 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Visual Hallucinations in Multimodal Systems through Retrieval-Augmented Reliability-Aware Inference
Jun 14, 2026Multimodal large language models (MLLMs) have demonstrated strong capabilities in vision-language understanding and natural-language response generation. However, these systems can still produce overconfident predictions and hallucination-like outputs, particularly when the visual evidence is weak, ambiguous, or semantically inconsistent. Most existing approaches focus on improving multimodal representation alignment or retrieval-augmented generation, while providing limited mechanisms to quantify instance-level prediction reliability or identify incorrect visual outputs. This work proposes a retrieval-augmented reliability-aware inference framework for trustworthy multimodal visual understanding. The proposed framework constructs an external visual evidence database using pretrained visual embeddings and nearest-neighbor retrieval over normalized feature representations. Retrieved evidence is used to estimate prediction trustworthiness through multiple reliability indicators, including similarity strength, class-support agreement, evidence margin, entropy-based uncertainty, and an aggregate reliability score. Based on these signals, a decision gate determines whether the system should accept the prediction, answer with caution, or abstain/fallback when evidence is insufficient. A multimodal response-generation layer then produces a final user-facing response conditioned on the reliability decision. Experiments on ImageNet-100 demonstrate that the proposed reliability-aware framework improves accepted prediction accuracy from 85.84\% to 88.88\% at 89.04\% coverage. The hallucination-like accepted wrong-answer rate is reduced from 14.16\% to 11.12\%. These results show that integrating retrieval evidence, reliability estimation, and selective decision gating can improve calibration and reduce overconfident visual errors without retraining large multimodal models.
Correcting Variable Importance Scored by Random Forests
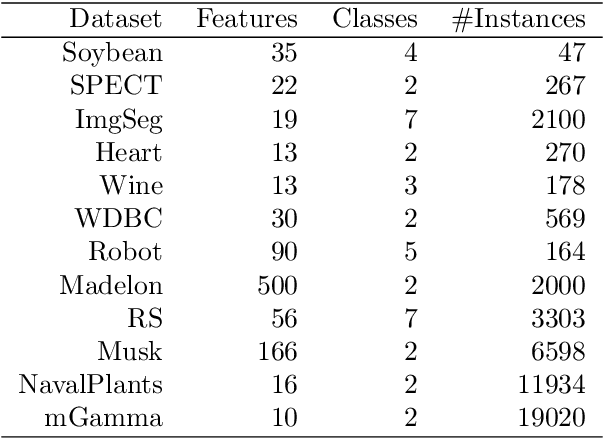
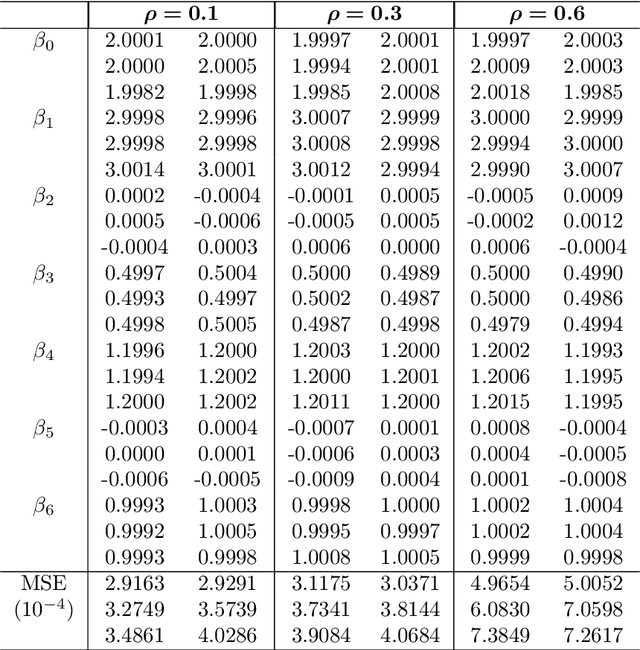
Jun 09, 2026Variable importance produced by Random Forests (RF) is used widely in statistical data analysis, and has played an important role in a variety of tasks such as assisting model interpretation, model selection and diagnosis, and cost-bounded learning etc. However, the calculation of variable importance in RF does not take into account of the correlations among variables, and variables that are correlated to many other variables tend to receive a lower importance index or being completely masked (i.e., with an importance index near zero) by other strongly correlated variables. To prevent influence from unwanted correlated variables in calculating variable importance, we propose to group variables by their conditional correlations (conditional on the response variable). We explore two computationally efficient options, with one grouping variables individually, and then separates the variable of interest from all correlated variables, while the other uses clustering to group variables according to their pair-wise conditional correlations. Our experiments show that both lead to sensible corrections to the importance of variables.
A Computational Approach to Improving Fairness in K-means Clustering
May 29, 2025The popular K-means clustering algorithm potentially suffers from a major weakness for further analysis or interpretation. Some cluster may have disproportionately more (or fewer) points from one of the subpopulations in terms of some sensitive variable, e.g., gender or race. Such a fairness issue may cause bias and unexpected social consequences. This work attempts to improve the fairness of K-means clustering with a two-stage optimization formulation--clustering first and then adjust cluster membership of a small subset of selected data points. Two computationally efficient algorithms are proposed in identifying those data points that are expensive for fairness, with one focusing on nearest data points outside of a cluster and the other on highly 'mixed' data points. Experiments on benchmark datasets show substantial improvement on fairness with a minimal impact to clustering quality. The proposed algorithms can be easily extended to a broad class of clustering algorithms or fairness metrics.
A Deep Neural Network Based Approach to Building Budget-Constrained Models for Big Data Analysis
Feb 23, 2023



Deep learning approaches require collection of data on many different input features or variables for accurate model training and prediction. Since data collection on input features could be costly, it is crucial to reduce the cost by selecting a subset of features and developing a budget-constrained model (BCM). In this paper, we introduce an approach to eliminating less important features for big data analysis using Deep Neural Networks (DNNs). Once a DNN model has been developed, we identify the weak links and weak neurons, and remove some input features to bring the model cost within a given budget. The experimental results show our approach is feasible and supports user selection of a suitable BCM within a given budget.
Improving Short Text Classification With Augmented Data Using GPT-3
May 23, 2022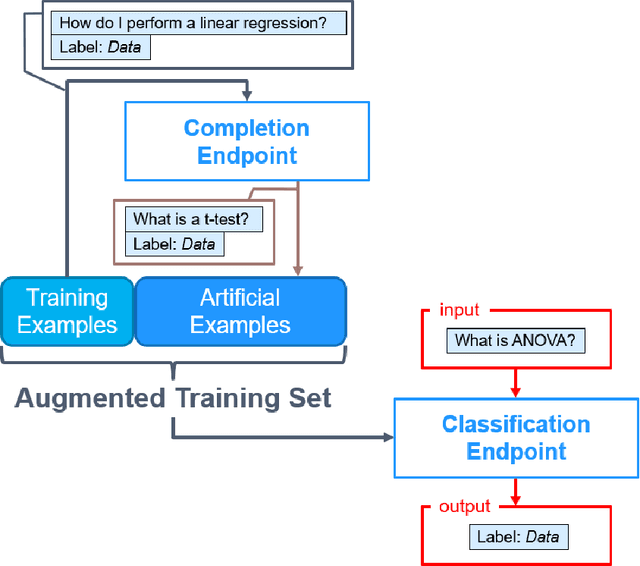
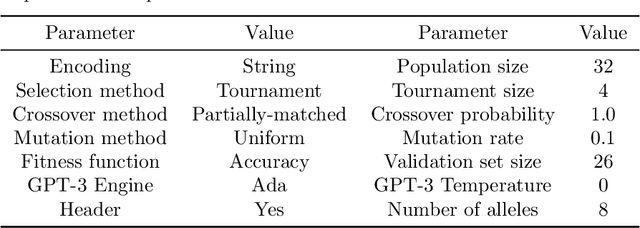

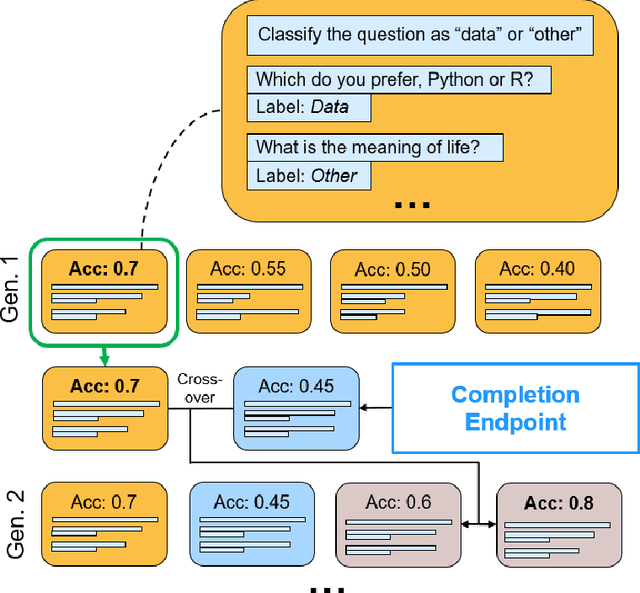
GPT-3 is a large-scale natural language model developed by OpenAI that can perform many different tasks, including topic classification. Although researchers claim that it requires only a small number of in-context examples to learn a task, in practice GPT-3 requires these training examples to be either of exceptional quality or a higher quantity than easily created by hand. To address this issue, this study teaches GPT-3 to classify whether a question is related to data science by augmenting a small training set with additional examples generated by GPT-3 itself. This study compares two classifiers: the GPT-3 Classification Endpoint with augmented examples, and the GPT-3 Completion Endpoint with an optimal training set chosen using a genetic algorithm. We find that while the augmented Completion Endpoint achieves upwards of 80 percent validation accuracy, using the augmented Classification Endpoint yields more consistent accuracy on unseen examples. In this way, giving large-scale machine learning models like GPT-3 the ability to propose their own additional training examples can result in improved classification performance.
Learning Low-dimensional Manifolds for Scoring of Tissue Microarray Images
Feb 22, 2021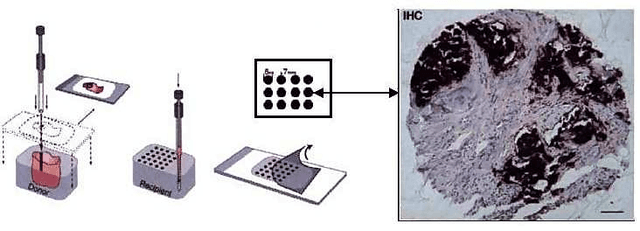
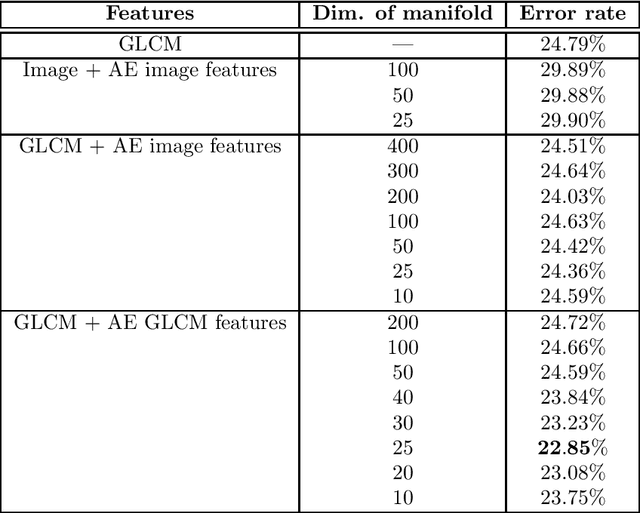
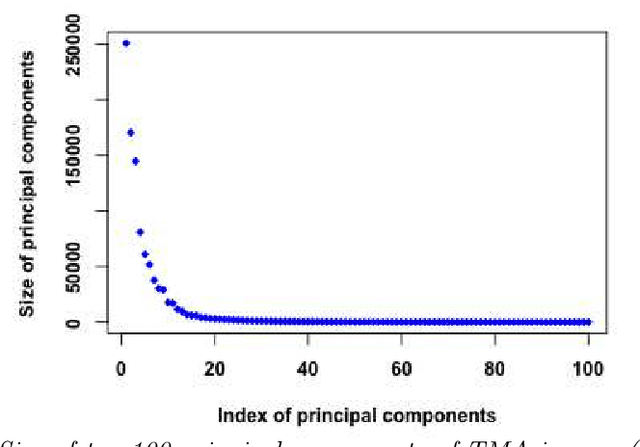
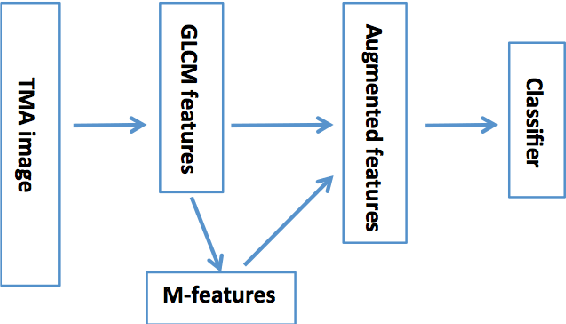
Tissue microarray (TMA) images have emerged as an important high-throughput tool for cancer study and the validation of biomarkers. Efforts have been dedicated to further improve the accuracy of TACOMA, a cutting-edge automatic scoring algorithm for TMA images. One major advance is due to deepTacoma, an algorithm that incorporates suitable deep representations of a group nature. Inspired by the recent advance in semi-supervised learning and deep learning, we propose mfTacoma to learn alternative deep representations in the context of TMA image scoring. In particular, mfTacoma learns the low-dimensional manifolds, a common latent structure in high dimensional data. Deep representation learning and manifold learning typically requires large data. By encoding deep representation of the manifolds as regularizing features, mfTacoma effectively leverages the manifold information that is potentially crude due to small data. Our experiments show that deep features by manifolds outperforms two alternatives -- deep features by linear manifolds with principal component analysis or by leveraging the group property.
$DC^2$: A Divide-and-conquer Algorithm for Large-scale Kernel Learning with Application to Clustering
Nov 16, 2019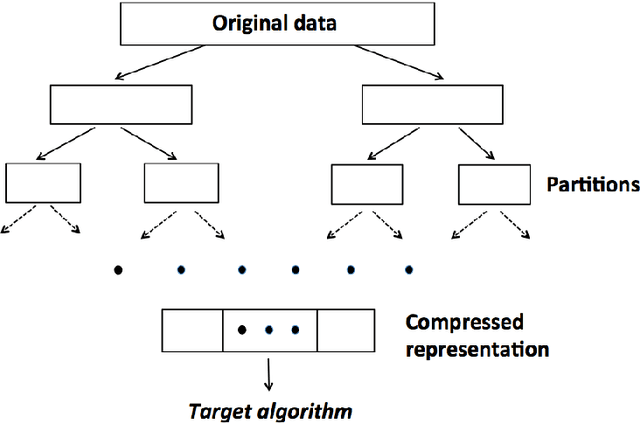
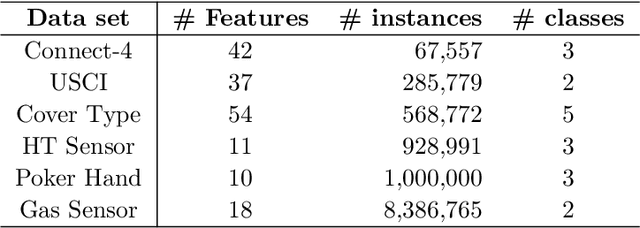
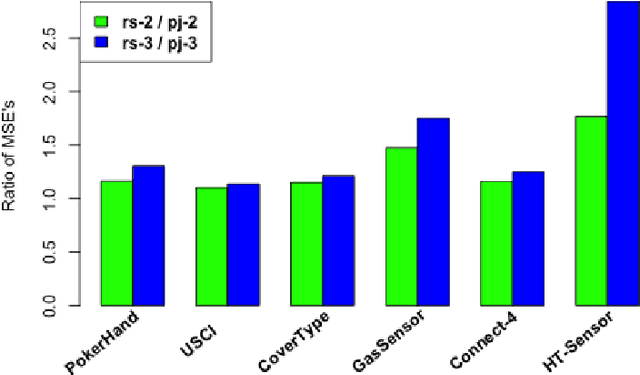
Divide-and-conquer is a general strategy to deal with large scale problems. It is typically applied to generate ensemble instances, which potentially limits the problem size it can handle. Additionally, the data are often divided by random sampling which may be suboptimal. To address these concerns, we propose the $DC^2$ algorithm. Instead of ensemble instances, we produce structure-preserving signature pieces to be assembled and conquered. $DC^2$ achieves the efficiency of sampling-based large scale kernel methods while enabling parallel multicore or clustered computation. The data partition and subsequent compression are unified by recursive random projections. Empirically dividing the data by random projections induces smaller mean squared approximation errors than conventional random sampling. The power of $DC^2$ is demonstrated by our clustering algorithm $rpfCluster^+$, which is as accurate as some fastest approximate spectral clustering algorithms while maintaining a running time close to that of K-means clustering. Analysis on $DC^2$ when applied to spectral clustering shows that the loss in clustering accuracy due to data division and reduction is upper bounded by the data approximation error which would vanish with recursive random projections. Due to its easy implementation and flexibility, we expect $DC^2$ to be applicable to general large scale learning problems.
Similarity Kernel and Clustering via Random Projection Forests
Aug 28, 2019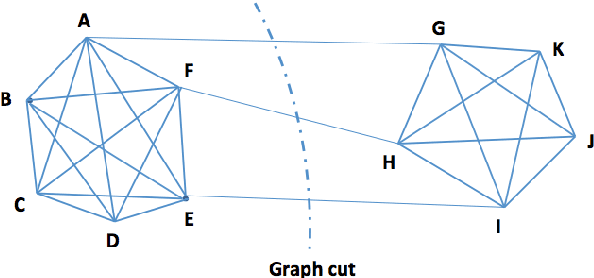
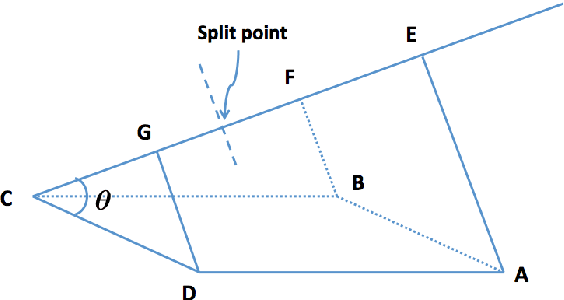
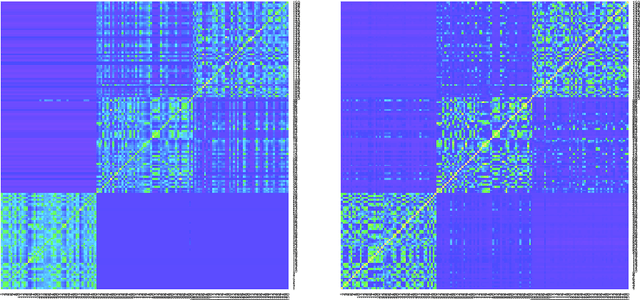
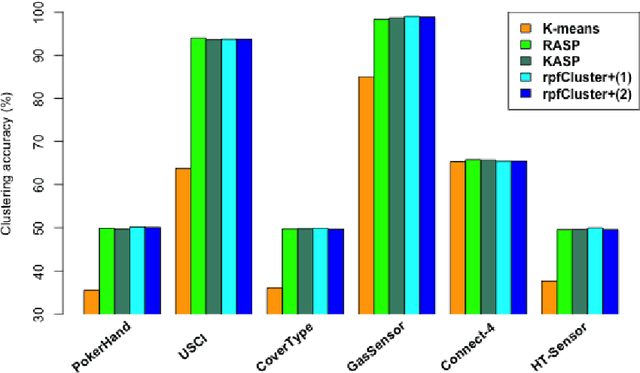
Similarity plays a fundamental role in many areas, including data mining, machine learning, statistics and various applied domains. Inspired by the success of ensemble methods and the flexibility of trees, we propose to learn a similarity kernel called rpf-kernel through random projection forests (rpForests). Our theoretical analysis reveals a highly desirable property of rpf-kernel: far-away (dissimilar) points have a low similarity value while nearby (similar) points would have a high similarity}, and the similarities have a native interpretation as the probability of points remaining in the same leaf nodes during the growth of rpForests. The learned rpf-kernel leads to an effective clustering algorithm--rpfCluster. On a wide variety of real and benchmark datasets, rpfCluster compares favorably to K-means clustering, spectral clustering and a state-of-the-art clustering ensemble algorithm--Cluster Forests. Our approach is simple to implement and readily adapt to the geometry of the underlying data. Given its desirable theoretical property and competitive empirical performance when applied to clustering, we expect rpf-kernel to be applicable to many problems of an unsupervised nature or as a regularizer in some supervised or weakly supervised settings.
Learning over inherently distributed data
Jul 30, 2019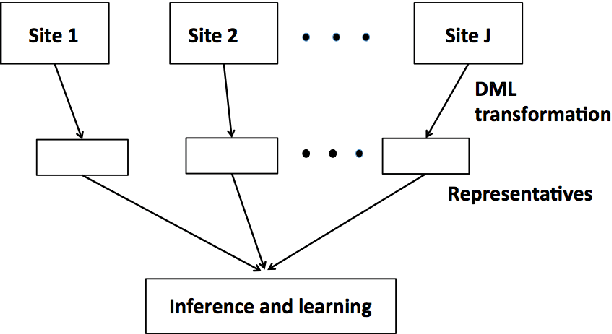
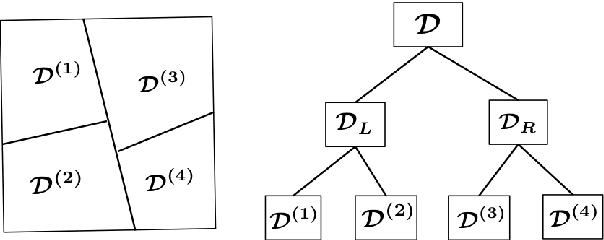

The recent decades have seen a surge of interests in distributed computing. Existing work focus primarily on either distributed computing platforms, data query tools, or, algorithms to divide big data and conquer at individual machines etc. It is, however, increasingly often that the data of interest are inherently distributed, i.e., data are stored at multiple distributed sites due to diverse collection channels, business operations etc. We propose to enable learning and inference in such a setting via a general framework based on the distortion minimizing local transformations. This framework only requires a small amount of local signatures to be shared among distributed sites, eliminating the need of having to transmitting big data. Computation can be done very efficiently via parallel local computation. The error incurred due to distributed computing vanishes when increasing the size of local signatures. As the shared data need not be in their original form, data privacy may also be preserved. Experiments on linear (logistic) regression and Random Forests have shown promise of this approach. This framework is expected to apply to a general class of tools in learning and inference with the continuity property.
Fast communication-efficient spectral clustering over distributed data
May 05, 2019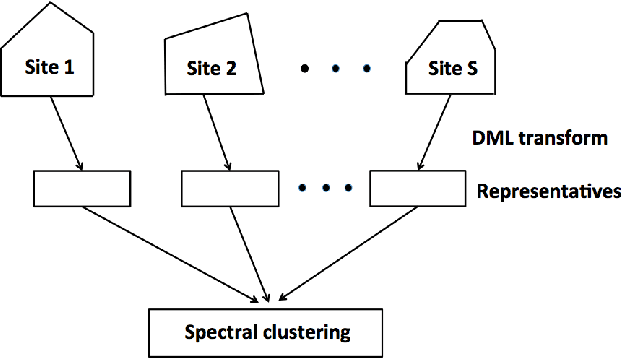
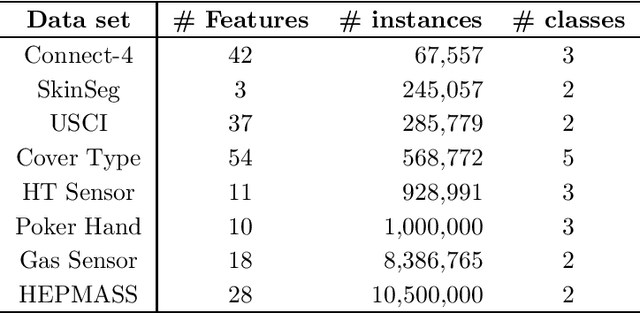
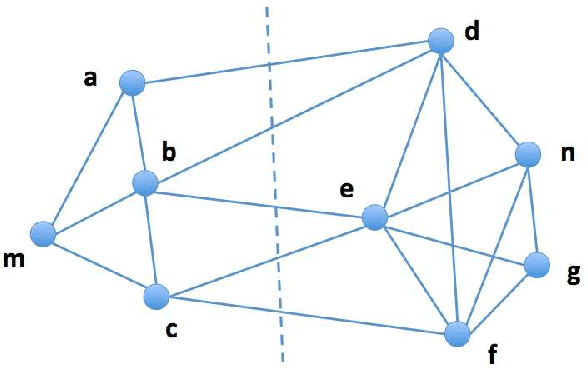
The last decades have seen a surge of interests in distributed computing thanks to advances in clustered computing and big data technology. Existing distributed algorithms typically assume {\it all the data are already in one place}, and divide the data and conquer on multiple machines. However, it is increasingly often that the data are located at a number of distributed sites, and one wishes to compute over all the data with low communication overhead. For spectral clustering, we propose a novel framework that enables its computation over such distributed data, with "minimal" communications while a major speedup in computation. The loss in accuracy is negligible compared to the non-distributed setting. Our approach allows local parallel computing at where the data are located, thus turns the distributed nature of the data into a blessing; the speedup is most substantial when the data are evenly distributed across sites. Experiments on synthetic and large UC Irvine datasets show almost no loss in accuracy with our approach while about 2x speedup under various settings with two distributed sites. As the transmitted data need not be in their original form, our framework readily addresses the privacy concern for data sharing in distributed computing.
* 27 pages, 7 figures