 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structure-preserving Guided Retinal Image Filtering and Its Application for Optic Disc Analysis
May 22, 2018
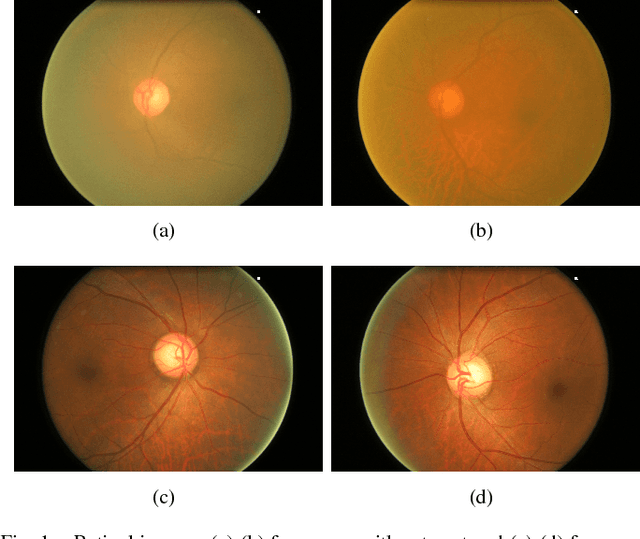
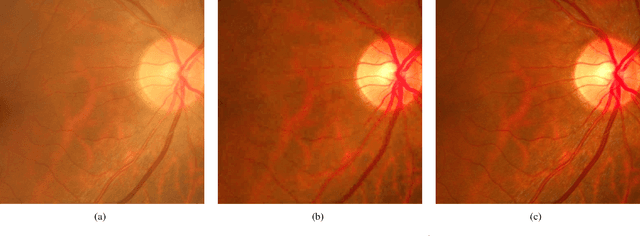

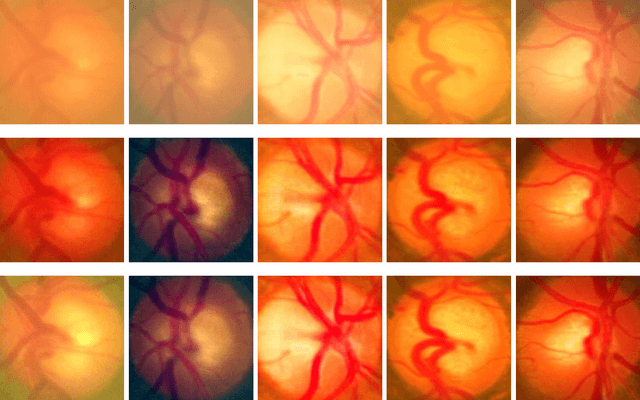
Retinal fundus photographs have been used in the diagnosis of many ocular diseases such as glaucoma, pathological myopia, age-related macular degeneration and diabetic retinopathy. With the development of computer science, computer aided diagnosis has been developed to process and analyse the retinal images automatically. One of the challenges in the analysis is that the quality of the retinal image is often degraded. For example, a cataract in human lens will attenuate the retinal image, just as a cloudy camera lens which reduces the quality of a photograph. It often obscures the details in the retinal images and posts challenges in retinal image processing and analysing tasks. In this paper, we approximate the degradation of the retinal images as a combination of human-lens attenuation and scattering. A novel structure-preserving guided retinal image filtering (SGRIF) is then proposed to restore images based on the attenuation and scattering model. The proposed SGRIF consists of a step of global structure transferring and a step of global edge-preserving smoothing. Our results show that the proposed SGRIF method is able to improve the contrast of retinal images, measured by histogram flatness measure, histogram spread and variability of local luminosity. In addition, we further explored the benefits of SGRIF for subsequent retinal image processing and analysing tasks. In the two applications of deep learning based optic cup segmentation and sparse learning based cup-to-disc ratio (CDR) computation, our results show that we are able to achieve more accurate optic cup segmentation and CDR measurements from images processed by SGRIF.
* Accepted for publication on IEEE Trans. on Medical Imaging
Cross-Modal Generalization: Learning in Low Resource Modalities via Meta-Alignment
Dec 04, 2020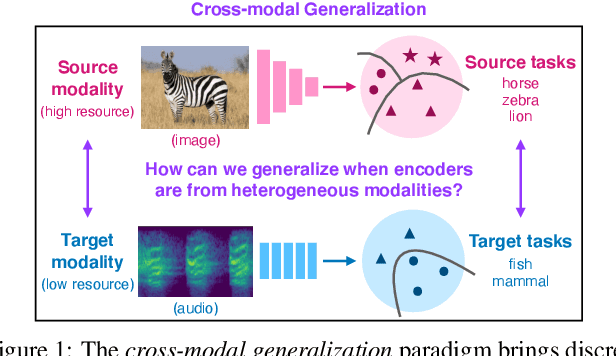
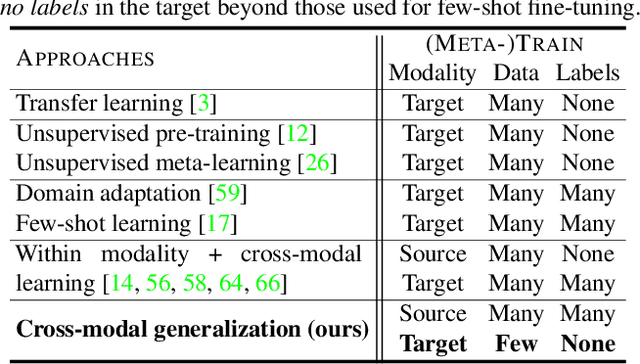
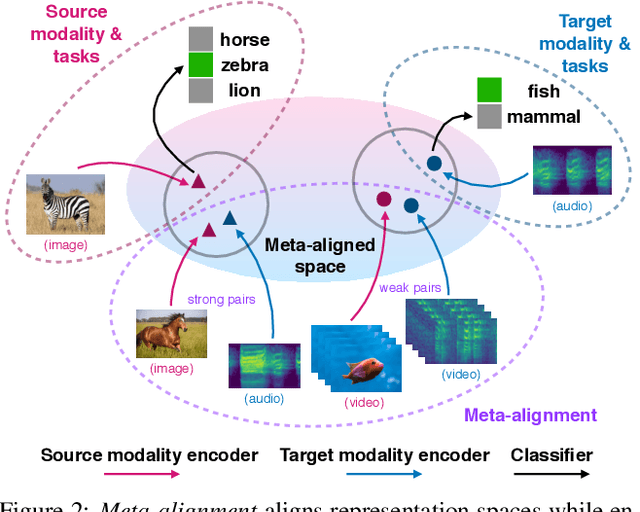
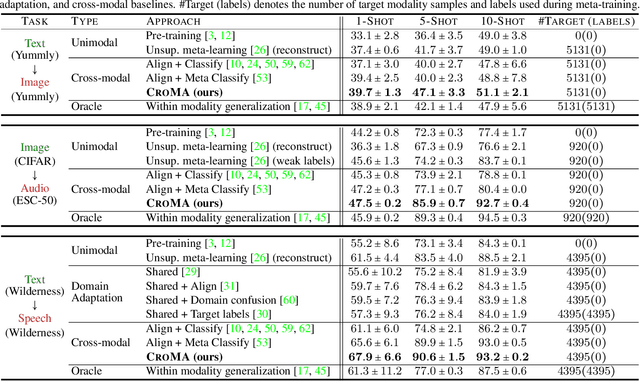
The natural world is abundant with concepts expressed via visual, acoustic, tactile, and linguistic modalities. Much of the existing progress in multimodal learning, however, focuses primarily on problems where the same set of modalities are present at train and test time, which makes learning in low-resource modalities particularly difficult. In this work, we propose algorithms for cross-modal generalization: a learning paradigm to train a model that can (1) quickly perform new tasks in a target modality (i.e. meta-learning) and (2) doing so while being trained on a different source modality. We study a key research question: how can we ensure generalization across modalities despite using separate encoders for different source and target modalities? Our solution is based on meta-alignment, a novel method to align representation spaces using strongly and weakly paired cross-modal data while ensuring quick generalization to new tasks across different modalities. We study this problem on 3 classification tasks: text to image, image to audio, and text to speech. Our results demonstrate strong performance even when the new target modality has only a few (1-10) labeled samples and in the presence of noisy labels, a scenario particularly prevalent in low-resource modalities.
A Locally Adapting Technique for Boundary Detection using Image Segmentation
Jul 27, 2017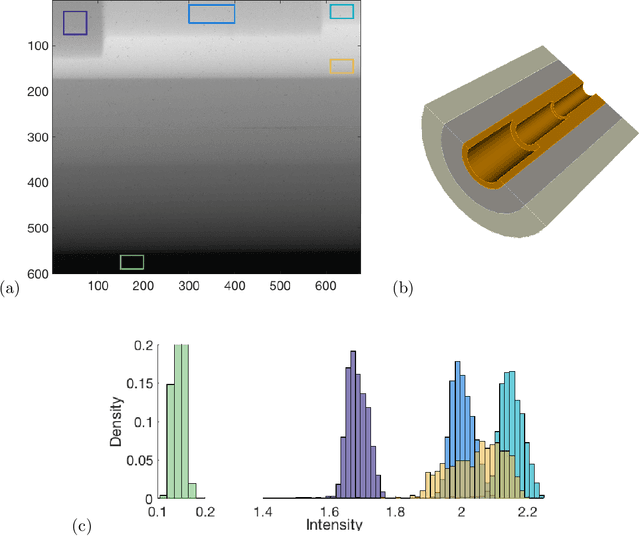
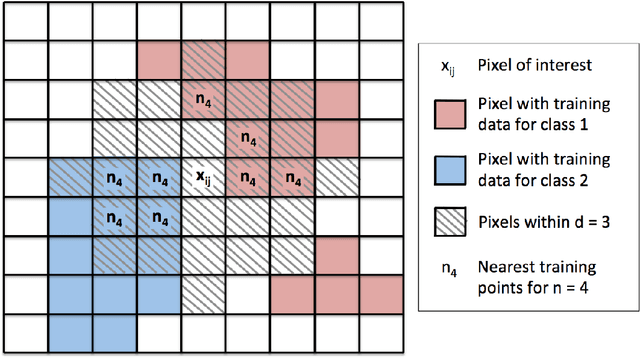
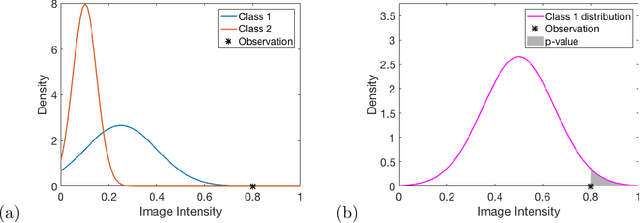
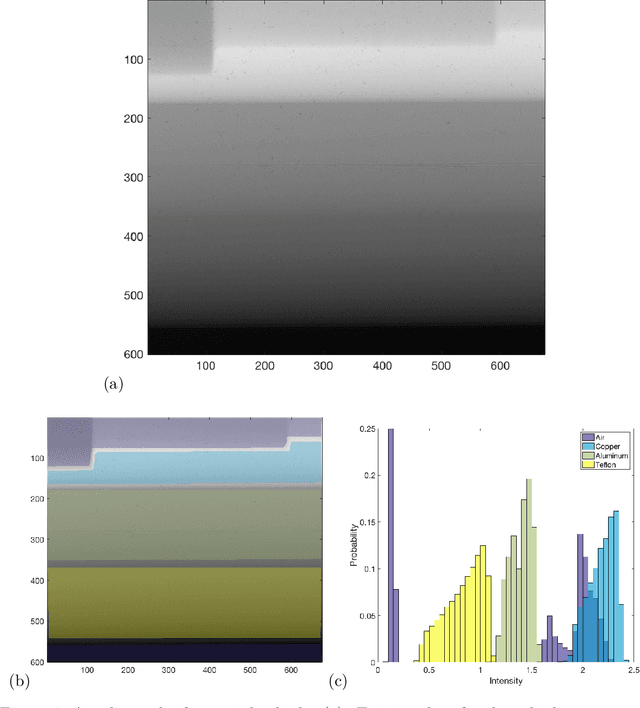
Rapid growth in the field of quantitative digital image analysis is paving the way for researchers to make precise measurements about objects in an image. To compute quantities from the image such as the density of compressed materials or the velocity of a shockwave, we must determine object boundaries. Images containing regions that each have a spatial trend in intensity are of particular interest. We present a supervised image segmentation method that incorporates spatial information to locate boundaries between regions with overlapping intensity histograms. The segmentation of a pixel is determined by comparing its intensity to distributions from local, nearby pixel intensities. Because of the statistical nature of the algorithm, we use maximum likelihood estimation theory to quantify uncertainty about each boundary. We demonstrate the success of this algorithm on a radiograph of a multicomponent cylinder and on an optical image of a laser-induced shockwave, and we provide final boundary locations with associated bands of uncertainty.
Consensus Based Medical Image Segmentation Using Semi-Supervised Learning And Graph Cuts
May 21, 2018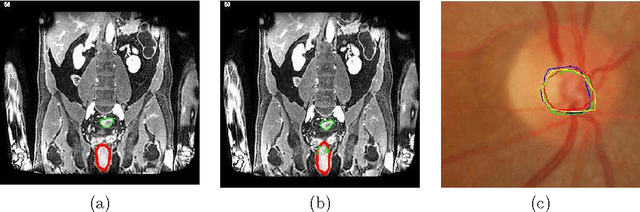
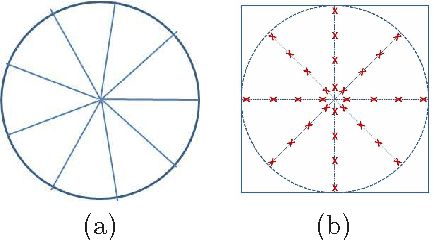

Medical image segmentation requires consensus ground truth segmentations to be derived from multiple expert annotations. A novel approach is proposed that obtains consensus segmentations from experts using graph cuts (GC) and semi supervised learning (SSL). Popular approaches use iterative Expectation Maximization (EM) to estimate the final annotation and quantify annotator's performance. Such techniques pose the risk of getting trapped in local minima. We propose a self consistency (SC) score to quantify annotator consistency using low level image features. SSL is used to predict missing annotations by considering global features and local image consistency. The SC score also serves as the penalty cost in a second order Markov random field (MRF) cost function optimized using graph cuts to derive the final consensus label. Graph cut obtains a global maximum without an iterative procedure. Experimental results on synthetic images, real data of Crohn's disease patients and retinal images show our final segmentation to be accurate and more consistent than competing methods.
Self-Supervised Flow Estimation using Geometric Regularization with Applications to Camera Image and Grid Map Sequences
Apr 17, 2019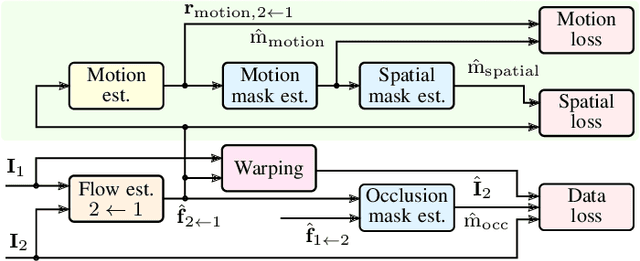

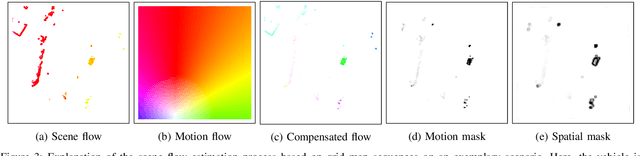
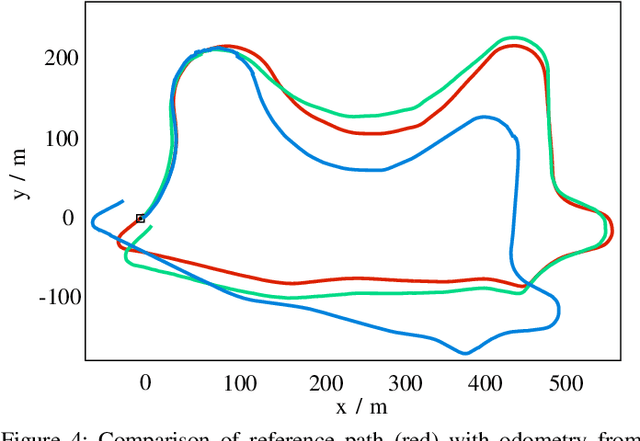
We present a self-supervised approach to estimate flow in camera image and top-view grid map sequences using fully convolutional neural networks in the domain of automated driving. We extend existing approaches for self-supervised optical flow estimation by adding a regularizer expressing motion consistency assuming a static environment. However, as this assumption is violated for other moving traffic participants we also estimate a mask to scale this regularization. Adding a regularization towards motion consistency improves convergence and flow estimation accuracy. Furthermore, we scale the errors due to spatial flow inconsistency by a mask that we derive from the motion mask. This improves accuracy in regions where the flow drastically changes due to a better separation between static and dynamic environment. We apply our approach to optical flow estimation from camera image sequences, validate on odometry estimation and suggest a method to iteratively increase optical flow estimation accuracy using the generated motion masks. Finally, we provide quantitative and qualitative results based on the KITTI odometry and tracking benchmark for scene flow estimation based on grid map sequences. We show that we can improve accuracy and convergence when applying motion and spatial consistency regularization.
Devil's in the Detail: Graph-based Key-point Alignment and Embedding for Person Re-ID
Sep 11, 2020

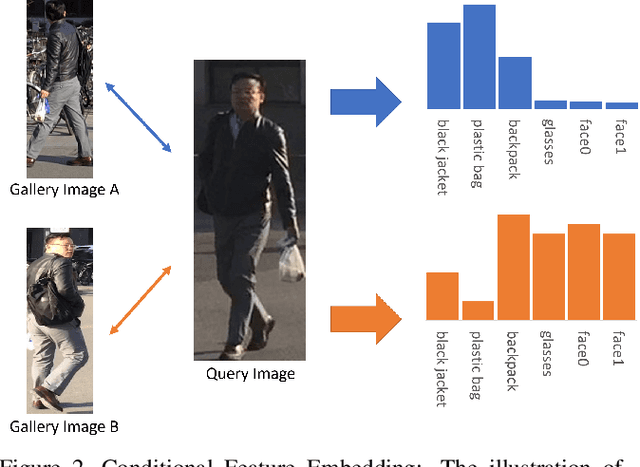
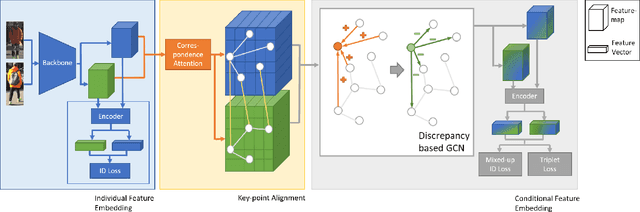
Although Person Re-Identification has made impressive progress, difficult cases like occlusion, change of view-point and similar clothing still bring great challenges. Besides overall visual features, matching and comparing detailed local information is also essential for tackling these challenges. This paper proposes two key recognition patterns to better utilize the local information of pedestrian images. From the spatial perspective, the model should be able to select and align key-points from the image pairs for comparison (i.e. key-points alignment). From the perspective of feature channels, the feature of a query image should be dynamically adjusted based on the gallery image it needs to match (i.e. conditional feature embedding). Most of the existing methods are unable to satisfy both key-point alignment and conditional feature embedding. By introducing novel techniques including correspondence attention module and discrepancy-based GCN, we propose an end-to-end ReID method that integrates both patterns into a unified framework, called Siamese-GCN. The experiments show that Siamese-GCN achieves state-of-the-art performance on three public datasets.
Minimizing false negative rate in melanoma detection and providing insight into the causes of classification
Feb 18, 2021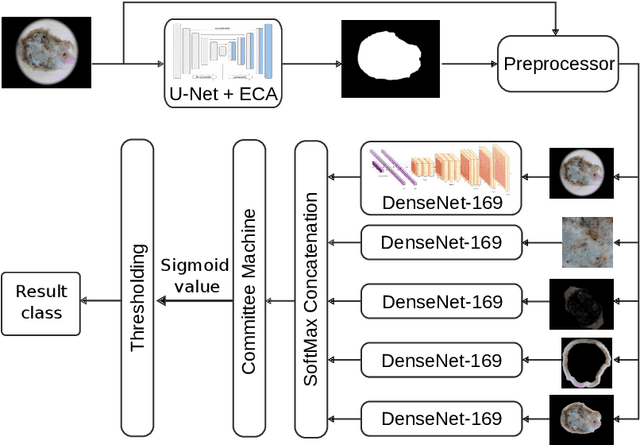
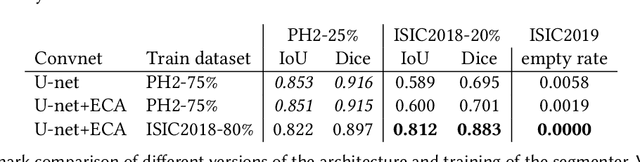
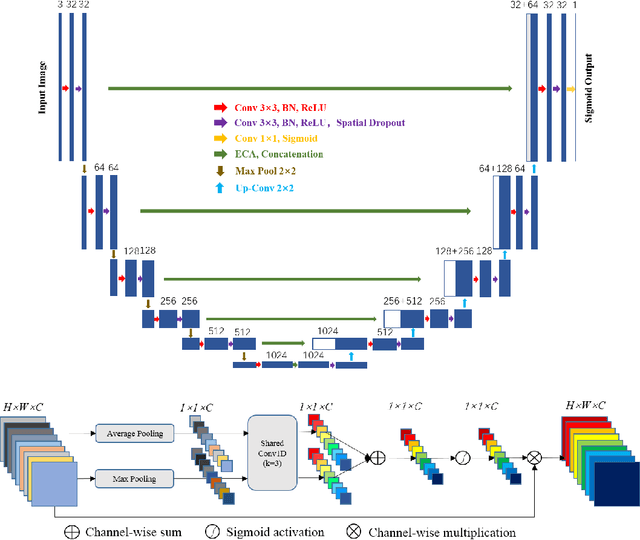
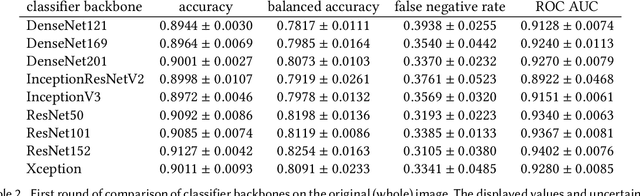
Our goal is to bridge human and machine intelligence in melanoma detection. We develop a classification system exploiting a combination of visual pre-processing, deep learning, and ensembling for providing explanations to experts and to minimize false negative rate while maintaining high accuracy in melanoma detection. Source images are first automatically segmented using a U-net CNN. The result of the segmentation is then used to extract image sub-areas and specific parameters relevant in human evaluation, namely center, border, and asymmetry measures. These data are then processed by tailored neural networks which include structure searching algorithms. Partial results are then ensembled by a committee machine. Our evaluation on the largest skin lesion dataset which is publicly available today, ISIC-2019, shows improvement in all evaluated metrics over a baseline using the original images only. We also showed that indicative scores computed by the feature classifiers can provide useful insight into the various features on which the decision can be based.
FusiformNet: Extracting Discriminative Facial Features on Different Levels
Nov 01, 2020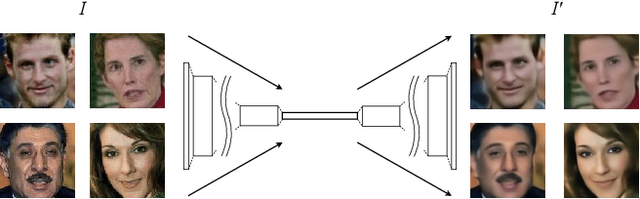
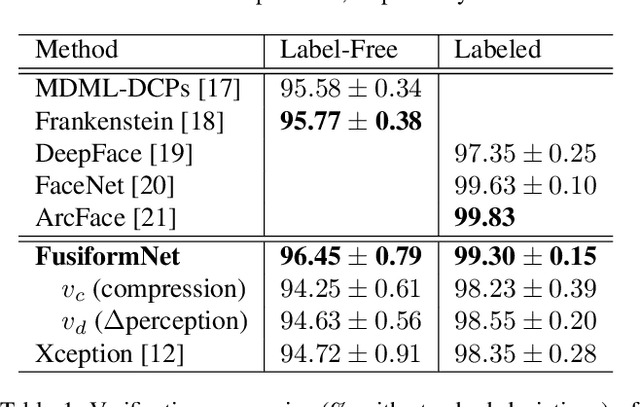
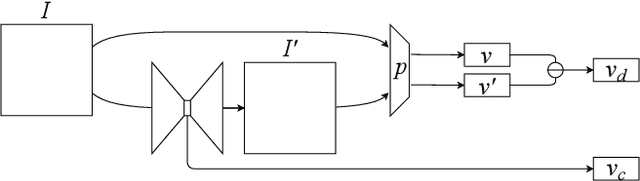
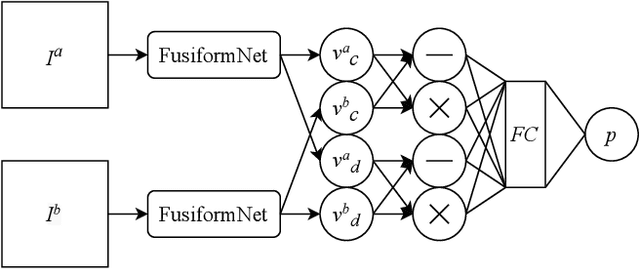
Over the last several years, research on facial recognition based on Deep Neural Network has evolved with approaches like task-specific loss functions, image normalization and augmentation, network architectures, etc. However, there have been few approaches with attention to how human faces differ from person to person. Premising that inter-personal differences are found both generally and locally on the human face, I propose FusiformNet, a novel framework for feature extraction that leverages the nature of person-identifying facial features. Tested on ImageUnrestricted setting of Labeled Face in the Wild benchmark, this method achieved a state-of-the-art accuracy of 96.67% without labeled outside data, image augmentation, normalization, or special loss functions. Likewise, the method also performed on par with previous state-of-the-arts when pretrained on CASIA-WebFace dataset. Considering its ability to extract both general and local facial features, the utility of FusiformNet may not be limited to facial recognition but also extend to other DNN-based tasks.
ManhattanSLAM: Robust Planar Tracking and Mapping Leveraging Mixture of Manhattan Frames
Mar 28, 2021
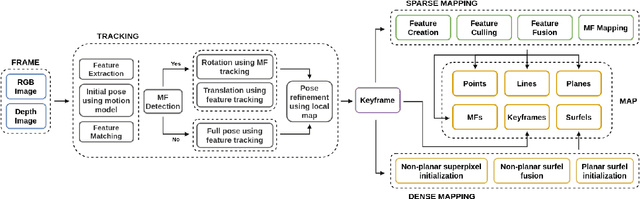
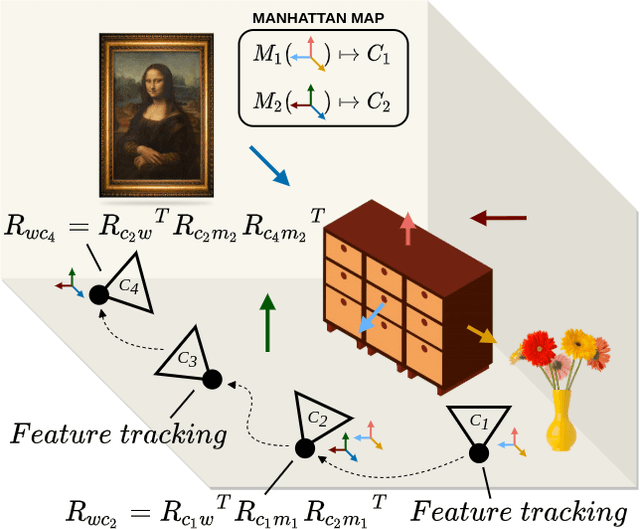
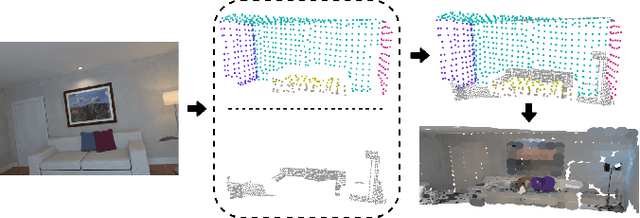
In this paper, a robust RGB-D SLAM system is proposed to utilize the structural information in indoor scenes, allowing for accurate tracking and efficient dense mapping on a CPU. Prior works have used the Manhattan World (MW) assumption to estimate low-drift camera pose, in turn limiting the applications of such systems. This paper, in contrast, proposes a novel approach delivering robust tracking in MW and non-MW environments. We check orthogonal relations between planes to directly detect Manhattan Frames, modeling the scene as a Mixture of Manhattan Frames. For MW scenes, we decouple pose estimation and provide a novel drift-free rotation estimation based on Manhattan Frame observations. For translation estimation in MW scenes and full camera pose estimation in non-MW scenes, we make use of point, line and plane features for robust tracking in challenging scenes. %mapping Additionally, by exploiting plane features detected in each frame, we also propose an efficient surfel-based dense mapping strategy, which divides each image into planar and non-planar regions. Planar surfels are initialized directly from sparse planes in our map while non-planar surfels are built by extracting superpixels. We evaluate our method on public benchmarks for pose estimation, drift and reconstruction accuracy, achieving superior performance compared to other state-of-the-art methods. We will open-source our code in the future.
Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
Mar 19, 2021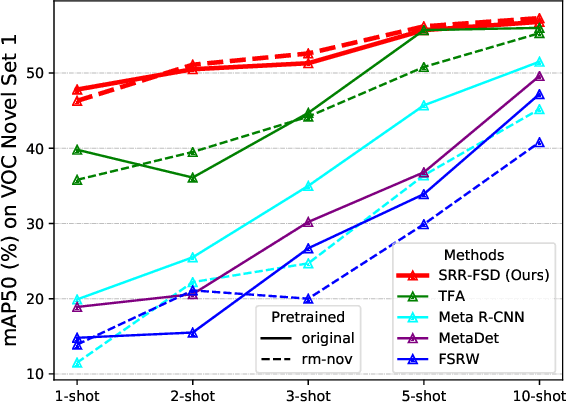
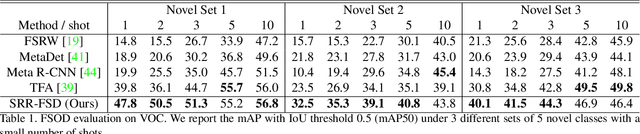
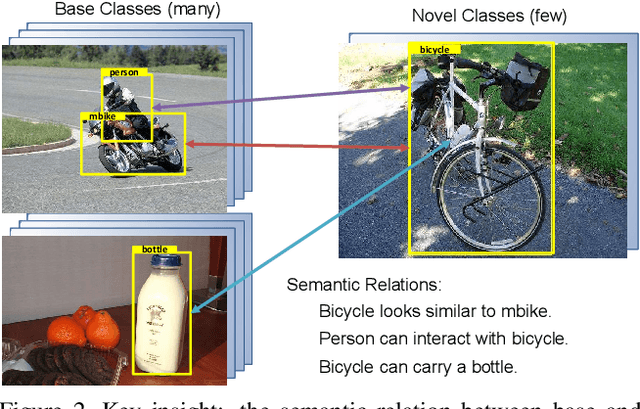
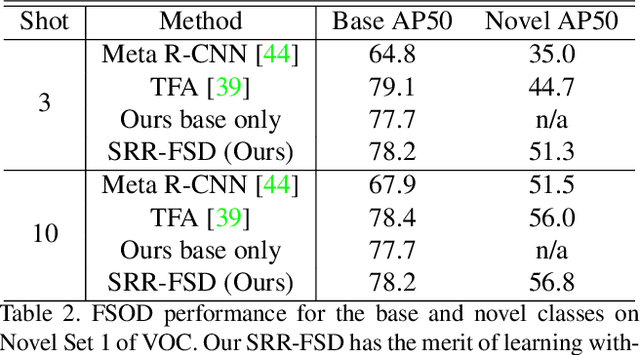
Few-shot object detection is an imperative and long-lasting problem due to the inherent long-tail distribution of real-world data. Its performance is largely affected by the data scarcity of novel classes. But the semantic relation between the novel classes and the base classes is constant regardless of the data availability. In this work, we investigate utilizing this semantic relation together with the visual information and introduce explicit relation reasoning into the learning of novel object detection. Specifically, we represent each class concept by a semantic embedding learned from a large corpus of text. The detector is trained to project the image representations of objects into this embedding space. We also identify the problems of trivially using the raw embeddings with a heuristic knowledge graph and propose to augment the embeddings with a dynamic relation graph. As a result, our few-shot detector, termed SRR-FSD, is robust and stable to the variation of shots of novel objects. Experiments show that SRR-FSD can achieve competitive results at higher shots, and more importantly, a significantly better performance given both lower explicit and implicit shots. The benchmark protocol with implicit shots removed from the pretrained classification dataset can serve as a more realistic setting for future research.