 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SiamCorners: Siamese Corner Networks for Visual Tracking
Apr 15, 2021

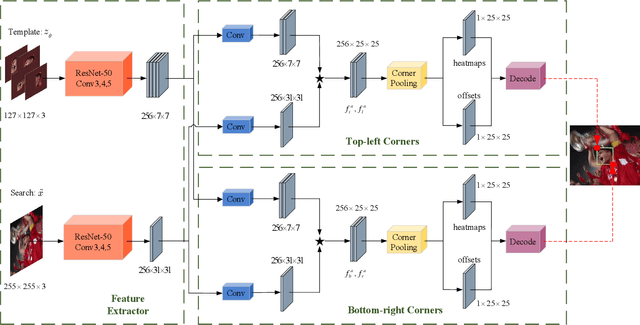


The current Siamese network based on region proposal network (RPN) has attracted great attention in visual tracking due to its excellent accuracy and high efficiency. However, the design of the RPN involves the selection of the number, scale, and aspect ratios of anchor boxes, which will affect the applicability and convenience of the model. Furthermore, these anchor boxes require complicated calculations, such as calculating their intersection-over-union (IoU) with ground truth bounding boxes.Due to the problems related to anchor boxes, we propose a simple yet effective anchor-free tracker (named Siamese corner networks, SiamCorners), which is end-to-end trained offline on large-scale image pairs. Specifically, we introduce a modified corner pooling layer to convert the bounding box estimate of the target into a pair of corner predictions (the bottom-right and the top-left corners). By tracking a target as a pair of corners, we avoid the need to design the anchor boxes. This will make the entire tracking algorithm more flexible and simple than anchorbased trackers. In our network design, we further introduce a layer-wise feature aggregation strategy that enables the corner pooling module to predict multiple corners for a tracking target in deep networks. We then introduce a new penalty term that is used to select an optimal tracking box in these candidate corners. Finally, SiamCorners achieves experimental results that are comparable to the state-of-art tracker while maintaining a high running speed. In particular, SiamCorners achieves a 53.7% AUC on NFS30 and a 61.4% AUC on UAV123, while still running at 42 frames per second (FPS).
Machine Learning-based Automatic Graphene Detection with Color Correction for Optical Microscope Images
Mar 24, 2021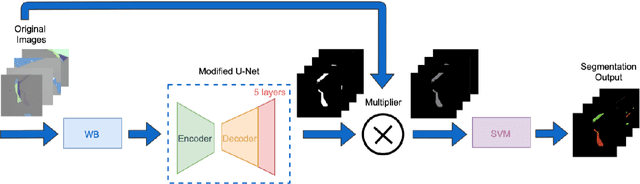
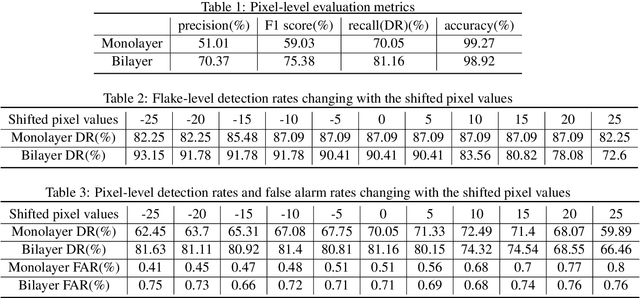


Graphene serves critical application and research purposes in various fields. However, fabricating high-quality and large quantities of graphene is time-consuming and it requires heavy human resource labor costs. In this paper, we propose a Machine Learning-based Automatic Graphene Detection Method with Color Correction (MLA-GDCC), a reliable and autonomous graphene detection from microscopic images. The MLA-GDCC includes a white balance (WB) to correct the color imbalance on the images, a modified U-Net and a support vector machine (SVM) to segment the graphene flakes. Considering the color shifts of the images caused by different cameras, we apply WB correction to correct the imbalance of the color pixels. A modified U-Net model, a convolutional neural network (CNN) architecture for fast and precise image segmentation, is introduced to segment the graphene flakes from the background. In order to improve the pixel-level accuracy, we implement a SVM after the modified U-Net model to separate the monolayer and bilayer graphene flakes. The MLA-GDCC achieves flake-level detection rates of 87.09% for monolayer and 90.41% for bilayer graphene, and the pixel-level accuracy of 99.27% for monolayer and 98.92% for bilayer graphene. MLA-GDCC not only achieves high detection rates of the graphene flakes but also speeds up the latency for the graphene detection process from hours to seconds.
GRAPPA-GANs for Parallel MRI Reconstruction
Jan 05, 2021
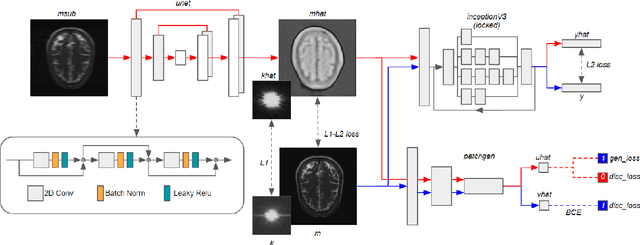
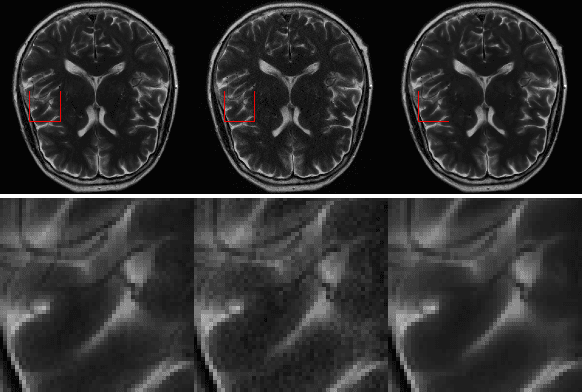
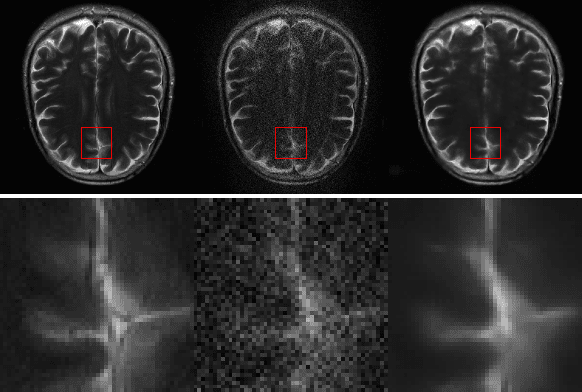
k-space undersampling is a standard technique to accelerate MR image acquisitions. Reconstruction techniques including GeneRalized Autocalibrating Partial Parallel Acquisition(GRAPPA) and its variants are utilized extensively in clinical and research settings. A reconstruction model combining GRAPPA with a conditional generative adversarial network (GAN) was developed and tested on multi-coil human brain images from the fastMRI dataset. For various acceleration rates, GAN and GRAPPA reconstructions were compared in terms of peak signal-to-noise ratio (PSNR) and structural similarity (SSIM). For an acceleration rate of R=4, PSNR improved from 33.88 using regularized GRAPPA to 37.65 using GAN. GAN consistently outperformed GRAPPA for various acceleration rates.
Multi-Source Domain Adaptation with Collaborative Learning for Semantic Segmentation
Mar 16, 2021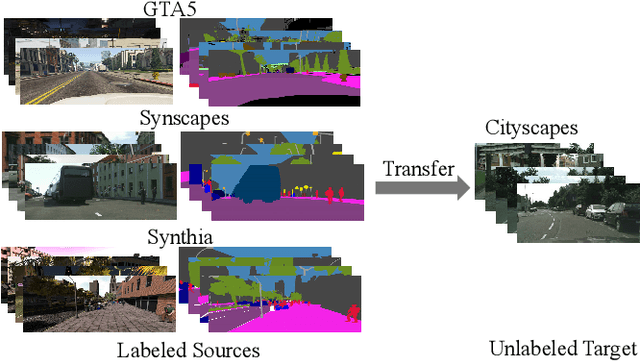
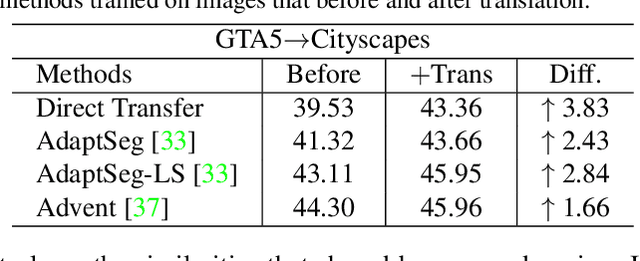
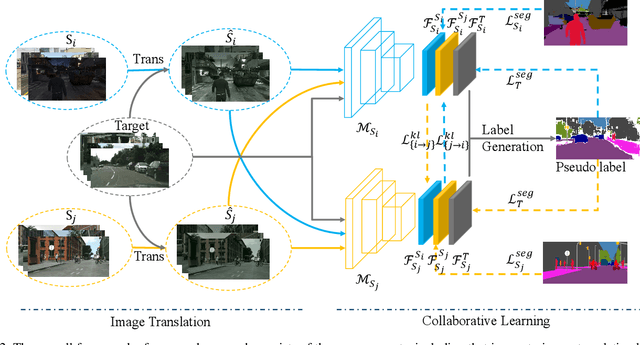
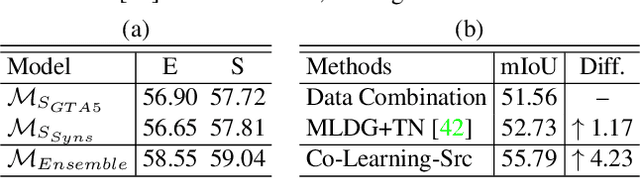
Multi-source unsupervised domain adaptation~(MSDA) aims at adapting models trained on multiple labeled source domains to an unlabeled target domain. In this paper, we propose a novel multi-source domain adaptation framework based on collaborative learning for semantic segmentation. Firstly, a simple image translation method is introduced to align the pixel value distribution to reduce the gap between source domains and target domain to some extent. Then, to fully exploit the essential semantic information across source domains, we propose a collaborative learning method for domain adaptation without seeing any data from target domain. In addition, similar to the setting of unsupervised domain adaptation, unlabeled target domain data is leveraged to further improve the performance of domain adaptation. This is achieved by additionally constraining the outputs of multiple adaptation models with pseudo labels online generated by an ensembled model. Extensive experiments and ablation studies are conducted on the widely-used domain adaptation benchmark datasets in semantic segmentation. Our proposed method achieves 59.0\% mIoU on the validation set of Cityscapes by training on the labeled Synscapes and GTA5 datasets and unlabeled training set of Cityscapes. It significantly outperforms all previous state-of-the-arts single-source and multi-source unsupervised domain adaptation methods.
Dual-stream Multiple Instance Learning Network for Whole Slide Image Classification with Self-supervised Contrastive Learning
Nov 17, 2020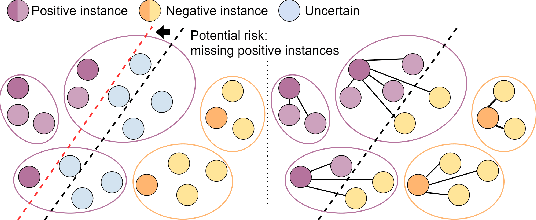
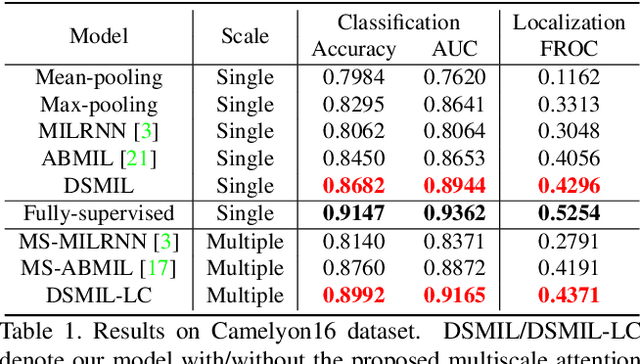
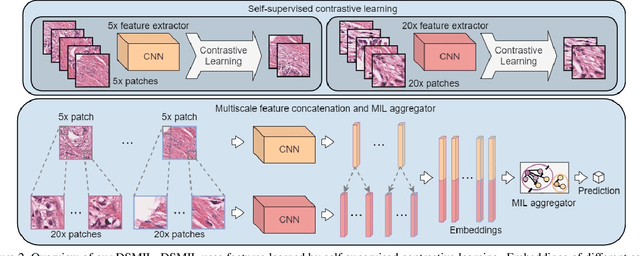
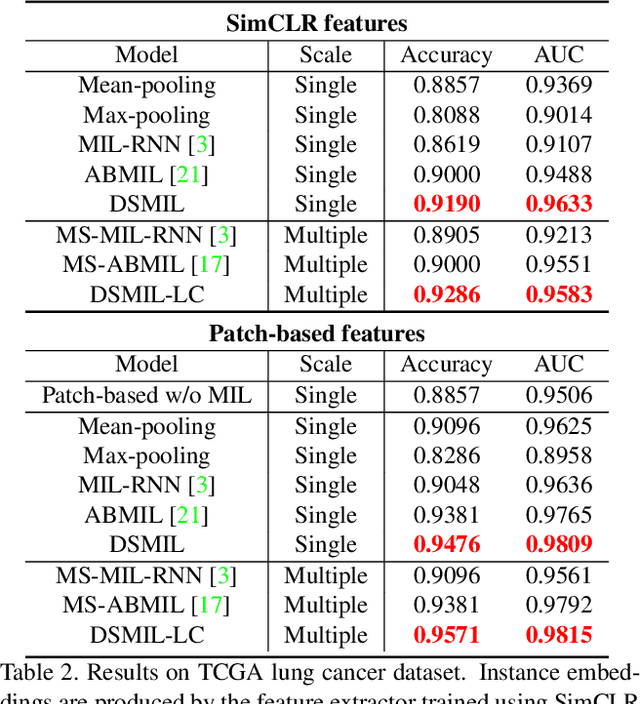
Whole slide images (WSIs) have large resolutions and usually lack localized annotations. WSI classification can be cast as a multiple instance learning (MIL) problem when only slide-level labels are available. We propose a MIL-based method for WSI classification and tumor detection in WSI that does not require localized annotations. First, we propose a novel MIL aggregator that models the relations of the instances in a dual-stream architecture with trainable distance measurement. Second, since WSIs can produce large or unbalanced bags that hinder the training of MIL models, we propose to use self-supervised contrastive learning to extract good representations for MIL and alleviate the issue of prohibitive memory requirement for large bags. Third, we propose a pyramidal fusion mechanism for multiscale WSI features that further improves the classification and localization accuracy. The classification accuracy of our model compares favorably to fully-supervised methods, with less than 2\% accuracy gap on two representative WSI datasets, and outperforms all previous MIL-based methods. Benchmark results on standard MIL datasets further show the superior performance of our MIL aggregator over other MIL models on general MIL problems.
Do Input Gradients Highlight Discriminative Features?
Feb 25, 2021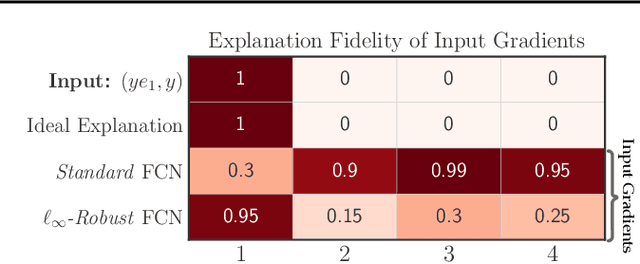

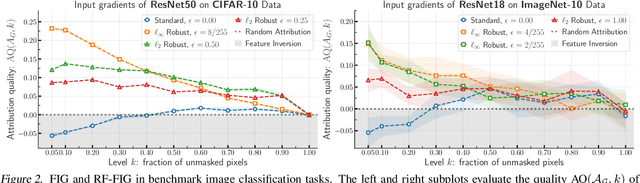
Interpretability methods that seek to explain instance-specific model predictions [Simonyan et al. 2014, Smilkov et al. 2017] are often based on the premise that the magnitude of input-gradient -- gradient of the loss with respect to input -- highlights discriminative features that are relevant for prediction over non-discriminative features that are irrelevant for prediction. In this work, we introduce an evaluation framework to study this hypothesis for benchmark image classification tasks, and make two surprising observations on CIFAR-10 and Imagenet-10 datasets: (a) contrary to conventional wisdom, input gradients of standard models (i.e., trained on the original data) actually highlight irrelevant features over relevant features; (b) however, input gradients of adversarially robust models (i.e., trained on adversarially perturbed data) starkly highlight relevant features over irrelevant features. To better understand input gradients, we introduce a synthetic testbed and theoretically justify our counter-intuitive empirical findings. Our observations motivate the need to formalize and verify common assumptions in interpretability, while our evaluation framework and synthetic dataset serve as a testbed to rigorously analyze instance-specific interpretability methods.
Demonstrating the Evolution of GANs through t-SNE
Feb 25, 2021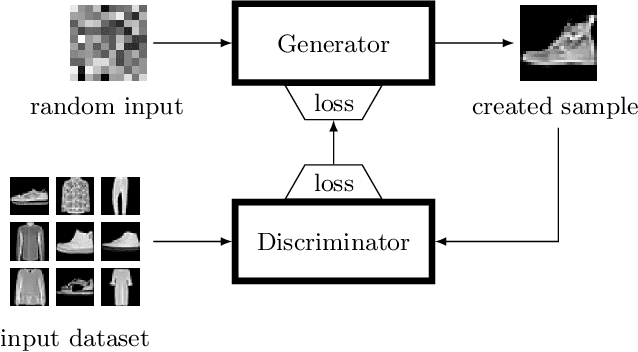
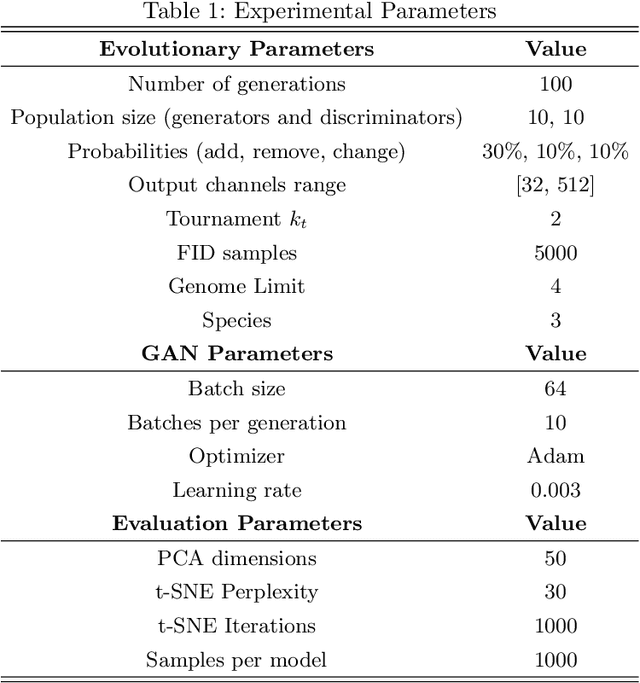
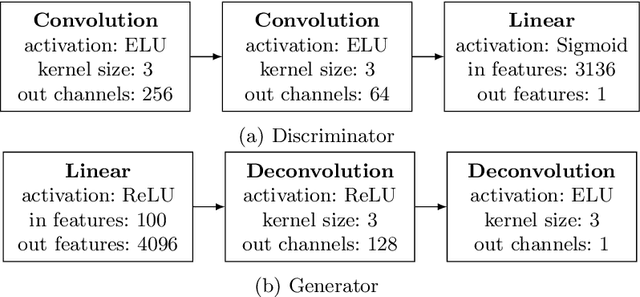
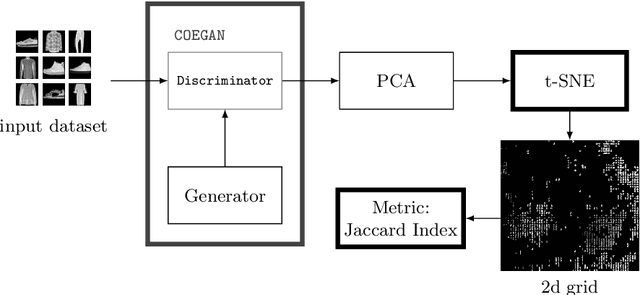
Generative Adversarial Networks (GANs) are powerful generative models that achieved strong results, mainly in the image domain. However, the training of GANs is not trivial, presenting some challenges tackled by different strategies. Evolutionary algorithms, such as COEGAN, were recently proposed as a solution to improve the GAN training, overcoming common problems that affect the model, such as vanishing gradient and mode collapse. In this work, we propose an evaluation method based on t-distributed Stochastic Neighbour Embedding (t-SNE) to assess the progress of GANs and visualize the distribution learned by generators in training. We propose the use of the feature space extracted from trained discriminators to evaluate samples produced by generators and from the input dataset. A metric based on the resulting t-SNE maps and the Jaccard index is proposed to represent the model quality. Experiments were conducted to assess the progress of GANs when trained using COEGAN. The results show both by visual inspection and metrics that the Evolutionary Algorithm gradually improves discriminators and generators through generations, avoiding problems such as mode collapse.
Image-based Automated Species Identification: Can Virtual Data Augmentation Overcome Problems of Insufficient Sampling?
Oct 18, 2020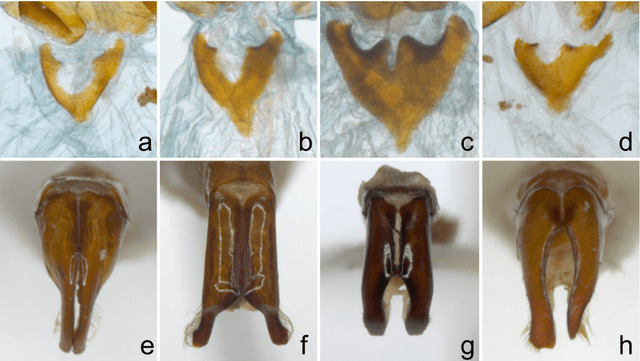

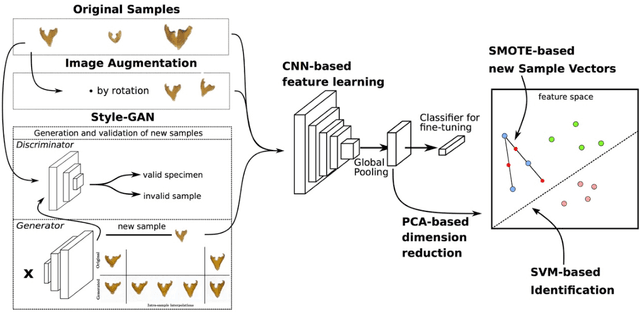

Automated species identification and delimitation is challenging, particularly in rare and thus often scarcely sampled species, which do not allow sufficient discrimination of infraspecific versus interspecific variation. Typical problems arising from either low or exaggerated interspecific morphological differentiation are best met by automated methods of machine learning that learn efficient and effective species identification from training samples. However, limited infraspecific sampling remains a key challenge also in machine learning. 1In this study, we assessed whether a two-level data augmentation approach may help to overcome the problem of scarce training data in automated visual species identification. The first level of visual data augmentation applies classic approaches of data augmentation and generation of faked images using a GAN approach. Descriptive feature vectors are derived from bottleneck features of a VGG-16 convolutional neural network (CNN) that are then stepwise reduced in dimensionality using Global Average Pooling and PCA to prevent overfitting. The second level of data augmentation employs synthetic additional sampling in feature space by an oversampling algorithm in vector space (SMOTE). Applied on two challenging datasets of scarab beetles (Coleoptera), our augmentation approach outperformed a non-augmented deep learning baseline approach as well as a traditional 2D morphometric approach (Procrustes analysis).
Segmentation of Lungs in Chest X-Ray Image Using Generative Adversarial Networks
Sep 12, 2020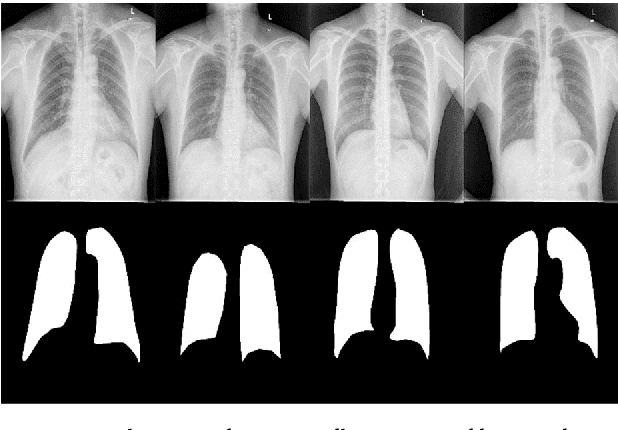

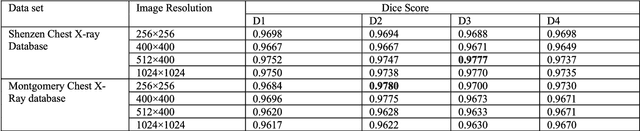
Chest X-ray (CXR) is a low-cost medical imaging technique. It is a common procedure for the identification of many respiratory diseases compared to MRI, CT, and PET scans. This paper presents the use of generative adversarial networks (GAN) to perform the task of lung segmentation on a given CXR. GANs are popular to generate realistic data by learning the mapping from one domain to another. In our work, the generator of the GAN is trained to generate a segmented mask of a given input CXR. The discriminator distinguishes between a ground truth and the generated mask, and updates the generator through the adversarial loss measure. The objective is to generate masks for the input CXR, which are as realistic as possible compared to the ground truth masks. The model is trained and evaluated using four different discriminators referred to as D1, D2, D3, and D4, respectively. Experimental results on three different CXR datasets reveal that the proposed model is able to achieve a dice-score of 0.9740, and IOU score of 0.943, which are better than other reported state-of-the art results.
* Volume 8, August 2020, Pages 153535 - 153545
Blind Inverse Gamma Correction with Maximized Differential Entropy
Jul 05, 2020
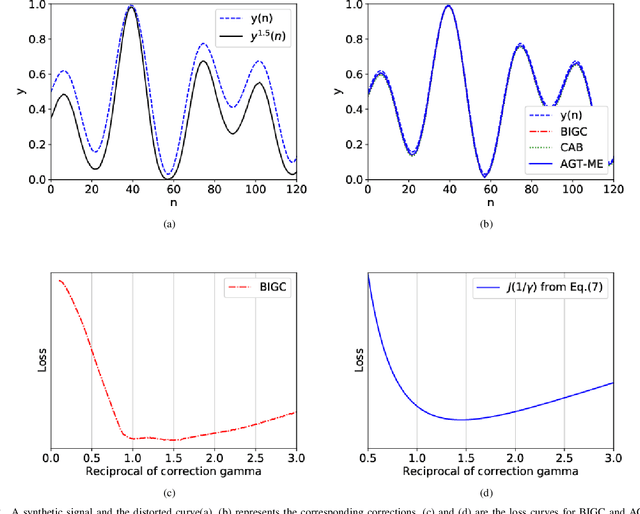

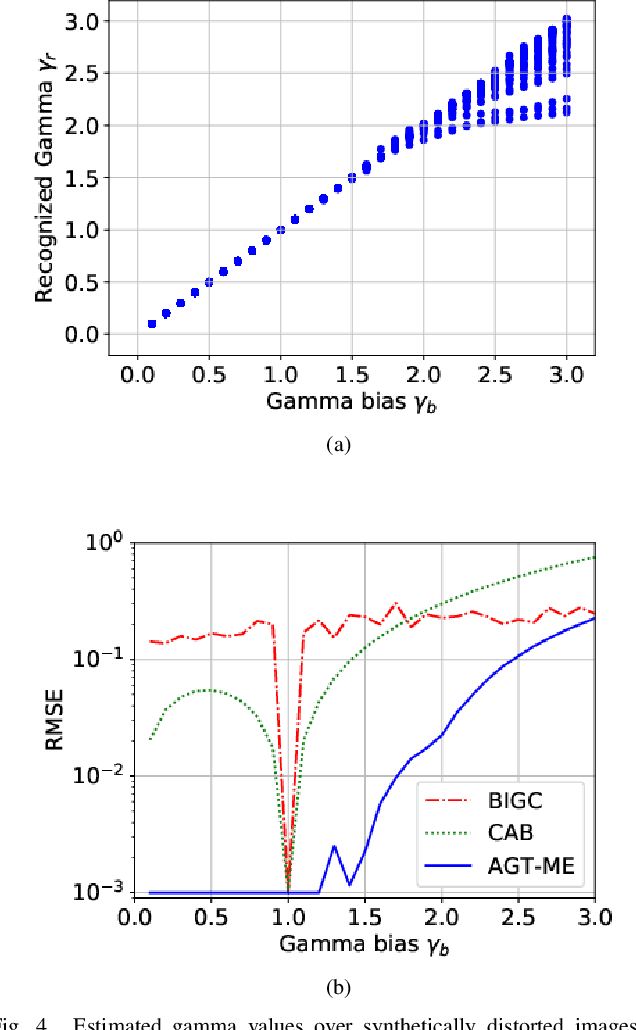
Unwanted nonlinear gamma distortion frequently occurs in a great diversity of images during the procedures of image acquisition, processing, and/or display. And the gamma distortion often varies with capture setup change and luminance variation. Blind inverse gamma correction, which automatically determines a proper restoration gamma value from a given image, is of paramount importance to attenuate the distortion. For blind inverse gamma correction, an adaptive gamma transformation method (AGT-ME) is proposed directly from a maximized differential entropy model. And the corresponding optimization has a mathematical concise closed-form solution, resulting in efficient implementation and accurate gamma restoration of AGT-ME. Considering the human eye has a non-linear perception sensitivity, a modified version AGT-ME-VISUAL is also proposed to achieve better visual performance. Tested on variable datasets, AGT-ME could obtain an accurate estimation of a large range of gamma distortion (0.1 to 3.0), outperforming the state-of-the-art methods. Besides, the proposed AGT-ME and AGT-ME-VISUAL were applied to three typical applications, including automatic gamma adjustment, natural/medical image contrast enhancement, and fringe projection profilometry image restoration. Furthermore, the AGT-ME/ AGT-ME-VISUAL is general and can be seamlessly extended to the masked image, multi-channel (color or spectrum) image, or multi-frame video, and free of the arbitrary tuning parameter. Besides, the corresponding Python code (https://github.com/yongleex/AGT-ME) is also provided for interested users.