 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Atmospheric turbulence mitigation for sequences with moving objects using recursive image fusion
Aug 10, 2018
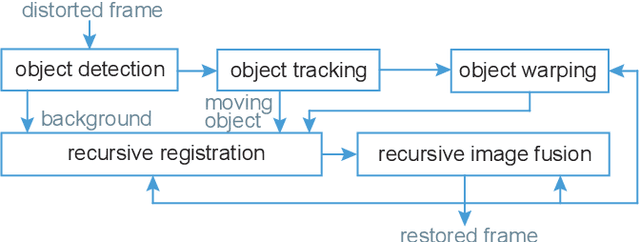
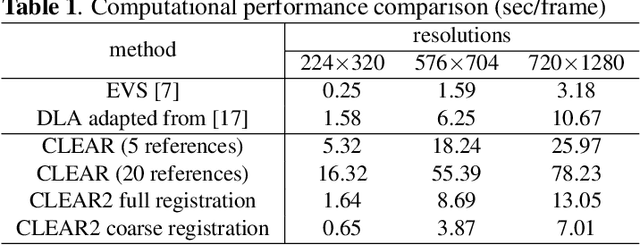


This paper describes a new method for mitigating the effects of atmospheric distortion on observed sequences that include large moving objects. In order to provide accurate detail from objects behind the distorting layer, we solve the space-variant distortion problem using recursive image fusion based on the Dual Tree Complex Wavelet Transform (DT-CWT). The moving objects are detected and tracked using the improved Gaussian mixture models (GMM) and Kalman filtering. New fusion rules are introduced which work on the magnitudes and angles of the DT-CWT coefficients independently to achieve a sharp image and to reduce atmospheric distortion, respectively. The subjective results show that the proposed method achieves better video quality than other existing methods with competitive speed.
Confidence Adaptive Anytime Pixel-Level Recognition
Apr 01, 2021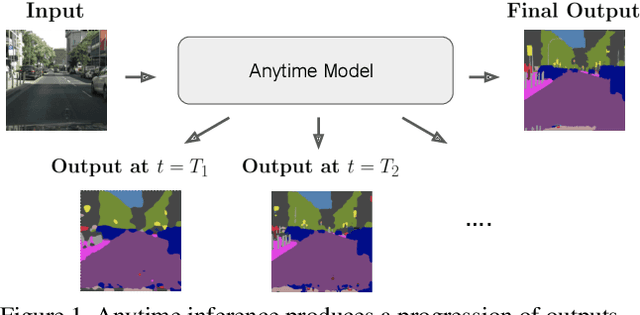
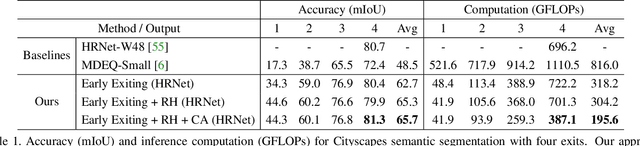
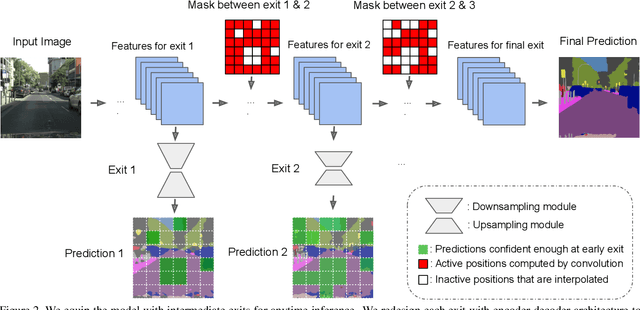
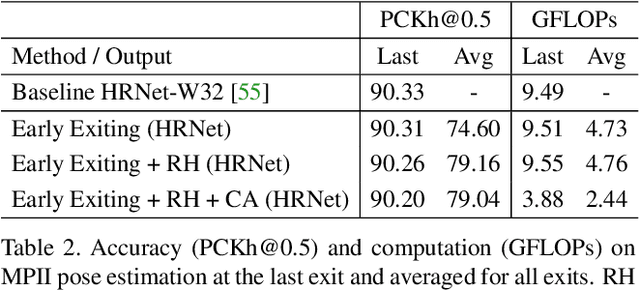
Anytime inference requires a model to make a progression of predictions which might be halted at any time. Prior research on anytime visual recognition has mostly focused on image classification. We propose the first unified and end-to-end model approach for anytime pixel-level recognition. A cascade of "exits" is attached to the model to make multiple predictions and direct further computation. We redesign the exits to account for the depth and spatial resolution of the features for each exit. To reduce total computation, and make full use of prior predictions, we develop a novel spatially adaptive approach to avoid further computation on regions where early predictions are already sufficiently confident. Our full model with redesigned exit architecture and spatial adaptivity enables anytime inference, achieves the same level of final accuracy, and even significantly reduces total computation. We evaluate our approach on semantic segmentation and human pose estimation. On Cityscapes semantic segmentation and MPII human pose estimation, our approach enables anytime inference while also reducing the total FLOPs of its base models by 44.4% and 59.1% without sacrificing accuracy. As a new anytime baseline, we measure the anytime capability of deep equilibrium networks, a recent class of model that is intrinsically iterative, and we show that the accuracy-computation curve of our architecture strictly dominates it.
Diverse Plausible Shape Completions from Ambiguous Depth Images
Nov 18, 2020
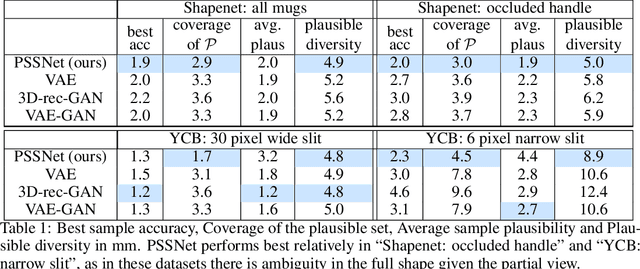
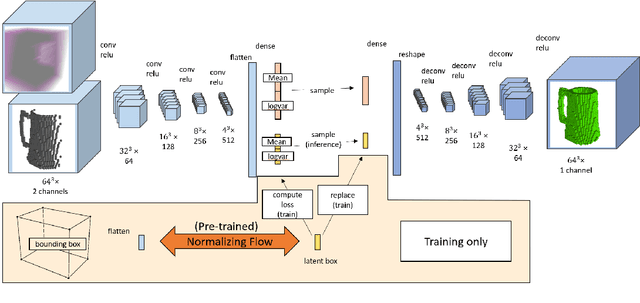
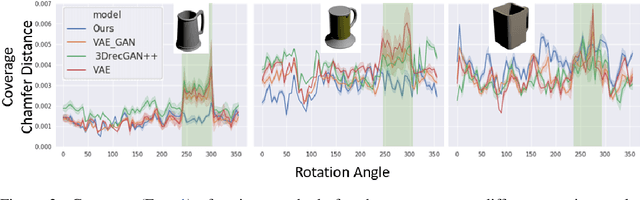
We propose PSSNet, a network architecture for generating diverse plausible 3D reconstructions from a single 2.5D depth image. Existing methods tend to produce only small variations on a single shape, even when multiple shapes are consistent with an observation. To obtain diversity we alter a Variational Auto Encoder by providing a learned shape bounding box feature as side information during training. Since these features are known during training, we are able to add a supervised loss to the encoder and noiseless values to the decoder. To evaluate, we sample a set of completions from a network, construct a set of plausible shape matches for each test observation, and compare using our plausible diversity metric defined over sets of shapes. We perform experiments using Shapenet mugs and partially-occluded YCB objects and find that our method performs comparably in datasets with little ambiguity, and outperforms existing methods when many shapes plausibly fit an observed depth image. We demonstrate one use for PSSNet on a physical robot when grasping objects in occlusion and clutter.
Simple is not Easy: A Simple Strong Baseline for TextVQA and TextCaps
Dec 09, 2020
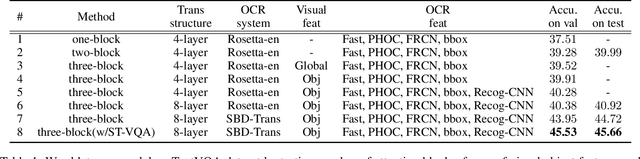
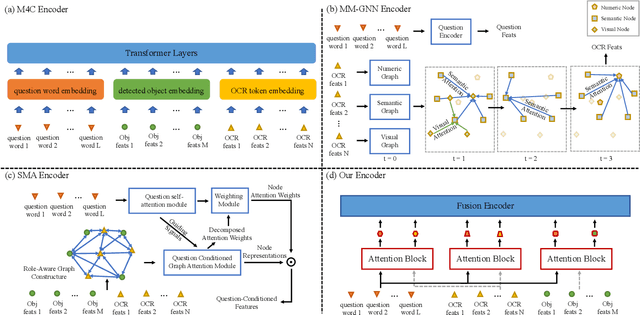

Texts appearing in daily scenes that can be recognized by OCR (Optical Character Recognition) tools contain significant information, such as street name, product brand and prices. Two tasks -- text-based visual question answering and text-based image captioning, with a text extension from existing vision-language applications, are catching on rapidly. To address these problems, many sophisticated multi-modality encoding frameworks (such as heterogeneous graph structure) are being used. In this paper, we argue that a simple attention mechanism can do the same or even better job without any bells and whistles. Under this mechanism, we simply split OCR token features into separate visual- and linguistic-attention branches, and send them to a popular Transformer decoder to generate answers or captions. Surprisingly, we find this simple baseline model is rather strong -- it consistently outperforms state-of-the-art (SOTA) models on two popular benchmarks, TextVQA and all three tasks of ST-VQA, although these SOTA models use far more complex encoding mechanisms. Transferring it to text-based image captioning, we also surpass the TextCaps Challenge 2020 winner. We wish this work to set the new baseline for this two OCR text related applications and to inspire new thinking of multi-modality encoder design. Code is available at https://github.com/ZephyrZhuQi/ssbaseline
Fast Interactive Video Object Segmentation with Graph Neural Networks
Mar 05, 2021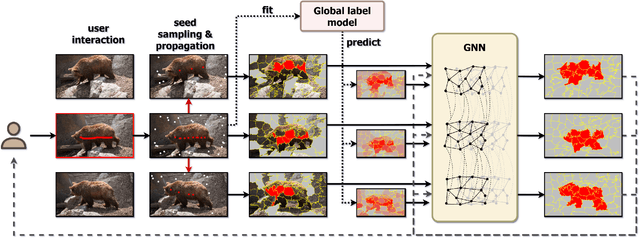


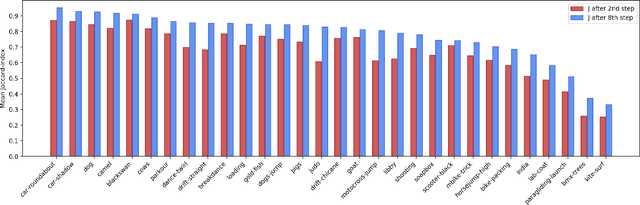
Pixelwise annotation of image sequences can be very tedious for humans. Interactive video object segmentation aims to utilize automatic methods to speed up the process and reduce the workload of the annotators. Most contemporary approaches rely on deep convolutional networks to collect and process information from human annotations throughout the video. However, such networks contain millions of parameters and need huge amounts of labeled training data to avoid overfitting. Beyond that, label propagation is usually executed as a series of frame-by-frame inference steps, which is difficult to be parallelized and is thus time consuming. In this paper we present a graph neural network based approach for tackling the problem of interactive video object segmentation. Our network operates on superpixel-graphs which allow us to reduce the dimensionality of the problem by several magnitudes. We show, that our network possessing only a few thousand parameters is able to achieve state-of-the-art performance, while inference remains fast and can be trained quickly with very little data.
Learning Low-dimensional Manifolds for Scoring of Tissue Microarray Images
Feb 22, 2021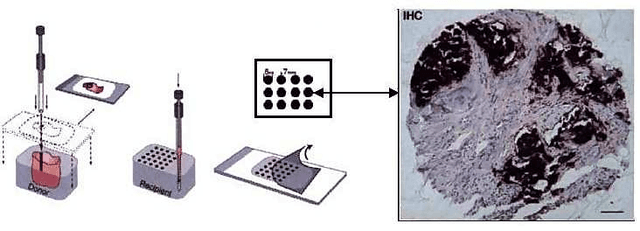
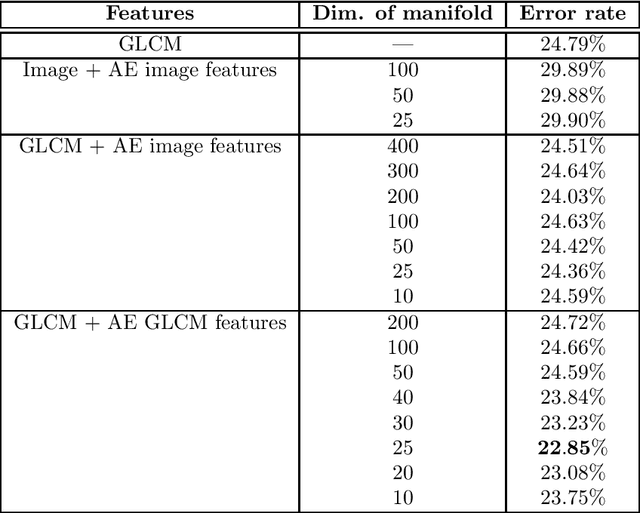
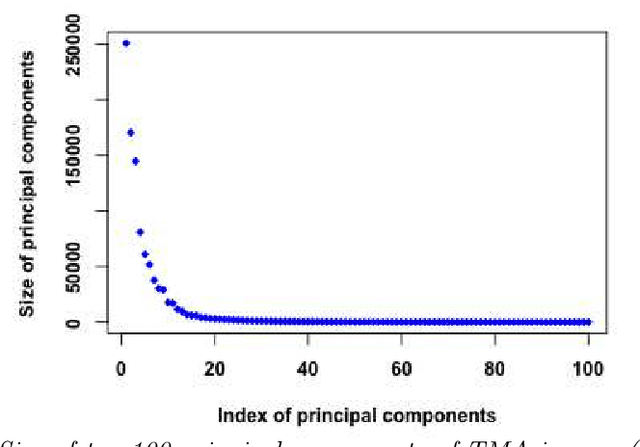
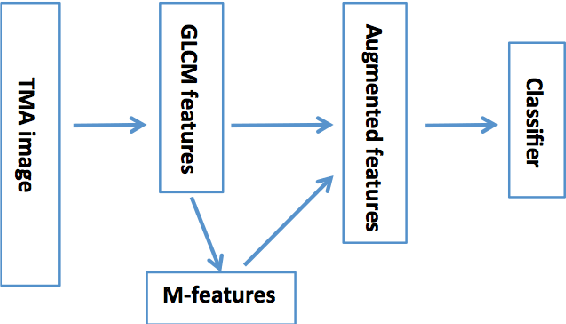
Tissue microarray (TMA) images have emerged as an important high-throughput tool for cancer study and the validation of biomarkers. Efforts have been dedicated to further improve the accuracy of TACOMA, a cutting-edge automatic scoring algorithm for TMA images. One major advance is due to deepTacoma, an algorithm that incorporates suitable deep representations of a group nature. Inspired by the recent advance in semi-supervised learning and deep learning, we propose mfTacoma to learn alternative deep representations in the context of TMA image scoring. In particular, mfTacoma learns the low-dimensional manifolds, a common latent structure in high dimensional data. Deep representation learning and manifold learning typically requires large data. By encoding deep representation of the manifolds as regularizing features, mfTacoma effectively leverages the manifold information that is potentially crude due to small data. Our experiments show that deep features by manifolds outperforms two alternatives -- deep features by linear manifolds with principal component analysis or by leveraging the group property.
Adaptive Structure-constrained Robust Latent Low-Rank Coding for Image Recovery
Aug 22, 2019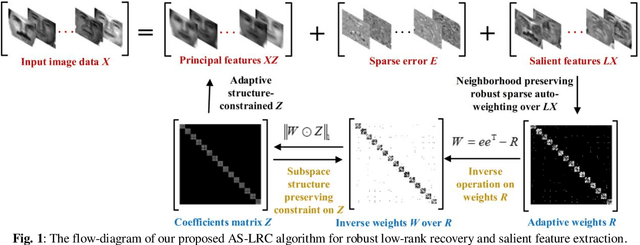

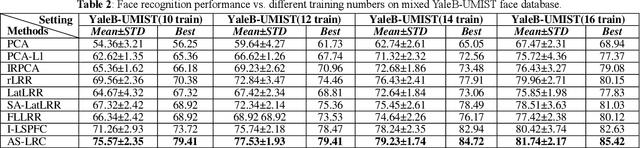
In this paper, we propose a robust representation learning model called Adaptive Structure-constrained Low-Rank Coding (AS-LRC) for the latent representation of data. To recover the underlying subspaces more accurately, AS-LRC seamlessly integrates an adaptive weighting based block-diagonal structure-constrained low-rank representation and the group sparse salient feature extraction into a unified framework. Specifically, AS-LRC performs the latent decomposition of given data into a low-rank reconstruction by a block-diagonal codes matrix, a group sparse locality-adaptive salient feature part and a sparse error part. To enforce the block-diagonal structures adaptive to different real datasets for the low-rank recovery, AS-LRC clearly computes an auto-weighting matrix based on the locality-adaptive features and multiplies by the low-rank coefficients for direct minimization at the same time. This encourages the codes to be block-diagonal and can avoid the tricky issue of choosing optimal neighborhood size or kernel width for the weight assignment, suffered in most local geometrical structures-preserving low-rank coding methods. In addition, our AS-LRC selects the L2,1-norm on the projection for extracting group sparse features rather than learning low-rank features by Nuclear-norm regularization, which can make learnt features robust to noise and outliers in samples, and can also make the feature coding process efficient. Extensive visualizations and numerical results demonstrate the effectiveness of our AS-LRC for image representation and recovery.
GRIHA: Synthesizing 2-Dimensional Building Layouts from Images Captured using a Smart Phone
Mar 15, 2021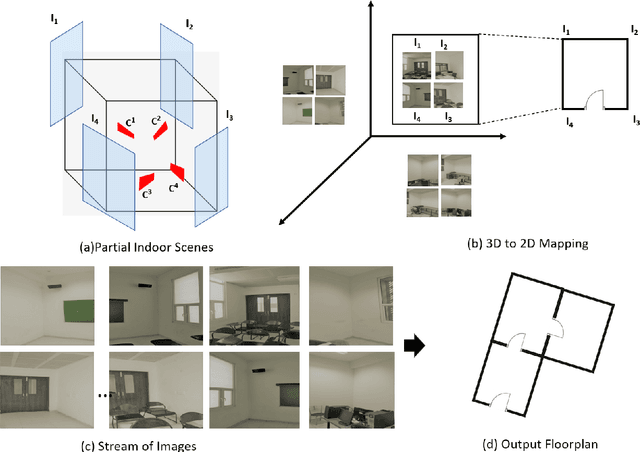



Reconstructing an indoor scene and generating a layout/floor plan in 3D or 2D is a widely known problem. Quite a few algorithms have been proposed in the literature recently. However, most existing methods either use RGB-D images, thus requiring a depth camera, or depending on panoramic photos, assuming that there is little to no occlusion in the rooms. In this work, we proposed GRIHA (Generating Room Interior of a House using ARCore), a framework for generating a layout using an RGB image captured using a simple mobile phone camera. We take advantage of Simultaneous Localization and Mapping (SLAM) to assess the 3D transformations required for layout generation. SLAM technology is built-in in recent mobile libraries such as ARCore by Google. Hence, the proposed method is fast and efficient. It gives the user freedom to generate layout by merely taking a few conventional photos, rather than relying on specialized depth hardware or occlusion-free panoramic images. We have compared GRIHA with other existing methods and obtained superior results. Also, the system is tested on multiple hardware platforms to test the dependency and efficiency.
Retinal Vasculature Segmentation Using Local Saliency Maps and Generative Adversarial Networks For Image Super Resolution
May 21, 2018



We propose an image super resolution(ISR) method using generative adversarial networks (GANs) that takes a low resolution input fundus image and generates a high resolution super resolved (SR) image upto scaling factor of $16$. This facilitates more accurate automated image analysis, especially for small or blurred landmarks and pathologies. Local saliency maps, which define each pixel's importance, are used to define a novel saliency loss in the GAN cost function. Experimental results show the resulting SR images have perceptual quality very close to the original images and perform better than competing methods that do not weigh pixels according to their importance. When used for retinal vasculature segmentation, our SR images result in accuracy levels close to those obtained when using the original images.
Multi-focus image fusion using VOL and EOL in DCT domain
Oct 24, 2017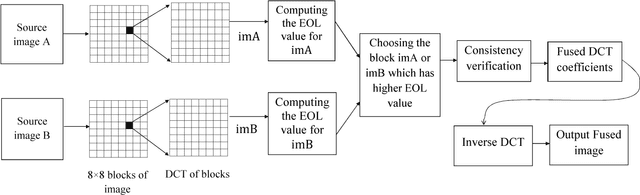


The purpose of multi-focus image fusion is gathering the essential information and the focused parts from the input multi-focus images into a single image. These multi-focused images are captured with different depths of focus of cameras. Multi-focus image fusion is very time-saving and appropriate in discrete cosine transform (DCT) domain, especially when JPEG images are used in visual sensor networks (VSN). The previous works in DCT domain have some errors in selection of the suitable divided blocks according to their criterion for measurement of the block contrast. In this paper, we used variance of Laplacian (VOL) and energy of Laplacian (EOL) as criterion to measure the contrast of image. Also in this paper, the EOL and VOL calculations directly in DCT domain are prepared using vector processing. We developed four matrices which calculate the Laplacian of block easily in DCT domain. Our works greatly reduce error due to unsuitable block selection. The results of the proposed algorithms are compared with the previous algorithms in order to demonstrate the superiority of the output image quality in the proposed methods. The several JPEG multi-focus images are used in experiments and their fused image by our proposed methods and the other algorithms are compared with different measurement criteria.