 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the impact of fairness-aware criteria in AutoML
Apr 11, 2026Machine Learning (ML) systems are increasingly used to support decision-making processes that affect individuals. However, these systems often rely on biased data, which can lead to unfair outcomes against specific groups. With the growing adoption of Automated Machine Learning (AutoML), the risk of intensifying discriminatory behaviours increases, as most frameworks primarily focus on model selection to maximise predictive performance. Previous research on fairness in AutoML had largely followed this trend, integrating fairness awareness only in the model selection or hyperparameter tuning, while neglecting other critical stages of the ML pipeline. This paper aims to study the impact of integrating fairness directly into the optimisation component of an AutoML framework that constructs complete ML pipelines, from data selection and transformations to model selection and tuning. As selecting appropriate fairness metrics remains a key challenge, our work incorporates complementary fairness metrics to capture different dimensions of fairness during the optimisation. Their integration within AutoML resulted in measurable differences compared to a baseline focused solely on predictive performance. Despite a 9.4% decrease in predictive power, the average fairness improved by 14.5%, accompanied by a 35.7% reduction in data usage. Furthermore, fairness integration produced complete yet simpler final solutions, suggesting that model complexity is not always required to achieve balanced and fair ML solutions.
Evolutionary Token-Level Prompt Optimization for Diffusion Models
Apr 10, 2026Text-to-image diffusion models exhibit strong generative performance but remain highly sensitive to prompt formulation, often requiring extensive manual trial and error to obtain satisfactory results. This motivates the development of automated, model-agnostic prompt optimization methods that can systematically explore the conditioning space beyond conventional text rewriting. This work investigates the use of a Genetic Algorithm (GA) for prompt optimization by directly evolving the token vectors employed by CLIP-based diffusion models. The GA optimizes a fitness function that combines aesthetic quality, measured by the LAION Aesthetic Predictor V2, with prompt-image alignment, assessed via CLIPScore. Experiments on 36 prompts from the Parti Prompts (P2) dataset show that the proposed approach outperforms the baseline methods, including Promptist and random search, achieving up to a 23.93% improvement in fitness. Overall, the method is adaptable to image generation models with tokenized text encoders and provides a modular framework for future extensions, the limitations and prospects of which are discussed.
Evolutionary Optimization Trumps Adam Optimization on Embedding Space Exploration
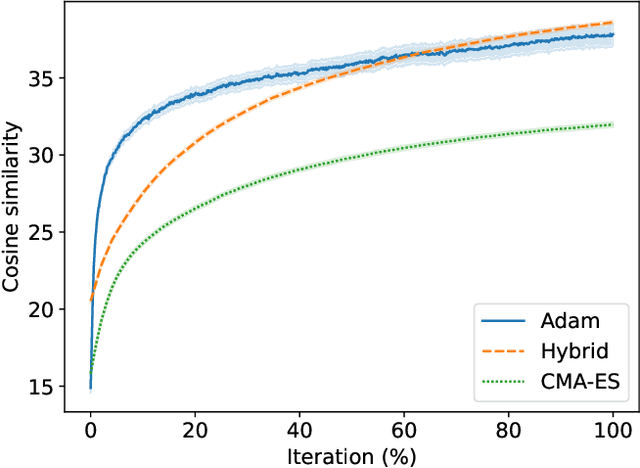
Nov 05, 2025Deep generative models, especially diffusion architectures, have transformed image generation; however, they are challenging to control and optimize for specific goals without expensive retraining. Embedding Space Exploration, especially with Evolutionary Algorithms (EAs), has been shown to be a promising method for optimizing image generation, particularly within Diffusion Models. Therefore, in this work, we study the performance of an evolutionary optimization method, namely Separable Covariance Matrix Adaptation Evolution Strategy (sep-CMA-ES), against the widely adopted Adaptive Moment Estimation (Adam), applied to Stable Diffusion XL Turbo's prompt embedding vector. The evaluation of images combines the LAION Aesthetic Predictor V2 with CLIPScore into a weighted fitness function, allowing flexible trade-offs between visual appeal and adherence to prompts. Experiments on a subset of the Parti Prompts (P2) dataset showcase that sep-CMA-ES consistently yields superior improvements in aesthetic and alignment metrics in comparison to Adam. Results indicate that the evolutionary method provides efficient, gradient-free optimization for diffusion models, enhancing controllability without the need for fine-tuning. This study emphasizes the potential of evolutionary methods for embedding space exploration of deep generative models and outlines future research directions.
Evolutionary algorithms meet self-supervised learning: a comprehensive survey
Apr 09, 2025The number of studies that combine Evolutionary Machine Learning and self-supervised learning has been growing steadily in recent years. Evolutionary Machine Learning has been shown to help automate the design of machine learning algorithms and to lead to more reliable solutions. Self-supervised learning, on the other hand, has produced good results in learning useful features when labelled data is limited. This suggests that the combination of these two areas can help both in shaping evolutionary processes and in automating the design of deep neural networks, while also reducing the need for labelled data. Still, there are no detailed reviews that explain how Evolutionary Machine Learning and self-supervised learning can be used together. To help with this, we provide an overview of studies that bring these areas together. Based on this growing interest and the range of existing works, we suggest a new sub-area of research, which we call Evolutionary Self-Supervised Learning and introduce a taxonomy for it. Finally, we point out some of the main challenges and suggest directions for future research to help Evolutionary Self-Supervised Learning grow and mature as a field.
EDCA -- An Evolutionary Data-Centric AutoML Framework for Efficient Pipelines
Mar 06, 2025



Automated Machine Learning (AutoML) gained popularity due to the increased demand for Machine Learning (ML) specialists, allowing them to apply ML techniques effortlessly and quickly. AutoML implementations use optimisation methods to identify the most effective ML solution for a given dataset, aiming to improve one or more predefined metrics. However, most implementations focus on model selection and hyperparameter tuning. Despite being an important factor in obtaining high-performance ML systems, data quality is usually an overlooked part of AutoML and continues to be a manual and time-consuming task. This work presents EDCA, an Evolutionary Data Centric AutoML framework. In addition to the traditional tasks such as selecting the best models and hyperparameters, EDCA enhances the given data by optimising data processing tasks such as data reduction and cleaning according to the problems' needs. All these steps create an ML pipeline that is optimised by an evolutionary algorithm. To assess its effectiveness, EDCA was compared to FLAML and TPOT, two frameworks at the top of the AutoML benchmarks. The frameworks were evaluated in the same conditions using datasets from AMLB classification benchmarks. EDCA achieved statistically similar results in performance to FLAML and TPOT but used significantly less data to train the final solutions. Moreover, EDCA experimental results reveal that a good performance can be achieved using less data and efficient ML algorithm aspects that align with Green AutoML guidelines
Towards evolution of Deep Neural Networks through contrastive Self-Supervised learning
Jun 20, 2024



Deep Neural Networks (DNNs) have been successfully applied to a wide range of problems. However, two main limitations are commonly pointed out. The first one is that they require long time to design. The other is that they heavily rely on labelled data, which can sometimes be costly and hard to obtain. In order to address the first problem, neuroevolution has been proved to be a plausible option to automate the design of DNNs. As for the second problem, self-supervised learning has been used to leverage unlabelled data to learn representations. Our goal is to study how neuroevolution can help self-supervised learning to bridge the gap to supervised learning in terms of performance. In this work, we propose a framework that is able to evolve deep neural networks using self-supervised learning. Our results on the CIFAR-10 dataset show that it is possible to evolve adequate neural networks while reducing the reliance on labelled data. Moreover, an analysis to the structure of the evolved networks suggests that the amount of labelled data fed to them has less effect on the structure of networks that learned via self-supervised learning, when compared to individuals that relied on supervised learning.
Automatic Design of Telecom Networks with Genetic Algorithms
Apr 02, 2023With the increasing demand for high-quality internet services, deploying GPON/Fiber-to-the-Home networks is one of the biggest challenges that internet providers have to deal with due to the significant investments involved. Automated network design usage becomes more critical to aid with planning the network by minimising the costs of planning and deployment. The main objective is to tackle this problem of optimisation of networks that requires taking into account multiple factors such as the equipment placement and their configuration, the optimisation of the cable routes, the optimisation of the clients' allocation and other constraints involved in the minimisation problem. An AI-based solution is proposed to automate network design, which is a task typically done manually by teams of engineers. It is a difficult task requiring significant time to complete manually. To alleviate this tiresome task, we proposed a Genetic Algorithm using a two-level representation to design the networks automatically. To validate the approach, we compare the quality of the generated solutions with the handmade design ones that are deployed in the real world. The results show that our method can save costs and time in finding suitable and better solutions than existing ones, indicating its potential as a support design tool of solutions for GPON/Fiber-to-the-Home networks. In concrete, in the two scenarios where we validate our proposal, our approach can cut costs by 31% and by 52.2%, respectively, when compared with existing handmade ones, showcasing and validating the potential of the proposed approach.
Reducing the Price of Stable Cable Stayed Bridges with CMA-ES
Apr 02, 2023



The design of cable-stayed bridges requires the determination of several design variables' values. Civil engineers usually perform this task by hand as an iteration of steps that stops when the engineer is happy with both the cost and maintaining the structural constraints of the solution. The problem's difficulty arises from the fact that changing a variable may affect other variables, meaning that they are not independent, suggesting that we are facing a deceptive landscape. In this work, we compare two approaches to a baseline solution: a Genetic Algorithm and a CMA-ES algorithm. There are two objectives when designing the bridges: minimizing the cost and maintaining the structural constraints in acceptable values to be considered safe. These are conflicting objectives, meaning that decreasing the cost often results in a bridge that is not structurally safe. The results suggest that CMA-ES is a better option for finding good solutions in the search space, beating the baseline with the same amount of evaluations, while the Genetic Algorithm could not. In concrete, the CMA-ES approach is able to design bridges that are cheaper and structurally safe.
Exploring Generative Adversarial Networks for Text-to-Image Generation with Evolution Strategies
Jul 06, 2022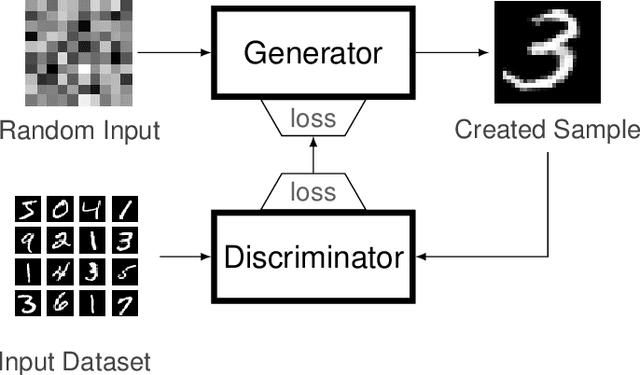
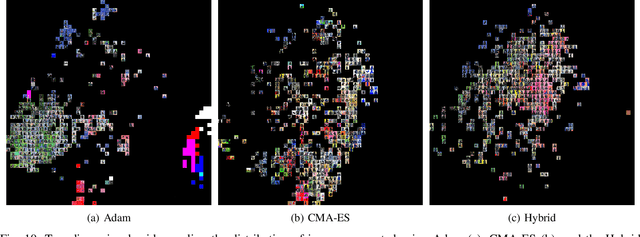

In the context of generative models, text-to-image generation achieved impressive results in recent years. Models using different approaches were proposed and trained in huge datasets of pairs of texts and images. However, some methods rely on pre-trained models such as Generative Adversarial Networks, searching through the latent space of the generative model by using a gradient-based approach to update the latent vector, relying on loss functions such as the cosine similarity. In this work, we follow a different direction by proposing the use of Covariance Matrix Adaptation Evolution Strategy to explore the latent space of Generative Adversarial Networks. We compare this approach to the one using Adam and a hybrid strategy. We design an experimental study to compare the three approaches using different text inputs for image generation by adapting an evaluation method based on the projection of the resulting samples into a two-dimensional grid to inspect the diversity of the distributions. The results evidence that the evolutionary method achieves more diversity in the generation of samples, exploring different regions of the resulting grids. Besides, we show that the hybrid method combines the explored areas of the gradient-based and evolutionary approaches, leveraging the quality of the results.
TensorGP -- Genetic Programming Engine in TensorFlow
Mar 12, 2021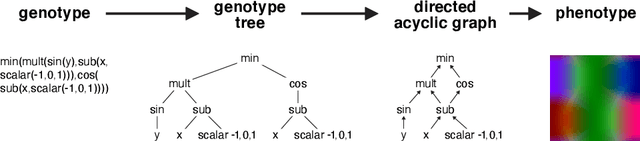
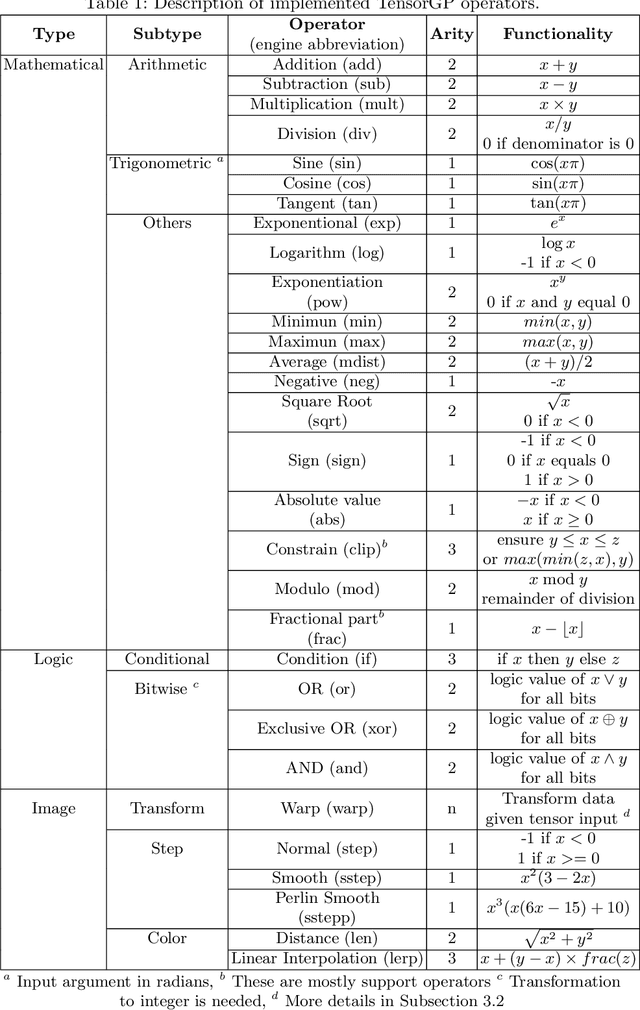

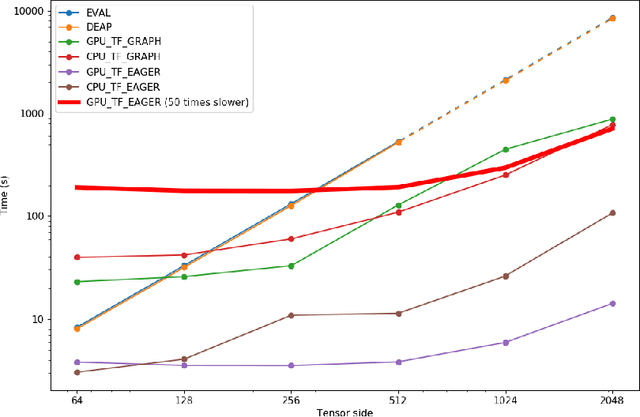
In this paper, we resort to the TensorFlow framework to investigate the benefits of applying data vectorization and fitness caching methods to domain evaluation in Genetic Programming. For this purpose, an independent engine was developed, TensorGP, along with a testing suite to extract comparative timing results across different architectures and amongst both iterative and vectorized approaches. Our performance benchmarks demonstrate that by exploiting the TensorFlow eager execution model, performance gains of up to two orders of magnitude can be achieved on a parallel approach running on dedicated hardware when compared to a standard iterative approach.