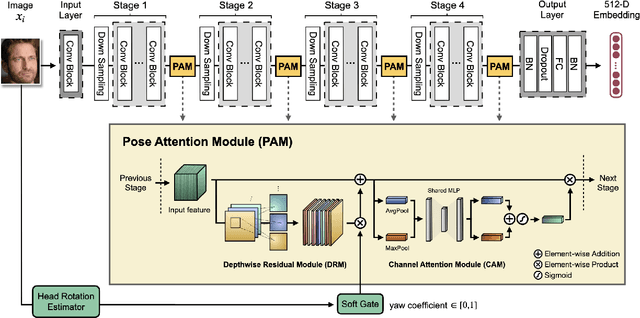
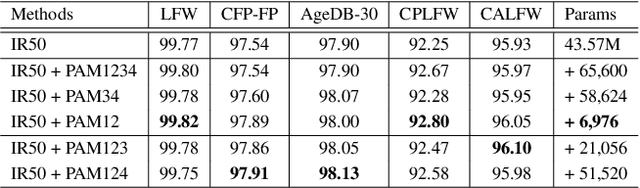
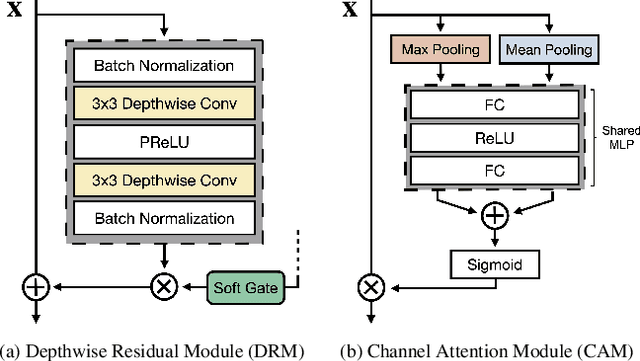
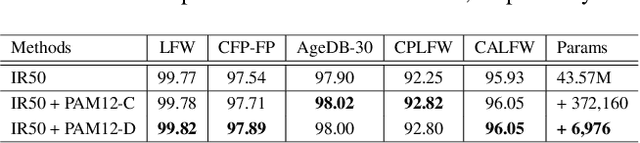
Pose variation is one of the key challenges in face recognition. Conventional techniques mainly focus on face frontalization or face augmentation in image space. However, transforming face images in image space is not guaranteed to preserve the lossless identity features of the original image. Moreover, these methods suffer from more computational costs and memory requirements due to the additional models. We argue that it is more desirable to perform feature transformation in hierarchical feature space rather than image space, which can take advantage of different feature levels and benefit from joint learning with representation learning. To this end, we propose a lightweight and easy-to-implement attention block, named Pose Attention Module (PAM), for pose-invariant face recognition. Specifically, PAM performs frontal-profile feature transformation in hierarchical feature space by learning residuals between pose variations with a soft gate mechanism. We validated the effectiveness of PAM block design through extensive ablation studies and verified the performance on several popular benchmarks, including LFW, CFP-FP, AgeDB-30, CPLFW, and CALFW. Experimental results show that our method not only outperforms state-of-the-art methods but also effectively reduces memory requirements by more than 75 times. It is noteworthy that our method is not limited to face recognition with large pose variations. By adjusting the soft gate mechanism of PAM to a specific coefficient, such semantic attention block can easily extend to address other intra-class imbalance problems in face recognition, including large variations in age, illumination, expression, etc.
Implementation of Parallel Simplified Swarm Optimization in CUDA
Oct 01, 2021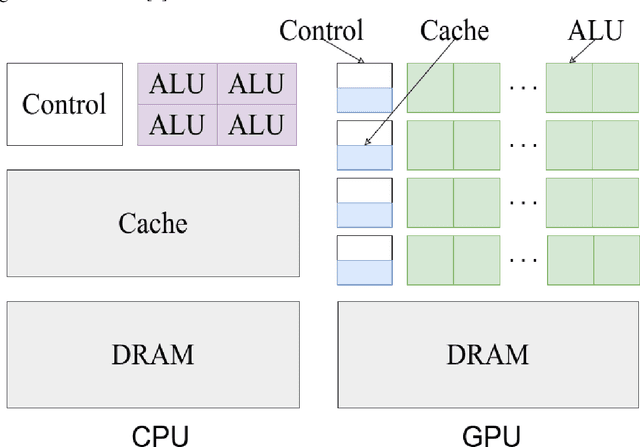
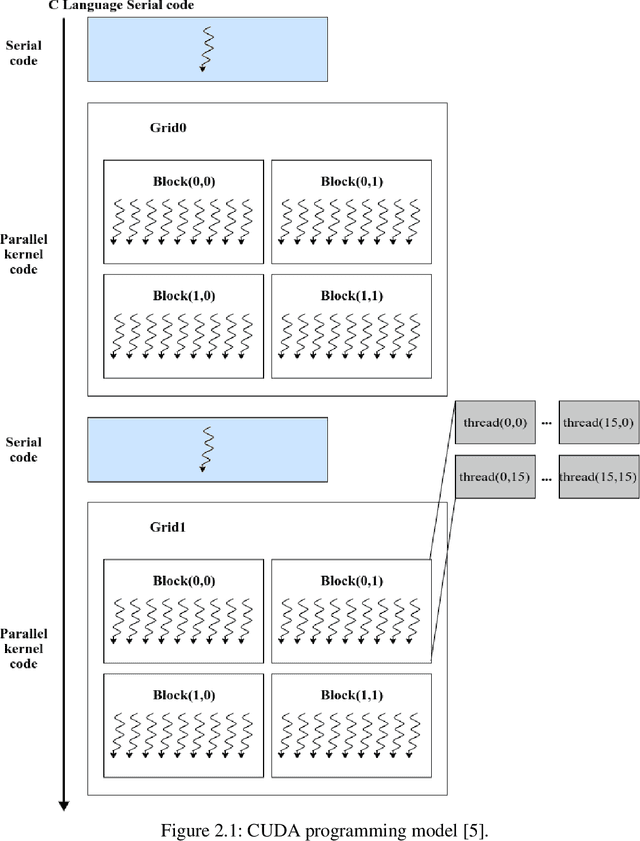
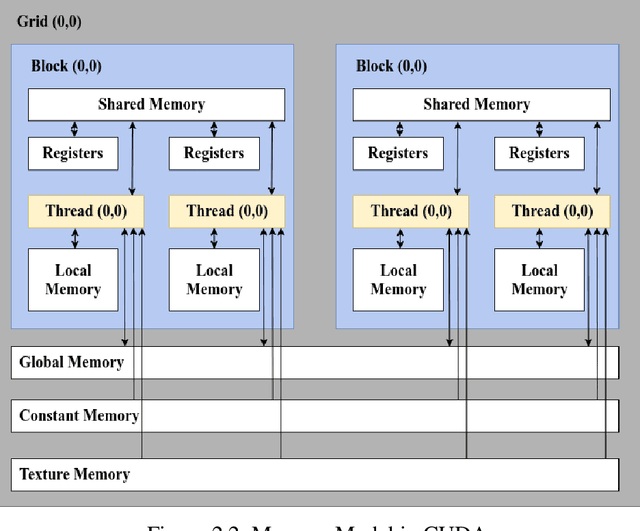
As the acquisition cost of the graphics processing unit (GPU) has decreased, personal computers (PC) can handle optimization problems nowadays. In optimization computing, intelligent swarm algorithms (SIAs) method is suitable for parallelization. However, a GPU-based Simplified Swarm Optimization Algorithm has never been proposed. Accordingly, this paper proposed Parallel Simplified Swarm Optimization (PSSO) based on the CUDA platform considering computational ability and versatility. In PSSO, the theoretical value of time complexity of fitness function is O (tNm). There are t iterations and N fitness functions, each of which required pair comparisons m times. pBests and gBest have the resource preemption when updating in previous studies. As the experiment results showed, the time complexity has successfully reduced by an order of magnitude of N, and the problem of resource preemption was avoided entirely.
A Novel Simplified Swarm Optimization for Generalized Reliability Redundancy Allocation Problem
Oct 01, 2021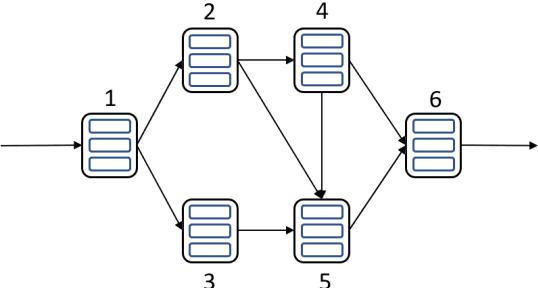
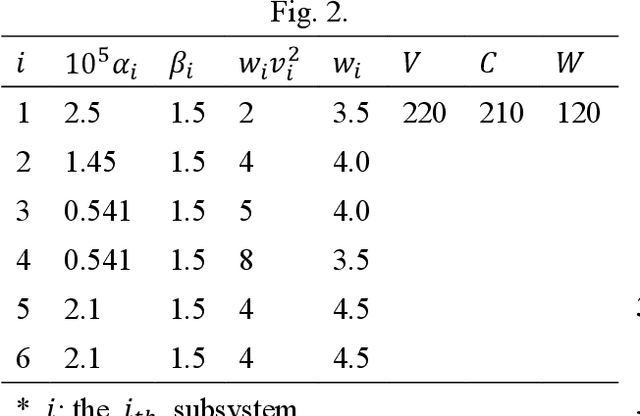
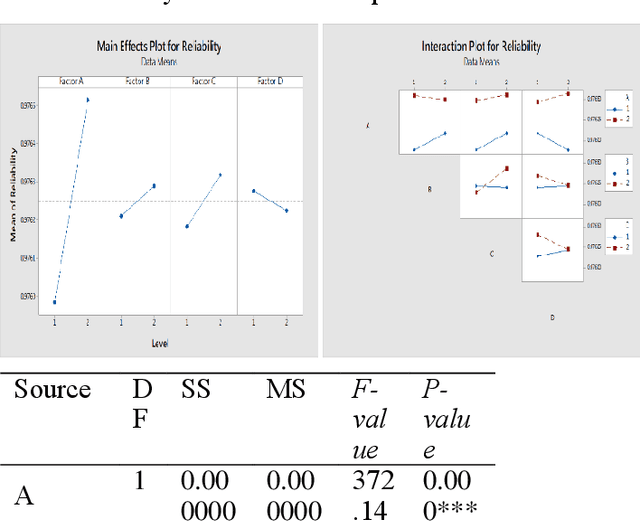
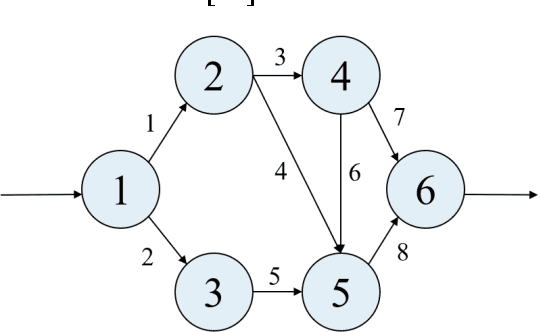
Network systems are commonly used in various fields, such as power grid, Internet of Things (IoT), and gas networks. Reliability redundancy allocation problem (RRAP) is a well-known reliability design tool, which needs to be developed when the system is extended from the series-parallel structure to a more general network structure. Therefore, this study proposes a novel RRAP called General RRAP (GRRAP) to be applied to network systems. The Binary Addition Tree Algorithm (BAT) is used to solve the network reliability. Since GRRAP is an NP-hard problem, a new algorithm called Binary-addition simplified swarm optimization (BSSO) is also proposed in this study. BSSO combines the accuracy of the BAT with the efficiency of SSO, which can effectively reduce the solution space and speed up the time to find high-quality solutions. The experimental results show that BSSO outperforms three well-known algorithms, Genetic Algorithm (GA), Particle Swarm Optimization (PSO), and Swarm Optimization (SSO), on six network benchmarks.
Convolution Neural Network Hyperparameter Optimization Using Simplified Swarm Optimization
Mar 06, 2021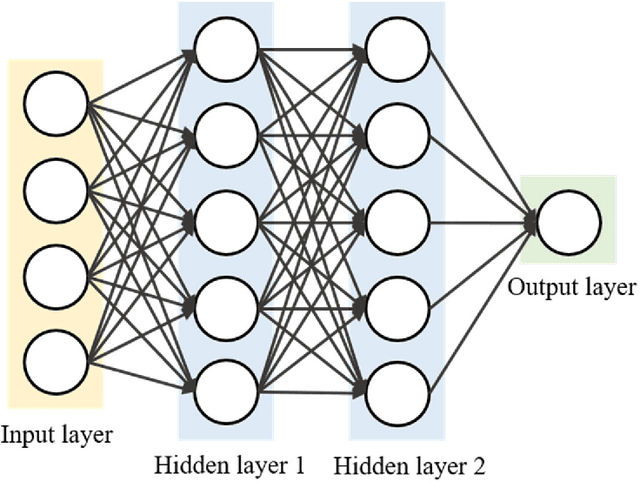
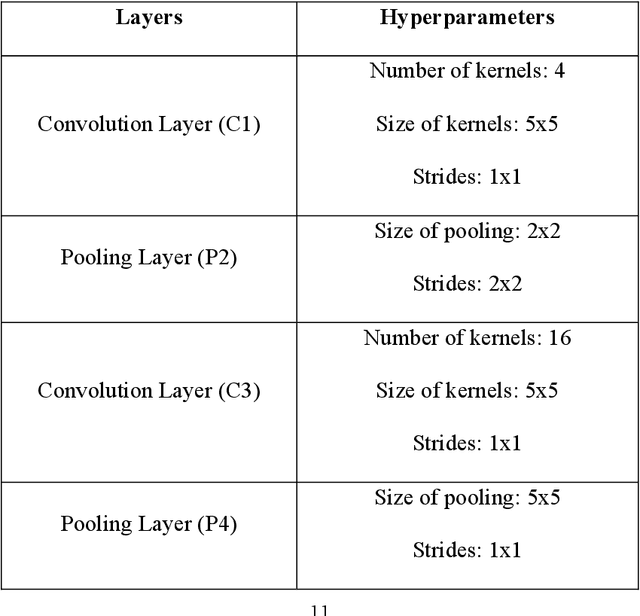
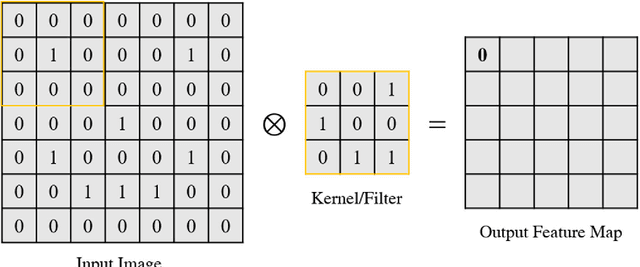
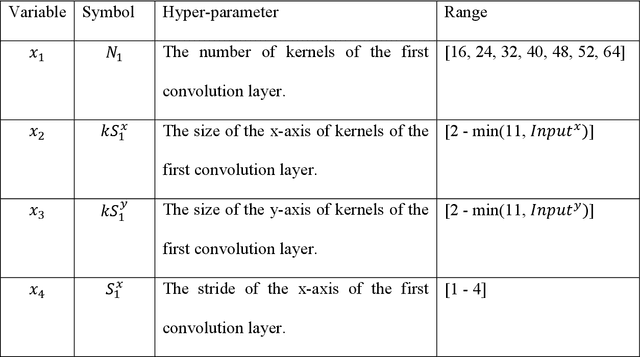
Among the machine learning approaches applied in computer vision, Convolutional Neural Network (CNN) is widely used in the field of image recognition. However, although existing CNN models have been proven to be efficient, it is not easy to find a network architecture with better performance. Some studies choose to optimize the network architecture, while others chose to optimize the hyperparameters, such as the number and size of convolutional kernels, convolutional strides, pooling size, etc. Most of them are designed manually, which requires relevant expertise and takes a lot of time. Therefore, this study proposes the idea of applying Simplified Swarm Optimization (SSO) on the hyperparameter optimization of LeNet models while using MNIST, Fashion MNIST, and Cifar10 as validation. The experimental results show that the proposed algorithm has higher accuracy than the original LeNet model, and it only takes a very short time to find a better hyperparameter configuration after training. In addition, we also analyze the output shape of the feature map after each layer, and surprisingly, the results were mostly rectangular. The contribution of the study is to provide users with a simpler way to get better results with the existing model., and this study can also be applied to other CNN architectures.
Simplified Swarm Optimization for Bi-Objection Active Reliability Redundancy Allocation Problems
Jun 17, 2020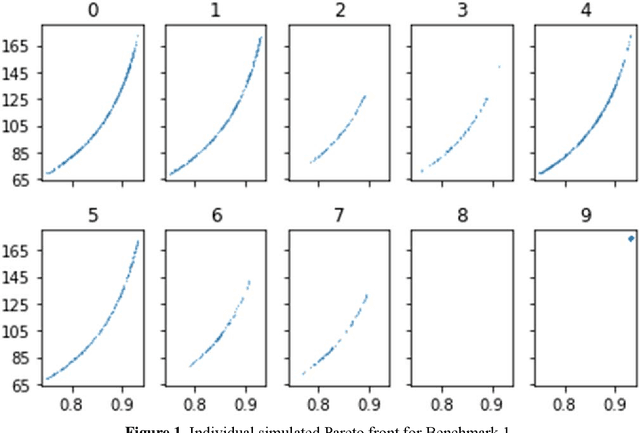
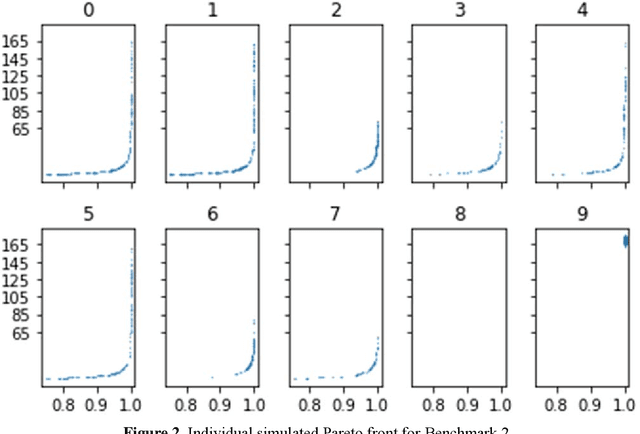

The reliability redundancy allocation problem (RRAP) is a well-known tool in system design, development, and management. The RRAP is always modeled as a nonlinear mixed-integer non-deterministic polynomial-time hardness (NP-hard) problem. To maximize the system reliability, the integer (component active redundancy level) and real variables (component reliability) must be determined to ensure that the cost limit and some nonlinear constraints are satisfied. In this study, a bi-objective RRAP is formulated by changing the cost constraint as a new goal, because it is necessary to balance the reliability and cost impact for the entire system in practical applications. To solve the proposed problem, a new simplified swarm optimization (SSO) with a penalty function, a real one-type solution structure, a number-based self-adaptive new update mechanism, a constrained nondominated-solution selection, and a new pBest replacement policy is developed in terms of these structures selected from full-factorial design to find the Pareto solutions efficiently and effectively. The proposed SSO outperforms several metaheuristic state-of-the-art algorithms, e.g., nondominated sorting genetic algorithm II (NSGA-II) and multi-objective particle swarm optimization (MOPSO), according to experimental results for four benchmark problems involving the bi-objective active RRAP.
Convolutional Support Vector Machine
Feb 11, 2020
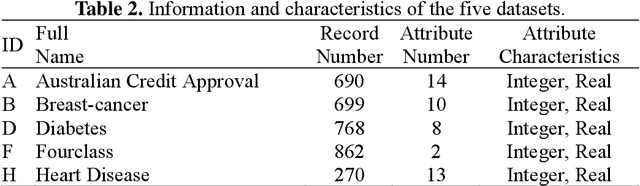
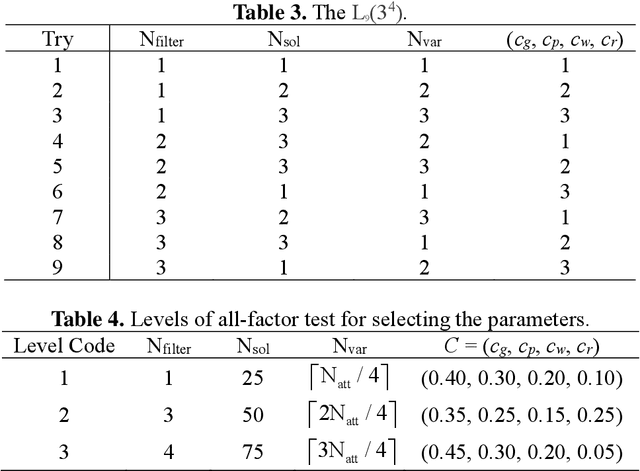
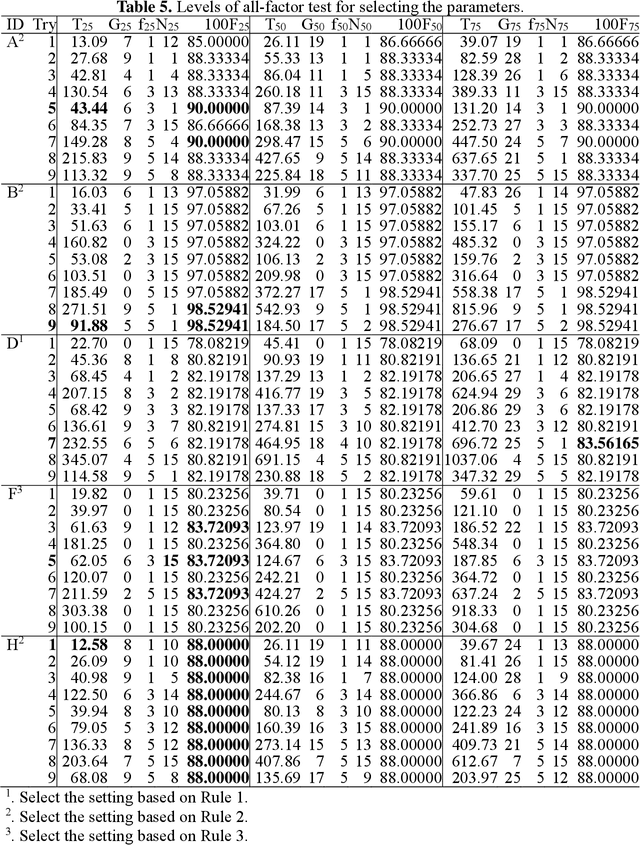
The support vector machine (SVM) and deep learning (e.g., convolutional neural networks (CNNs)) are the two most famous algorithms in small and big data, respectively. Nonetheless, smaller datasets may be very important, costly, and not easy to obtain in a short time. This paper proposes a novel convolutional SVM (CSVM) that has both advantages of CNN and SVM to improve the accuracy and effectiveness of mining smaller datasets. The proposed CSVM adapts the convolution product from CNN to learn new information hidden deeply in the datasets. In addition, it uses a modified simplified swarm optimization (SSO) to help train the CSVM to update classifiers, and then the traditional SVM is implemented as the fitness for the SSO to estimate the accuracy. To evaluate the performance of the proposed CSVM, experiments were conducted to test five well-known benchmark databases for the classification problem. Numerical experiments compared favorably with those obtained using SVM, 3-layer artificial NN (ANN), and 4-layer ANN. The results of these experiments verify that the proposed CSVM with the proposed SSO can effectively increase classification accuracy.
A Novel Generalized Artificial Neural Network for Mining Two-Class Datasets
Oct 23, 2019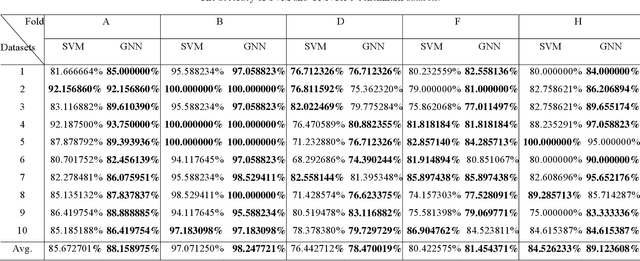
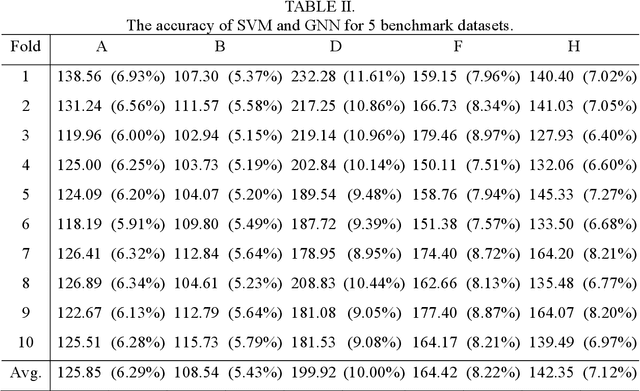
A novel general neural network (GNN) is proposed for two-class data mining in this study. In a GNN, each attribute in the dataset is treated as a node, with each pair of nodes being connected by an arc. The reliability is of each arc, which is similar to the weight in artificial neural network and must be solved using simplified swarm optimization (SSO), is constant. After the node reliability is made the transformed value of the related attribute, the approximate reliability of each GNN instance is calculated based on the proposed intelligent Monte Carlo simulation (iMCS). This approximate GNN reliability is then compared with a given threshold to predict each instance. The proposed iMCS-SSO is used to repeat the procedure and train the GNN, such that the predicted class values match the actual class values as much as possible. To evaluate the classification performance of the proposed GNN, experiments were performed on five well-known benchmark datasets. The computational results compared favorably with those obtained using support vector machines.