 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning from Ambiguous Labels for Lung Nodule Malignancy Prediction
Apr 23, 2021
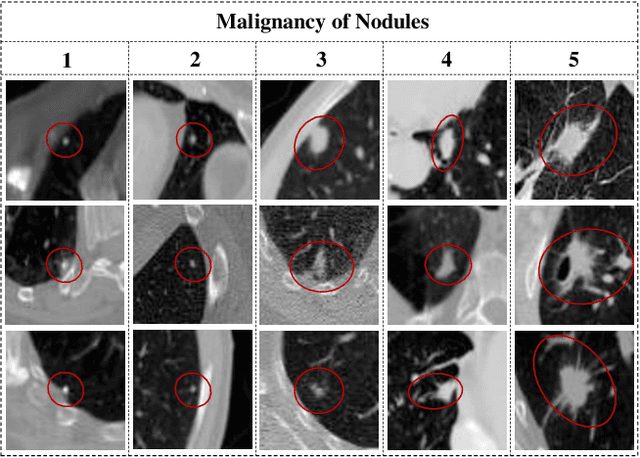
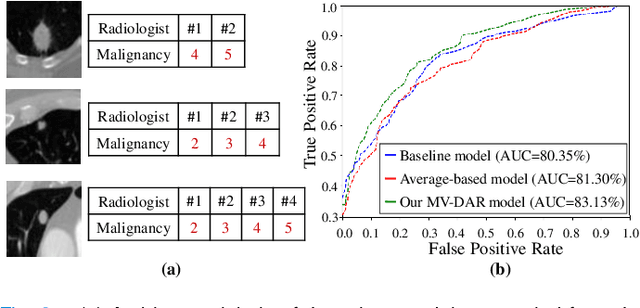
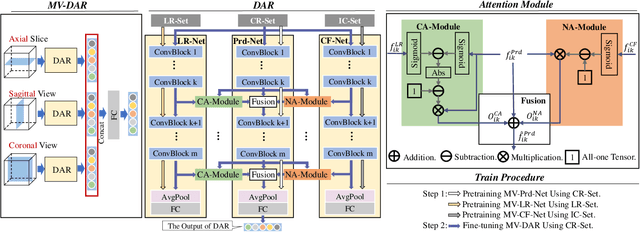
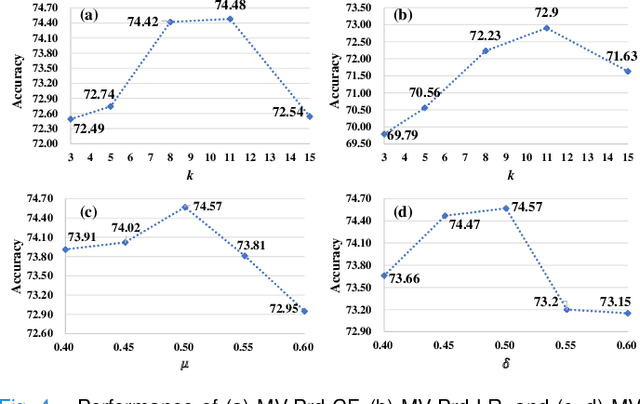
Lung nodule malignancy prediction is an essential step in the early diagnosis of lung cancer. Besides the difficulties commonly discussed, the challenges of this task also come from the ambiguous labels provided by annotators, since deep learning models may learn, even amplify, the bias embedded in them. In this paper, we propose a multi-view "divide-and-rule" (MV-DAR) model to learn from both reliable and ambiguous annotations for lung nodule malignancy prediction. According to the consistency and reliability of their annotations, we divide nodules into three sets: a consistent and reliable set (CR-Set), an inconsistent set (IC-Set), and a low reliable set (LR-Set). The nodule in IC-Set is annotated by multiple radiologists inconsistently, and the nodule in LR-Set is annotated by only one radiologist. The proposed MV-DAR contains three DAR submodels to characterize a lung nodule from three orthographic views. Each DAR consists of a prediction network (Prd-Net), a counterfactual network (CF-Net), and a low reliable network (LR-Net), learning on CR-Set, IC-Set, and LR-Set, respectively. The image representation ability learned by CF-Net and LR-Net is then transferred to Prd-Net by negative-attention module (NA-Module) and consistent-attention module (CA-Module), aiming to boost the prediction ability of Prd-Net. The MV-DAR model has been evaluated on the LIDC-IDRI dataset and LUNGx dataset. Our results indicate not only the effectiveness of the proposed MV-DAR model in learning from ambiguous labels but also its superiority over present noisy label-learning models in lung nodule malignancy prediction.
Group Equivariant Conditional Neural Processes
Feb 17, 2021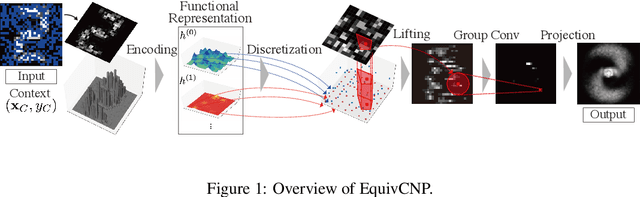
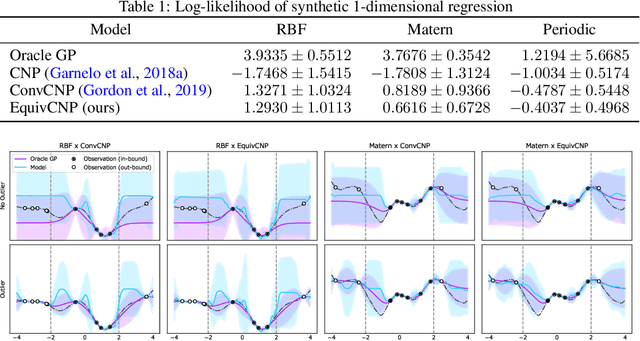

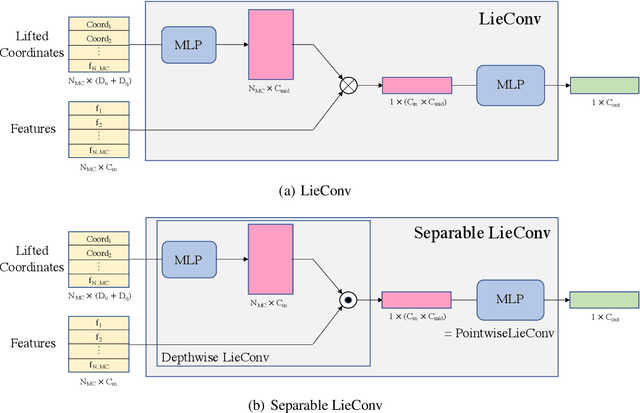
We present the group equivariant conditional neural process (EquivCNP), a meta-learning method with permutation invariance in a data set as in conventional conditional neural processes (CNPs), and it also has transformation equivariance in data space. Incorporating group equivariance, such as rotation and scaling equivariance, provides a way to consider the symmetry of real-world data. We give a decomposition theorem for permutation-invariant and group-equivariant maps, which leads us to construct EquivCNPs with an infinite-dimensional latent space to handle group symmetries. In this paper, we build architecture using Lie group convolutional layers for practical implementation. We show that EquivCNP with translation equivariance achieves comparable performance to conventional CNPs in a 1D regression task. Moreover, we demonstrate that incorporating an appropriate Lie group equivariance, EquivCNP is capable of zero-shot generalization for an image-completion task by selecting an appropriate Lie group equivariance.
Online Alternate Generator against Adversarial Attacks
Sep 17, 2020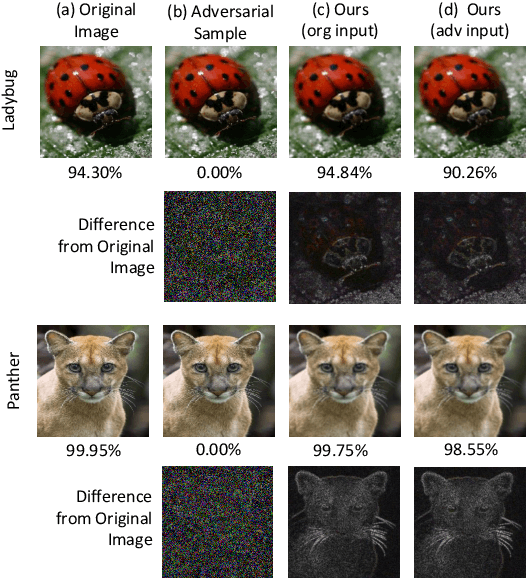

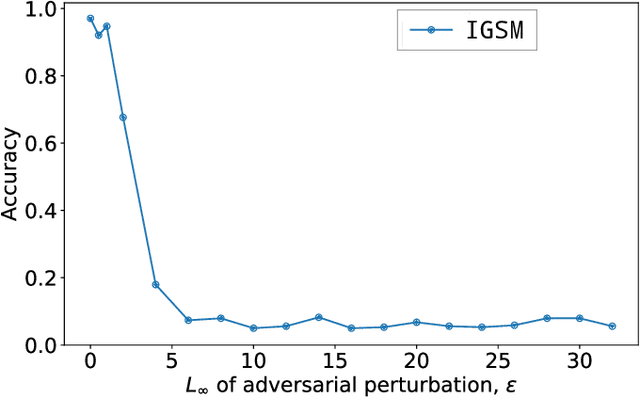
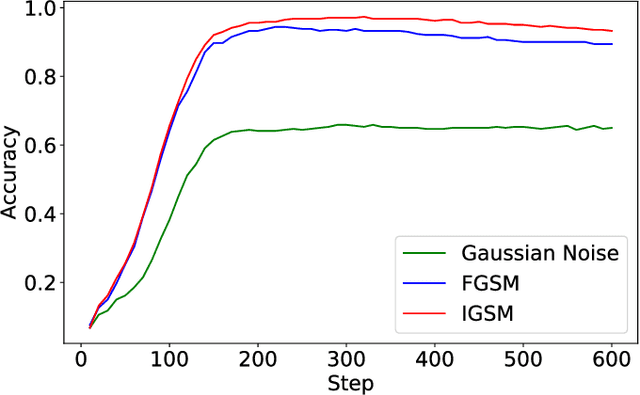
The field of computer vision has witnessed phenomenal progress in recent years partially due to the development of deep convolutional neural networks. However, deep learning models are notoriously sensitive to adversarial examples which are synthesized by adding quasi-perceptible noises on real images. Some existing defense methods require to re-train attacked target networks and augment the train set via known adversarial attacks, which is inefficient and might be unpromising with unknown attack types. To overcome the above issues, we propose a portable defense method, online alternate generator, which does not need to access or modify the parameters of the target networks. The proposed method works by online synthesizing another image from scratch for an input image, instead of removing or destroying adversarial noises. To avoid pretrained parameters exploited by attackers, we alternately update the generator and the synthesized image at the inference stage. Experimental results demonstrate that the proposed defensive scheme and method outperforms a series of state-of-the-art defending models against gray-box adversarial attacks.
Automatic Ship Classification Utilizing Bag of Deep Features
Feb 23, 2021
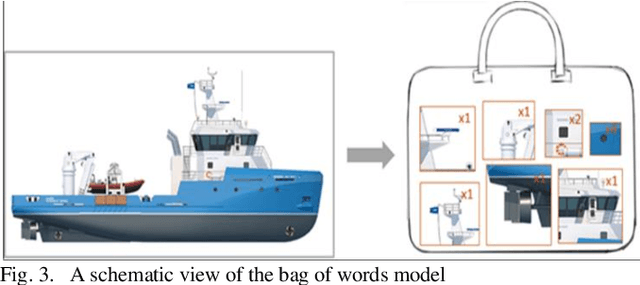
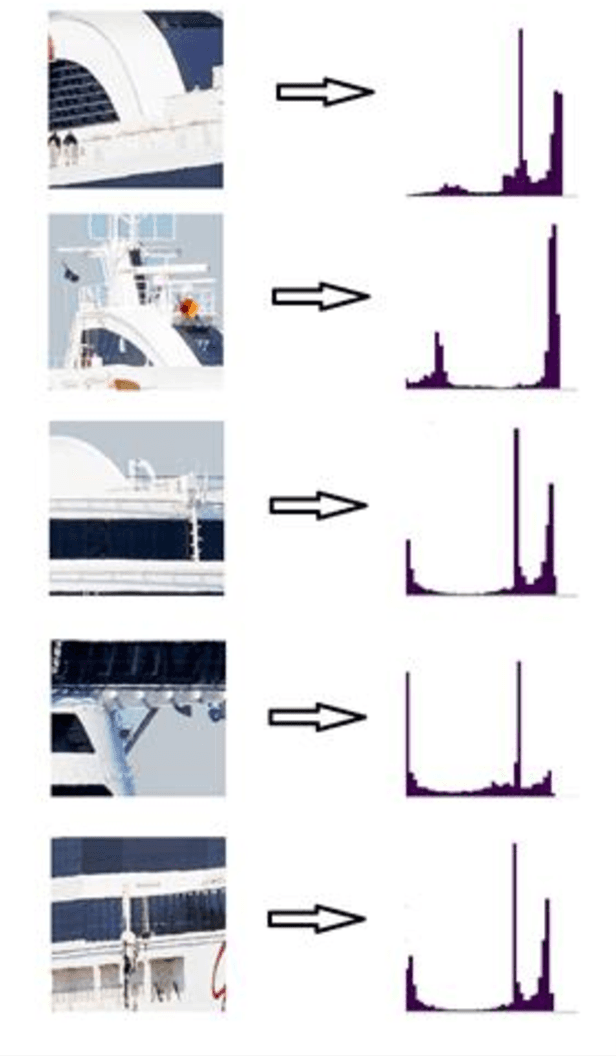
Detection and classification of ships based on their silhouette profiles in natural imagery is an important undertaking in computer science. This problem can be viewed from a variety of perspectives, including security, traffic control, and even militarism. Therefore, in each of the aforementioned applications, specific processing is required. In this paper, by applying the "bag of words" (BoW), a new method is presented that its words are the features that are obtained using pre-trained models of deep convolutional networks. , Three VGG models are utilized which provide superior accuracy in identifying objects. The regions of the image that are selected as the initial proposals are derived from a greedy algorithm on the key points generated by the Scale Invariant Feature Transform (SIFT) method. Using the deep features in the BOW method provides a good improvement in the recognition and classification of ships. Eventually, we obtained an accuracy of 91.8% in the classification of the ships which shows the improvement of about 5% compared to previous methods.
Vision Transformers for Dense Prediction
Mar 24, 2021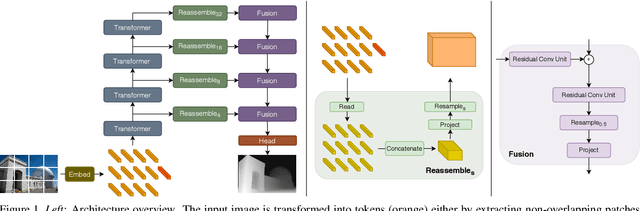
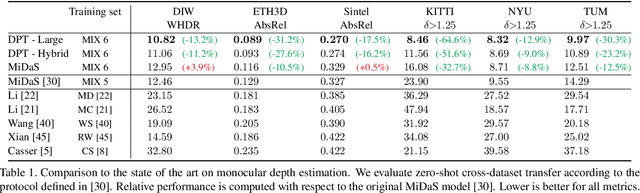
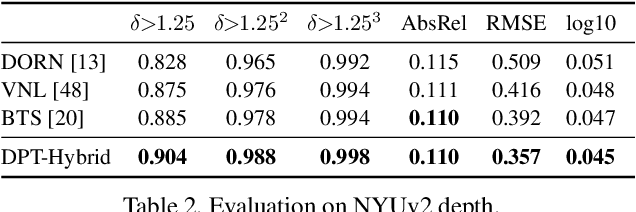

We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art. Our models are available at https://github.com/intel-isl/DPT.
FakeMix Augmentation Improves Transparent Object Detection
Mar 24, 2021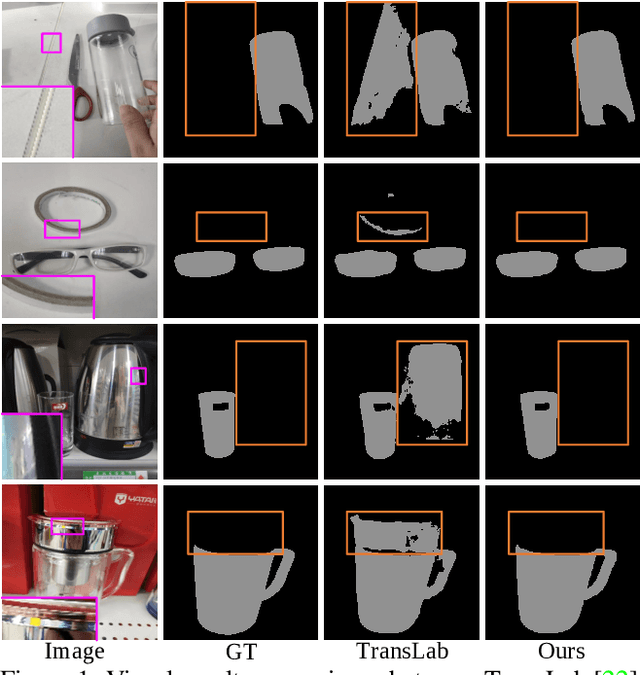

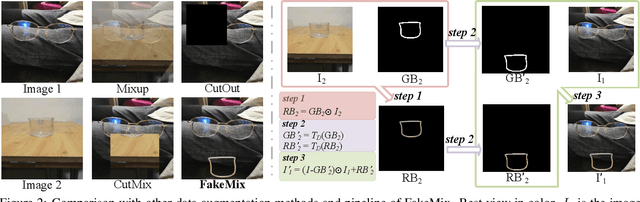
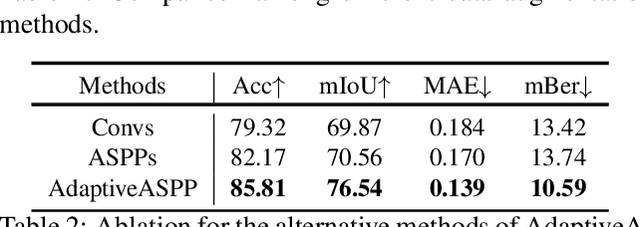
Detecting transparent objects in natural scenes is challenging due to the low contrast in texture, brightness and colors. Recent deep-learning-based works reveal that it is effective to leverage boundaries for transparent object detection (TOD). However, these methods usually encounter boundary-related imbalance problem, leading to limited generation capability. Detailly, a kind of boundaries in the background, which share the same characteristics with boundaries of transparent objects but have much smaller amounts, usually hurt the performance. To conquer the boundary-related imbalance problem, we propose a novel content-dependent data augmentation method termed FakeMix. Considering collecting these trouble-maker boundaries in the background is hard without corresponding annotations, we elaborately generate them by appending the boundaries of transparent objects from other samples into the current image during training, which adjusts the data space and improves the generalization of the models. Further, we present AdaptiveASPP, an enhanced version of ASPP, that can capture multi-scale and cross-modality features dynamically. Extensive experiments demonstrate that our methods clearly outperform the state-of-the-art methods. We also show that our approach can also transfer well on related tasks, in which the model meets similar troubles, such as mirror detection, glass detection, and camouflaged object detection. Code will be made publicly available.
Uncertainty-Based Biological Age Estimation of Brain MRI Scans
Mar 15, 2021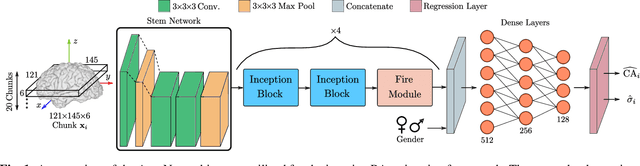
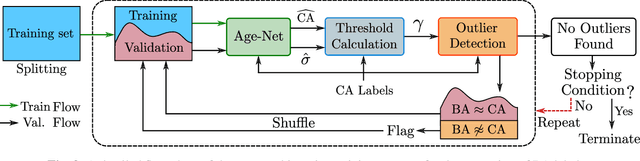
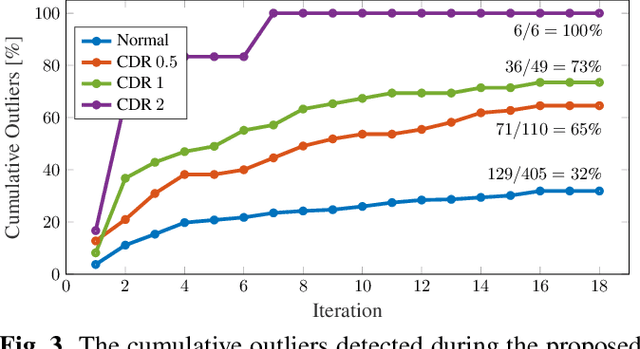
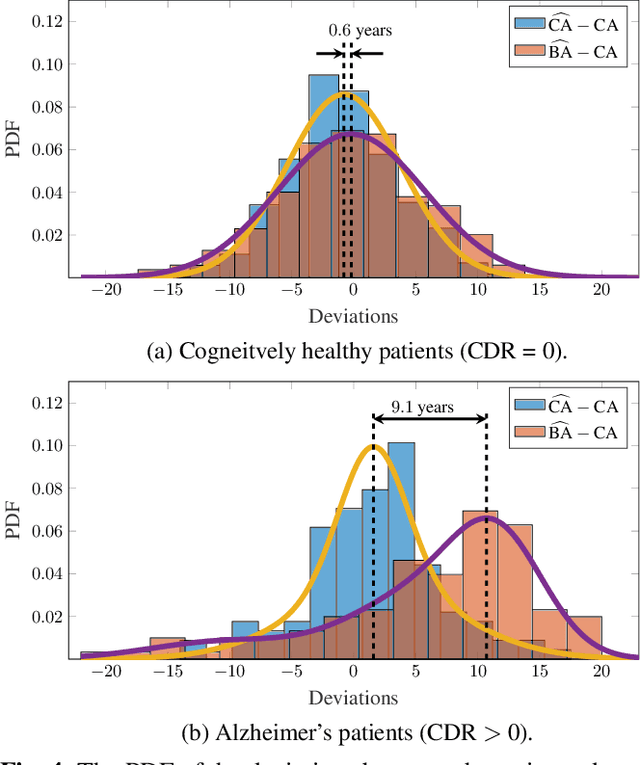
Age is an essential factor in modern diagnostic procedures. However, assessment of the true biological age (BA) remains a daunting task due to the lack of reference ground-truth labels. Current BA estimation approaches are either restricted to skeletal images or rely on non-imaging modalities that yield a whole-body BA assessment. However, various organ systems may exhibit different aging characteristics due to lifestyle and genetic factors. In this initial study, we propose a new framework for organ-specific BA estimation utilizing 3D magnetic resonance image (MRI) scans. As a first step, this framework predicts the chronological age (CA) together with the corresponding patient-dependent aleatoric uncertainty. An iterative training algorithm is then utilized to segregate atypical aging patients from the given population based on the predicted uncertainty scores. In this manner, we hypothesize that training a new model on the remaining population should approximate the true BA behavior. We apply the proposed methodology on a brain MRI dataset containing healthy individuals as well as Alzheimer's patients. We demonstrate the correlation between the predicted BAs and the expected cognitive deterioration in Alzheimer's patients.
How to distribute data across tasks for meta-learning?
Mar 15, 2021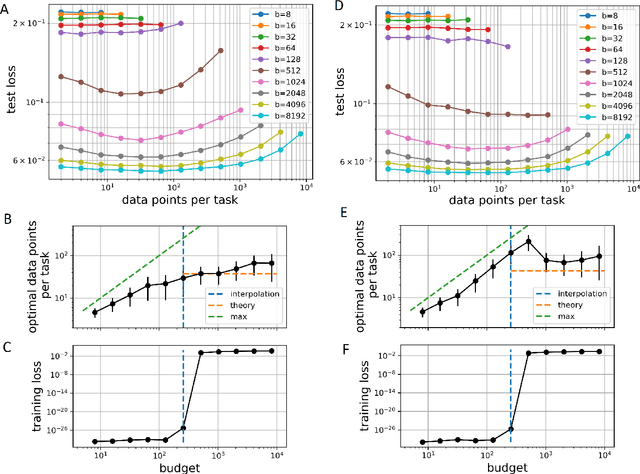
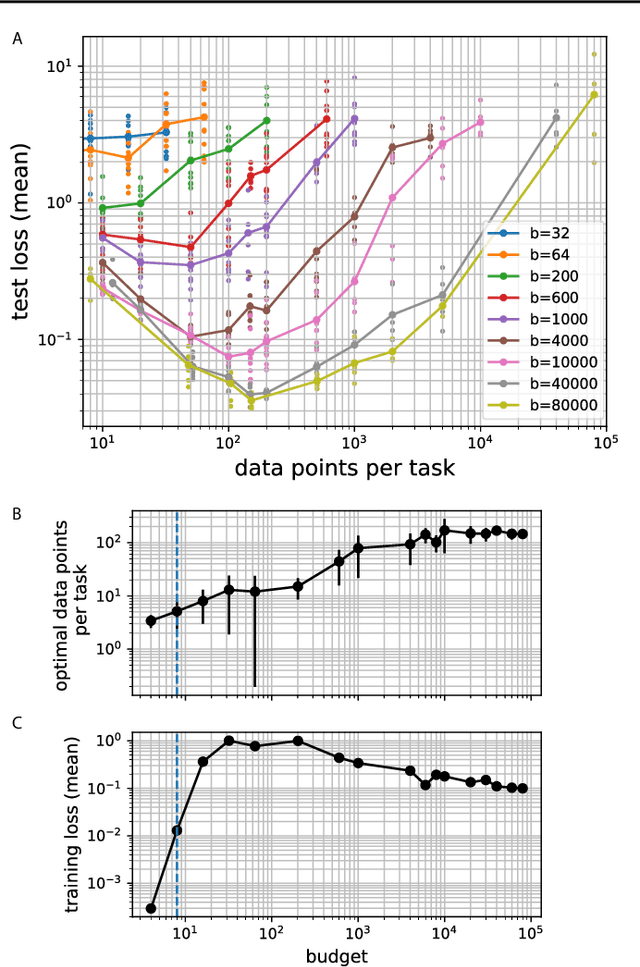
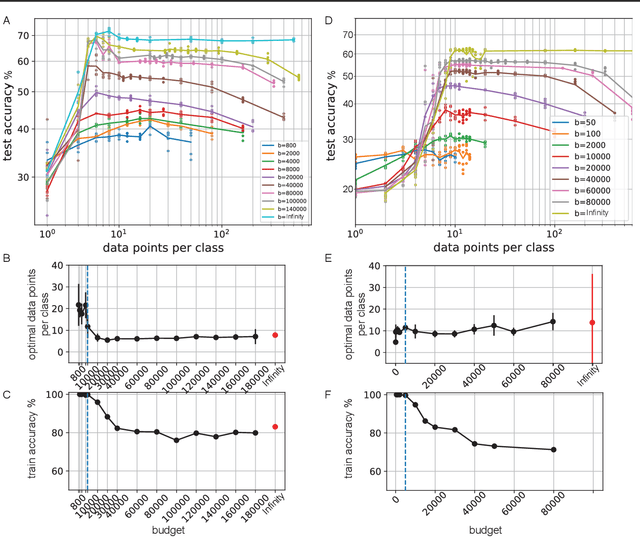

Meta-learning models transfer the knowledge acquired from previous tasks to quickly learn new ones. They are tested on benchmarks with a fixed number of data points per training task. This number is usually arbitrary and it is unknown how it affects the performance. Since labelling of data is expensive, finding the optimal allocation of labels across training tasks may reduce costs: given a fixed budget of labels, should we use a small number of highly labelled tasks, or many tasks with few labels each? We show that: 1) The optimal number of data points per task depends on the budget, but it converges to a unique constant value for large budgets; 2) Convergence occurs around the interpolation threshold of the model. We prove our results mathematically on mixed linear regression, and we show empirically that the same results hold for nonlinear regression and few-shot image classification on CIFAR-FS and mini-ImageNet. Our results suggest a simple and efficient procedure for data collection: the optimal allocation of data can be computed at low cost, by using relatively small data, and collection of additional data can be optimized by the knowledge of the optimal allocation.
Image Denoising with Kernels based on Natural Image Relations
Jan 31, 2016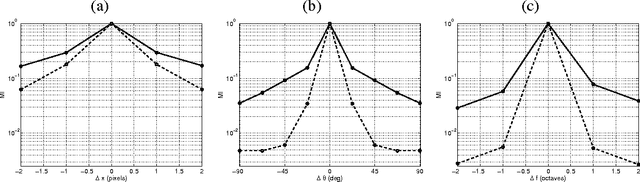
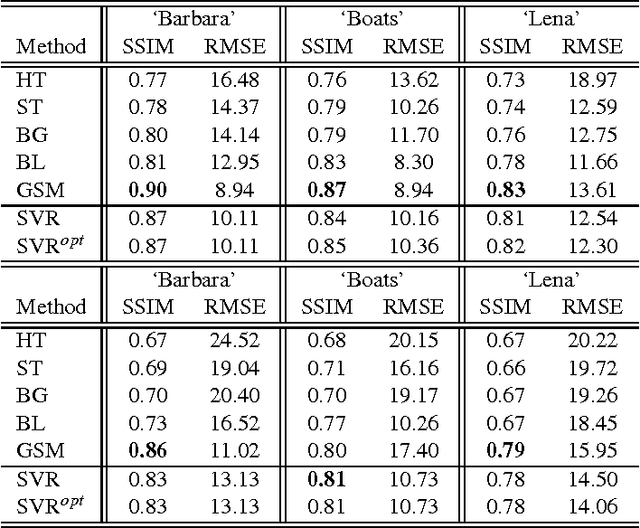
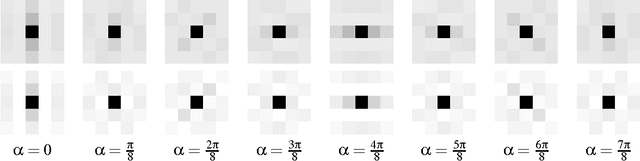
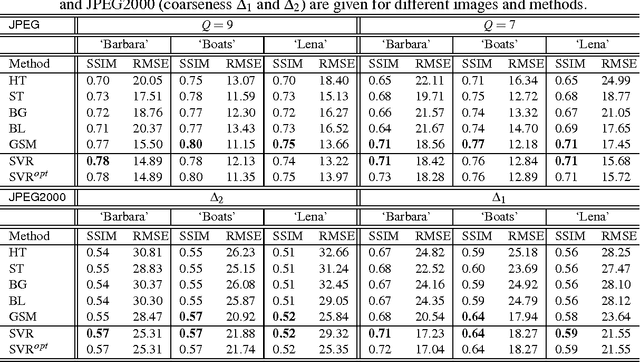
A successful class of image denoising methods is based on Bayesian approaches working in wavelet representations. However, analytical estimates can be obtained only for particular combinations of analytical models of signal and noise, thus precluding its straightforward extension to deal with other arbitrary noise sources. In this paper, we propose an alternative non-explicit way to take into account the relations among natural image wavelet coefficients for denoising: we use support vector regression (SVR) in the wavelet domain to enforce these relations in the estimated signal. Since relations among the coefficients are specific to the signal, the regularization property of SVR is exploited to remove the noise, which does not share this feature. The specific signal relations are encoded in an anisotropic kernel obtained from mutual information measures computed on a representative image database. Training considers minimizing the Kullback-Leibler divergence (KLD) between the estimated and actual probability functions of signal and noise in order to enforce similarity. Due to its non-parametric nature, the method can eventually cope with different noise sources without the need of an explicit re-formulation, as it is strictly necessary under parametric Bayesian formalisms. Results under several noise levels and noise sources show that: (1) the proposed method outperforms conventional wavelet methods that assume coefficient independence, (2) it is similar to state-of-the-art methods that do explicitly include these relations when the noise source is Gaussian, and (3) it gives better numerical and visual performance when more complex, realistic noise sources are considered. Therefore, the proposed machine learning approach can be seen as a more flexible (model-free) alternative to the explicit description of wavelet coefficient relations for image denoising.
Confidence Adaptive Anytime Pixel-Level Recognition
Apr 01, 2021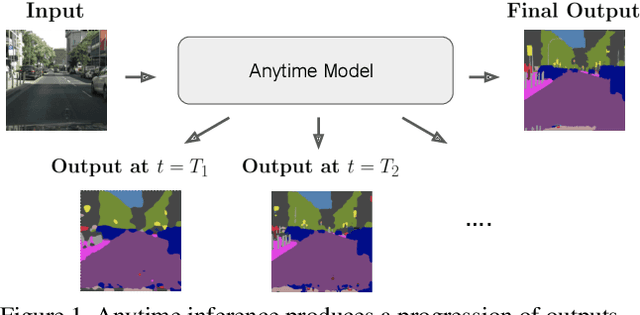
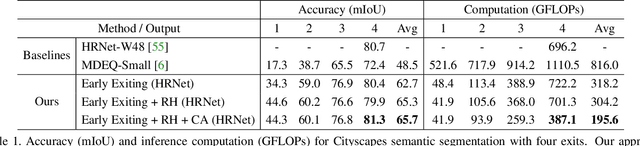
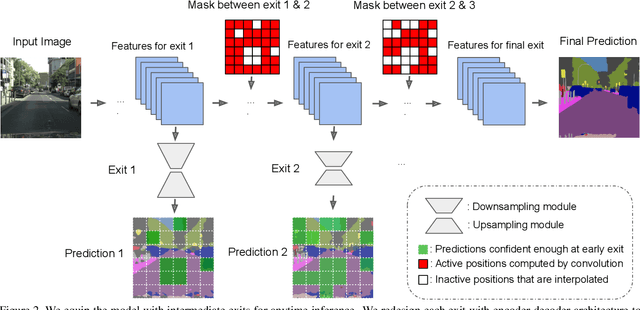
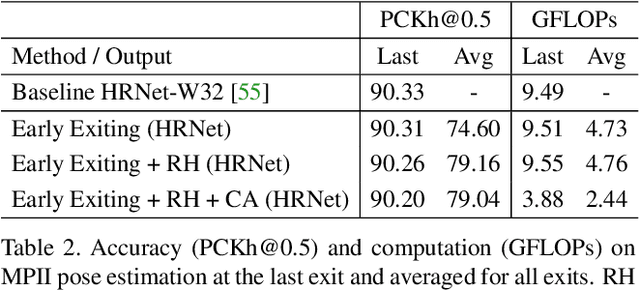
Anytime inference requires a model to make a progression of predictions which might be halted at any time. Prior research on anytime visual recognition has mostly focused on image classification. We propose the first unified and end-to-end model approach for anytime pixel-level recognition. A cascade of "exits" is attached to the model to make multiple predictions and direct further computation. We redesign the exits to account for the depth and spatial resolution of the features for each exit. To reduce total computation, and make full use of prior predictions, we develop a novel spatially adaptive approach to avoid further computation on regions where early predictions are already sufficiently confident. Our full model with redesigned exit architecture and spatial adaptivity enables anytime inference, achieves the same level of final accuracy, and even significantly reduces total computation. We evaluate our approach on semantic segmentation and human pose estimation. On Cityscapes semantic segmentation and MPII human pose estimation, our approach enables anytime inference while also reducing the total FLOPs of its base models by 44.4% and 59.1% without sacrificing accuracy. As a new anytime baseline, we measure the anytime capability of deep equilibrium networks, a recent class of model that is intrinsically iterative, and we show that the accuracy-computation curve of our architecture strictly dominates it.