 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-stream Multiple Instance Learning Network for Whole Slide Image Classification with Self-supervised Contrastive Learning
Nov 17, 2020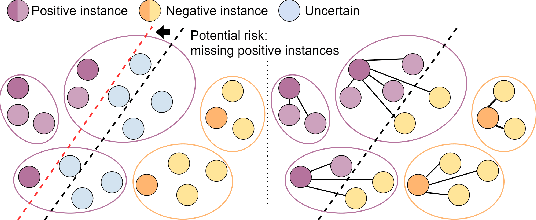
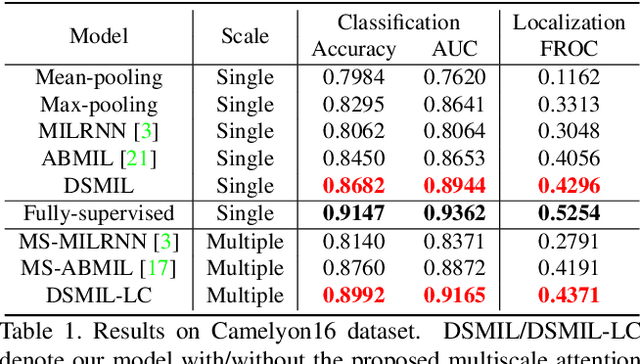
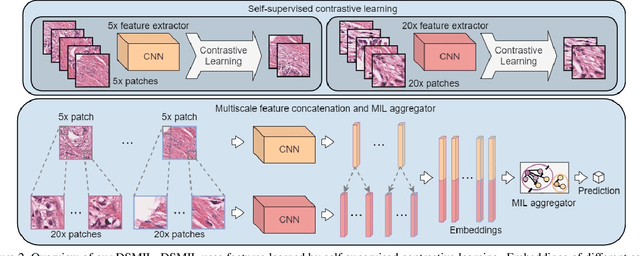
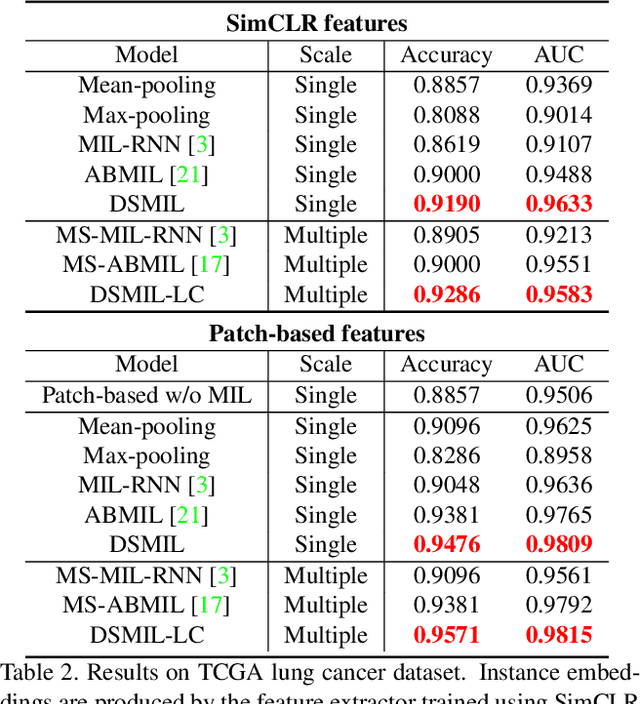
Whole slide images (WSIs) have large resolutions and usually lack localized annotations. WSI classification can be cast as a multiple instance learning (MIL) problem when only slide-level labels are available. We propose a MIL-based method for WSI classification and tumor detection in WSI that does not require localized annotations. First, we propose a novel MIL aggregator that models the relations of the instances in a dual-stream architecture with trainable distance measurement. Second, since WSIs can produce large or unbalanced bags that hinder the training of MIL models, we propose to use self-supervised contrastive learning to extract good representations for MIL and alleviate the issue of prohibitive memory requirement for large bags. Third, we propose a pyramidal fusion mechanism for multiscale WSI features that further improves the classification and localization accuracy. The classification accuracy of our model compares favorably to fully-supervised methods, with less than 2\% accuracy gap on two representative WSI datasets, and outperforms all previous MIL-based methods. Benchmark results on standard MIL datasets further show the superior performance of our MIL aggregator over other MIL models on general MIL problems.
Dual-stream Maximum Self-attention Multi-instance Learning
Jun 09, 2020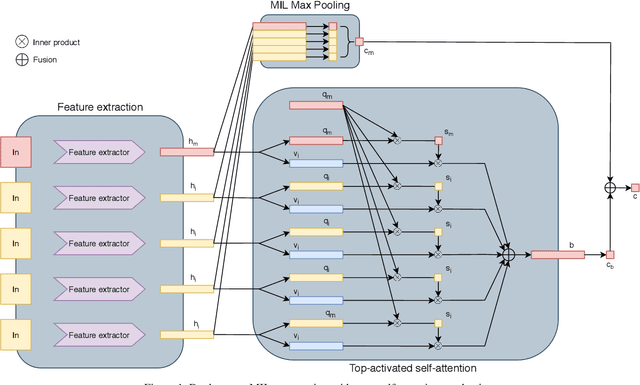
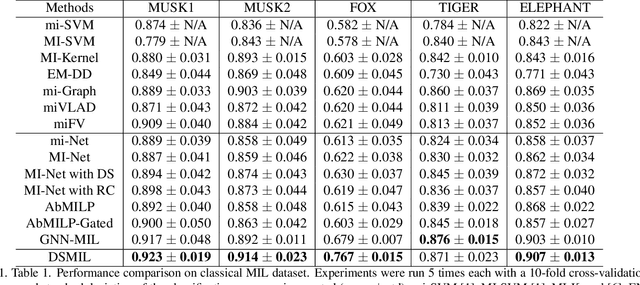
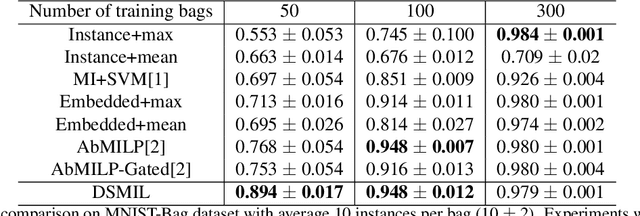

Multi-instance learning (MIL) is a form of weakly supervised learning where a single class label is assigned to a bag of instances while the instance-level labels are not available. Training classifiers to accurately determine the bag label and instance labels is a challenging but critical task in many practical scenarios, such as computational histopathology. Recently, MIL models fully parameterized by neural networks have become popular due to the high flexibility and superior performance. Most of these models rely on attention mechanisms that assign attention scores across the instance embeddings in a bag and produce the bag embedding using an aggregation operator. In this paper, we proposed a dual-stream maximum self-attention MIL model (DSMIL) parameterized by neural networks. The first stream deploys a simple MIL max-pooling while the top-activated instance embedding is determined and used to obtain self-attention scores across instance embeddings in the second stream. Different from most of the previous methods, the proposed model jointly learns an instance classifier and a bag classifier based on the same instance embeddings. The experiments results show that our method achieves superior performance compared to the best MIL methods and demonstrates state-of-the-art performance on benchmark MIL datasets.